Hive on Spark版本兼容性 2024-06-08 hive, 数据仓库, spark, hadoop, 大数据 398人 已看 Hive on Spark仅在特定版本的Spark上进行测试,因此给定版本的Hive只能保证与特定版本的Spark一起工作。其他版本的Spark可能与给定版本的Hive一起工作,但不能保证。
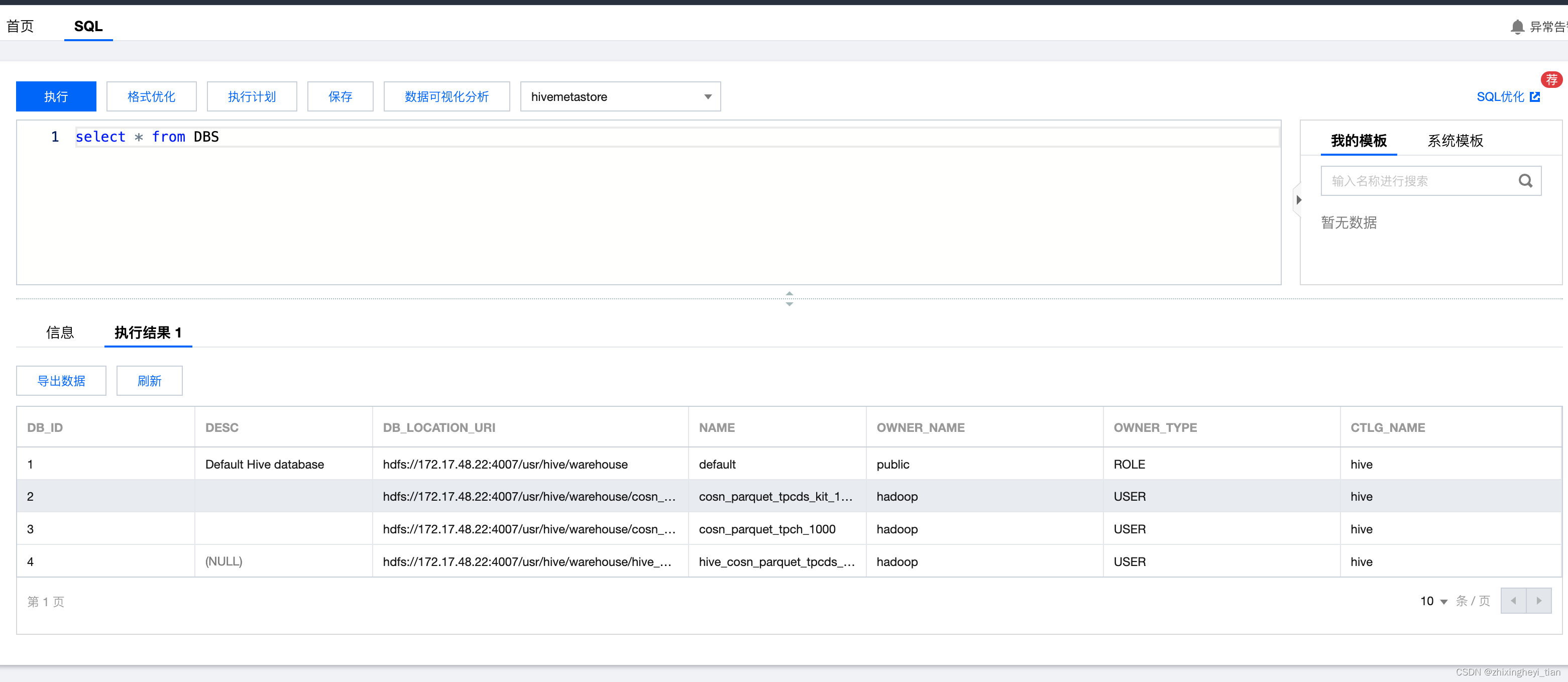
查看Hive表的描述信息,包括在HDFS上的Location信息 2024-06-01 hive, 深度优先, 数据仓库, hadoop, 大数据 134人 已看 DESCRIBE FORMATTED 表名;
Servlet 2024-05-31 hive, 数据仓库, servlet, hadoop, 大数据 129人 已看 在刚才的入门案例中,我们定义了自己的Servlet,实现的方式都是选择实现Servlet,在Servlet的API介绍中,它提出了我们除了实现Servlet还可以继承GenericServlet和继承HttpServlet,通过查阅servlet的类视图,我们看到Servlet下有一个抽象类GenericServlet,抽象类GenericServlet还有一个子类HttpServlet。我们通过浏览器发送请求,请求首先到达Tomcat服务器,由服务器解析请求URL,然后在部署的应用列表中找到我们的应用。
【Hive SQL 每日一题】统计各个商品今年销售额与去年销售额的增长率及排名变化 2024-05-31 hive, 数据仓库, hadoop, 大数据, sql 129人 已看 惯性思维导致,在排序中,并不是排名越高值越大,相反,因为我们的排名越靠前(越高),其排名值越小,想到这里,就应该明白了。(2)根据(1)中的结果,通过窗口函数排序,获取分别获取两个年度的销售额排名。(3)根据(2)中的结果,判断并计算两个年度的增长率以及排名变化,最终通过。统计各个商品今年销售额与去年销售额的增长率及销售额的排名变化。(1)获取去年与今年两个年度的数据,并进行聚合统计。可能对于排名那里存在疑惑,为什么是。连接商品表,获取商品名称。
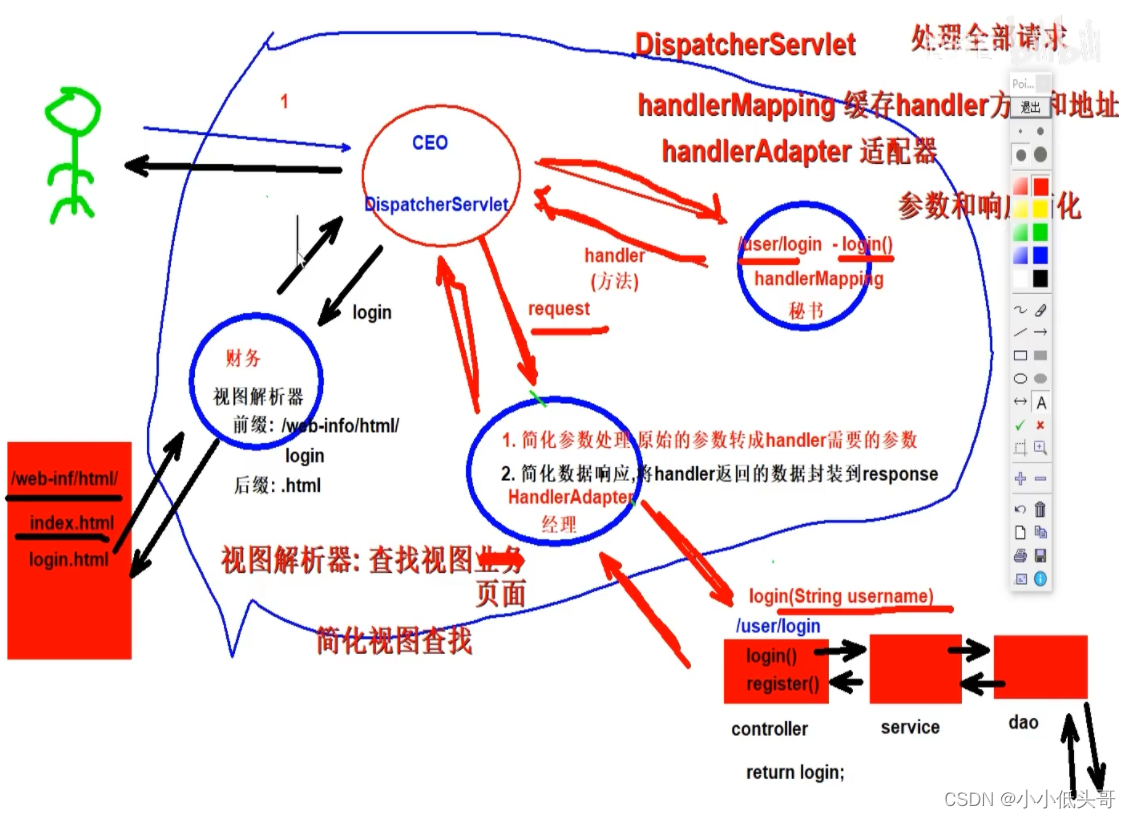
Spring MVC 源码分析之 DispatcherServlet#getHandler 方法 2024-05-30 hive, spring, java, servlet, mvc 165人 已看 本文简单分析了 Spring MVC 工作流程中获取 Handler 的实现,整个过程先通过 Request 请求的一些属性,从整个 HandlerMapping 中获取到具体的 Handler,然后和当前请求应该使用的拦截器一起,通过责任链模式构造出一个拦截器链,看似是从 HandlerMapping 中获取处理当前请求的 Handler,实则最后返回的是一个拦截器链,希望本篇的细节剖析可以帮助大家建立更深的映像。欢迎提出建议及对错误的地方指出纠正。
SpringMVC接收数据 2024-06-05 hive, spring, java, 后端, mvc 146人 已看 介绍了@RequestMapping注解的作用以及Param参数、 路径参数 JSON参数、 Cookie数据请求头数据的接收
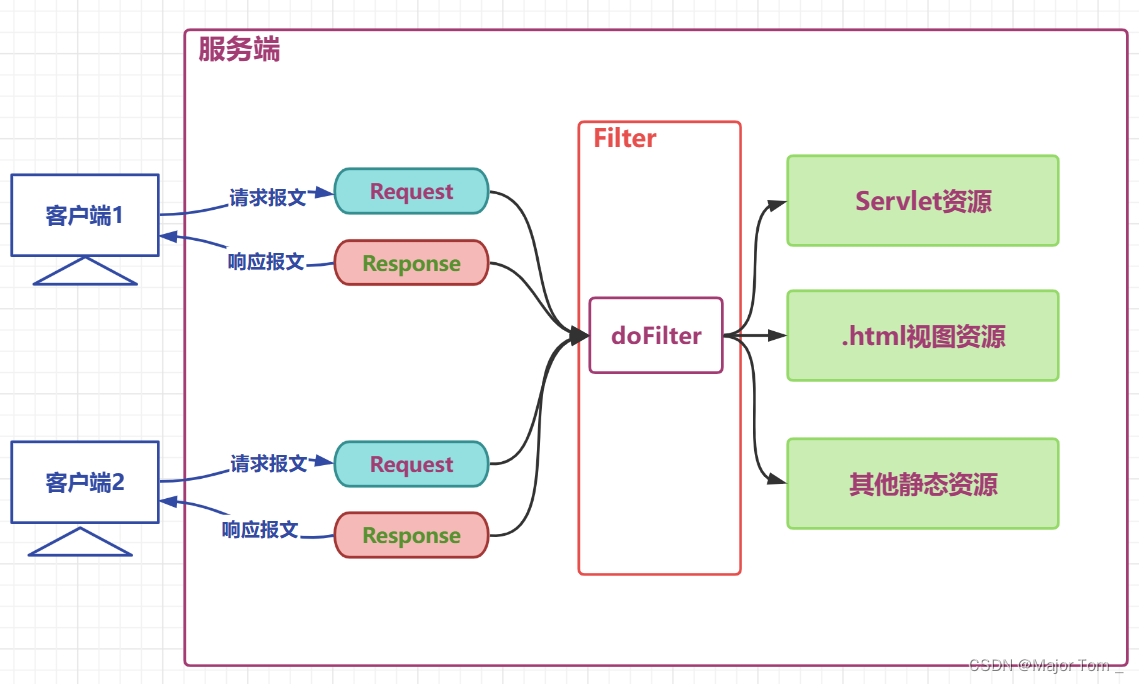
10_JavaWeb过滤器 2024-06-05 hive, 数据仓库, hadoop, 大数据 107人 已看 关于路径的配置过滤器可以url-pattern或者直接写url-name都可。下面写法是通过url-pattern配置 批Servlet匹配;3.过滤 doFilter (多次)生活举例: 公司前台,停车场安保,地铁验票闸机。1.构造 constorct 默认重写。java中过滤仅仅是对请求做出过滤。4.销毁 destory。过滤器开发中应用的场景。2.初始化 init。
大数据基础问题:在Hive中如何实现全增量统一的UDTF、内置函数、聚合、Join等计算引擎常见算子? 2024-06-04 hive, 数据仓库, hadoop, 大数据 84人 已看 大数据行业的Hive可谓是精兵强将。HiveQL支持丰富的SQL功能,包括但不限于数据定义语言(DDL)、数据操作语言(DML)、聚合函数、窗口函数、子查询等
Spark_SparkOnHive_海豚调度跑任务写入Hive表失败解决 2024-05-28 hive, spark, hadoop, 分布式, 大数据 118人 已看 方法将 DataFrame 的数据插入到一个已经存在的Hive表中,如果该表已经存在,则直接将数据插入到该表中,如果表不存在,则会抛出异常。如果表不存在,则会自动创建该表,如果表已经存在,则会用DataFrame的数据覆盖该表中的数据。前段时间我在海豚上打包程序写hive出现了一个问题,spark程序向hive写数据时,报了如下bug,后来我删了建,把分区也删了,parquet格式也加了,还是报这个问题,因此排除是建表问题。后来我看代码,入库的语句如下,死活写不进去。如上,为什么会这样呢,我想了一下,
“Spark+Hive”在DPU环境下的性能测评 | OLAP数据库引擎选型白皮书(24版)DPU部分节选 2024-05-30 hive, spark, 硬件架构, 分布式, 大数据 115人 已看 在奇点云2024年版《OLAP数据库引擎选型白皮书》中,中科驭数联合奇点云针对Spark+Hive这类大数据计算场景下的主力引擎,测评DPU环境下对比CPU环境下的性能提升效果。特此节选该章节内容,与大家共享。
ServletContext 2024-06-02 hive, 数据仓库, servlet, hadoop, 大数据 138人 已看 ServletContext 是应用上下文对象。每一个应用中只有一个 ServletContext 对象, 这个ServletContext 对象被所有Servlet所共享.在 Servlet 规范中,一共有 4 个域对象。ServletContext 就是其中的一个。它也是 web 应用中最大的作用域,也叫 application 域。它可以实现整个应用之间的数据共享!生命周期:应用一加载则创建,应用被停止则销毁。
大数据面试题 —— Hive 2024-05-19 hive, 数据仓库, hadoop, 大数据 98人 已看 (1)承UDF或者UDAF或者UDTF,实现特定的方法;(2)打成jar包,上传到服务器(3)执行命令add jar路径,目的是将 jar 包添加到 hive 中create temporary function 函数名 as "自定义函数全类名"(5)在select中使用 UDF 函数。
大数据面试题 —— Hive 2024-05-19 hive, 数据仓库, hadoop, 大数据 74人 已看 (1)承UDF或者UDAF或者UDTF,实现特定的方法;(2)打成jar包,上传到服务器(3)执行命令add jar路径,目的是将 jar 包添加到 hive 中create temporary function 函数名 as "自定义函数全类名"(5)在select中使用 UDF 函数。
Spark SQL数据源 - Hive表 2024-06-01 hive, spark, 分布式, 大数据, sql 99人 已看 Spark SQL对Hive的支持非常强大,可以直接读取和写入Hive表中的数据。Hive是一个基于Hadoop的数据仓库,它提供了SQL接口来查询和管理存储在HDFS或其他Hadoop兼容存储系统中的数据。
Spark SQL数据源 - Hive表 2024-06-01 hive, spark, 分布式, 大数据, sql 133人 已看 Spark SQL对Hive的支持非常强大,可以直接读取和写入Hive表中的数据。Hive是一个基于Hadoop的数据仓库,它提供了SQL接口来查询和管理存储在HDFS或其他Hadoop兼容存储系统中的数据。
17、Spring系列-SpringMVC-请求源码流程 2024-06-01 hive, spring, java, 后端, mvc 106人 已看 Spring官网的MVC模块介绍:Spring Web MVC是基于Servlet API构建的原始Web框架,从一开始就已包含在Spring框架中。正式名称“ Spring Web MVC”来自其源模块的名称(spring-webmvc),但它通常被称为“ Spring MVC”。从Servlet到SpringMVC最典型的MVC就是JSP + servlet + javabean的模式。
Hive-因精度丢失导致的 join 数据异常 2024-05-31 hive, java, 数据仓库, hadoop, 数据库 89人 已看 这篇文章介绍了Hive在处理join操作时由于精度丢失导致的数据异常问题。作者通过实例展示了在join操作中,即使两个join key明显不相等,Hive也可能将其匹配,这是因为Hive在执行计划中默认会对不同类型的key进行UDFToDouble转换,导致精度丢失。文章指出了这个问题,并提出了需要从执行计划的角度去理解和解决这类问题。
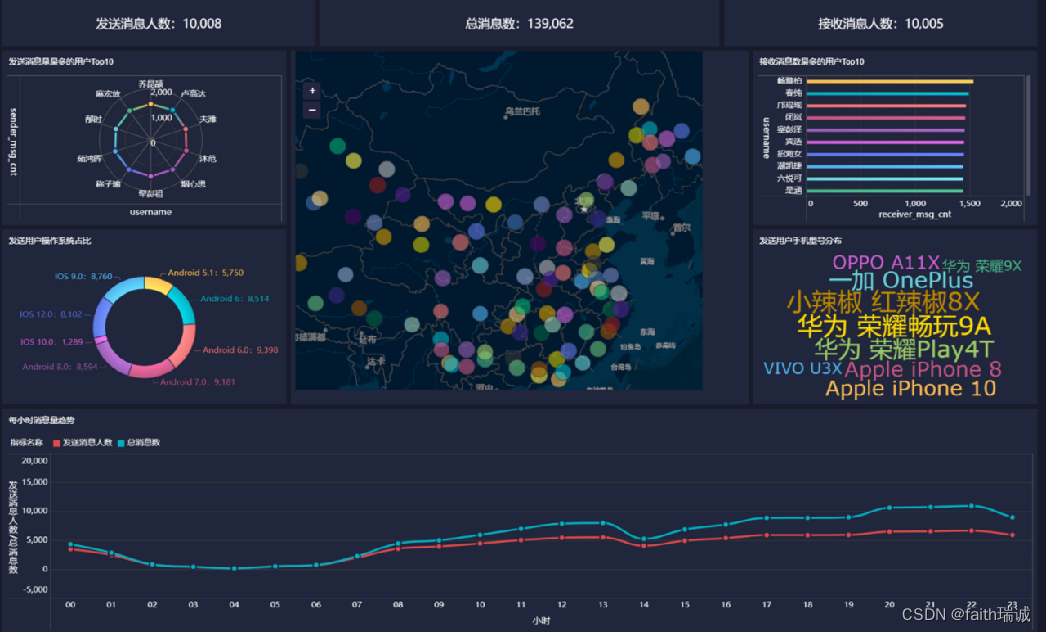
Hadoop+Hive数据分析综合案例 2024-05-31 hive, 数据分析, hadoop, 分布式, 大数据 119人 已看 聊天平台每天都会有大量的用户在线,会出现大量的聊天数据,通过对聊天数据的统计分析,可以更好的对用户构建精准的用户画像,为用户提供更好的服务以及实现高ROI的平台运营推广,给公司的发展决策提供精确的数据支撑。我们将基于一个社交平台App的用户数据,完成相关指标的统计分析并结合BI工具对指标进行可视化展现。