cv2 复制视频踩坑 2024-05-14 python, 音视频, 计算机视觉, 人工智能, opencv 78人 已看 总结,复制视频时需要获取宽高,自己设置的会导致视频复制不了。通过视频获取的视频的宽高,可以正常复制。自己设置的高度,不能正常复制。
Django JSONField/HStoreField SQL注入漏洞(CVE-2019-14234) 2024-05-18 python, django, sqlite, json, 数据库 100人 已看 CVE-2019-14234 是一个 SQL 注入漏洞,它存在于 Django 框架中的 JSONField 和 HStoreField 字段类型中。当开发者使用这些字段类型,并且允许用户通过查询集(queryset)的键名(key name)来执行查询时,就可能会受到此漏洞的影响。由于 Django 在处理这些查询时使用了简单的字符串拼接,恶意用户可以通过构造特定的查询来注入恶意的 SQL 代码。
JS、Go、Rust 错误处理的不同 - JS 可以不用 Try/Catch 吗? 2024-05-20 rust, python, golang, javascript, 开发语言 73人 已看 Go、Rust 的错误处理使用 error 值,而 JS 使用 Try/Catch 捕获异常。那 JS 能否使用 Go、Rust 的错误处理方式呢?
flask Web应用的接口调试 2024-05-20 python, 后端, flask 95人 已看 在header中填写 Content-Type application/json。在api.ts文件中可见调用了 /conversation 接口。在app.py最下方有 /conversation 接口。本地运行后,使用postman调试。使用chrom浏览器F12查看 Networ-body中填写如下测试值。
【Python】理解分类变量和连续变量 2024-05-14 python, 人工智能, 数据挖掘, 开发语言, 分类 94人 已看 凡是血肉的东西都难与灵魂一样高扬。在数据分析和建模过程中,变量可以分为不同的类型,其中最常见的两种类型是分类变量和连续变量。理解这两种变量类型及其处理方法对于数据分析和建模的成功至关重要。本文将介绍分类变量和连续变量的概念,并通过实例说明如何处理和分析这些变量。
加载完整pytorch .pt模型可能出现的问题 2024-05-21 python, 机器学习, 深度学习, pytorch, 人工智能 92人 已看 现在我们兴致勃勃的昭告天下,我们产生了最牛逼的模型,然后想要在别的地方使用它。在加载完整模型的时候,很可能出错,特别是当我们对模型里面数据流经的途径进行了更改的时候。如果我们不对Net()进行更改,那么没问题,但是当我们更改了Net()的数据流时,就很有可能发生问题。我们在保留训练好的模型model时,可以保留model的参数,也可以直接将完整model全部保留下来。那么现在再load .pth使用时就会出问题,所以要注意,一定要保证数据流的形式没问题,要不然直接加载使用也会出问题。
scikit-learn机器学习要点总结 2024-05-20 python, 机器学习, scikit-learn, 人工智能, sklearn 139人 已看 《数据采集与分析》课程sklearn机器学习部分重要知识点,复习总结sklearn库的相关内容。
Django继承User表实现注册和登录 2024-05-18 python, django, sqlite, 后端, 数据库 107人 已看 (1)、引入**(2)、继承 **phone = models.CharField(max_length=11, null=True, verbose_name="手机号")verbose_name = "用户表"
python代码混淆加密 2024-05-20 python, 开发语言 26人 已看 此时即可生成so文件sum.cpython-310-x86_64-linux-gnu.so。在linux环境下生成.so库文件后,记事本查看so文件依然能找到123456字符串。pyminifier3用于代码混淆,Cython用于生成动态链接库。把.so文件放在其它python脚本的目录下即可调用。所以需要先混淆代码,再生成动态链接库。
python的Serial 串口缓存区数据处理 2024-05-17 python, 缓存, 开发语言 54人 已看 没头脑很久没有处理串口数据,今日测试一个测距传感模块,用简单的serial.read没十几秒就屏幕冻住了,不往下print了。后来反应过来是不停访问串口,导致串口数据缓存区溢出了。有一个比较保险的方式如下,简单而言是成块读取缓存区所有的数据,处理完数据以后,再重新读缓存区所有的数据。
Django图书馆综合项目-学习 2024-05-13 学习, python, django, 后端 68人 已看 添加一些数据后,创建一些urls 这边用子路由结合命名空间的方式去访问。在创建book的时候需要导入Auther 和 Publisher。接下来我们将作者,出版社,书籍的APP分别创建一下。创建一个超级管理员 方便进后台去增加一些数据。将新创建的app在settings里注册。我这边用的IDE是VScode。下一节我们再做一些页面的跳转学习。在每个APP的admin中添加。模型创建好之后执行以下迁移。创建一些对应的html页面。将视图函数和路由都配置一下。查看一下表是否创建成功。其他2个也一样添加一下。
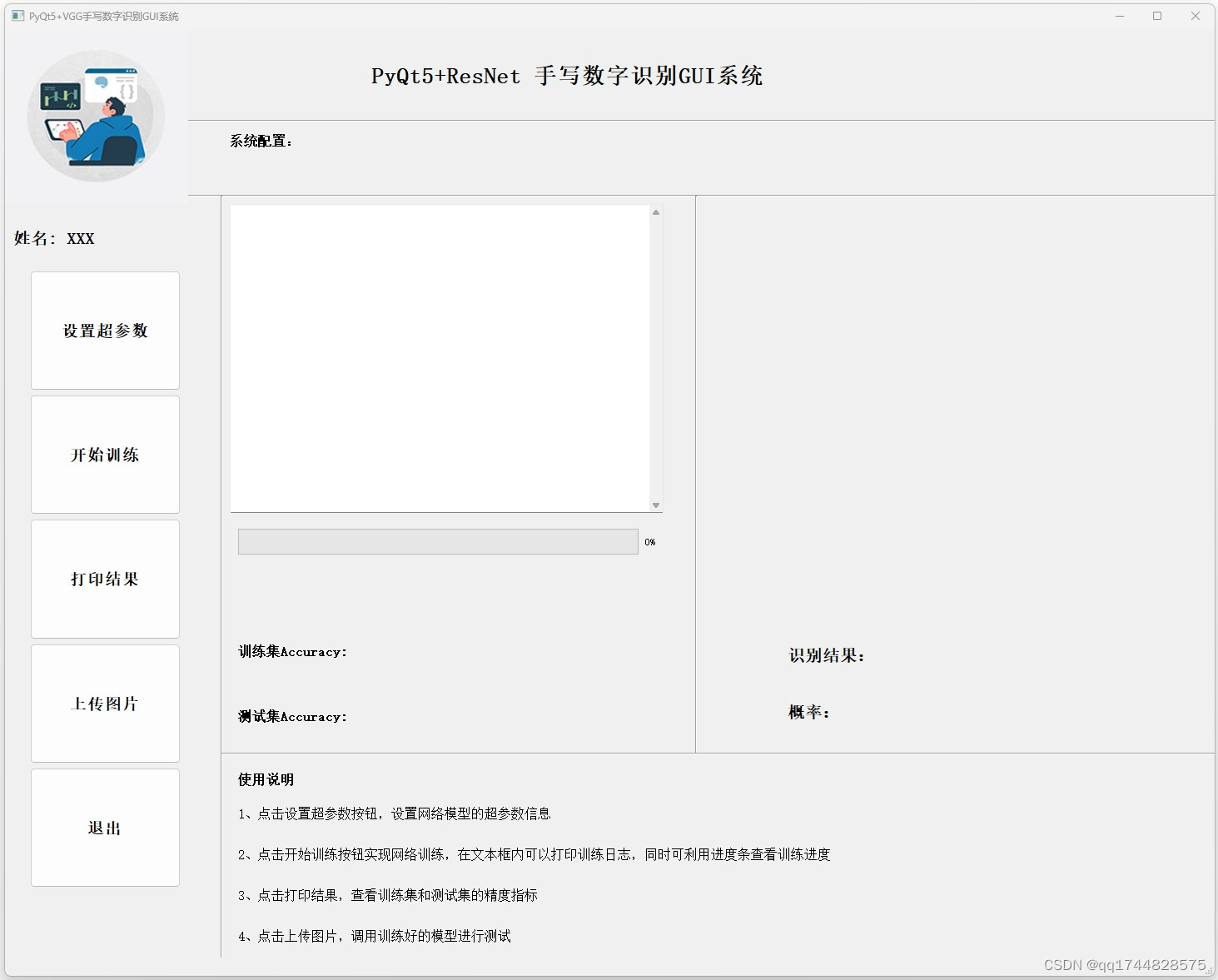
深度学习之基于Pytorch+PyQt5+ResNet手写数字识别 2024-05-20 python, 机器学习, 深度学习, pytorch, 人工智能 78人 已看 一、项目目标该项目的核心目标是开发一个能够准确识别手写数字的系统。通过使用Pytorch深度学习框架和ResNet神经网络架构,系统可以学习从手写数字图像中提取特征并进行分类,实现对手写数字的自动识别。二、项目组成深度学习模型:项目采用Pytorch深度学习框架构建基于ResNet的神经网络模型。ResNet(残差网络)是一种先进的神经网络架构,通过引入残差连接解决了深度神经网络在训练过程中可能出现的梯度消失或梯度爆炸问题,使得网络可以更加深入地学习数据的特征。
python实名认证开发文档-接口文档-身份证ocr接口 2024-05-15 python, ocr 66人 已看 想象一下,当用户因为简便快捷的认证过程而露出满意的微笑,那份由技术带来的温暖,正是翔云身份证实名认证接口提供平台不懈追求的目标。每一次准确无误的识别,都是翔云对“科技让生活更美好”这一信念的践行。众多行业领军者已选择并信赖翔云实名认证解决方案,从金融科技到在线教育,从政府服务到医疗健康,翔云与您一起步入实名认证的新纪元,用技术的力量重塑信任,开启业务增长的新篇章!Python实名认证开发文档,特别是深度优化的OCR接口,正是您跨越信任鸿沟、构建坚不可摧业务防线的金钥匙!
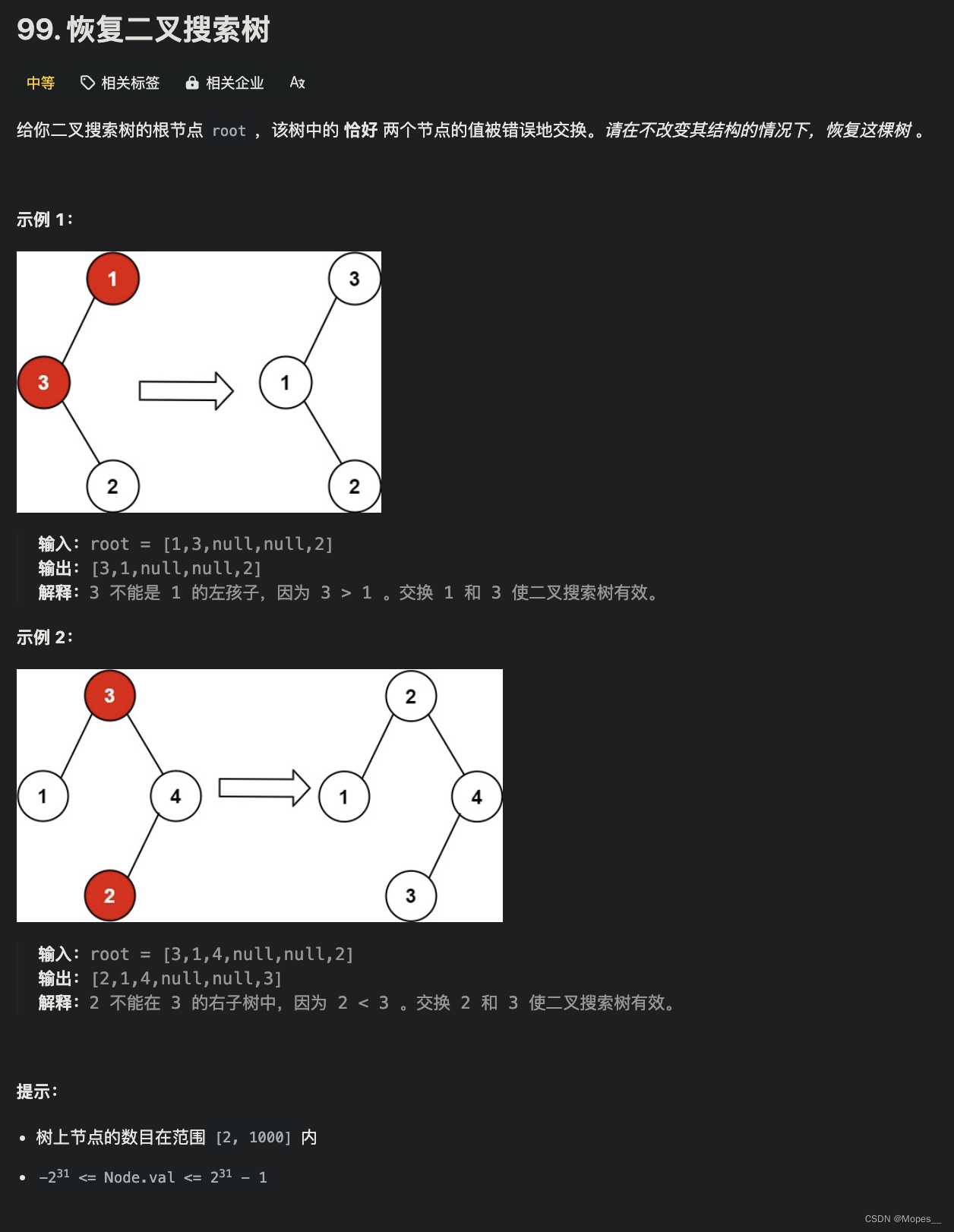
Python | Leetcode Python题解之第99题恢复二叉搜索树 2024-05-20 算法, python, leetcode, 职场和发展, 开发语言 55人 已看 Python | Leetcode Python题解之第99题恢复二叉搜索树
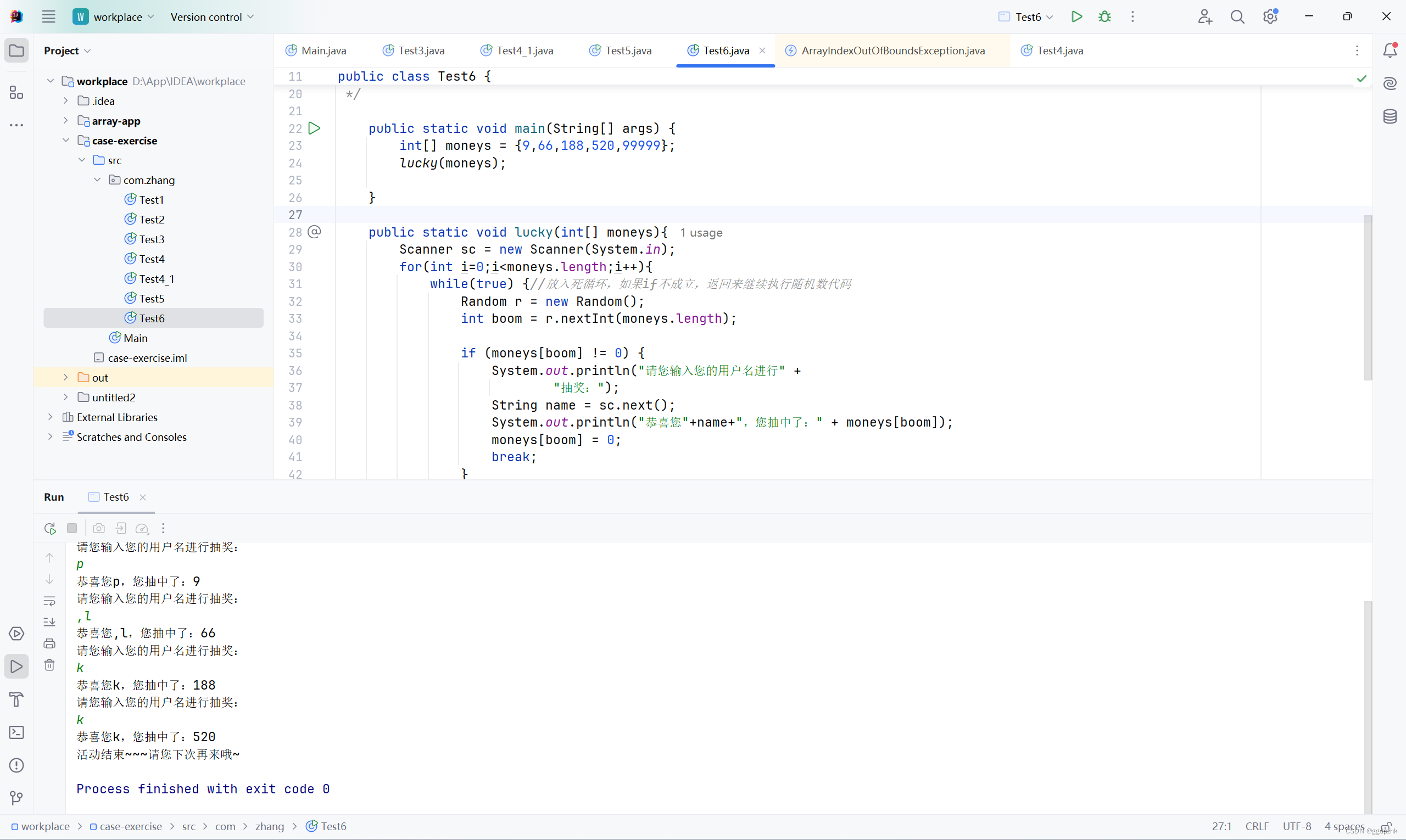
Java:抢红包案例 2024-05-20 python, java, 开发语言 40人 已看 一个大v直播时发起了抢红包活动,分别有9,66,188,520,99999五个红包。请模拟粉丝来抽奖,按照先到先得,随机抽取,抽完为止。,因为while(true)这是个死循环。注意:一个红包只能被抽取一次。
【python将字符串按‘/‘和‘\‘分割开】 2024-05-20 python, 开发语言 45人 已看 这个函数split_string使用正则表达式[\/]来匹配字符串中的/或\,然后使用re.split函数来分割字符串。通过列表推导式,它去除了可能产生的空字符串,确保返回的列表只包含实际的目录或文件名。在Python中,要将一个字符串按/和\分割开,你可以使用正则表达式配合re模块的split函数。这样可以确保无论字符串中是否包含这些分隔符,都能正确地将字符串分割开。
pytorch文本分类(四)模型框架(模型训练与验证) 2024-05-20 python, 机器学习, 深度学习, pytorch, 人工智能 93人 已看 本文是在原本闯关训练的基础上总结得来,加入了自己的理解以及疑问解答(by GPT4)选定了模型框架后,需要对神经网络模型进行训练,主要有3个步骤:接下来详细介绍这3个步骤。构建模型结构,主要有神经网络结构设计、激活函数的选择、模型权重如何初始化、网络层是否批标准化、正则化策略的设定。由于在关卡四中介绍了神经网络结构设计和激活函数的选择,这里不过多介绍,下面简单介绍下权重初始化,批标准化和正则化策略。权重初始化权重参数初始化可以加速模型收敛速度,影响模型结果。常用的初始化方法有:批标准化batch n
python数据分析——整理数据2 2024-05-21 python, 人工智能, 大数据, 开发语言 47人 已看 pivot_table和melt的主要区别是:melt是pandas中的函数,而pivot_table是dataframe对象的方法。最好把歌曲信息存储在单独的表中,如此year、artist、track和time等列的信息就不会在数据集中重复出现。具体操作为:把year、artist、track、time和date.entered放入一个新的dataframe中,给每组值分配唯一的ID,然后再另一个DataFrame(表示歌曲、日期、周次及排名)中使用这些ID。2、一张表中的多个观测单元(归一化)