第1关:个人数据脱敏
任务描述
随着计算机与互联网技术快速发展,电话号码,家庭住址,姓名等个人隐私信息被泄露的风险也越来越高。
数据脱敏是指对敏感信息进行变形处理,比如将电话号码 13000000000 中的四位用*来代替,变为 130****0000
本题要求从输入的学生信息中将手机号码,姓名,学号数据进行脱敏处理。
处理规则如下:
学号(13 位或 14 位数串):第 5-11 位修改为* 如 0121134567801 修改为 0121*******01
姓名:第2位修改为*,如贾诩修改为贾*
电话号码(11位数串):第4-7位修改为* 如13000000000中修改为130****0000
输入格式
第一行输入 n,代表 n 个同学的信息
依次输入 n 行学生信息数据,每行输入一名学生的学号、姓名、电话号码,数据间以空格间隔
输出格式
将学生数据脱敏后的信息保存到二维列表中,并输出这个二维表。
如果 n 不是正整数,输出ERROR。(本题保证 n 是整数,且信息完整)
示例 1
输入: 2 01211345678011 张辽 14457673508 01211345678012 徐晃 18514863218 输出:[['0121*******011', '张*', '144****3508'], ['0121*******012', '徐*', '185****3218']]
def DataMasking():
mask = [input().split() for i in range(n)]
for item in mask:
item[0] = item[0][:4] + '*' * 7 + item[0][11:]
item[1] = item[1][0] + '*' + item[1][2:]
item[2] = item[2][:3] + '*' * 4 + item[2][7:]
return mask
if __name__ == '__main__':
n = int(input())
print('ERROR') if n <= 0 else print(DataMasking())第2关:年龄最大的人
任务描述
给定一批人的出生日期,请找出其中年龄最大的,并输出他的出生日期。(同年同月同日出生的人才一样大)
日期格式为yyyy-mm-dd:
四位数 y 表示年份(不小于1000);
两位数 m 表示月份;
两位数 d 表示日期;
年、月、日之间以一个连字符-分隔。
输入:
每行输入一个日期,输入回车时结束输入 提示:判断输入是否为空字符串,为真则结束输入 本题保证所有输入均为标准格式yyyy-mm-dd
输出:
输出最大的人的出生日期,格式同输入。
输入输出示例
输入: 2008-08-08 1953-06-15 1949-10-01 1926-08-18
输出: 1926-08-18
ls=[]
while 1:
x = input()
if x=='':
break
ls.append(x)
ls.sort()
print(ls[0])第3关:绝对值排序
任务描述
读入一个列表,按照绝对值从大到小排序,如果绝对值相同,则正数在前面。
提示:使用list1=eval(input())直接读入一个列表。
输入格式
题目的输入为一行,是一个元素类型都是数值的列表, 如:[3,-4,2,4]
输出格式
输出为一行,是按照绝对值从大到小排序后的列表里的元素,元素之间用一个英文半角逗号分隔,如: 4,-4,3,2
示例1
输入:[3,-4,2,4] 输出:4,-4,3,2
示例2
输入:[5.2,3,4,6,-5.2]
输出:6,5.2,-5.2,4,3
ls = eval(input())
ls.sort(key=lambda x:(abs(x),x),reverse=True)
print(','.join(map(str,ls)))第4关:奇偶插入
任务描述
给定一个无序的列表A,其中数据均为非负整数,其中奇数和偶数各占一半。
当列表A中的奇数和偶数个数相同时,将A中的奇数和偶数分别排序,并在放入列表时保持:当i是奇数时,A[i]为奇数,i为偶数时,A[i]为偶数
如果输入的数据不符合本题要求,输出ERROR
本题不考虑内存限制,可使用多个列表完成操作。
示例 1
输入: 4 5 7 2
输出: [2, 5, 4, 7]
示例 2
输入: 1 2 3
输出: ERROR
l=input().strip().split(" ")
l=list(map(int,l))
l.sort()
l1=[i for i in l if i%2==1]#l1存放奇数
l2=[i for i in l if i%2==0]#l1存放偶数
if len(l1)==len(l2):
l=[]
for i in range(len(l1)):
l.append(l2[i])
l.append(l1[i])
print(l)
else:
print("ERROR")第5关:程序员问卷调查
- 任务描述
题目文件中保存来自约60000条程序员的问卷调查记录(部分数据),数据来源:2020 Stack Overflow Developer Survey
调查问题为:
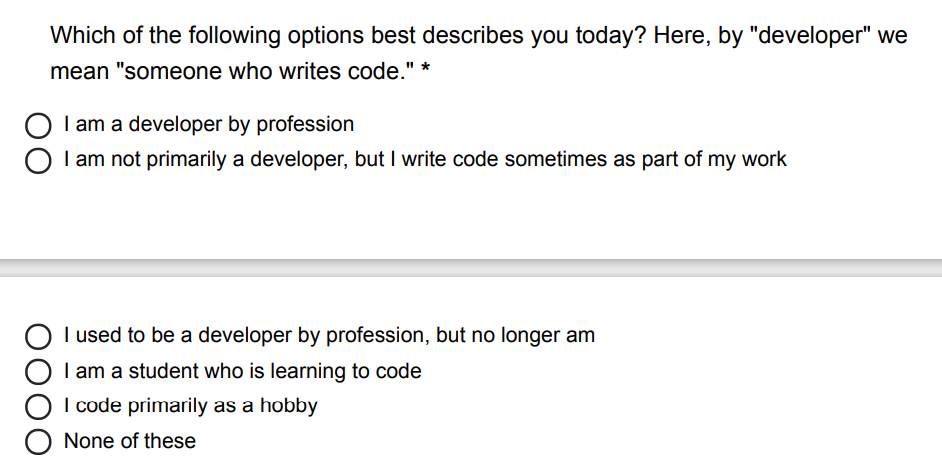
文件中数据格式为:
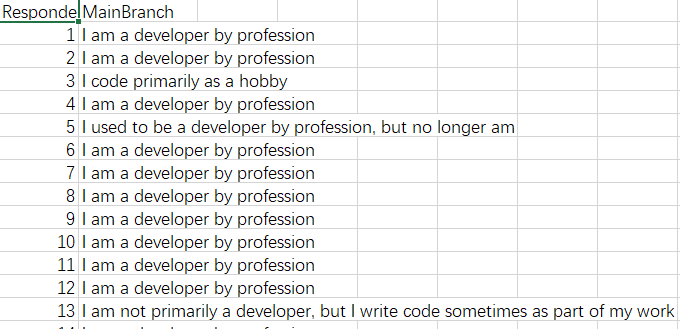
每行数据分为两部分,调查编号和工作描述 题目提供一个fopen函数打开该文件,将数据存入列表并返回。
#不允许修改。fopen函数打开文件,并返回包含文件数据一个列表ls,def fopen(name):ls=[]with open(name,'r',encoding = 'UTF-8') as f:for i in f.readlines()[1:]:ls.append(i.strip().split(',', maxsplit=1))return lslt = fopen('survey.csv') #不允许修改,打开题目文件,并将返回的数据列表赋值给lt
返回列表形式为(仅展示格式,与数据无关): [['1', 'I am a developer by profession'], ['2', 'I am a developer by profession'], ['3', 'I code primarily as a hobby'], ['4', 'I am a developer by profession'], ['5', '"I used to be a developer by profession, but no longer am"'], ... ...]
请输入下列分类,统计问卷数据中下列各项分类的回答记录条数:
| 分类 | 回答 |
|---|---|
程序员 |
I am a developer by profession |
程序爱好者 |
I code primarily as a hobby |
程序初学者 |
I am a student who is learning to code |
编程相关者 |
"I am not primarily a developer, but I write code sometimes as part of my work" |
非程序员 |
"I used to be a developer by profession, but no longer am" |
空白 |
NA |
如果输入为记录,输出所有记录条数 如果不是以上的输入,则输出错误输入
输入输出示例
输入输出示例仅为格式示例,与实际测试数据无关
| 输入 | 输出 | |
|---|---|---|
| 示例 1 | 成员 |
错误输入 |
| 示例 2 | 程序爱好者 |
程序爱好者:23457条 |
| 示例 3 | 记录 |
总计:66887条 |
| 示例 4 | 空白 |
空白:4567条 |
#不允许修改。fopen函数打开文件,并返回包含文件数据一个列表ls,
def fopen(name):
ls=[]
with open(name,'r',encoding = 'UTF-8') as f:
for i in f.readlines()[1:]:
ls.append(i.strip().split(',',maxsplit=1))
return ls
lt = fopen('step7/survey.csv') #不允许修改,打开题目文件,并将返回的数据列表赋值给lt
def fun(ls):
person_no_hair=0
like_no_hair=0
new_no_hair=0
rele_no_hair=0
no_no_hair=0
kong=0
for i in ls:
if i[1]=='I am a developer by profession':#程序员
person_no_hair+=1
elif i[1]=='I code primarily as a hobby':#程序爱好者
like_no_hair+=1
elif i[1]=='I am a student who is learning to code':#程序初学者
new_no_hair+=1
elif i[1]=='"I am not primarily a developer, but I write code sometimes as part of my work"':#编程相关者
rele_no_hair+=1
elif i[1]=='"I used to be a developer by profession, but no longer am"':#非程序员
no_no_hair+=1
elif i[1]=='NA':
kong+=1
return [person_no_hair, like_no_hair, new_no_hair, rele_no_hair, no_no_hair,kong]
s=input()
l=fun(lt)
if(s=='程序员'):
print(f"程序员:{l[0]}条")
elif(s=='程序爱好者'):
print(f"程序爱好者:{l[1]}条")
elif(s=='程序初学者'):
print(f"程序初学者:{l[2]}条")
elif(s=='编程相关者'):
print(f"编程相关者:{l[3]}条")
elif(s=='非程序员'):
print(f"非程序员:{l[4]}条")
elif(s=='空白'):
print(f"空白:{l[5]}条")
elif(s=='记录'):
print(f"总计:{sum(l)}条")
else:
print("错误输入")
第6关:2024政府工作报告数据提取
任务描述
附件中为2024年政府工作报告,本题要求将报告中所有包含数字字符的短句(*)进行提取。
- 短句:将中文标点符号替换为英文空格,然后将报告数据按英文空格进行分割得到的列表中的字符串。
['"', '#', '$', '%', '&', ''', '(', ')', '*', '+', ',', '-', '/', ':', ';', '<', '=', '>', '@', '[', '\', ']', '^', '_', '`', '{', '|', '}', '~', '⦅', '⦆', '「', '」', '、', '\u3000', '、', '〃', '〈', '〉', '《', '》', '「', '」', '『', '』', '【', '】', '〔', '〕', '〖', '〗', '〘', '〙', '〚', '〛', '〜', '〝', '〞', '〟', '〰', '〾', '〿', '–', '—', '‘', '’', '‛', '“', '”', '„', '‟', '…', '‧', '﹏', '﹑', '﹔', '·', '.', '!', '?', '。', '。']# 本题使用上述中文标点符号集
编程要求
代码模板已将文件内容读取为一个字符串。
输入一个关键词key
- 如果该关键词
key在报告中出现,则统计输出该关键字key在报告中出现的次数,并按照报告中出现顺序依次输出包含该关键词key所有短句,以换行间隔。 - 如果输入的关键词为
数字短句,则输出所有包含数字的短句,以换行间隔。 - 除以上情况外如果输入的关键词在报告中没有出现过,则输出
未找到关键词
提示:本题可使用列表推导式将满足要求的短句放入列表,再做后续处理。
测试说明
- 根据关键词查询的结果,必须按照报告中出现顺序输出。
- 2024政府工作报告
格式示例:
输入1: 卫生
输出1: 5 医药卫生 提高医疗卫生服务能力 扩大基层医疗卫生机构慢性病 精神卫生 深入开展健康中国行动和爱国卫生运动
输入2: 数字短句
输出2:(要求输出所有数字短句,此示例仅展示部分数据) 2024年3月5日在第十四届全国人民代表大会第二次会议上 2023年工作回顾 国内生产总值超过126万亿元 增长5.2% ... ...
输入3: 湖北
输出3: 未找到关键词
import string
def Read_report(name): #本函数已定义完整
#读取报告原文,返回字符串,本函数勿修改。
with open(name,'r',encoding='UTF-8') as f:
return f.read()
#下方为待完成区域
def Short(s):
#定义函数,判断字符串s中是否包含数字字符
for n in '0123456789':
if n in s:
return True
return False
def Sign_delete(s):
#定义函数,将报告字符串中的所有中文标点符号替换成英文空格,以便后续分割列表。
sign = ['"', '#', '$', '%', '&', ''', '(', ')', '*', '+', ',', '-', '/', ':', ';', '<', '=', '>', '@', '[', '\', ']', '^', '_', '`', '{', '|', '}', '~', '⦅', '⦆', '「', '」', '、', '\u3000', '、', '〃', '〈', '〉', '《', '》', '「', '」', '『', '』', '【', '】', '〔', '〕', '〖', '〗', '〘', '〙', '〚', '〛', '〜', '〝', '〞', '〟', '〰', '〾', '〿', '–', '—', '‘', '’', '‛', '“', '”', '„', '‟', '…', '‧', '﹏', '﹑', '﹔', '·', '.', '!', '?', '。', '。']
# 继续完成函数定义
for c in sign:
s=s.replace(c,' ')
return s.split()
def Search(key):
ls=[x for x in report if key in x]
if len(ls)==0:
print('未找到关键词')
else:
print(len(ls))
for x in ls:
print(x)
name = 'step8/2024政府工作报告.txt'
report = Read_report(name) #读取报告文件
report = Sign_delete(report) #替换报告中符号,以便后续分隔
key = input() #输入关键词
# 下方继续后续流程设计代码
if key=='数字短句':
for x in report:
if Short(x):
print(x)
else:
Search(key)