需求:
一张图片中有多个目标物体,将多个目标物体进行识别分割定位
import cv2
import numpy as np
def show_photo(name,picture):
cv2.imshow(name,picture)
cv2.waitKey(0)
cv2.destroyAllWindows()
img_path = r"test3.png"
img = cv2.imread(img_path)
show_photo("img",img)
height, width = img.shape[:2] # 得到行和列的长度
image = cv2.imread(img_path)
shape = image.shape
image_row = shape[0]
image_col = shape[1]
print(image_row,image_col)
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY) # 得到灰度图
#show_photo("gray",gray)
ret, binary = cv2.threshold(gray, 0, 255, cv2.THRESH_BINARY_INV | cv2.THRESH_OTSU)
show_photo("binary",binary) # 二值化
kernel = np.ones((3, 3), np.uint8)
img_dilate = cv2.dilate(binary, kernel, iterations = 5) # 膨胀
show_photo("img_dilate",img_dilate)
outImage, contours, hireachy = cv2.findContours(img_dilate, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE) # 找轮廓
draw_img = image.copy()
res = cv2.drawContours(draw_img,contours,-1,(0,0,255),2) # 绘制轮廓,一定要copy要不然会覆盖原图
show_photo('res',res)
draw_img1 = image.copy()
for cont in contours: # 绘制轮廓到原图上
x, y, w, h = cv2.boundingRect(cont)
cv2.rectangle(draw_img1, (x, y), (x+w, y+h), (255, 0, 0), 1,8)
print((x, y),(x+w, y+h))
show_photo('img_part',image[y:y+h,x:x+w]) # 截取每个物体所对应的ROI
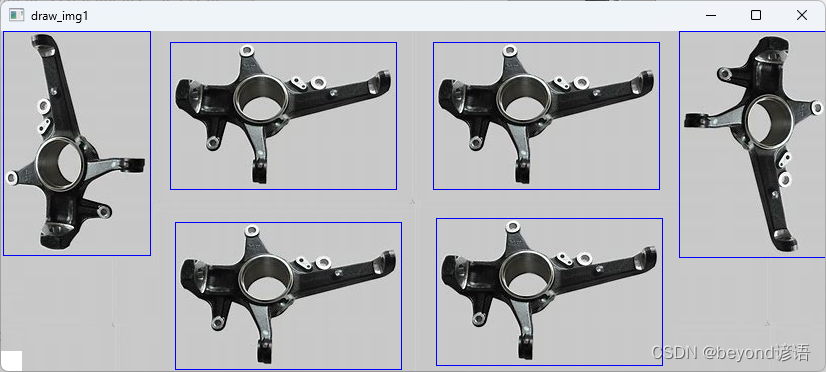
show_photo('draw_img1',draw_img1)
运行效果:
原图

二值图

膨胀

canny找轮廓

挨个分割






分割整体