文章目录
一、文本搜索工具–grep
1、简介
grep(Global search REgular expression and Print out the line.)是一种强大的文本搜索工具,它能使用特定模式匹配(包括正则表达式)搜索文本,并默认输出匹配行。Unix的grep家族包括grep、egrep和fgrep。Windows系统下类似命令FINDSTR。
从grep的全称中可以了解到,grep是一个可以利用""正则表达式"进行"全局搜索"的工具,grep会在文本文件中按照指定的正则进行全局搜索,并将搜索出的行打印出来。
2、工作原理
-
grep读取输入数据,这可以是来自一个或多个文件的内容,也可以是管道(stdin)传入的数据。 - 它根据提供的模式(pattern),这个模式可以是简单字符串或复杂的正则表达式,逐行匹配文本。
- 当一行文本与模式匹配时,该行会被输出到标准输出(stdout),默认情况下不改变原始文件。
- 如果没有找到匹配项,
grep可能不会输出任何内容,具体行为取决于使用的选项。
3、语法格式
grep [选项] PATTERN [文件列表]
- grep:命令名称,用于搜索含有特定模式的文件内容。
-
[选项]:可选参数,用来控制搜索的方式、输出格式等。常见的选项包括
-i(忽略大小写)、-v(反向匹配)、-n(显示行号)、-r或-R(递归搜索)、-w(精确单词匹配)等。 - PATTERN:必填项,表示要搜索的模式或正则表达式。这可以是一个简单的文本字符串或复杂的正则表达式,用于匹配文件中的内容。
-
[文件列表]:可选,指定要搜索的一个或多个文件名。如果不提供文件名,
grep默认从标准输入(stdin)读取数据,这意味着你可以通过管道(|)将其他命令的输出传递给grep进行搜索。
4、选项介绍
| 选项 | 描述 |
|---|---|
-i |
忽略大小写进行匹配。 |
-v |
反转匹配,输出不匹配指定模式的行。 |
-n |
在每行匹配之前显示行号。 |
-c |
计算匹配行的总数,而不是打印匹配行。 |
-o |
只打印匹配的内容 |
-l |
只列出包含匹配项的文件名,对于每个匹配的文件只输出一次。 |
-L |
列出不包含匹配项的文件名。 |
-B |
打印匹配的前几行 |
-A |
打印匹配的后几行 |
-C |
打印匹配的前后几行 |
-w |
匹配整个单词,即模式必须与整个单词相匹配,而不是单词的一部分。 |
-r 或 -R
|
递归搜索指定目录下的所有文件。 |
-E |
使用扩展正则表达式(ERE)。 |
-F |
将模式作为固定字符串对待,不解释为正则表达式。 |
-q |
静默模式,不输出任何内容到屏幕,仅返回退出状态码。常用于脚本中判断是否存在匹配。 |
-e |
多点操作 |
5、实例测试
测试文档
test
#!/bin/bash
set -euo pipefail
NGINX_VERSION="1.18.0"
INSTALL_DIR="/apps/NGINX"
#echo "开始安装 Nginx $NGINX_VERSION..."
#echo "1. 安装依赖包..."
if yum list installed $PACKAGE_LIST &> /dev/null; then
echo "依赖包已安装。"
else
echo "正在安装依赖包:$PACKAGE_LIST"
yum -y install $PACKAGE_LIST > /dev/null
echo "依赖包安$装完成。"
echo "2. 创建非登录用户 NgInX..."
if id -u NgInX &> /dev/null; then
echo "NgInX 源码下载完成。"
echo "5. 设置#目录#权限..."
chown -R nginx.NGINX "$INSTALL_DIR" > /dev/null
echo "6. 创建符号链#接..."
ln -s "$INSTALL_DIR/sbin/NgInX" /usr/bin/ > /dev/null
echo "符号链$接创建完成$。"
[Install]
[install]
sed -i '/^#pid.*$/a pid /apps/nginx/run/nginx.pid;' /apps/NGINX/conf/NgInX.conf > /dev/null
echo "NgInX 安$装完成。"
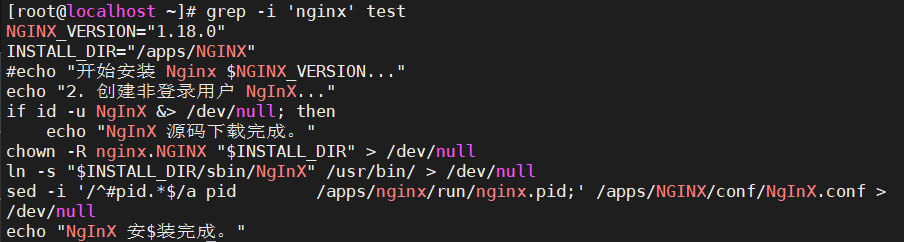
5.1、-i选项
打印出所有的
nginx,无论大小写
grep -i 'nginx' test
5.2、-v选项
打印出所有不包含
null的行
grep -v 'echo' test

5.3、-n选项
打印所有不包含
nginx大小写,并且显示所在行
grep -inv 'nginx' test

5.4、-c选项
打印所有不包含
echo大小写,并且计算匹配的行的总数
grep -ivc 'echo' test

5.5、-o选项
只打印匹配到的
NgInX字符串
grep -o 'NgInX' test

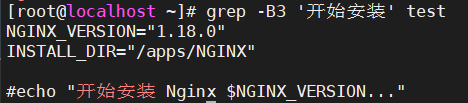
5.6、-B选项
打印匹配
开始安装的前三行
grep -B3 '开始安装' test
5.7、-A选项
打印匹配
开始安装的后三行
grep -A3 '开始安装' test

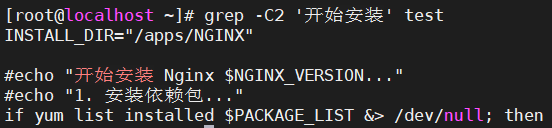
5.8、-C选项
打印匹配
开始安装的前后两行
grep -C2 '开始安装' test
5.9、-w选项
打印完全匹配
NgInX字符串的行
grep -w 'NgInX' test
5.10、-E选项
过滤
test文件中所有的空行、注释#
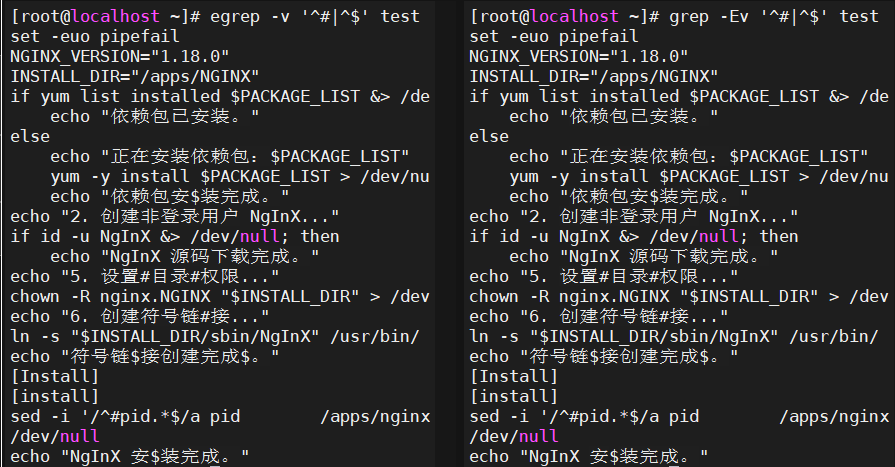
egrep -v '^#|^$' test
grep -Ev '^#|^$' test
5.11、-e选项
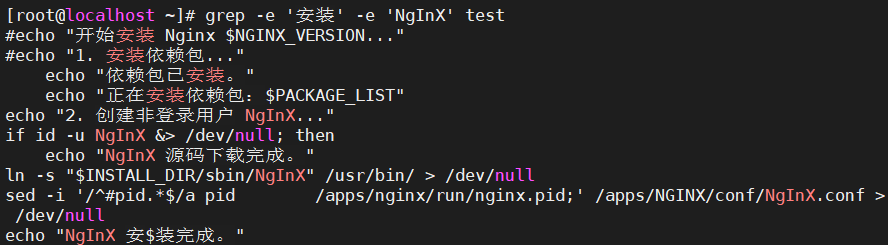
同时查找包含"安装"和"NgInX"的行
grep -e '安装' -e 'NgInX' test
二、流编辑器–sed
sed操作文件前记得备份源文件,或者先使用默认的-e参数操作
1、简介
sed全称为Stream EDitor,行编辑器,同时也是一种流编辑器。是一个强大的非交互式命令行工具,主要用于自动地对文本文件或者输入流进行基于模式的查找、替换、删除、插入等操作。
2、工作原理
-
读取行:
sed逐行读取输入文件(或从标准输入接收到的数据)。每次读取一行内容,不会一次性将整个文件加载到内存中,这使得sed在处理大文件时效率很高。 -
模式空间:读取的每一行文本会被放置到一个称为“模式空间”(pattern space)的缓冲区中。模式空间是
sed进行文本处理的主要场所,所有的编辑命令都在这里对文本行进行操作。 -
执行命令:根据提供的命令脚本,
sed会对模式空间中的文本行进行匹配、替换、删除等操作。这些命令可以是简单的正则表达式匹配,也可以是复杂的逻辑判断和操作序列。 -
输出处理结果:处理完一行后,
sed会将模式空间中的内容输出到屏幕(或重定向的输出文件),然后清空模式空间(除非使用特殊命令如H、G、N、D等操作了保留空间hold space),准备处理下一行。这个过程重复,直到所有行都被处理完毕。 -
保留空间:除了模式空间,
sed还有一个称为“保留空间”(hold space)的缓冲区,它可以用来临时存储数据,实现更复杂的文本处理逻辑,比如在多行间传递数据。 -
非破坏性处理:默认情况下,
sed不对原文件进行修改,而是将处理后的结果输出到标准输出。如果你想修改原文件,可以使用-i选项进行就地编辑。 -
退出处理:当文件的所有行都被成功处理并输出后,
sed完成其任务并退出。
3、语法格式
-
sed的命令格式:
-
sed [option] 'sed command' 输入文件
-
-
sed的脚本格式
-
sed [option] ‐f 'sed script' 输入文件
-
4、选项介绍
| 选项 | 描述 |
|---|---|
-n |
抑制自动打印模式空间的内容,仅打印通过命令显式指定的内容。 |
-e |
添加脚本到执行的命令列表中,允许多个-e选项串联多个脚本。 |
-f |
从指定的脚本文件中读取命令并执行。 |
--follow-symlinks |
处理文件时跟随符号链接。 |
-i |
直接修改文件内容。 |
-c |
在使用-i模式时,使用复制而非重命名来处理文件。 |
-b |
对于某些平台,打开文件时使用二进制模式,但实际上不起作用。 |
-l N |
为l命令指定期望的行宽包装长度。 |
--posix |
禁用所有GNU扩展,使用POSIX兼容模式。 |
-r |
使用扩展正则表达式。 |
-s |
将每个文件视为独立的,而非一个连续的长流。 |
-u |
减少从输入文件加载的数据量,并更频繁地刷新输出缓冲区,适合处理大文件或需要即时输出的情况。 |
-z |
使用NUL字符而不是换行符作为行分隔符。 |
--help |
显示帮助信息并退出。 |
--version |
输出版本信息并退出。 |
5、动作介绍
| 动作 | 描述 |
|---|---|
= |
打印当前处理的行号。 |
a \text |
在当前行之后追加文本text,文本中的换行需用\转义。 |
i \text |
在当前行之前插入文本text,文本中的换行需用\转义。 |
q [exit-code] |
立即退出sed脚本,可选指定退出代码。 |
Q [exit-code] |
GNU扩展,立即退出sed脚本,不处理剩余输入,可选指定退出代码。 |
r filename |
读取文件filename的内容并追加到模式空间处理后的输出中。 |
R filename |
GNU扩展,读取文件filename的一行并追加到模式空间处理后的输出中,每次调用读取一行。 |
{ ... } |
定义一个命令块,其中可以包含多条sed命令。 |
b label |
无条件跳转到标签label处,或如果没有指定标签,则跳到脚本末尾。 |
c \text |
用text替换当前模式空间中的行,文本中的换行需用\转义。 |
d |
删除模式空间中的当前行,然后开始处理下一行。 |
D |
如果模式空间中没有换行符,就像执行了d命令;如果有换行符,删除至第一个换行符前的内容并重新开始处理。 |
h H |
复制模式空间内容到保持空间(h)或追加到保持空间(H)。 |
g G |
用保持空间的内容替换模式空间内容(g)或追加保持空间内容到模式空间(G)。 |
l |
以一种视觉上不易混淆的形式列出模式空间中的当前行。 |
l width |
GNU扩展,按指定宽度width折行显示模式空间中的当前行。 |
n N |
读取下一行到模式空间(n)或追加下一行到模式空间而不启动新循环(N)。 |
p |
打印当前模式空间的内容。 |
P |
打印模式空间中的内容直到第一个换行符。 |
s/regexp/replacement/ |
替换与正则表达式regexp匹配的部分为replacement,&在替换中表示匹配的文本,\1到\9表示捕获组。 |
t label |
如果最近的替换成功,则跳转到标签label。 |
T label |
GNU扩展,如果最近的替换未成功,则跳转到标签label。 |
w filename |
将模式空间的内容写入文件filename。 |
W filename |
GNU扩展,将模式空间的第一行写入文件filename。 |
x |
交换模式空间与保持空间的内容。 |
y/source/dest/ |
对模式空间中的字符进行转换,将source中每个字符转换为dest中对应位置的字符。 |
6、sed的增删改查
以下所有的命令皆不使用-i选项修改仅供展示
测试文档:
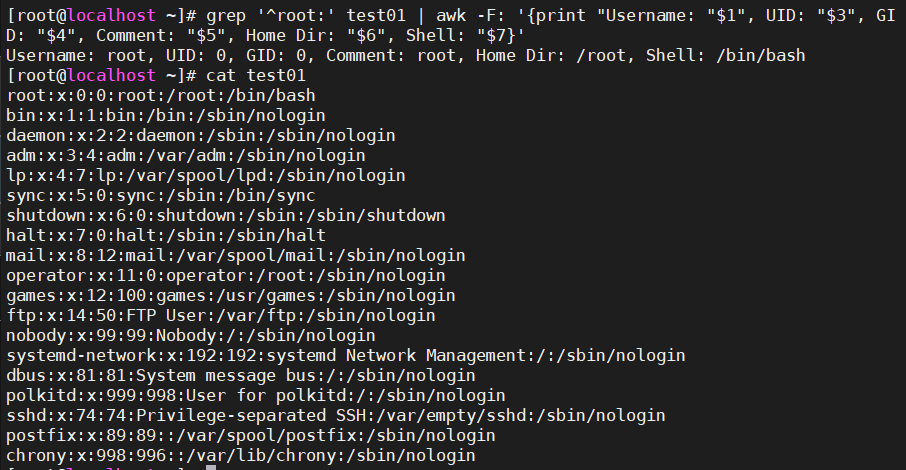
[root@localhost ~]# cat /etc/passwd > test01
[root@localhost ~]# cat test01
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
sync:x:5:0:sync:/sbin:/bin/sync
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
halt:x:7:0:halt:/sbin:/sbin/halt
mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
operator:x:11:0:operator:/root:/sbin/nologin
games:x:12:100:games:/usr/games:/sbin/nologin
ftp:x:14:50:FTP User:/var/ftp:/sbin/nologin
nobody:x:99:99:Nobody:/:/sbin/nologin
systemd-network:x:192:192:systemd Network Management:/:/sbin/nologin
dbus:x:81:81:System message bus:/:/sbin/nologin
polkitd:x:999:998:User for polkitd:/:/sbin/nologin
sshd:x:74:74:Privilege-separated SSH:/var/empty/sshd:/sbin/nologin
postfix:x:89:89::/var/spool/postfix:/sbin/nologin
chrony:x:998:996::/var/lib/chrony:/sbin/nologin
6.1、增
“a”:apend,追加,追加文本到指定行后。
“i”:insert,插入,插入文本到指定行前。
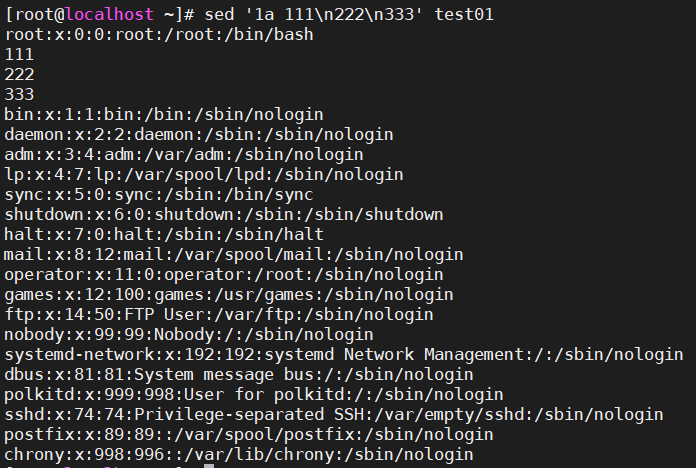
6.1.1、在test01文件的第一行后面追加3行数字
-
sed '1a 111\n222\n333' test01 -
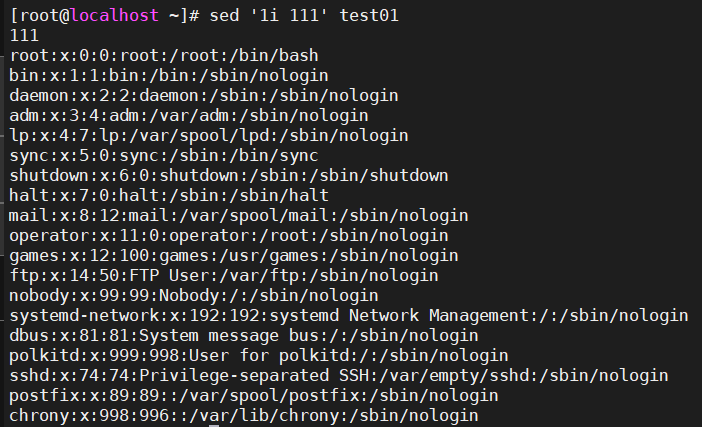
6.1.2、在行首添加一行数字
-
sed '1i 111' test01 -
6.2、删
“d”:delete,删除文本
6.2.1、删除第一行
-
nl test01 | sed '1d' -
6.2.2、删除2-10行
-
nl test01 | sed '2,10d' -
6.2.3、删除全文
-
sed 'd' test01
6.2.4、删除匹配到/sbin/nologin的行
-
sed '/\/sbin\/nologin/d' test01 -
6.2.5、删除以bin开头的行
-
sed '/^bin/d' test01 -
6.2.6、删除第三行到末尾
-
nl test01 | sed '3,$d' -

6.2.7、删除第1-3行以外的行
-
nl test01 | sed '1,3!d' -

6.2.8、去除文件中的空行和注释行
-
sed -e '/^#/d' -e '/^$/d' test01
6.3、改
“c”:change,替换
6.3.1、将第一行替换为 hello sed
-
sed '1c hello sed' test01 -
6.4、文本替换
-
选项:
-
“s”: 这是sed中最常用的命令,代表替换(substitute)。当你希望在文件中查找并替换某些文本时,就会用到这个命令。例如,
s/old/new/表示将每一行中首次出现的"old"字符串替换为"new"。这里的"old"是你要查找的目标文本,而"new"是你希望替换成的新文本。 -
“g”: 这是一个修饰符,用于指示sed进行全局替换(global)。如果不加"g",sed只会在每行的第一个匹配处进行替换。加上"g"后,sed会在同一行内所有匹配到的目标内容都进行替换。所以,
s/old/new/g表示将每行中所有出现的"old"都替换为"new"。
-
“s”: 这是sed中最常用的命令,代表替换(substitute)。当你希望在文件中查找并替换某些文本时,就会用到这个命令。例如,
-
替换语法(-i选项慎用):
-
sed -i 's/目标内容/替换内容/g' file -
#本质上与上面的命令差不多,更改分隔符为#可以避免转义的复杂性,使命令更易读 sed -i '#/目标内容#替换内容/g' file
-
6.4.1、将所有的nologin替换为login
-
sed 's/nologin/login/g' test01 -
6.4.2、将所有的/sbin/nologin 替换为/bin/login
-
sed '/\/sbin\/nologin/s#/sbin\/nologin#/bin/login#g' test01 -
6.4.3、匹配以mail开头的行,将该行所有的mail替换为gmail
-
sed '/^mail/{s#mail#gmail#g}' test01 -
6.5、查
“p”:print,打印,输出指定内容
配合
-n取消默认输出
6.5.1、显示第二行(包括模式空间文件)
-
sed '2p' test01 -
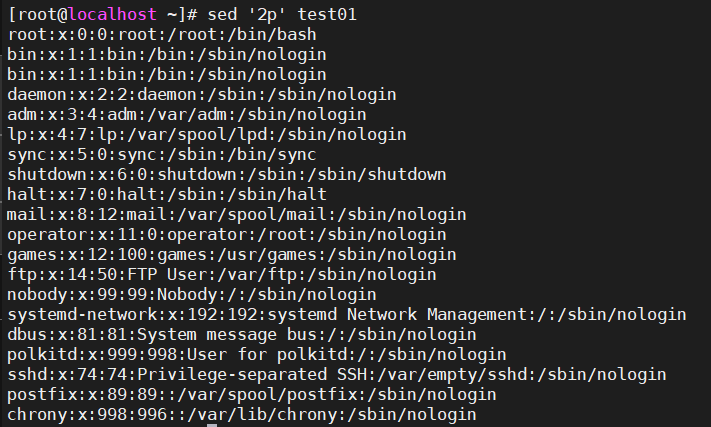
6.5.2、只显示第二行
-
sed -n '2p' test01 -

三、文本处理工具–awk
1、简介
awk不仅仅是 linux系统中的一个命令,而且是一种编程语言,可以用来处理数据和生成报告(excel)。处理的数据可以是一个或多个文件,可以是来自标准输入,也可以通过管道获取标准输入,awk可以在命令行上直接编辑命令进行操作,也可以编写成awk程序来进行更为复杂的运用。
2、工作原理
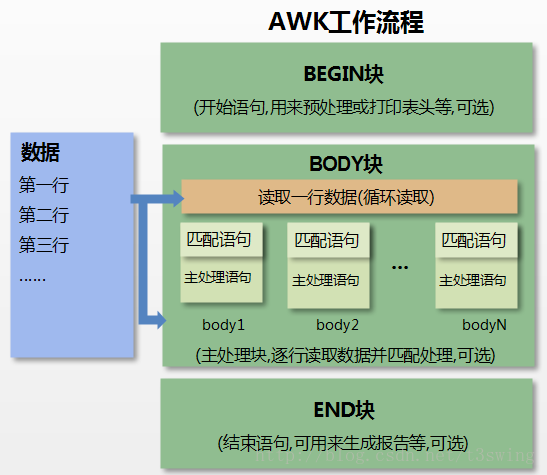
- 1、通过关键字 BEGIN 执行 BEGIN 块的内容,即 BEGIN 后花括号 {} 的内容。
- 2、完成 BEGIN 块的执行,开始执行body块。
- 3、读入有 \n 换行符分割的记录。
- 4、将记录按指定的域分隔符划分域,填充域,$0 则表示所有域(即一行内容), 1 ∗ ∗ 表示第一个域, ∗ ∗ 1** 表示第一个域,** 1∗∗表示第一个域,∗∗n 表示第 n 个域。
- 5、依次执行各 BODY 块,pattern 部分匹配该行内容成功后,才会执行 awk-commands 的内容。
- 6、循环读取并执行各行直到文件结束,完成body块执行。
- 7、开始 END 块执行,END 块可以输出最终结果。
3、语法格式
- awk指令是由模式,动作,或者模式和动作的组合组成。
- 模式即pattern,可以类似理解成sed的模式匹配,可以由表达式组成,也可以是两个正斜杠之间的正则表达式。比如NR==1,这就是模式,可以把他理解为一个条件。
- 动作即action,是由在大括号里面的一条或多条语句组成,语句之间使用分号隔开。
awk [options] 'pattern {action}' file
awk处理的内容可以来自标准输入(<) ,一个或多个文件或者管道


4、选项介绍
| 选项 | 描述 |
|---|---|
-b, --characters-as-bytes
|
将所有输入数据视为单字节字符,忽略多字节字符处理的locale信息。 |
-c, --traditional
|
运行于兼容模式,gawk表现得与UNIX awk一致,不识别GNU特有的扩展。 |
-C, --copyright
|
输出GNU版权信息并成功退出。 |
-d[file], --dump-variables[=file]
|
输出所有全局变量的排序列表及其类型、最终值至指定文件或默认的awkvars.out。 |
-e program-text, --source program-text
|
使用命令行提供的program-text作为AWK程序源代码。 |
-E file, --exec file
|
类似于-f,但作为最后一个处理的选项,适合用于避免CGI应用中URL传递选项或源代码。禁用命令行变量赋值。 |
-f program-file, --file program-file
|
从指定文件读取AWK程序源码而非命令行参数。可多次使用。 |
-F fs, --field-separator fs
|
使用fs作为输入字段分隔符。 |
-g, --gen-pot
|
扫描并解析AWK程序,生成包含所有可本地化字符串的GNU .pot文件。程序本身不执行。 |
-h, --help
|
输出可用选项的简短摘要后立即退出。 |
-L [value], --lint[=value]
|
提供关于可疑或非便携构造的警告,可选fatal使警告成为错误,invalid仅报告实际无效项。 |
-n, --non-decimal-data
|
识别输入数据中的八进制和十六进制值,需谨慎使用。 |
-N, --use-lc-numeric
|
强制gawk在解析输入数据时使用locale的十进制点字符。 |
-o output-file |
指定输出的文件名 |
-O, --optimize
|
启用程序内部表示的优化,当前包括常量折叠。 |
-p[prof_file], --profile[=prof_file]
|
将性能分析数据发送到指定文件,默认为awkprof.out。 |
-P, --posix
|
启用兼容模式,并施加额外限制以符合POSIX标准。 |
-r, --re-interval
|
允许在正则表达式匹配中使用区间表达式。 |
-R, --command file
|
(Dgawk专用) 从文件读取存储的调试器命令。 |
-S, --sandbox
|
在沙盒模式下运行gawk,禁用系统调用、getline输入重定向、print/printf输出重定向等。 |
-t, --lint-old
|
提供关于不兼容原始Unix awk结构的警告。 |
-V, --version
|
输出gawk的版本信息。 |
-- |
标志选项结束,允许后续参数以"-"开头,符合POSIX约定。 |
-v var=val, --assign var=val
|
在程序执行前将变量var赋值为val。 |
5、awk运算符
5.1、算数运算符
| 算术运算符 | 描述 |
|---|---|
| + | 加法 |
| - | 减法 |
| * | 乘法 |
| / | 除法 |
| % | 取模(求余数) |
| += | 加等于 |
| -= | 减等于 |
| *= | 乘等于 |
| /= | 除等于 |
| %= | 取模等于 |
| ** | 幂运算(乘方) |
5.2、关系运算符
| 关系运算符 | 描述 |
|---|---|
| == | 等于 |
| != | 不等于 |
| < | 小于 |
| > | 大于 |
| <= | 小于等于 |
| >= | 大于等于 |
5.3、逻辑运算符
| 逻辑运算符 | 描述 |
|---|---|
| && | 逻辑与 |
| || | 逻辑或 |
| ! | 逻辑非 |
5.4、赋值运算符
| 赋值运算符 | 描述 |
|---|---|
| = | 简单赋值 |
| += | 加法赋值 |
| -= | 减法赋值 |
| *= | 乘法赋值 |
| /= | 除法赋值 |
| %= | 取模赋值 |
| **= | 幂赋值(乘方赋值) |
5.5、特殊运算符
| 特殊运算符 | 描述 |
|---|---|
| ? : | 条件运算符(三目运算符) |
| ~ | 匹配正则表达式(模式匹配) |
| !~ | 不匹配正则表达式 |
6、awk常用的内置变量
| 内置变量 | 描述 |
|---|---|
| $0 | 当前记录 |
| \ 1 − 1- 1−n | 当前记录的第n个字段 |
| ARGC | 命令行参数的数量,不包括awk命令本身 |
| ARGV | 包含命令行参数的数组 |
| FILENAME | 当前输入文件的名称 |
| FNR | 当前记录号,在处理多个文件时,对于每个文件单独计数 |
| NR | 总的输入记录号,从1开始,跨多个文件累加 |
| NF | 当前行中的字段数,即分割后数组的元素数量 |
| FS | 输入字段分隔符,默认为空格或制表符 |
| OFS | 输出字段分隔符,默认为空格或制表符,用于打印时分隔字段 |
| RS | 输入记录分隔符,默认为换行符,用于界定不同的记录 |
| ORS | 输出记录分隔符,默认为换行符,用于打印时分隔记录 |
| RSTART | 匹配字符串的起始位置,由match函数设置 |
| RLENGTH | 匹配字符串的长度,由match函数设置 |
| ENVIRON | 环境变量关联的关联数组,可以访问外部环境变量 |
7、awk的正则
| 正则表达式 | 展示 | 功能 | 解释及举例 |
|---|---|---|---|
| . | 点 | 匹配任意单个字符(不包括换行符) |
/./ 匹配任何单字符的行,如 “a”, “b”, “1”, “!” 等。 |
| ^ | 脱字符 | 匹配字符串的开始 |
/^Hello/ 匹配以 “Hello” 开头的行。 |
| $ | 美元符号 | 匹配字符串的结束 |
/world$/ 匹配以 “world” 结尾的行。 |
| [abc] | 字符集 | 匹配字符集中的任意一个字符 |
/[abc]/ 匹配含有 “a”、“b” 或 “c” 的行。 |
| [^abc] | 否定字符集 | 匹配不在字符集中的任意一个字符 |
/[^abc]/ 匹配不含 “a”、“b” 或 “c” 的行。 |
| [a-z] | 字符范围 | 匹配指定范围内的任意字符 |
/[a-z]/ 匹配小写字母。 |
| \d | 数字 | 匹配任何数字(等价于 [0-9]) |
/\\d+/ 匹配一个或多个连续数字。 |
| \s | 空白字符 | 匹配任何空白字符(空格、tab、换行等) |
/\\s+/ 匹配一个或多个空白字符。 |
| \w | 单词字符 | 匹配字母、数字或下划线(等价于 [a-zA-Z0-9_]) |
/\\w+/ 匹配一个或多个单词字符组成的字符串。 |
| \W | 非单词字符 | 匹配非单词字符(等价于 [^a-zA-Z0-9_]) |
/\\W+/ 匹配一个或多个非单词字符。 |
| * | 星号 | 重复前面的子表达式零次或多次 |
/a*b/ 匹配任意数量的 “a” 后跟一个 “b”,如 “b”, “ab”, “aab”, “aaab”。 |
| + | 加号 | 重复前面的子表达式一次或多次 |
/a+b/ 匹配至少一个 “a” 后跟一个 “b”,如 “ab”, “aab”, “aaab”。 |
| ? | 问号 | 重复前面的子表达式零次或一次 |
/a?b/ 匹配 “b” 或者 “ab”。 |
| {n} | 重复次数 | 重复前面的子表达式恰好n次 |
/a{2}/ 匹配 “aa”。 |
| {n,} | 至少重复n次 | 重复前面的子表达式至少n次 |
/a{2,}/ 匹配至少两个 “a” 如 “aa”, “aaa”, “aaaa” 等。 |
| {n,m} | 重复n到m次 | 重复前面的子表达式n到m次(包括n和m) |
/a{2,3}/ 匹配 “aa” 或 “aaa”。 |
| (…) | 分组 | 定义子表达式以便引用或重复 |
/(ab)+/ 匹配一个或多个 “ab” 连续出现,如 “ab”, “abab”, “ababab”。 |
| | | 或者 | 匹配两种或多种可能的模式之一 | 匹配左边或右边的子表达式之一 `/apache |
8、BEGIN和END模块
BEGIN只执行一次并且执行在主体代码块之前。
END只执行一次并且执行在主体代码块之后。
BEGIN可以抛开文件单独执行,结果类似于echo而END不可以。
BEGIN中没有文件的读取变量而END是有的。
但END中的$0是awk处理到最后的文本样式。
8.1、BEGIN模块
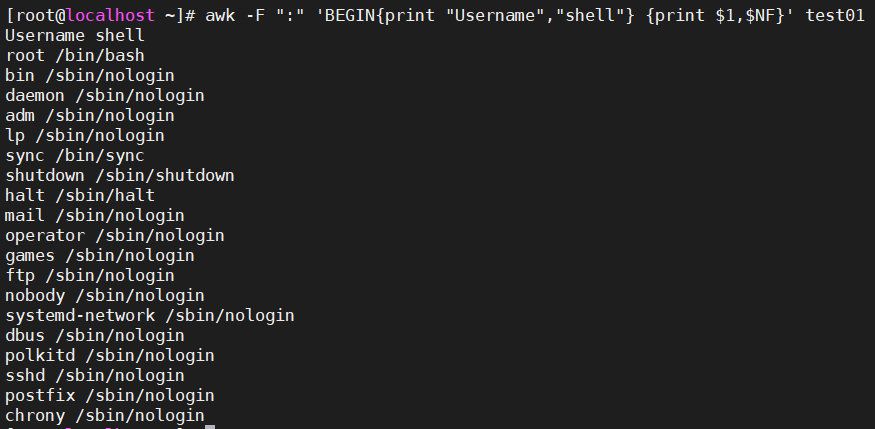
8.1.1、输出标题行Username shell,以及对应的用户和shell类型
awk -F ":" 'BEGIN{print "Username shell"} {print $1,$NF}' test01
8.2、END模块
8.2.1、打印对应的用户和shell类型,最后再打印end of file
awk -F ":" '{print $1,$NF} END{print "out of file"}' test01
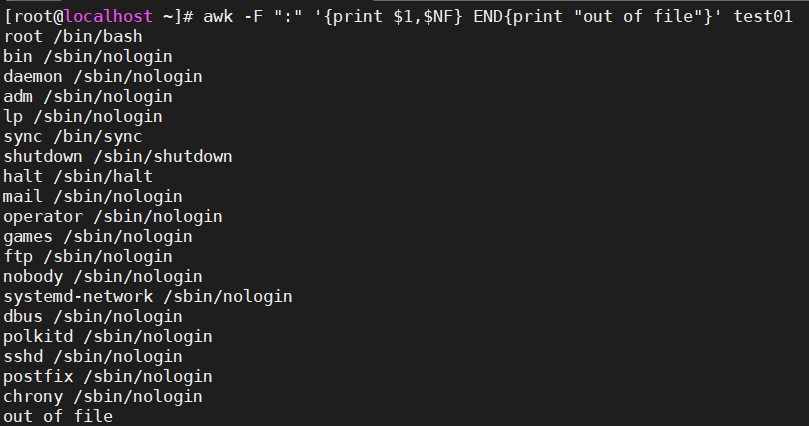
9、实例测试
测试文档依然是test01
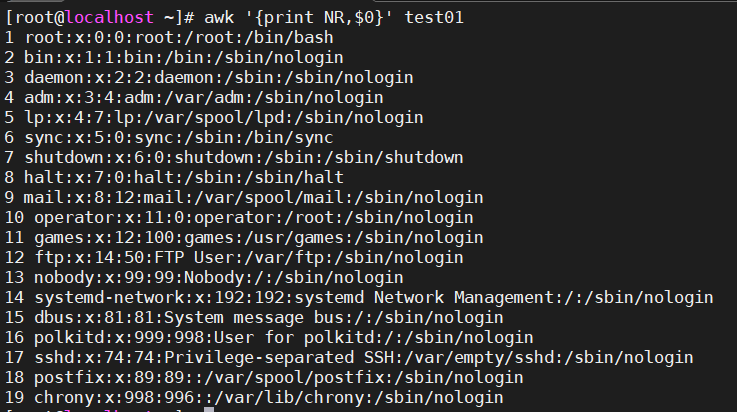
9.1、打印test01内容并附带行号
awk '{print NR,$0}' test01
9.2、只打印第二行
awk 'NR==2{print}' test01

9.3、打印二到四行
awk 'NR>=2 && NR<=4{print}' test01
awk 'NR>1 && NR<5{print}' test01

9.4、只打印第二行和第四行
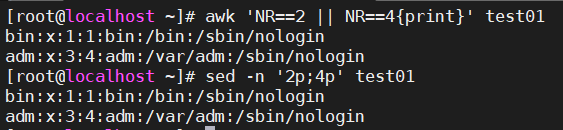
awk 'NR==2 || NR==4{print}' test01
9.5、匹配以root开头的行
awk '/^root/{print}' test01

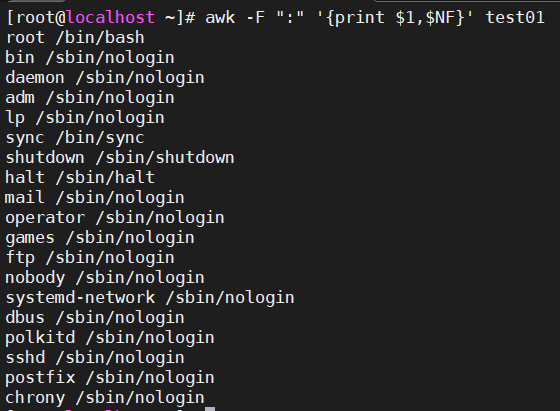
9.6、打印test01文件中用户和对应的shell类型
awk -F ":" '{print $1,$NF}' test01
四、综合案例
1、查找用户名为root的行,并打印其所有的字段
grep '^root:' test01 | awk -F: '{print "Username: "$1", UID: "$3", GID: "$4", Comment: "$5", Home Dir: "$6", Shell: "$7}'
2、统计不同shell类型的用户数量
grep -E '/bin/bash$|/sbin/nologin$' test01 | awk -F: '{print $7}' | sort | uniq -c

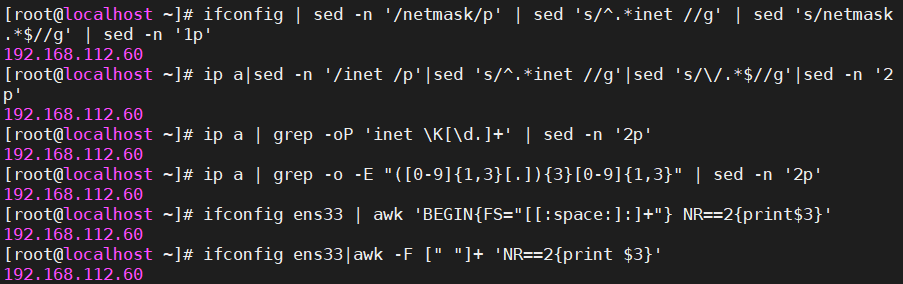
3、获取系统的ip地址
ifconfig | sed -n '/netmask/p' | sed 's/^.*inet //g' | sed 's/netmask.*$//g' | sed -n '1p'
ip a|sed -n '/inet /p'|sed 's/^.*inet //g'|sed 's/\/.*$//g'|sed -n '2p'
ip a | grep -oP 'inet \K[\d.]+' | sed -n '2p'
ip a | grep -o -E "([0-9]{1,3}[.]){3}[0-9]{1,3}" | sed -n '2p'
ifconfig ens33|awk -F [" "]+ 'NR==2{print $3}'
ifconfig ens33 | awk 'BEGIN{FS="[[:space:]:]+"} NR==2{print$3}'