:字符串深入使用
字符串是计算机编程中表示文本数据的一种数据类型。它是由字符组成的序列,可以包含字母、数字、标点符号和其他特殊字符。
1. 字符串的转义符
转义有两层含义:
- 将一些普通符号赋予特殊功能,比如
\n,\t等 - 将一些特殊符号变为普通符号,比如
\",\\等
以下是一些常见的转义字符及其含义:
\n:换行符,表示在字符串中创建一个新行。
\t:制表符,表示在字符串中插入一个水平制表符(Tab)。
\b:退格字符,b代表backspace,可以把一个退格符看成一个backspace键
\":双引号,用于在字符串中包含双引号字符。
\':单引号,用于在字符串中包含单引号字符。
\\:反斜杠,用于在字符串中包含反斜杠字符本身。
s1 = 'D:\Program Files\nancy\table\back\Python 3.8\python.exe'
print(s1)
s2 = 'D:\Program Files\\nancy\\table\\back\Python 3.8\python.exe'
print(s2)
s3 = r'D:\Program Files\nancy\table\back\Python 3.8\python.exe'
print(s3)
s4 = "i'm \"yuan!\""
s5 = 'i\'m "yuan!"'
print(s4)
print(s5)
2. 格式化输出
字符串的格式化输出,有两种方式:%占位符方式,f-string方式。重点讲了f-string方式,通过{}符替换的方式进行格式化,但是{}中不仅仅替换的是变量,其实是表达式!!!还讲了格式化输出时的一些我之前不知道的参数:可以设置宽度,精度,对齐方式,填充方式。
格式化输出是一种将变量值和其他文本组合成特定格式的字符串的技术。它允许我们以可读性更好的方式将数据插入到字符串中,并指定其显示的样式和布局。
在Python中,有多种方法可以进行格式化输出,其中最常用的方式是使用字符串的 f-strings(格式化字符串字面值)。
【1】%占位符
name = "Yuan"
age = 19
message = "My name is %s, and I am %s years old." % (name, age)
print(message)
在这个示例中,我们使用 %s 占位符将变量 name 的值插入到字符串 "Hello, %s!" 中,然后通过 % 运算符进行格式化。在执行格式化时,% 运算符的左侧是字符串模板,右侧是要按顺序插入的值。
【2】f-string格式
格式化字符串字面值(Formatted String Literal,或称为 f-string)来进行格式化输出。适用于 Python 3.6 及以上版本
name = "yuan"
age = 18
height = 185.123456
s = f"姓名:{name: ^15},年龄:{age},身高:{height:^15.5}cm"
print(s)
name = "alex123456"
age = 18
height = 185
print(s)
宽度与精度
格式描述符形式为:width[.precision]。
-
width正整数,设置字符串的宽度。 -
precision非负整数,可选项,设置字符串的精度,即显示字符串前多少个字符。
填充与对齐
格式描述符形式为:[pad]alignWidth[.precision]。
-
pad填充字符,可选,默认空格。 -
align对齐方式,可选<(左对齐),>(右对齐),^(居中对齐)。
虽然 %s 是一种用于字符串格式化的方式,但自从 Python 3.6 版本起,推荐使用格式化字符串字面值(f-string)或 .format() 方法来进行字符串格式化,因为它们提供了更简洁和直观的语法。
【1】索引和切片
字符串的索引和切片,重点讲了切片:左闭右开,缺省,step步长,当step为负数时,表示字符串到着取,此时切片区间必须从右往左写。
在编程中,索引(Index)和切片(Slice)是用于访问和操作序列(如字符串、列表、元组等)中元素的常用操作。
字符串属于序列类型,所谓序列,指的是一块可存放多个值的连续内存空间,这些值按一定顺序排列,可通过每个值所在位置的编号(称为索引)访问它们。
- 索引用于通过指定位置来访问序列中的单个元素。在大多数编程语言中,索引通常从0开始,表示序列中的第一个元素,然后依次递增。而负索引从 -1 开始,表示序列中的最后一个元素。使用方括号
[]来访问特定索引位置的元素。 - 切片用于从序列中获取一定范围的子序列。它通过指定起始索引和结束索引来选择需要的子序列。切片操作使用方括号
[],并在方括号内使用start:stop:step的形式。注意,start的元素可以获取到,stop的元素获取不到,最后一个元素是[stop-1]对应的元素。
s = "hello yuan"
# (1) 索引:获取某个字符
print(s[0]) # "h"
print(s[-1]) # "n"
# (2) 切片:获取某段子字符串
print(s[2:5]) # 输出"1lo"
print(s[:5]) # 输出"hello"
print(s[6:-1]) # 输出"yua"
print(s[6:]) # 输出"yuan"
print(s[:]) # 输出"hello yuan"
print(s[-1:-3:-1])
print(s[::-1]) # 输出“hello yuan”
【2】其它操作
# 不支持修改,添加元素
# 这是因为字符串在Python中被视为不可更改的序列。一旦创建了一个字符串,就无法直接修改其字符。
# s[0] = "a"
# s[10] = "!"
# 支持的操作
# (1) 获取长度,即元素个数
print(len(s)) # 10
# (2) +、*拼接
s1 = "hello"
s2 = "yuan"
print(s1 + " " + s2)
print("*" * 100)
# 字符串累加
s = ""
s += s1
s += s2
# (3) in判断
print("yuan" in s) # True
4. 字符串内置方法
字符串是一个不可被替换的数据类型!!!
字符串内置方法都不会影响原先字符串,他们都会返回一个新值。
字符串是一个不可被替换的数据类型,因此执行任何字符串的内置方法都不会改变字符串本身,而是开辟一块新的空间创建一个新的字符串对象
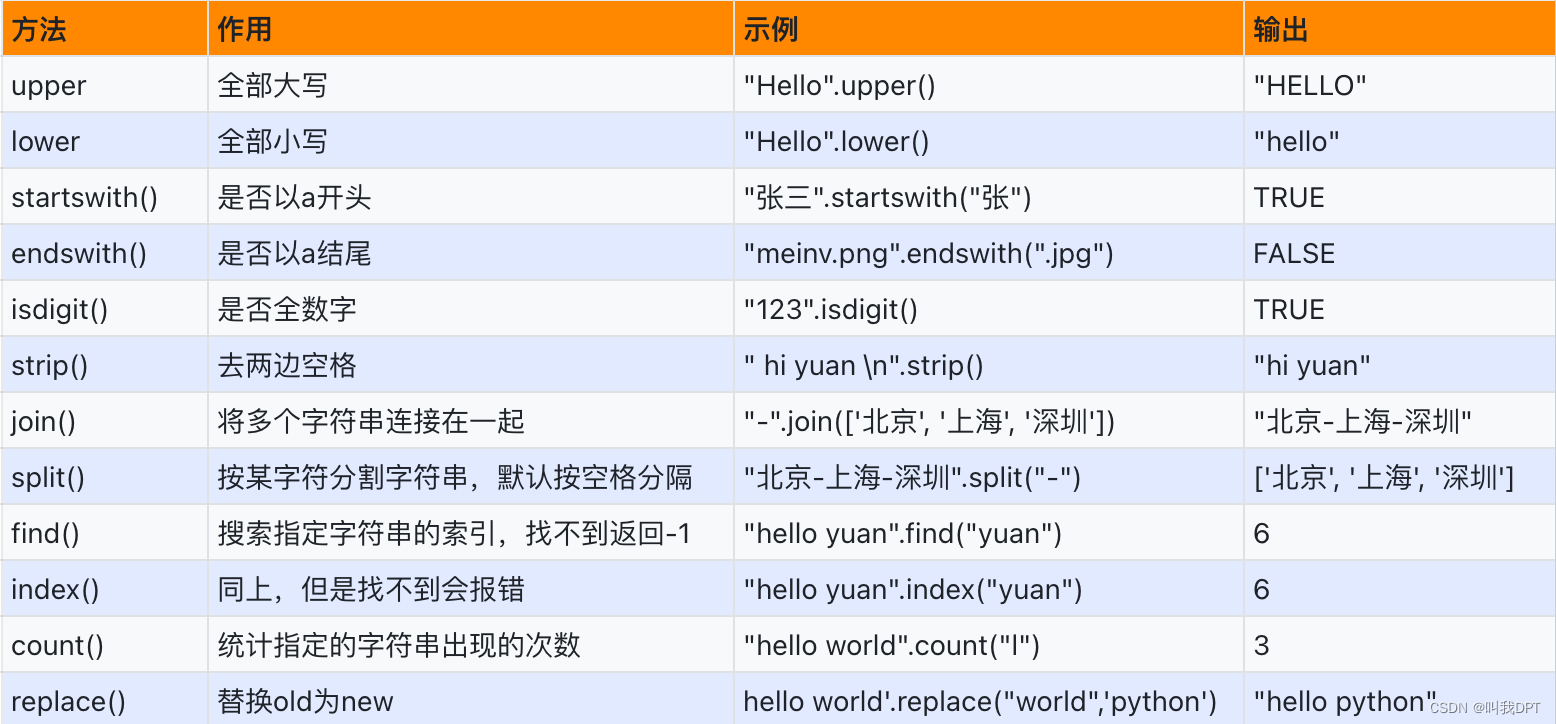
# (1) 字符串转大写:upper(),字符串转小写:lower()
s = "YuanHao"
print(s.upper()) # YUANHAO
print(s.lower()) # yuanhao
# (2) 判断是否以xxx开头
name = "张三"
# 判断是不是姓张
print(name.startswith("张"))
# (3) 判断是否以xxx结尾
url = "/xxx/yyy/zzz/a.png"
print(url.endswith("png"))
# (4) find和index都是查找某子字符串的索引,find找不到返回-1,index找不到报错
print(name.find("三"))
print(name.index("三"))
# (5) 去除两端空格或换行符\n
name = input("请输入姓名:")
print(name, len(name))
name = name.strip()
print(name, len(name))
# (6) 判断某字符串是否全是数字
print("123".isdigit())
# (7) split()和join()
cities = "天津 北京 上海 哈尔滨"
cities_list = cities.split(" ")
print("cities_list", cities_list)
print(len(cities_list))
ret = ",".join(cities_list)
print(ret) # "天津,北京,上海,哈尔滨
info = "yuan 19 180"
info_list = info.split(" ")
print(info_list[0])
print(info_list[1])
print(info_list[2])
# (8) replace(): 子字符串替换
sentence = "PHP is the best language.PHP...PHP...PHP..."
new_sentence = sentence.replace("PHP", "Python")
print(new_sentence)
comments = "这个产品真棒!我非常喜欢。服务很差,不推荐购买。这个餐厅的食物质量太差了,味道不好。我对这次旅行的体验非常满意。这个电影真糟糕,剧情一团糟。这个景点真糟糕,再也不来了!"
comments = comments.replace("差", "***").replace("不推荐", "***").replace("糟糕", "***")
print(comments)
# (9) count:计算字符串中某个子字符串出现的次数
print(sentence.count("PHP"))
:流程控制语句
流程控制语句是计算机编程中用于控制程序执行流程的语句。它们允许根据条件来控制代码的执行顺序和逻辑,从而使程序能够根据不同的情况做出不同的决策。流程控制实现了更复杂和灵活的编程逻辑。
-
顺序语句
顺序语句是按照编写的顺序依次执行程序中的代码。代码会按照从上到下的顺序有且仅执行一次。
-
分支语句
根据条件的真假来选择性地执行不同的代码块。这使得程序能够根据不同的情况做出不同的响应。
-
循环语句
允许重复执行一段代码,以便处理大量的数据或重复的任务。循环语句可以用于多次执行相同或类似的代码块,从而实现重复操作的需求。
流程控制是编程中的基本概念之一,对于编写高效、可靠的程序至关重要。
1. 分支语句
【1】双分支语句
双分支语句是一种编程结构,用于根据条件的真假选择不同的执行路径。它基于条件的结果,决定程序执行的部分。在许多编程语言中,双分支语句通常使用 if-else 语句来实现。
if 条件表达式:
# 条件表达式为True执行的语句块
# pass 语句可以占位
else:
# 条件表达式为False执行的语句块
其中,条件是一个表达式或逻辑判断,它的结果可以是 True(真)或 False(假)。
当条件为真时,执行代码块A,也称为 if 代码块;当条件为假时,执行代码块B,也称为 else 代码块。
双分支语句允许根据不同的条件结果执行不同的代码逻辑,从而实现程序的分支选择和条件判断。它是一种基本的控制流程结构,常用于处理二选一的情况。
# 案例1:获取用户年龄
age = int(input("请输入您的年龄:"))
# 判断是否进入成年电影
if age >= 18:
print("进入成人电影院!")
print("欧美区")
print("日韩区")
print("国产区")
else:
print("进入青少年模式!")
print("科幻冒险类")
print("益智早教类")
print("科普记录类")
# 案例2:根据用户输入的成绩判断其等级。如果成绩大于等于60分,则输出"及格",否则输出"不及格"。
# 案例3: 编写一个程序,判断一个年份是否为闰年。如果是闰年,则输出"是闰年",否则输出"不是闰年"。闰年的判断条件是能够被4整除但不能被100整除,或者能够被400整除。
# 案例4:编写一个程序,根据用户输入的三个数字,判断这三个数字是否能够构成一个等边三角形。如果能够构成等边三角形,则输出"能构成等边三角形",否则输出"不能构成等边三角形"。等边三角形的判断条件是三条边的长度相等。
# 案例5: 用户输入一个年龄,判断是否符合20-35
# 案例6: 输入一个数字,判断是否为偶数
重点:
和其它程序设计语言(如 Java、C 语言)采用大括号“{}”分隔代码块不同,Python 采用代码缩进和冒号( : )来区分代码块之间的层次。
在 Python 中,对于类定义、函数定义、流程控制语句、异常处理语句等,行尾的冒号和下一行的缩进,表示下一个代码块的开始,而缩进的结束则表示此代码块的结束。
注意,Python 中实现对代码的缩进,可以使用空格或者 Tab 键实现。但无论是手动敲空格,还是使用 Tab 键,通常情况下都是采用 4 个空格长度作为一个缩进量(默认情况下,一个 Tab 键就表示 4 个空格)。
【2】单分支语句

单分支语句只包含一个条件判断和一个对应的代码块。如果条件为真,执行代码块中的语句;如果条件为假,则直接跳过代码块。
# 示例:获取两个值中的较小值
# 获取两个输入值
value1 = float(input("请输入第一个值:"))
value2 = float(input("请输入第二个值:"))
# 使用单分支语句获取较小值
if value1 < value2:
min_value = value1
else:
min_value = value2
# 输出较小值
print("较小值为:", min_value)
这个案例可以使用单分支来实现
# 示例:获取两个值中的较小值
# 获取两个输入值
value1 = float(input("请输入第一个值:"))
value2 = float(input("请输入第二个值:"))
# 使用单分支语句获取较小值
if value1 > value2:
value1, value2 = value2, value1
print("较小值:", value1)
【3】多分支语句
多分支语句(if-elif-else语句)可用于在多个条件之间进行选择。
if condition1:
# 当条件1为真时执行的代码块
elif condition2:
# 当条件2为真时执行的代码块
elif condition3:
# 当条件3为真时执行的代码块
...
else:
# 当所有条件都为假时执行的代码块
案例1:成绩等级
# 案例1:根据用户输入的成绩判断其等级。
# 如果成绩[90,100],则输出"优秀"
# 如果成绩[80,90],则输出"良好"
# 如果成绩[60,80],则输出"及格"
# 如果成绩小于60,则输出"不及格"
# 如果成绩小于0或大于100,则输出"成绩有误"
score = int(input("请输入您的成绩:"))
if 90 < score <= 100:
print("成绩优秀!")
elif 80 < score <= 90:
print("成绩良好!")
elif 60 <= score <= 80:
print("成绩及格!")
elif 0 <= score < 60:
print("成绩不及格!")
else:
print("成绩有误")
if score < 0 or score > 100:
print("非法输入")
elif score > 90:
print("成绩优秀!")
elif score > 80:
print("成绩良好!")
elif score > 60:
print("成绩及格!")
else:
print("成绩成绩不及格")
案例2:BMI测试

# 示例:计算BMI并给出健康建议
# 获取用户输入的身高和体重
height = float(input("请输入您的身高(单位:米):"))
weight = float(input("请输入您的体重(单位:千克):"))
# 计算BMI
bmi = weight / (height ** 2)
# 根据BMI给出健康建议
if bmi < 18.5:
advice = f"您的BMI为 {bmi:.3},体重过轻,建议增加营养摄入。"
elif 18.5 <= bmi < 24:
advice = f"您的BMI为 {bmi:.3},体重正常,继续保持健康的生活方式。"
elif 24 <= bmi < 28:
advice = f"您的BMI为 {bmi:.3},体重过重,建议适当控制饮食并增加运动。"
else:
advice = f"您的BMI为 {bmi:.3},体重肥胖,建议减少高热量食物摄入并增加运动量。"
# 输出健康建议
print(advice)
# 场景:
# (1)怪物房: 遇到了史莱姆,并打败了它,金币加5,经验加10!
# (2) 宝箱房: 你打开了宝箱,获得了钥匙
# (3) 陷阱房: 你触发了陷阱,受到了毒箭的伤害,血值减10
# (4) 商店: 你来到了商店,购买了药水,金币减5,血值加20
import random
name = "勇士"
health = 100
coins = 0
exp = 0
print("欢迎来到地下城!")
print(f"""
当前生命值:{health}
当前经验值:{exp}
当前金币:{coins}
""")
input("按下 Enter 进入下一个房间...")
room = random.choice(["怪物房", "宝箱房", "陷阱房", "商店"])
if room == "怪物房":
print("你遇到了史莱姆,并打败了它")
exp += 10
coins += 5
print("金币加5,经验加10!")
elif room == "宝箱房":
print("你打开了宝箱,获得了钥匙")
elif room == "陷阱房":
print("你触发了陷阱,受到了毒箭的伤害")
health -= 10
elif room == "商店":
print("你来到了商店,购买了药水")
coins -= 5
health += 20
print(f"""
当前生命值:{health}
当前经验值:{exp}
当前金币:{coins}
""")
【4】分支嵌套
分支嵌套是指在一个分支语句内部嵌套另一个分支语句。
案例1:
age = int(input("年龄:"))
if age >= 18:
print("成人电影!")
choice = input("""
1. 日韩区
2. 欧美区
3. 国产区
""")
if choice == "1":
print("《熔炉》")
print("《千与千寻》")
print("《龙猫》")
print("《天空之城》")
elif choice == "2":
print("《肖申克的救赎》")
print("《当幸福来敲门》")
print("《阿甘正传》")
print("《星际穿越》")
elif choice == "3":
print("《霸王别姬》")
print("《大话西游》")
print("《让子弹飞》")
print("《无间道》")
else:
print("少儿电影")
print("科幻冒险类")
print("益智早教类")
print("科普记录类")
print("程序结束")
案例2:
"""
勇士与地下城的场景续写:
(1)怪物房: 遇到了史莱姆
1. 选择攻击,战胜史莱姆,则经验加20,金币加20,失败则经验减20,金币减20,血值减20,成功的概率为50%。
2. 选择逃跑,则金币减20
(2) 宝箱房: 你打开了宝箱,获得了钥匙
(3) 陷阱房: 你触发了陷阱,受到了毒箭的伤害,血值减10
(4) 商店: 你来到了商店,打印当前血值和金币,一个金币买一个药水对应10个血值,引导是否购买药水
1. 购买,引导购买几个金币的药水,并完成减金币和增血值
2. 不购买,打印退出商店
"""
import random
name = "勇士"
health = 100
coins = 0
exp = 0
print("欢迎来到地下城!")
print(f"""
当前生命值:{health}
当前经验值:{exp}
当前金币:{coins}
""")
input("按下 Enter 进入下一个房间...")
room = random.choice(["怪物房", "宝箱房", "陷阱房", "商店"])
if room == "怪物房":
action = input("请选择行动:(1)攻击 (2)逃跑")
if action == "1":
attack = random.randint(1, 20)
if attack >= 10:
print("你击败了史莱姆")
coins += 10
else:
print("你的攻击没有命中!")
health -= 20
elif action == "2":
print("你逃跑了,但失去了一些生命值")
health -= 10
else:
print("无效的选择!请重新选择。")
elif room == "宝箱房":
print("你打开了宝箱,获得了钥匙")
elif room == "陷阱房":
print("你触发了陷阱,受到了毒箭的伤害")
health -= 10
elif room == "商店":
choice = input("你来到了商店,购买了药水,是否购买?【Y/N】")
if choice == "Y" and coins >= 5:
print("购买药水成功")
coins -= 5
health += 20
else:
print("退出商店")
print(f"""
当前生命值:{health}
当前经验值:{exp}
当前金币:{coins}
""")
2. 循环语句
预备知识:
PyCharm提供了丰富的功能来帮助开发者编写、调试和运行 Python 代码。其中,PyCharm 的 Debug 模式是一种强大的调试工具,可以帮助开发者在代码执行过程中逐行跟踪和分析程序的行为。以下是关于 PyCharm Debug 模式的介绍:
- 设置断点:在需要调试的代码行上设置断点,断点是程序的一个暂停点,当程序执行到断点时会暂停执行,允许开发者逐行检查代码。
- 启动 Debug 模式:在 PyCharm 中,可以通过点击工具栏上的 “Debug” 按钮来启动 Debug 模式,或者使用快捷键(通常是 F9)。
- 逐行执行:在 Debug 模式下,可以使用调试工具栏上的按钮(如「Step Over」、「Step Into」和「Step Out」)逐行执行代码。Step Over 会执行当前行并跳转到下一行,Step Into 会进入函数调用并逐行执行函数内部代码,Step Out 会执行完当前函数并跳出到调用该函数的位置。
- 变量监视:在 Debug 模式下,可以查看变量的值和状态。在调试工具栏的「Variables」窗口中,可以看到当前作在 PyCharm 中,Debug 模式是一种强大的调试工具,可以帮助开发者在代码执行过程中逐行跟踪和分析程序的行为。
循环语句
循环语句是编程中的一种控制结构,用于重复执行特定的代码块,直到满足特定的条件为止。它允许程序根据需要多次执行相同或类似的操作,从而简化重复的任务。
【1】while循环
while循环用于在条件为真的情况下重复执行一段代码,直到条件变为假为止。以下是while循环的语法:
while条件:
循环体
在执行while循环时,程序会先检查条件是否为真。如果条件为真,就执行循环体中的代码,然后再次检查条件。如果条件仍为真,就再次执行循环体中的代码,以此类推,直到条件变为假为止。
# 无限循环
while 1:
print("hello yuan!")
# 有限循环方式1
count = 0 # 初始语句
while count < 10: # 判断条件
# print("hello yuan")
print("count:::", count)
count += 1 # 步进语句
#有限循环方式2
count = 100 # 初始语句
while count > 0: # 判断条件
print("count:::", count)
count -= 1 # 步进语句
【2】循环案例
案例1:计算1-100的和
"""
# 准备:
# 假设有一个变量s的初始值为0,将s增加5次,每次增加值分别为1,2,3,4,5,然后打印s的值。
"""
# 实现代码
count = 1 # 初始语句
s = 0
while count <= 100: # 判断条件
# s = 0 # 会怎么?
print("count:::", count)
s += count
count += 1 # 步进语句
print(s)
案例2:验证码案例
这节课讲了while的一个字符串凭借案例,还提到了两个库:random和string,库中都方法都可以直接使用的,就无需重复造轮子了
string库中已经帮我们定义好了一些常用的字符串对象
"""
# 假设有一个变量s的初始值为"",将s拼接5次,每次增加值分别为"A","B","C",然后打印s的值。
s = ""
s += "A"
s += "B"
s += "C"
print(s)
"""
import random
import string
char = string.ascii_letters + string.digits
count = 0
randomCodes = ""
while count < 10:
code = random.choice(char)
randomCodes += code
count += 1
print(randomCodes)
【3】for循环
核心:遍历
range函数其实就是帮我们生成一个临时的列表,结合for循环就可以进行指定次数的循环
range函数的参数:start默认等于0,step默认等于1
start,end,step这三个参数的关系与字符串切片的参数相同:step如果是正数:范围就是从小到大;step如果是负数:范围就是从大到小;
顾头不顾尾
for循环用于对一个容器对象(如字符串、列表、元组等)中的元素进行遍历和操作,直到所有元素都被遍历为止。以下是for循环的语法:
for 变量 in 容器对象(字符串,列表,字典等):
循环体
for i in "hello world":
# print("yuan")
print(i)
在执行for循环时,程序会依次将序列中的每个元素赋值给变量,并执行循环体中的代码,直到序列中的所有元素都被遍历完为止。
在 Python 中,range() 函数用于生成一个整数序列,它常用于循环和迭代操作。
range(stop)
range(start, stop, step)
参数解释:
-
start(可选):序列的起始值,默认为 0。 -
stop:序列的结束值(不包含在序列中)。 -
step(可选):序列中相邻两个值之间的步长,默认为 1。
for i in range(100): # 循环次数
print("yuan")
# 基于for循环实现1+100的和的计算
s = 0
for i in range(1, 101): # 循环次数
s += i
print(s)
【4】嵌套语句
案例1:打印出从 0 到 99 中能被 13 整除的所有数字。
for i in range(100):
if i % 13 == 0:
print(i)
案例2:打印出从 1 到 100 的所有整数,但将整除 3 的数字打印为 “Fizz”,整除 5 的数字打印为 “Buzz”,同时整除 3 和 5 的数字打印为 “FizzBuzz”。
for i in range(1, 101):
if i % 3 == 0 and i % 5 == 0:
print("FizzBuzz")
elif i % 3 == 0:
print("Fizz")
elif i % 5 == 0:
print("Buzz")
else:
print(i)
案例3:循环嵌套分支
import random
name = "勇士"
health = 100
coins = 0
exp = 0
print("欢迎来到地下城!")
while 1:
print(f"""
当前生命值:{health}
当前经验值:{exp}
当前金币:{coins}
""")
input("按下 Enter 进入下一个房间")
room = random.choice(["怪物房", "宝箱房", "陷阱房", "商店"])
# ......
【5】退出循环
while是条件循环,条件为False时退出循环,for循环是遍历循环,遍历完成则退出,这都属于正常退出循环,如果想非正常退出循环,分为强制退出当次循环和退出整个循环,分别使用关键字continue和break来实现
-
break退出整个循环
# 退出while循环
while True:
userInput = input("请输入一个数字(输入q退出):")
if userInput == 'q':
print("退出循环")
break
number = int(userInput)
square = number ** 2
print(f"{number} 的平方是 {square}")
# 退出for循环
# 查找1-100中第一个能整除13的非零偶数
for i in range(100):
if i % 13 == 0 and i != 0 and i % 2 == 0:
print("获取i值:", i)
break
-
continue退出当次循环
for i in range(100):
if i % 13 != 0:
continue
print("获取i值:", i)
for i in range(100):
if i % 13 == 0:
print("获取i值:", i)
for-else!!!:
当for循环种有if condition:break时才使用for-else:
当循环正常执行完循环时才会执行else中的代码块;如果break强制跳循环的话就不会执行else中的代码块!!!
:列表&元组
高级数据类型是一种编程语言中提供的用于表示复杂数据结构的数据类型。相比于基础数据类型(如整数、浮点数、布尔值等),高级数据类型可以存储和操作更多的数据,并且具备更丰富的功能和操作方法。
Python的高级数据类型主要包括列表、元组,字典,集合。
1. 列表的概念
在Python中,列表(List)是一种有序、可变、可重复的数据结构,用于存储一组元素。列表是Python中最常用的数据类型之一,它可以包含任意类型的元素,例如整数、浮点数、字符串等。
gf_name_list = ["高圆圆", "范冰冰", "李嘉欣", "陈红"]
info = ["yuan", 18, False]
print(type(info)) # <class 'list'>
列表的特点:
- 列表中的元素按照顺序进行存储和管理
- 元素可以是任意类型且可以不一致
- 元素的长度理论上没有限制
- 列表允许包含重复的元素
- 列表是可变数据类型
2. 列表的基本操作
这节课提到了可变类型和不可变类型,整型,浮点型,字符串类型都是不可变类型;列表是可变类型。
不可变类型是不可以被修改的:当执行不可变类型的内置方法时,会在内存开辟一块新的空间;
而可变类型是可以直接被修改了
还提到了一个面试题:是否可以把字符串‘hello,world’中的o变为大写O,当然是不能直接利用索引进行赋值替换的,因为字符串是不可变类型。所以要先将字符串强转成list再进行替换操作,之后将列表合成字符串。
拼接永远生成新值
索引是管理列表的核心!
- 索引操作
# 查询
l = ['高圆圆', '刘亦菲', '赵丽颖', '范冰冰', '李嘉欣']
print(l[2]) # 12
print(l[-1]) # 14
# 修改
l[3] = "佟丽娅"
- 切片操作
# 查询操作
l = [10,11,12,13,14]
print(l[2:5])
print(l[-3:-1])
print(l[:3])
print(l[1:])
print(l[:])
print(l[2:4])
print(l[-3:-1])
print(l[-1:-3])
print(l[-1:-3:-1])
print(l[::2])
# 修改操作
l[1:4] = [1,2,3]
1、取出的元素数量为:结束位置 - 开始位置;
2、取出元素不包含结束位置对应的索引,列表最后一个元素使用
list[len(slice)]获取;3、当缺省开始位置时,表示从连续区域开头到结束位置;
4、当缺省结束位置时,表示从开始位置到整个连续区域末尾;
5、两者同时缺省时,与列表本身等效;
6、step为正,从左向右切,为负从右向左切。
- 判断成员是否存在
in 关键字检查某元素是否为序列的成员
l = [10,11,12,13,14]
print(20 in l) # False
print(12 in l) # True
- 相加
l1 = [1,2,3]
l2 = [4,5,6]
print(l1 + l2) # [1, 2, 3, 4, 5, 6]
- 循环列表
for name in ["张三",'李四',"王五"]:
print(name)
for i in range(10): # range函数: range(start,end,step)
print(i)
# 基于for循环从100打印到1
for i in range(100,0,-1):
print(i)
-
计算元素个数
# len函数可以计算任意容器对象的元素个数!!! print(len("hello yuan!")) print(len([1, 2, 3, 4, 5, 6])) print(len(["rain", "eric", "alvin", "yuan", "Alex"])) print(len({"k1":"v1","k2":"v2"}))
3. 列表的内置方法
【1】内置方法
列表的内置方法的增的三个方法:append,insert,extend。append是直接往列表最后添加一个对象;insert是可以指定位置添加对象,但是会影响后面的元素所以性能不如append;extend是在一个列表的基础上再加一个列表,它与两个列表直接+的区别是:extend是在原来的基础上进行添加的,而+会生成一个新的列表。
列表内置方法的删的三个方法:pop,remove,clear。pop是根据索引删除,并返回删除元素的内容。remove是根据内容删除没有返回值。clear是清空列表
列表内置方法中的:sort,reverse,index,count。sort是将列表中的元素进行从小到大的排序。reserve是将列表进行翻转,l.reserve与l[::-1]的区别是reserve是对本身的列表进行修改,而利用步长是创建一个新的列表对象。index是根据内容查找索引值。count是计算列表中有多少个元素。

gf_name_list = ['高圆圆', '刘亦菲', '赵丽颖', '范冰冰', '李嘉欣']
# 一、增
# (1) 列表最后位置追加一个值
gf_name_list.append("橘梨纱")
# (2) 向列表任意位置插入一个值
gf_name_list.insert(1, "橘梨纱")
# (3) 扩展列表
gf_name_list.extend(["橘梨纱", "波多野结衣"])
# 二、删
# (1) 按索引删除
gf_name_list.pop(3)
print(gf_name_list)
# (2) 按元素值删除
gf_name_list.remove("范冰冰")
print(gf_name_list)
# (3) 清空列表
gf_name_list.clear()
print(gf_name_list)
# 三、其他操作
l = [10, 2, 34, 4, 5, 2]
# 排序
l.sort()
print(l)
# 翻转
l.reverse()
print(l)
# 计算某元素出现个数
print(l.count(2))
# 查看某元素的索引
print(l.index(34))
【2】案例练习
案例1: 构建一个列表,存储1-10的平方值
l = []
for i in range(1, 11):
# print(i ** 2)
# l.append(i ** 2)
if i % 2 == 0:
l.append(i ** 2)
print(l)
案例2:扑克牌发牌
import random
poke_types = ['♥️', '♦️', '♠️', '♣️']
poke_nums = [2, 3, 4, 5, 6, 7, 8, 9, 10, 'J', 'Q', 'K', 'A']
poke_list = []
for p_type in poke_types:
for p_num in poke_nums:
# print(f"{p_type}{p_num}")
poke_list.append(f"{p_type}{p_num}")
print(poke_list)
# (1) 抽王八
# random.choice():多选一
# ret1 = random.choice(poke_list)
# print(ret1)
# ret2 = random.choice(poke_list)
# print(ret2)
# ret3 = random.choice(poke_list)
# print(ret3)
# (2) 炸金花
# random.sample :多选多
ret1 = random.sample(poke_list, 3)
print(ret1)
for i in ret1:
poke_list.remove(i)
print(len(poke_list))
ret2 = random.sample(poke_list, 3)
for i in ret2:
poke_list.remove(i)
print(len(poke_list))
ret3 = random.sample(poke_list, 3)
print(ret1)
print(ret2)
print(ret3)
案例3:实现一个购物车清单,可以引导用户添加商品和删除商品
shopping_cart = []
while True:
print("--- 购物车清单 ---")
print("1. 添加商品")
print("2. 删除商品")
print("3. 查看购物车")
print("4. 结束程序")
choice = input("请输入选项:")
if choice == "1":
item = input("请输入要添加的商品:")
shopping_cart.append(item)
print("已添加商品:", item)
print()
elif choice == "2":
if len(shopping_cart) == 0:
print("购物车为空,无法删除商品。")
else:
item = input("请输入要删除的商品:")
if item in shopping_cart:
shopping_cart.remove(item)
print("已删除商品:", item)
else:
print("购物车中没有该商品。")
print()
elif choice == "3":
if len(shopping_cart) == 0:
print("购物车为空。")
else:
print("*" * 15)
print("购物车内容:")
for item in shopping_cart:
print(item)
print("*" * 15)
print()
elif choice == "4":
print("程序已结束。")
break
else:
print("无效选项,请重新输入。")
print()
4. 列表的深浅拷贝
python中的可变类型与不可变类型的区别,不可变类型有整数,浮点数,布尔值,字符串,元组,可变类型有列表,字典。
重点讲了可变类型的存储方式,解释了可变类型是为什么可变的:当创建一个三个元素的列表时,会在内存中分别开辟三块空间来存放元素,再开辟一块空间来存放对应三个元素的内存地址,让列表对象指向这块地址。正是因为这种存储方式,所以列表才是可变类型。
要注意,当要修改某个元素时并不是将对应的内存地址的元素直接修改,而是开辟一块新的空间将列表中的内存地址改为新的元素地址。老师还提到了,像C语言,go就是直接将元素存到列表中,原因是他们会要求提前定义这是一个什么类型的列表只能存放什么类型的数据,而python不需要提前声明,且任何类型的数据都可以同时存放在一个列表中。
当已经有一个列表,此时重新对列表重新进行赋值,不会直接修改元素的值,而是重新开辟空间,最后将变量指向新的空间,空间地址会发生改变
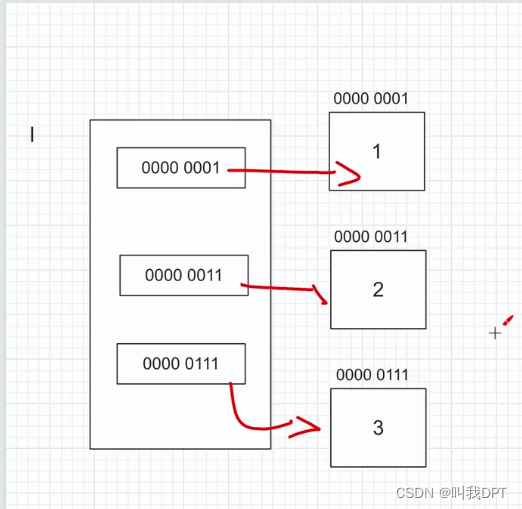
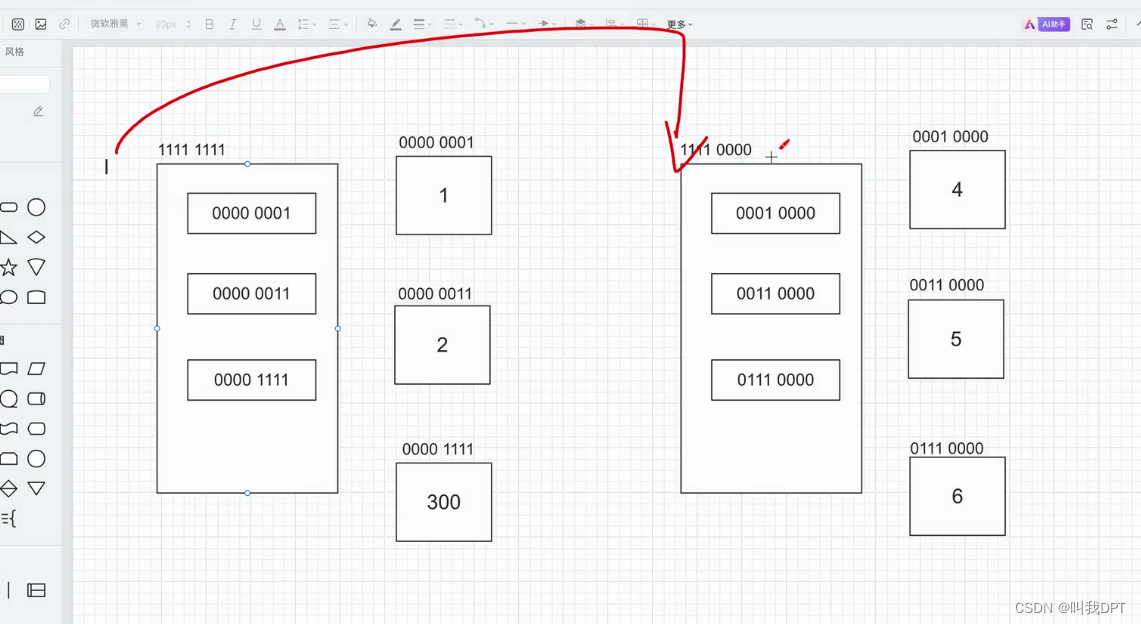
【1】可变类型与不可变类型
在Python中,数据类型可以分为可变类型(Mutable)和不可变类型(Immutable)。这指的是对象在创建后是否可以更改其值或状态。
不可变类型是指创建后不能更改其值或状态的对象。如果对不可变类型的对象进行修改,将会创建一个新的对象,原始对象的值保持不变。在修改后,对象的身份标识(即内存地址)会发生变化。
以下是Python中常见的不可变类型:整数(Integer) 和浮点数(Float),布尔值(Boolean),字符串(String),元组(Tuple)
可变类型是指可以在原地修改的对象,即可以改变其值或状态。当对可变类型的对象进行修改时,不会创建新的对象,而是直接修改原始对象。在修改后,对象的身份标识(即内存地址)保持不变。
Python中常见的可变类型:列表(List),字典(Dictionary)
对于可变类型,可以通过方法调用或索引赋值进行修改,而不会改变对象的身份标识。而对于不可变类型,任何修改操作都会创建一个新的对象。
【2】可变类型的存储方式
l = [1,2,3] # 存储
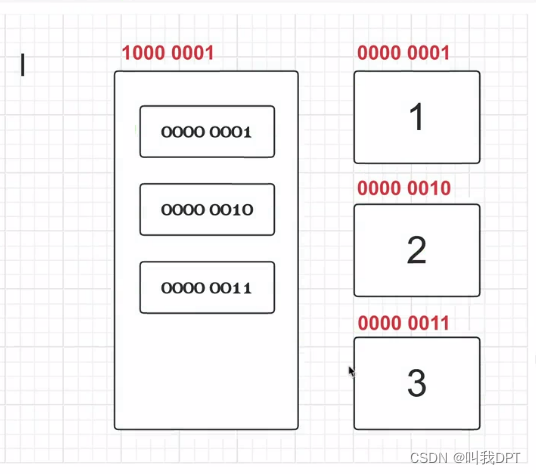
【3】可变类型的变量传递
可变类型的变量传递:实质就是两个变量引用同一块地址空间。与不可变类型不同的时,当两个变量同时指向同一块地址空间时,一个变量修改,另一个也会修改,因为两者是共享数据的。但是,当一个变量发生重新赋值操作时,对另一个变量没有影响,两个变量就毫无关联了
变量实际上是对对象的引用。变量传递的核心是两个变量引用同一地址空间
# 案例1:
x = 1
y = x
x = 2
# print(y)
print(id(x))
print(id(y))
# 案例2:
l1 = [1, 2, 3]
l2 = l1 # 变量传递
l1[0] = 100
print(l1, l2)
l2[1] = 200
print(l1, l2)
# 案例3:
l1 = [1, 2, 3]
l2 = [l1, 4, 5] # 也属于变量传递
l1[0] = 100
print(l1, l2)
l2[0][1] = 200
print(l1, l2)
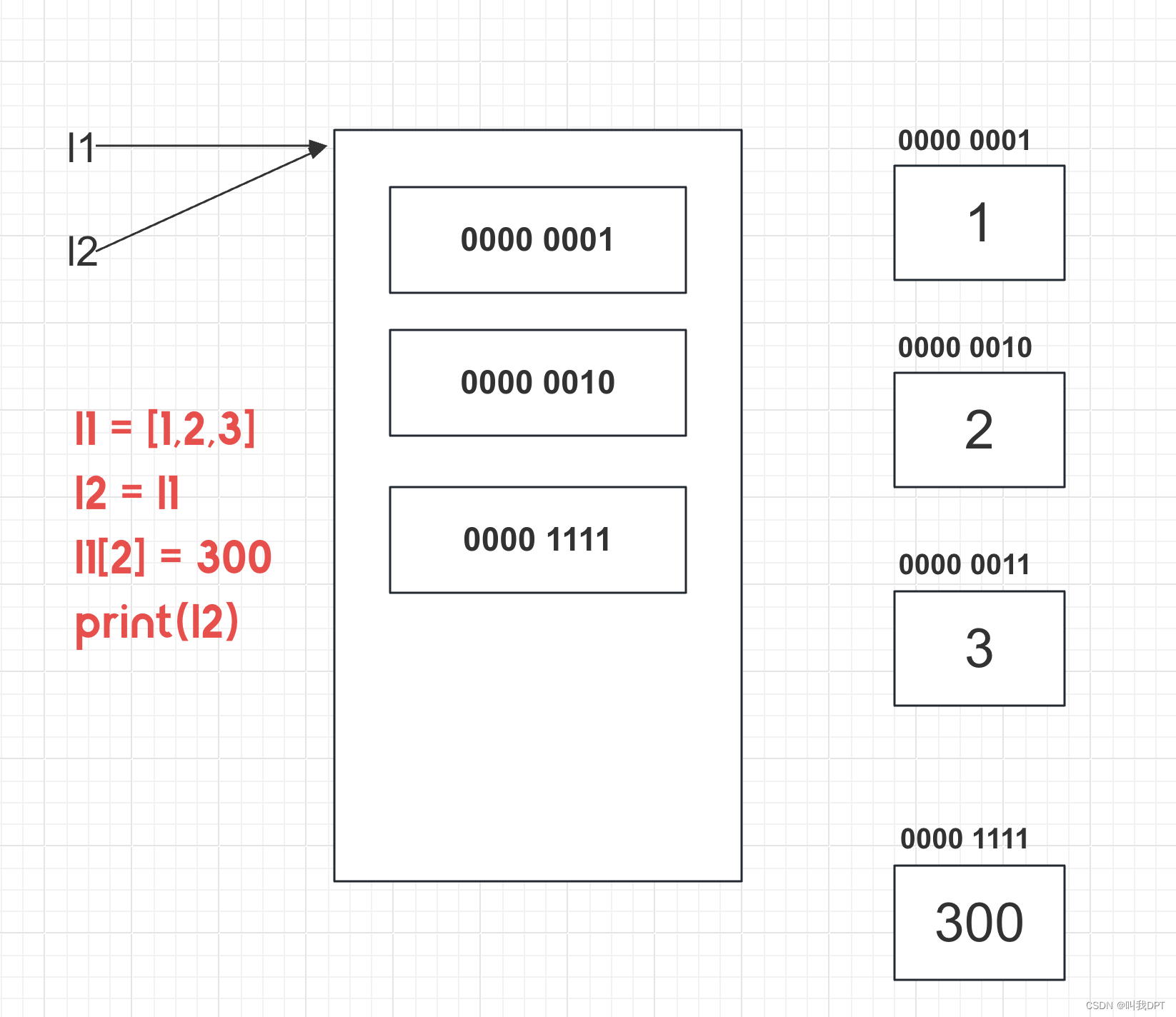
【4】列表的深浅拷贝
列表的深浅拷贝:
浅拷贝:浅拷贝就是只拷贝列表的第一层,也就是存放元素的内存地址的一层,而不会再拷贝一份元素对象。此时两个列表共同指向同一份元素。第一种情况:当列表中元素全部都是不可变对象时:此时修改一个列表中的元素,另一个列表并不会改变,因为他是创建了一个新元素而不是直接修改;第二种情况:当列表中元素存在可变对象时,此时要是一个修改可变对象,则另一个也会发生改变,以为两者是共享该可变对象的。所以浅拷贝呈现出一种在一定情况下两个列表有一定关系的情况。
深拷贝:深拷贝就是将列表的所有层循环拷贝一份,两个列表毫无关系。
在Python中,列表的拷贝可以分为深拷贝和浅拷贝两种方式。
浅拷贝(Shallow Copy)是创建一个新的列表对象,该对象与原始列表共享相同的元素对象。当你对其中一个列表进行修改时,另一个列表也会受到影响。
你可以使用以下方法进行浅拷贝:
# (1)使用切片操作符[:]进行拷贝:
l1 = [1, 2, 3, 4, 5]
l = l1[:]
# (2)使用list()函数进行拷贝
l2 = [1, 2, 3, 4, 5]
l = list(l2)
# (3)使用copy()方法进行拷贝(需要导入copy模块)
l3 = [1, 2, 3, 4, 5]
l = l3.copy()
场景应用:
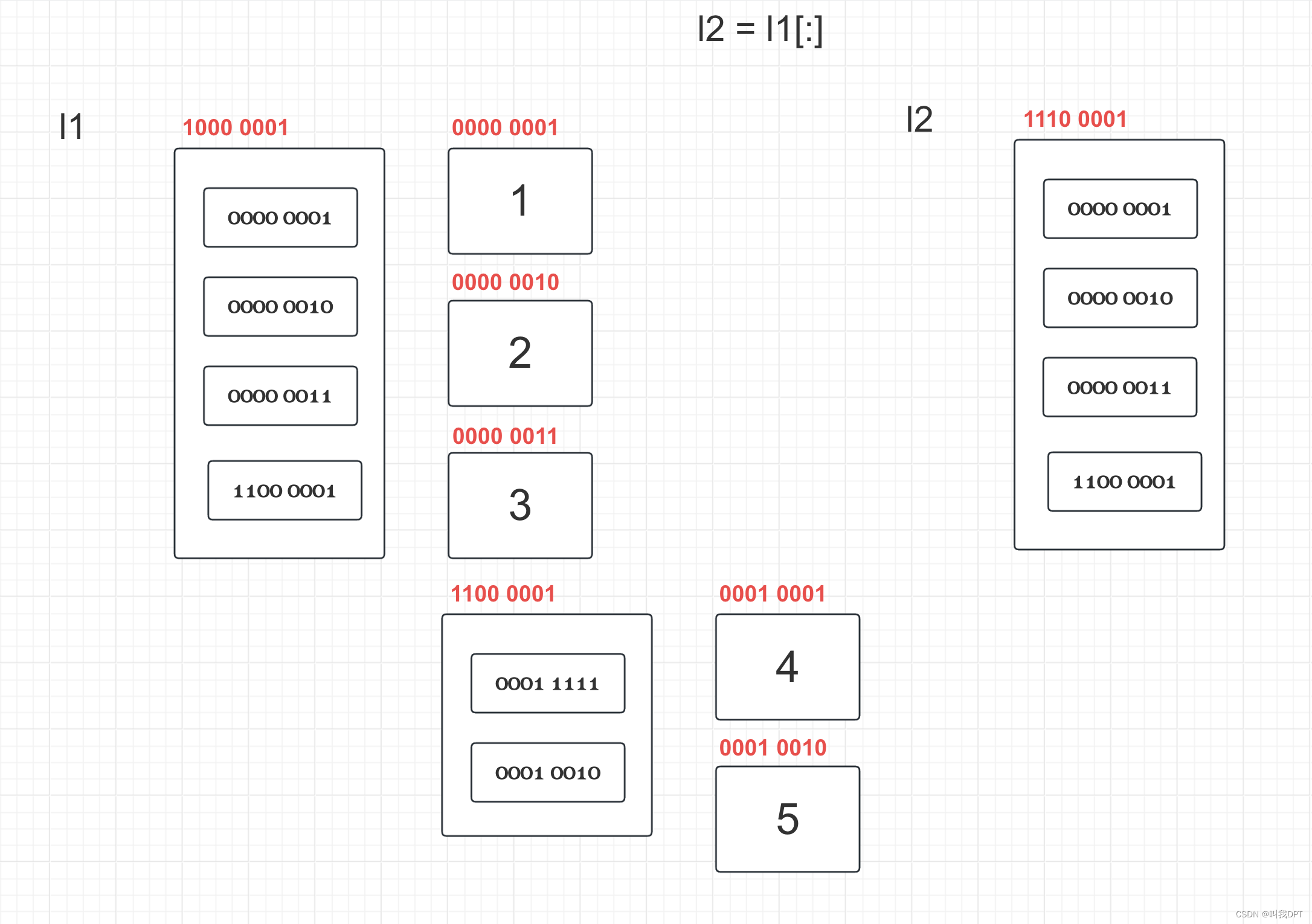
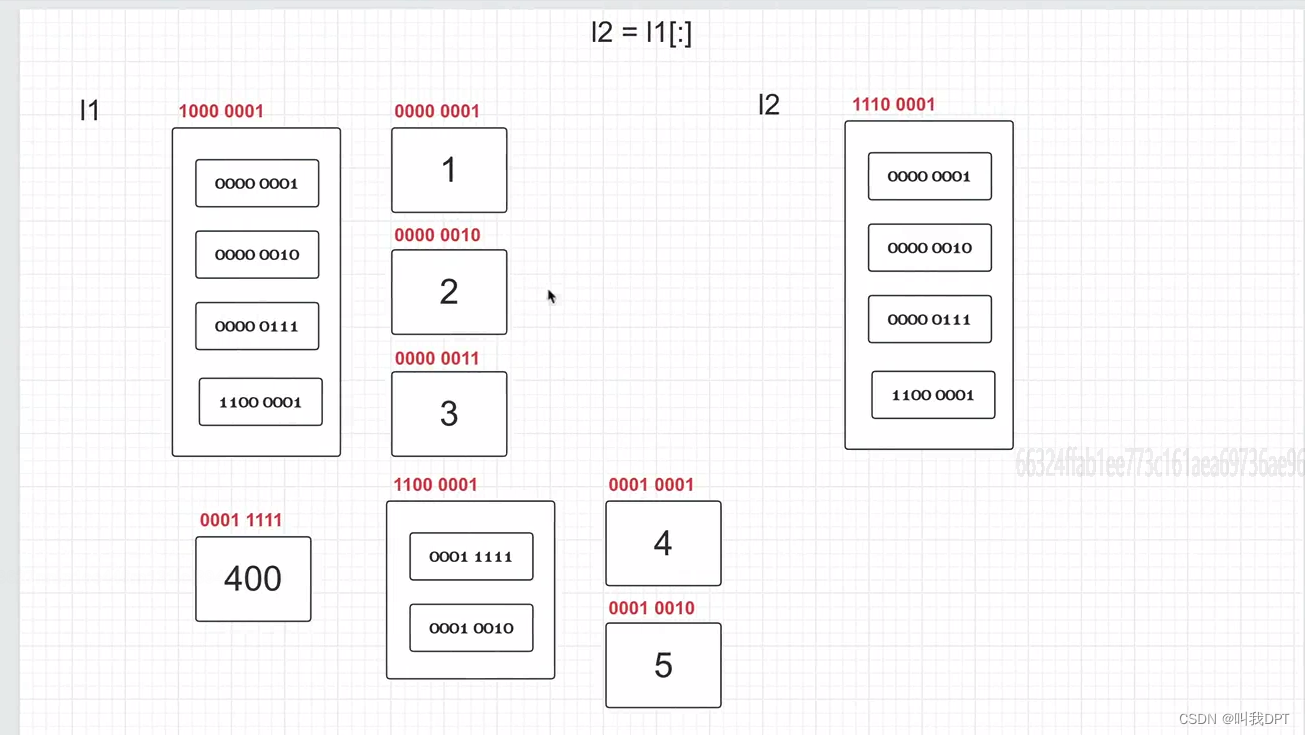
# 案例1
l1 = [1, 2, 3]
l2 = l1[:] # 浅拷贝
print(l2)
print(id(l1[0]))
print(id(l2[0]))
l1[1] = 300
print(l1)
print(l2)
# 案例2
l = [4, 5]
l1 = [1, 2, 3, l]
l2 = l1[:]
l1[0] = 100
print(l2)
l1[3][0] = 400
print(l2)
l1[3] = 400
print(l2)
深拷贝(Deep Copy)是创建一个新的列表对象,并且递归地复制原始列表中的所有元素对象。这意味着原始列表和深拷贝的列表是完全独立的,对其中一个列表的修改不会影响另一个列表。
你可以使用copy()模块中的deepcopy()函数进行深拷贝:
import copy
original_list = [1, 2, 3, 4, 5]
deep_copy = copy.deepcopy(original_list)
需要注意的是,深拷贝可能会更耗费内存和时间,特别是当拷贝的列表中包含大量嵌套的对象时。
5. 列表的嵌套
如果你要使用列表的嵌套来实现客户信息管理系统,可以将每个客户的信息存储在一个子列表中,然后将所有学生的子列表存储在主列表中。每个学生的信息可以按照一定的顺序存储,例如姓名、年龄、邮箱等。
# 初始化客户信息列表
customers = [
["Alice", 25, "alice@example.com"],
["Bob", 30, "bob@example.com"],
["Charlie", 35, "charlie@example.com"]
]
# 增加客户信息
new_customer = ["David", 28, "david@example.com"]
customers.append(new_customer)
# 删除客户信息
delete_customer = "Bob"
for customer in customers:
if customer[0] == delete_customer:
customers.remove(customer)
break
# 修改客户信息
update_customer = "Alice"
for customer in customers:
if customer[0] == update_customer:
customer[1] = 26
break
# 查询客户信息
search_customer = "Charlie"
for customer in customers:
if customer[0] == search_customer:
name = customer[0]
age = customer[1]
email = customer[2]
print(f"姓名: {name}, 年龄: {age}, 邮箱: {email}")
break
# 功能整合
print("""
1. 添加客户
2. 删除客户
3. 修改客户
4. 查询一个客户
5. 查询所有客户
6. 退出
""")
在这个案例代码中,每个客户的信息被存储在一个子列表中,然后将该客户的子列表添加到客户列表中。在展示学生信息时,可以通过索引访问每个客户的具体信息。该代码使用了列表的嵌套来存储客户信息。仍然实现了添加客户信息、查看客户信息和退出程序的功能。
6. 列表推导式
列表推导式(List comprehensions)是一种简洁的语法,用于创建新的列表,并可以在创建过程中对元素进行转换、筛选或组合操作。
列表推导式的一般形式为:
new_list = [expression for item in iterable if condition]
其中:
-
expression是要应用于每个元素的表达式或操作。 -
item是来自可迭代对象(如列表、元组或字符串)的每个元素。 -
iterable是可迭代对象,提供要遍历的元素。 -
condition是一个可选的条件,用于筛选出满足条件的元素。
# 创建一个包含1到5的平方的列表
squares = [x**2 for x in range(1, 6)]
print(squares) # 输出: [1, 4, 9, 16, 25]
# 筛选出长度大于等于5的字符串
words = ["apple", "banana", "cherry", "date", "elderberry"]
filtered_words = [word for word in words if len(word) >= 5]
print(filtered_words) # 输出: ["apple", "banana", "cherry"]
# 将两个列表中的元素进行组合
numbers = [1, 2, 3]
letters = ['A', 'B', 'C']
combined = [(number, letter) for number in numbers for letter in letters]
print(combined) # 输出: [(1, 'A'), (1, 'B'), (1, 'C'), (2, 'A'), (2, 'B'), (2, 'C'), (3, 'A'), (3, 'B'), (3, 'C')]
7. 元组
元组(Tuple)是Python中的一种数据类型,它是一个有序的、不可变的序列。元组使用圆括号 () 来表示,其中的元素可以是任意类型,并且可以包含重复的元素。
与列表(List)不同,元组是不可变的,这意味着一旦创建,它的元素就不能被修改、删除或添加。元组适合用于存储一组不可变的数据。例如,你可以使用元组来表示一个坐标点的 x 和 y 坐标值,或者表示日期的年、月、日等。元组也被称为只读列表
info = ("yuan", 20, 90)
# 获取长度
print(len(info))
# 索引和切片
print(info[2])
print(info[:2])
# 成员判断
print("yuan" in info)
# 拼接
print((1, 2) + (3, 4))
# 循环
for i in info:
print(i)
# 内置方法
print(t.index(5))
print(t.count(2))
当要对列表进行循环增删时:避免对原列表进行操作。
因为当对L本身进行数据删除的时候,索引的值会发生变化,可能会导致出现元素漏判的情况。
所以一旦涉及到对列表的循环增删操作,可以考虑使用浅拷贝,或者直接拷贝一份,避免对列表本身进行操作。
:字典&集合
1. 字典的初识
字典的存储原理:会先开辟一块空间,在空间由很多bucket组成,bucket分为两块,一块存储键,一块存储值。存储时根据计算出键的哈希值的二进制形式,将哈希值的最后三位作为偏移量找到对应的bucket。如果该bucket已经存放了信息,就看左边三位作为偏移量直至直到空的bucket。
查找时,先根据最后三位查找,在将两个键的哈希值进行对比,一直则找到;否则看前三位在对比直至找到。
【1】字典的创建与价值
字典(Dictionary)是一种在Python中用于存储和组织数据的数据结构。元素由键和对应的值组成。其中,键(Key)必须是唯一的,而值(Value)则可以是任意类型的数据。在 Python 中,字典使用大括号{}来表示,键和值之间使用冒号:进行分隔,多个键值对之间使用逗号,分隔。
# 列表
info_list = ["yuan", 18, 185, 70]
# 字典
info_dict = {"name": "yuan", "age": 18, "height": 185, "weight": 70}
print(type(info_dict)) # <class 'dict'>
字典类型很像学生时代常用的新华字典。我们知道,通过新华字典中的音节表,可以快速找到想要查找的汉字。其中,字典里的音节表就相当于字典类型中的键,而键对应的汉字则相当于值。
字典的灵魂:
字典是由一个一个的 key-value 构成的,字典通过键而不是通过索引来管理元素。字典的操作都是通过 key 来完成的。
【2】字典的存储与特点
hash:百度百科
Hash,一般翻译做散列、杂凑,或音译为哈希,是把任意长度的输入(又叫做预映射pre-image)通过散列算法变换成固定长度的输出,该输出就是散列值。这种转换是一种压缩映射,也就是,散列值的空间通常远小于输入的空间,不同的输入可能会散列成相同的输出,所以不可能从散列值来确定唯一的输入值。简单的说就是一种将任意长度的消息压缩到某一固定长度的消息摘要的函数。
字典对象的核心其实是个散列表,而散列表是一个稀疏数组(不是每个位置都有值),每个单元叫做bucket,每个bucket有两部分:一个是键对象的引用,一个是值对象的引用,由于,所有bucket结构和大小一致,我们可以通过偏移量来指定bucket的位置
将一对键值放入字典的过程:
先定义一个字典,再写入值
d = {}
d["name"] = "yuan"
在执行第二行时,第一步就是计算"name"的散列值,python中可以用hash函数得到hash值,再将得到的值放入bin函数,返回int类型的二进制
print(bin(hash("name")))
结果为:
-0b100000111110010100000010010010010101100010000011001000011010
假设数组长度为10,我们取出计算出的散列值,最右边3位数作为偏移量,即010,十进制是数字2,我们查看偏移量为2对应的bucket的位置是否为空,如果为空,则将键值放进去,如果不为空,依次取右边3位作为偏移量011,十进制是数字3,再查看偏移量3的bucket是否为空,直到单元为空的bucket将键值放进去。以上就是字典的存储原理
当进行字典的查询时:
d["name"]
d.get("name")
第一步与存储一样,先计算键的散列值,取出后三位010,十进制为2的偏移量,找到对应的bucket的位置,查看是否为空,如果为空就返回None,不为空就获取键并计算键的散列值,计算后将刚计算的散列值与要查询的键的散列值比较,相同就返回对应bucket位置的value,不同就往前再取三位重新计算偏移量,依次取完后还是没有结果就返回None。
print(bin(hash("name")))每次执行结果不同:这是因为 Python 在每次启动时,使用的哈希种子(hash seed)是随机选择的。哈希种子的随机选择是为了增加哈希函数的安全性和防止潜在的哈希碰撞攻击。
字典的特点:
- 无序性:字典中的元素没有特定的顺序,不像列表和元组那样按照索引访问。通过键来访问和操作字典中的值。
- 键是唯一的且不可变类型对象,用于标识值。值可以是任意类型的对象,如整数、字符串、列表、元组等。
- 可变性:可以向字典中添加、修改和删除键值对。这使得字典成为存储和操作动态数据的理想选择。
2. 字典的基本操作
字典的基本操作,创建,查值,修改值,删除值,元素是否存在,循环。
注意:字典键的值一旦创建无法修改,只能删除再创建。
# 使用 { } 创建字典
gf = {"name":"高圆圆","age":32}
print(len(gf))
# (1) 查键值
print(gf["name"]) # 高圆圆
print(gf["age"]) # 32
# (2) 添加或修改键值对,注意:如果键存在,则是修改,否则是添加
gf["age"] = 29 # 修改键的值
gf["gender"] = "female" # 添加键值对
# (3) 删除键值对 del 删除命令
print(gf)
del gf["age"]
print(gf)
del gf
print(gf)
# (4) 判断键是否存在某字典中
print("weight" in gf)
# (5) 循环
for key in gf:
print(key,d[key])
Python 字典中键(key)的名字不能被修改,我们只能根据键(key)修改值(value)。
3. 字典的内置方法
字典的内置方法:update增和改,pop按键删除返回值,get查,有返回值无返回None,可以设置默认参数。keys获取全部键,dict_keys类型。values获取全部键,dict_values类型。items获取全部键和值,dict_items类型,时列表嵌套元组的形式,items方法通常与for一起使用。
可变数据类型的操作核心就是:搞清楚是在修改可变数据类型还是对变量重新赋值

gf = {"name": "高圆圆", "age": 32}
# (1) 创建字典
knowledge = ['语文', '数学', '英语']
scores = dict.fromkeys(knowledge, 60)
print(scores)
# (2) 获取某键的值
print(gf.get("name")) # "高圆圆
# (3) 更新键值:添加或更改
gf.update({"age": 18, "weight": "50kg"})
print(gf) # {'name': '高圆圆', 'age': 18, 'weight': '50kg'}
# (4) 删除weight键值对
ret = gf.pop("weight") # 返回删除的值
print(gf)
# (5) 遍历字典键值对
for k, v in gf.items():
print(k, v)
4. 可变数据类型之字典
# 列表字典存储方式
l =[1,2,3]
d = {"a": 1, "b": 2}
# 案例1:
l1 = [3, 4, 5]
d1 = {"a": 1, "b": 2, "c": l1}
l1.append(6)
print(d1)
d1["c"][0] = 300
print(l1)
# 案例2:
d2 = {"x": 10, "y": 20}
d3 = {"a": 1, "b": 2, "c": d2}
d2["z"] = 30
# d3["c"].update({"z": 30})
print(d3)
# d3["c"]["x"] = 100
d3["c"].update({"x": 100})
print(d2)
d3["c"] = 3
# 案例3:
d4 = {"x": 10, "y": 20}
l2 = [1, 2, d4]
# d4["z"] = 30
# print(l2)
l2[2].pop("y")
print(d4)
5. 列表字典嵌套实战案例
【1】基于字典的客户信息管理系统
-
列表嵌套字典版本
# 初始化客户信息列表 customers = [ { "name": "Alice", "age": 25, "email": "alice@example.com" }, { "name": "Bob", "age": 28, "email": "bob@example.com" }, ] while 1: print(""" 1. 添加客户 2. 删除客户 3. 修改客户 4. 查询一个客户 5. 查询所有客户 6. 退出 """) choice = input("请输入您的选择:") if choice == "1": # (1) 添加客户 append name = input("请输入添加客户的姓名:") age = input("请输入添加客户的年龄:") email = input("请输入添加客户的邮箱:") new_customer = { "name": name, "age": age, "email": email } customers.append(new_customer) print(f"添加客户{name}成功!") # print("当前客户:", customers) elif choice == "2": # (2) 删除客户 del_customer_name = input("请输入删除客户的姓名:") flag = False for customerD in customers: # print(customerL) if customerD["name"] == del_customer_name: customers.remove(customerD) print(f"客户{del_customer_name}删除成功!") flag = True break if flag: print("当前客户列表:", customers) else: print(f"客户{del_customer_name}不存在!") elif choice == "3": # (3) 修改客户 update_customer_name = input("请输入修改客户的姓名:") name = input("请输入修改客户新的姓名:") age = input("请输入修改客户新的年龄:") email = input("请输入修改客户新的邮箱:") for customerD in customers: if customerD["name"] == update_customer_name: # customerD["name"] = name # customerD["age"] = age # customerD["email"] = email customerD.update({"name": name, "age": age, "email": email}) break print("当前客户列表:", customers) elif choice == "4": # (4) 查看某一个客户 query_customer_name = input("请输入查看客户的姓名:") for customerD in customers: # print("customerL",customerL) if customerD["name"] == query_customer_name: print(f"姓名:{customerD.get('name')},年龄:{customerD.get('age')},邮箱:{customerD.get('email')}") break elif choice == "5": # (5) 遍历每一个一个客户信息 # if len(customers) == 0: if customers: for customerD in customers: print(f"姓名:{customerD.get('name'):10},年龄:{customerD.get('age')},邮箱:{customerD.get('email')}") else: print("当前没有任何客户信息!") elif choice == "6": print("退出程序!") break else: print("输入内容格式不对!") -
字典嵌套字典版本
# 初始化客户信息列表 customers = { 1001: { "name": "Alice", "age": 25, "email": "alice@example.com" }, 1002: { "name": "Bob", "age": 28, "email": "bob@example.com" }, } while 1: print(""" 1. 添加客户 2. 删除客户 3. 修改客户 4. 查询一个客户 5. 查询所有客户 6. 退出 """) choice = input("请输入您的选择:") if choice == "1": # (1) 添加客户 append id = int(input("请输入添加客户的ID:")) if id in customers: # "1001" in {1001:...} print("该ID已经存在!") else: name = input("请输入添加客户的姓名:") age = input("请输入添加客户的年龄:") email = input("请输入添加客户的邮箱:") new_customer = { "name": name, "age": age, "email": email } # customers[id] = new_customer customers.update({id: new_customer}) print(f"添加客户{name}成功!") print("当前客户:", customers) elif choice == "2": # (2) 删除客户 del_customer_id = int(input("请输入删除客户的ID:")) if del_customer_id in customers: customers.pop(del_customer_id) print(f"删除{del_customer_id}客户成功!") print("当前客户:", customers) else: print("该ID不存在!") elif choice == "3": # (3) 修改客户 update_customer_id = int(input("请输入修改客户的ID:")) if update_customer_id in customers: name = input("请输入修改客户新的姓名:") age = input("请输入修改客户新的年龄:") email = input("请输入修改客户新的邮箱:") # 方式1: # customers[update_customer_id]["name"] = name # customers[update_customer_id]["age"] = age # customers[update_customer_id]["email"] = email # 方式2: customers[update_customer_id].update({"name": name, "age": age, "email": email}) # 方式3: # customers[update_customer_id] = { # "name": name, # "age": age, # "email": email, # } print(f"{update_customer_id}客户修改成功!") print("当前客户:", customers) else: print("该ID不存在!") elif choice == "4": # (4) 查看某一个客户 query_customer_id = int(input("请输入查看客户的ID:")) if query_customer_id in customers: customerD = customers[query_customer_id] print(f"姓名:{customerD.get('name')},年龄:{customerD.get('age')},邮箱:{customerD.get('email')}") else: print("该客户ID不存在!") elif choice == "5": # (5) 遍历每一个一个客户信息 # if len(customers) == 0: if customers: for key,customerDict in customers.items(): print(f"客户ID:{key},姓名:{customerDict.get('name'):10},年龄:{customerDict.get('age')},邮箱:{customerDict.get('email')}") else: print("当前没有任何客户信息!") elif choice == "6": print("退出程序!") break else: print("输入内容格式不对!")
6. 集合
集合的基本特性:唯一性,无序性,以及默认情况下时可变数据类型。还讲了内置方法:add添加,remove删除没有报错,discard删除没有不报错,pop随机删除,update并集更新。注意不能集合没有修改操作。
集合(Set)是Python中的一种无序、不重复的数据结构。集合是由一组元素组成的,这些元素必须是不可变数据类型,但 在集合中每个元素都是唯一的,即集合中不存在重复的元素。
集合的元素不能包含可变数据类型的元素,因为集合存储时是对元素进行哈希操作的,而不可变数据类型不能进行哈希操作。
通过运算符和内置函数讲了对集合进行交差并的运算:(1)&交集,-差集,|并集。(2)intersection交集,difference差集,symmetric_difference对称差集,union并集。
集合的基本语法和特性:
s1 = {1,2,3}
print(len(s1))
print(type(s1))
# 元素值必须是不可变数据类型
# s1 = {1, 2, 3,[4,5]} # 报错
# (1) 无序:没有索引
# print(s1[0])
# (2) 唯一: 集合可以去重
s2 = {1, 2, 3, 3, 2, 2}
print(s2)
# 面试题:
l = [1, 2, 3, 3, 2, 2]
# 类型转换:将列表转为set
print(set(l)) # {1, 2, 3}
print(list(set(l))) # [1, 2, 3]
- 无序性:集合中的元素是无序的,即元素没有固定的顺序。因此,不能使用索引来访问集合中的元素。
- 唯一性:集合中的元素是唯一的,不允许存在重复的元素。如果尝试向集合中添加已经存在的元素,集合不会发生变化。
- 可变性:集合是可变的,可以通过添加或删除元素来改变集合的内容。
集合的内置方法:
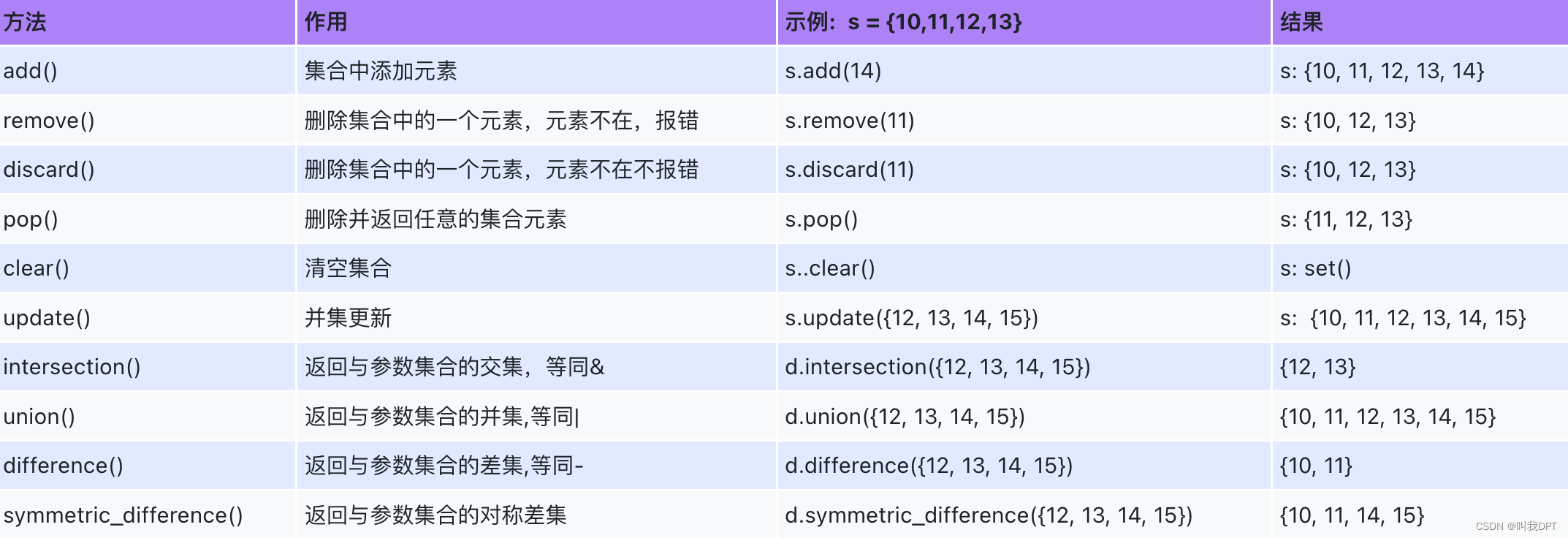
s3 = {1, 2, 3}
# 增删改查
# 增
s3.add(4)
s3.add(3)
print(s3)
s3.update({3, 4, 5})
print(s3)
# l = [1, 2, 3]
# l.extend([3, 4, 5])
# print(l)
# 删
s3.remove(2)
s3.remove(222)
s3.discard(2)
s3.discard(222)
s3.pop()
s3.clear()
print(s3) # set()
# 方式1: 操作符 交集(&) 差集(-) 并集(|)
s1 = {1, 2, 3, 4}
s2 = {3, 4, 5, 6}
print(s1 & s2) # {3, 4}
print(s2 & s1) # {3, 4}
print(s1 - s2) # {1, 2}
print(s2 - s1) # {5, 6}
print(s1 | s2) # {1, 2, 3, 4, 5, 6}
print(s2 | s1) # {1, 2, 3, 4, 5, 6}
print(s1, s2)
# 方式2:集合的内置方法
s1 = {1, 2, 3, 4}
s2 = {3, 4, 5, 6}
# 交集
print(s1.intersection(s2)) # {3, 4}
print(s2.intersection(s1)) # {3, 4}
# 差集
print(s1.difference(s2)) # {1, 2}
print(s2.difference(s1)) # {5, 6}
print(s1.symmetric_difference(s2)) # {1, 2, 5, 6}
print(s2.symmetric_difference(s1)) # {1, 2, 5, 6}
# 并集
print(s1.union(s2)) # {1, 2, 3, 4, 5, 6}
print(s2.union(s1)) # {1, 2, 3, 4, 5, 6}
商品推荐系统案例:
集合的一个应用场景案例:商品推荐系统:通过交集对比相似度推荐商品。
要注意声明空集合时,不可以直接写{},否则默认为字典,应该a=set()进行声明。
peiQi_hobby = {"螺狮粉", "臭豆腐", "榴莲", "apple"}
alex_hobby = {"螺狮粉", "臭豆腐", "榴莲", "💩", 'pizza'}
yuan_hobby = {"pizza", "salad", "ice cream", "臭豆腐", "榴莲", }
hobbies = [peiQi_hobby, yuan_hobby, alex_hobby]
# 给peiQi推荐商品:
# 版本1:
hobbies.remove(peiQi_hobby)
peiQi_list = []
for hobby in hobbies:
if len(peiQi_hobby.intersection(hobby)) >= 2:
# print(list(hobby - peiQi_hobby))
peiQi_list.extend(list(hobby - peiQi_hobby))
print(list(set(peiQi_list)))
# 版本2:
hobbies.remove(peiQi_hobby)
# peiQi_set = {}
# print(type(peiQi_set))
peiQi_set = set()
for hobby in hobbies:
if len(peiQi_hobby.intersection(hobby)) >= 2:
# print(hobby - peiQi_hobby)
peiQi_set.update(hobby - peiQi_hobby)
print(list(peiQi_set))
若有错误与不足请指出,关注DPT一起进步吧!!!