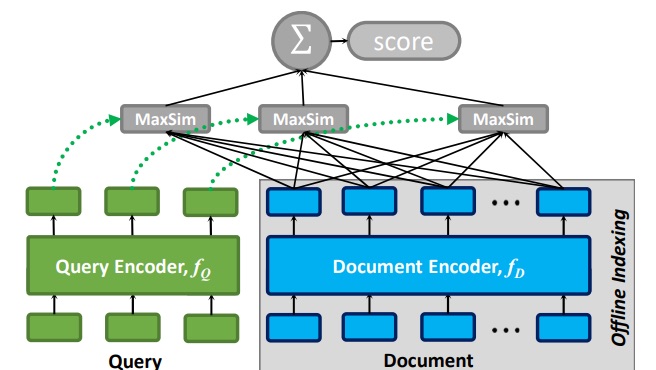
ColBERT 是一个检索模型,为了解决传统双塔模型大 chunk 导致的信息丢失问题,同时规避了常规检索模型全连接导致的搜索效率问题,ColBert 提出基于 token 向量的迟交互模式。传统的 dense 向量擅长捕捉语义信,但由于模型训练时只能学习训练数据中的知识,因此对于训练数据未覆盖的新词汇或专业术语,dense 向量的表达能力有限。再有 SPLADE、BGE 的 M3-Embedding 等模型在保留 sparse 向量关键词匹配能力的同时,尝试把更多的信息编码进去,以进一步提高检索质量。