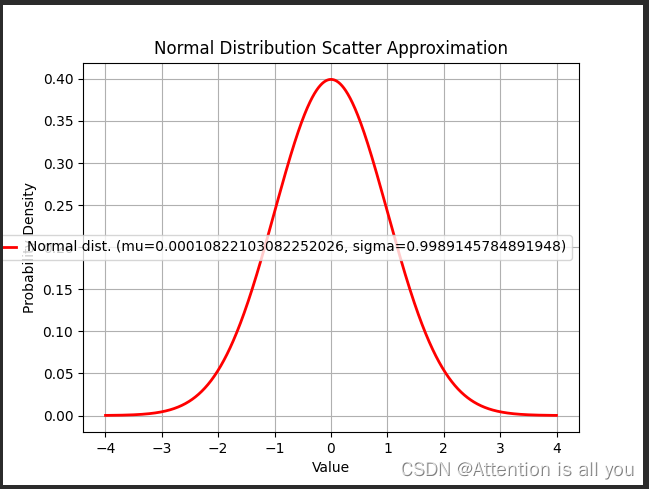
得到矩阵 Q, K, V之后就可以计算出 Self-Attention 的输出了,计算的公式如下:Attention(Q,K,V)=Softmax(QKTdk)VAttention(Q,K,V)=Softmax(\frac{QK^T}{\sqrt{d_k}})VAttention(Q,K,V)=Softmax(dkQKT)V除以维度的开方,可以将数据向0方向集中,使得经过softmax后的梯度更大.从数学上分析,可以使得QK的分布和Q/K保持一致,对于两个独立的正态分布而言,两者的加法的期望和