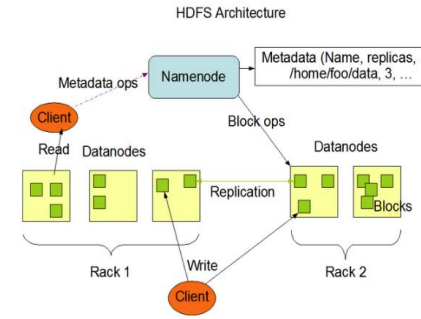
Hadoop决定创建一个由许多小伙伴组成的探险队,每个小伙伴都擅长处理不同类型的数据。他找到了擅长存储大量数据的“HDFS”(Hadoop Distributed File System),让它负责建造一个巨大的数据仓库,用来存放所有收集到的数据。接着,Hadoop又找到了擅长并行处理的“MapReduce”兄弟俩。Map哥哥负责将数据拆分成小块,让探险队的每个成员都能同时处理一部分数据;而Reduce弟弟则负责将处理完的数据汇总起来,形成最终的结果。在HDFS和MapReduce的帮助下,Hadoop