文章目录
资源:
(1)训练ui kohya_ss:
https://github.com/bmaltais/kohya_ss
(2)kohya_ss 的docker+ 其他docker
https://github.com/ashleykleynhans/stable-diffusion-docker
环境
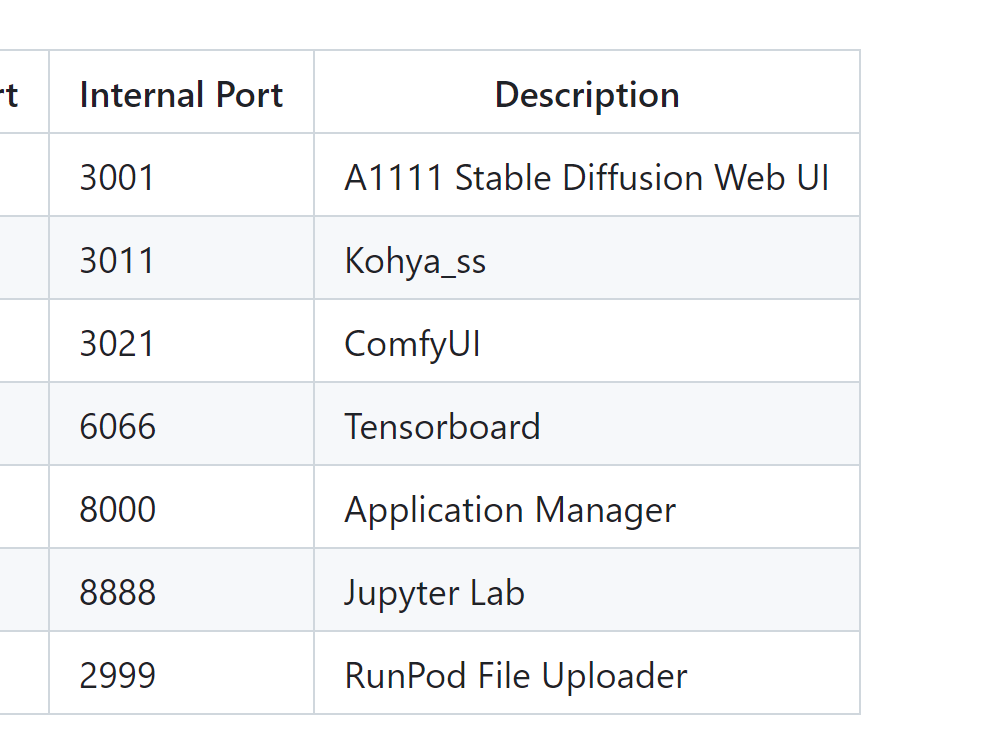
需要等待环境构建,有点慢,启动起来后,访问 http://home.elvisiky.com:7861/。
docker run -d \
--gpus all \
-v /workspace \
-p 7860:3001 \
-p 7861:3011 \
-p 7862:3021 \
-p 7863:6066 \
-p 7864:8000 \
-p 7866:8888 \
-p 7867:2999 \
-e JUPYTER_PASSWORD=Jup1t3R! \
-e ENABLE_TENSORBOARD=1 \
ashleykza/stable-diffusion-webui:latest
Application Log file
Stable Diffusion Web UI /workspace/logs/webui.log
Kohya SS /workspace/logs/kohya_ss.log
ComfyUI /workspace/logs/comfyui.log
数据
数量几十张即可
分辨率适中,勿收集极小图像
数据集需要统一的主题和风格的内容,图片不宜有复杂背景以及其他无关人物
图像人物尽量多角度,多表情,多姿势
凸显面部的图像数量比例稍微大点,全身照的图片数量比例稍微小点
堆糖:https://www.duitang.com
花瓣:https://huaban.com
pinterest:https://www.pinterest.com
通常,准备数百张图像是理想的(图像数量太少会导致类别图像无法被归纳,特征也不会被学习)。
如果要使用生成的图像,生成图像的大小通常应与训练分辨率(更准确地说,是bucket的分辨率,见下文)相匹配。
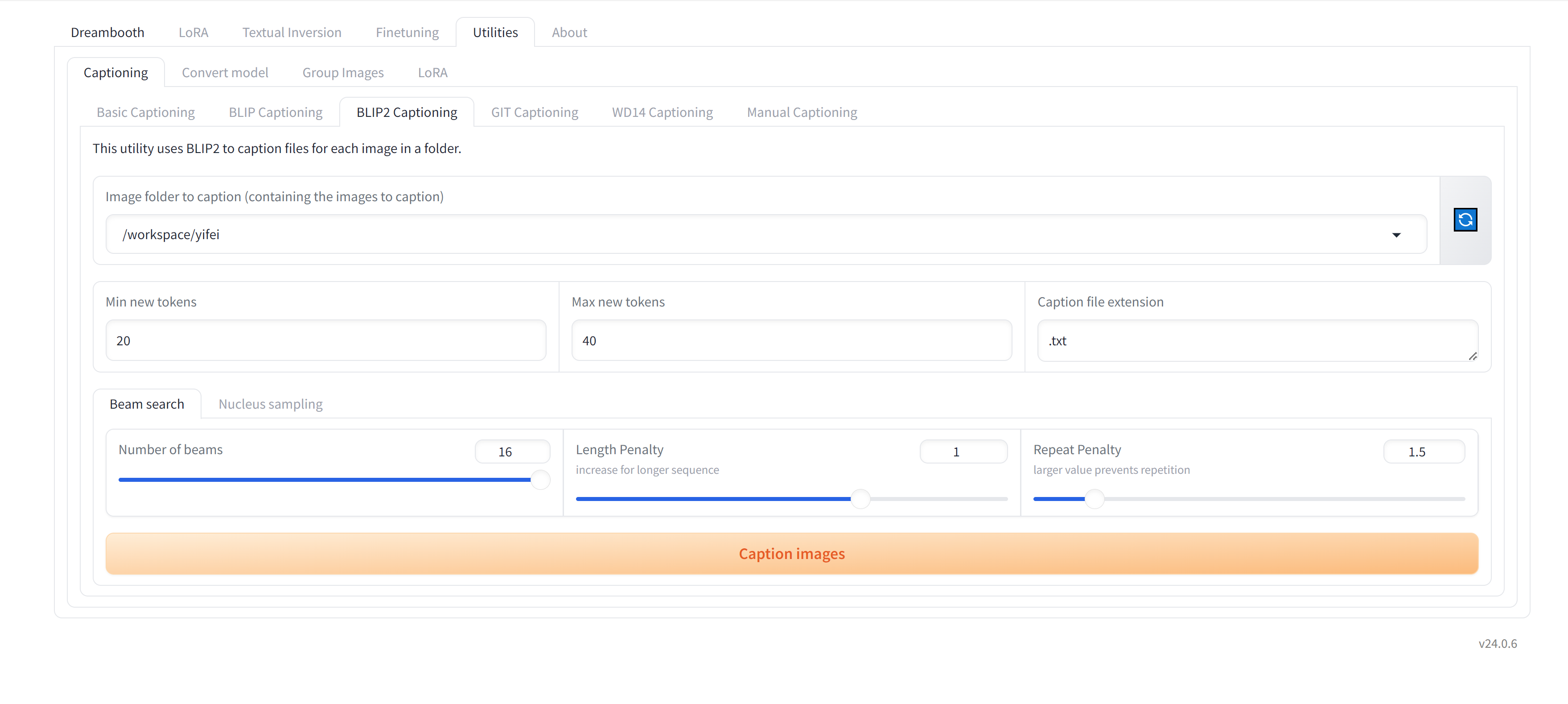
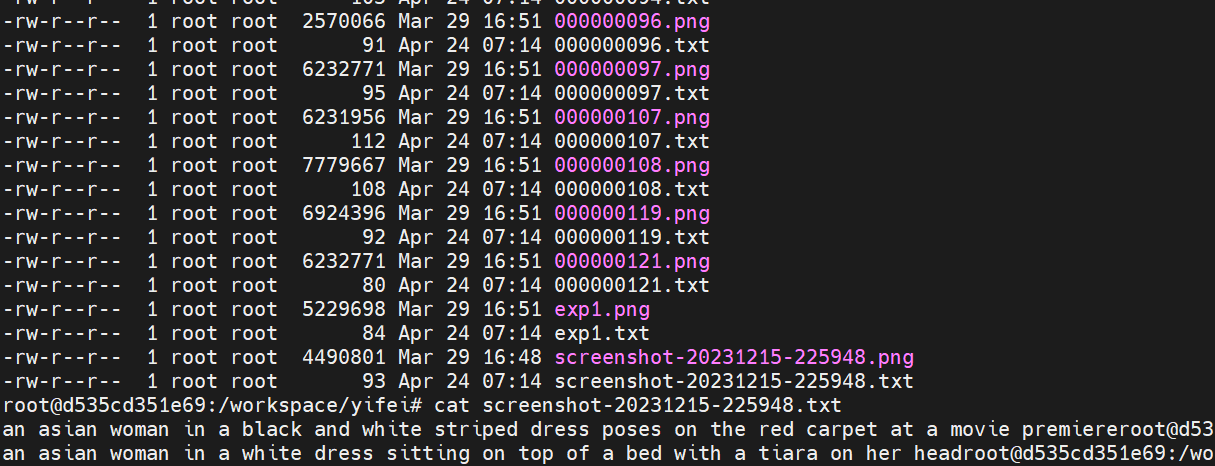
自动标注
kohya_ss BLIP2
“/workspace/kohya_ss/venv/bin/python”
“/workspace/kohya_ss/sd-scripts/finetune/make_captions.
py” --batch_size 1 --num_beams 1 --top_p 0.9
–max_length 75 --min_length 5 --beam_search
–caption_extension .txt “/workspace/maonv”
–caption_weights
kohya_ss WD14
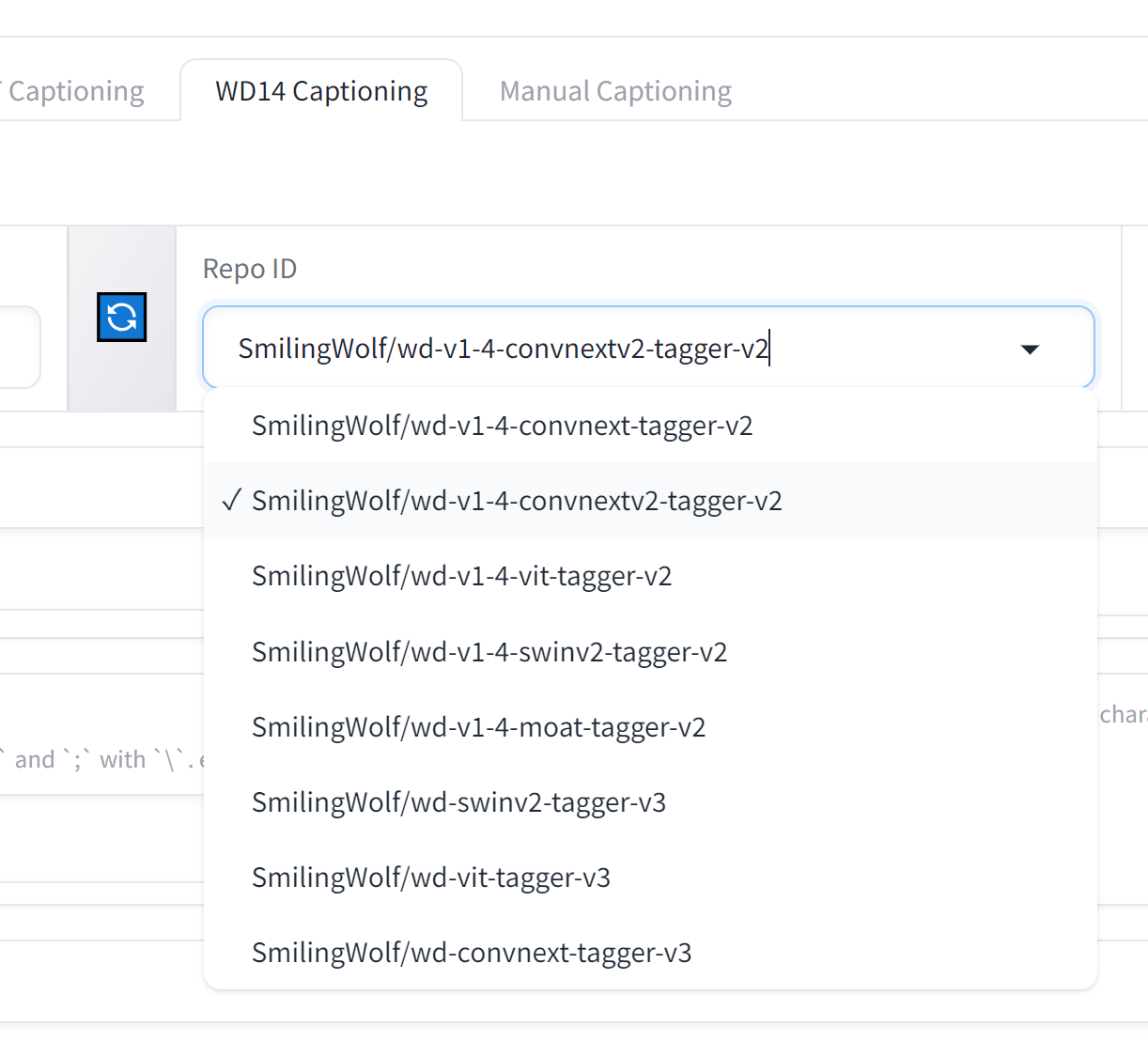
"/workspace/kohya_ss/venv/bin/python"
"/workspace/kohya_ss/sd-scripts/finetune/make_captions_
by_git.py" --batch_size 1 --max_data_loader_n_workers 2
--max_length 75 --caption_extension .txt
"/workspace/yifei" with shell=True
后续
遇到了一个文件夹命名的问题,后续直接用秋叶包,不再用kohya_ss。
https://github.com/kohya-ss/sd-scripts/issues/1294