在深度学习目标检测领域,YOLOv5成为了备受关注的模型之一。在训练过程中,正确的环境配置和有效的模型训练至关重要。本文将手把手教学如何进行YOLOv5的环境配置和模型训练,以帮助您更好地学习深度学习目标检测YOLO系列的挑战。
我们将重点讨论以下内容:
1. YOLOv5的环境配置:包括安装必要的软件和库、配置GPU环境以加速训练、设置Python环境等方面。
2. 数据准备与预处理:如何准备训练数据集,并进行必要的预处理,以确保模型训练的有效性和准确性。

1. 环境配置
首先我们在电脑上安装好Anaconda,安装教程:Anaconda安装过程-CSDN博客
安装好以后打开
然后输入命令
conda create -n name python==3.8 # 创建环境, name是可以替换的,随便起名,这个名字是你的环境名称出现
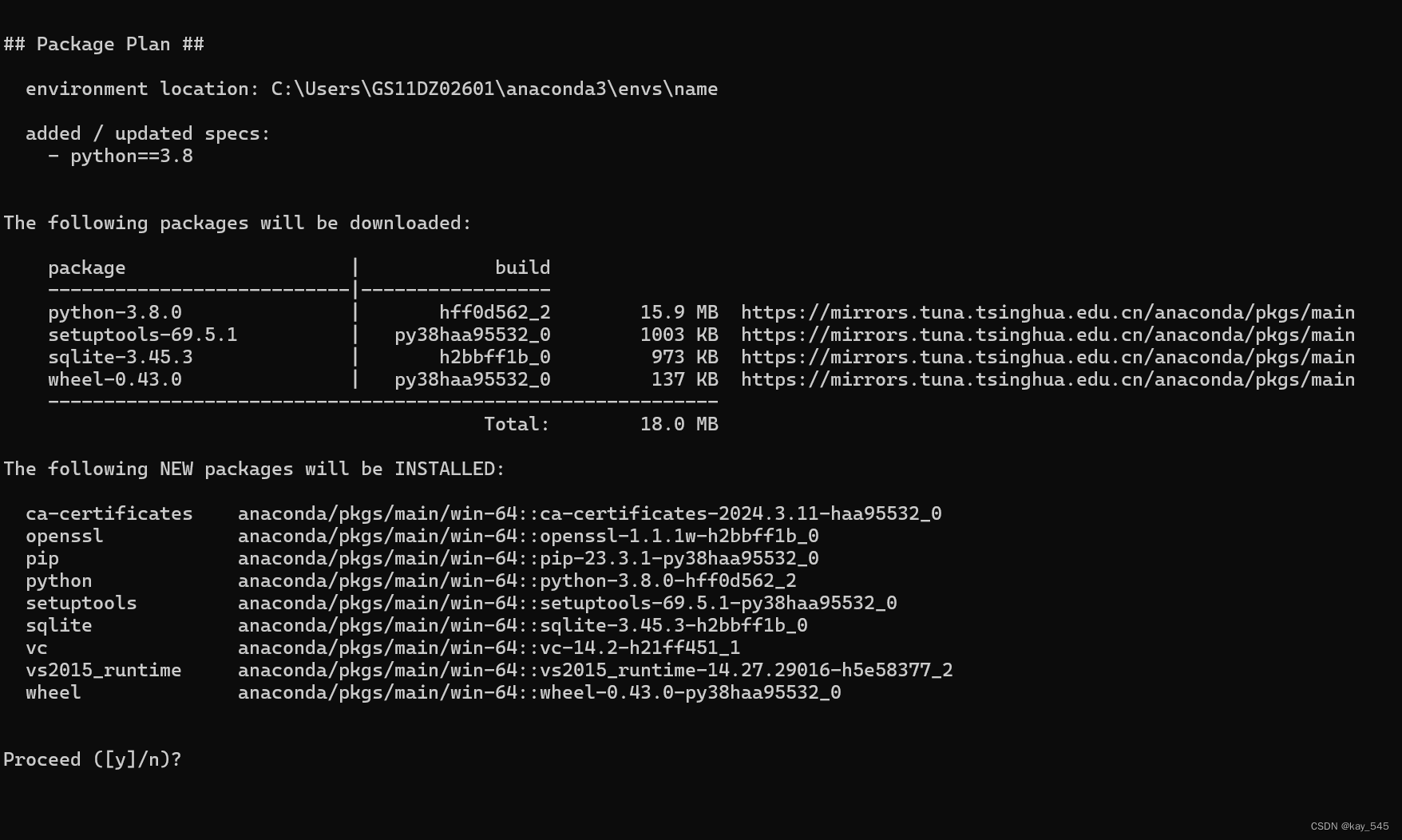
输入 Y,开始下载python和一些基础的包
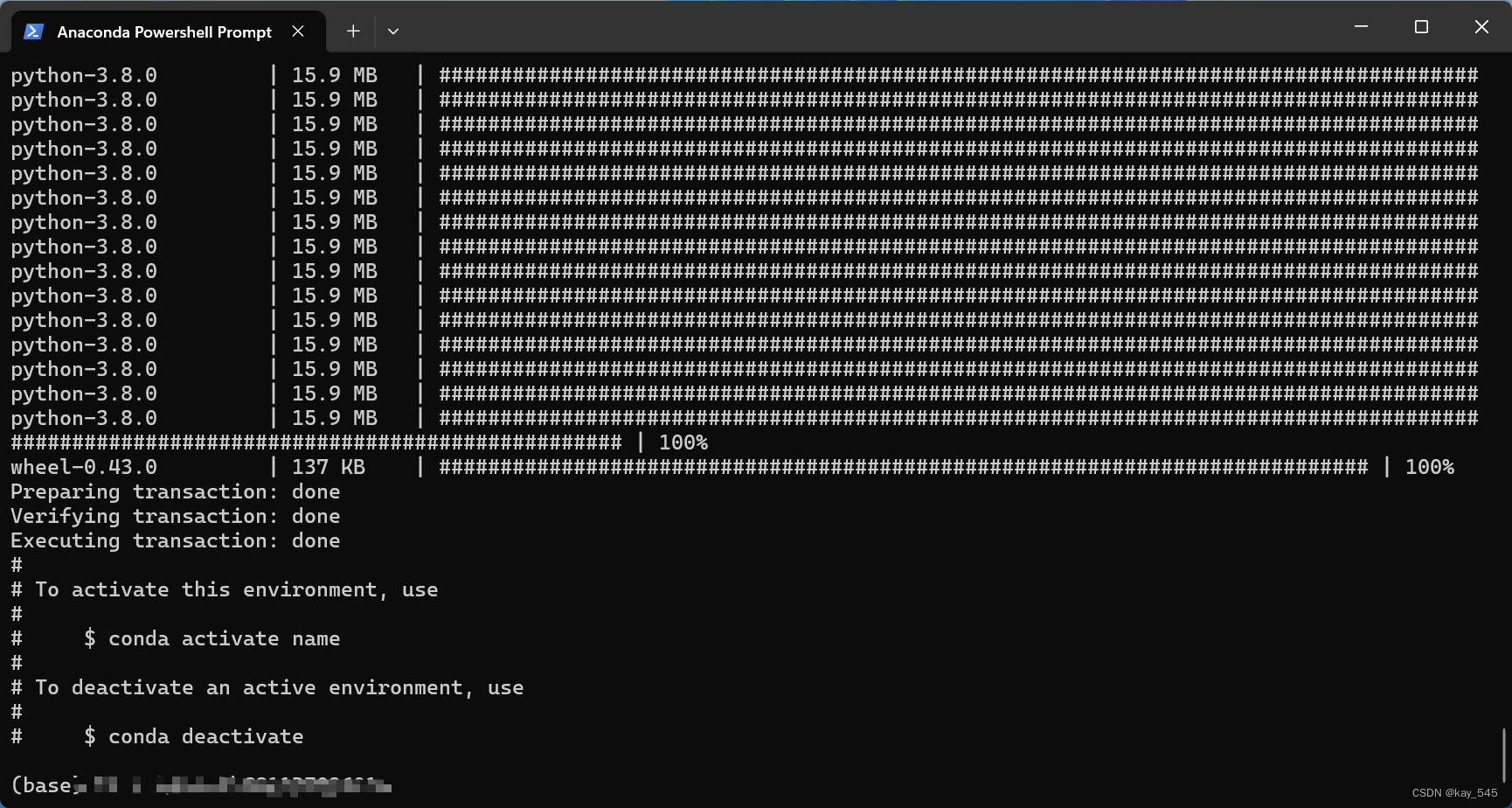
然后激活环境
conda activate name # 其中name是你上面创建环境的名称
然后切换到你下载的yolov5的目录下面
输入命令
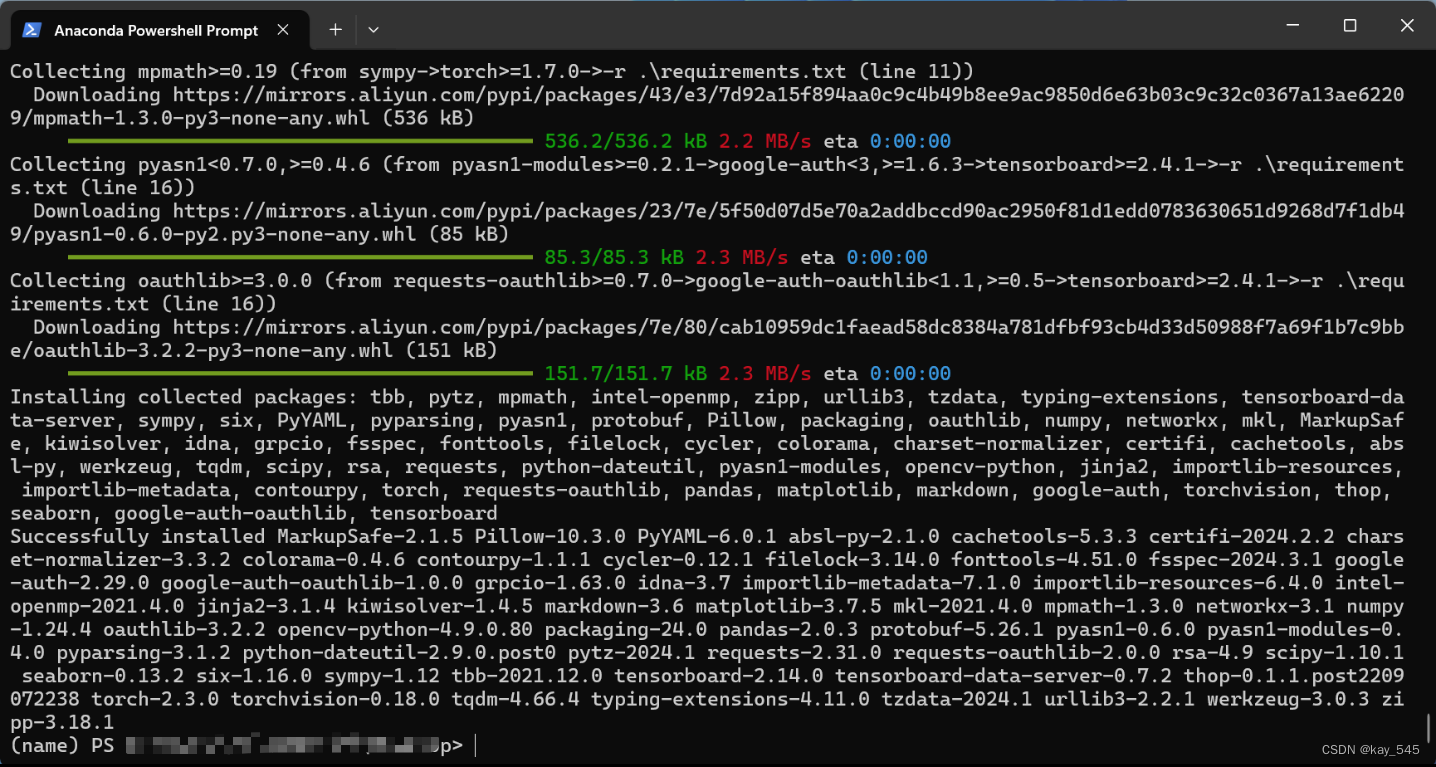
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple/ -r requirements.txt为了下载速度快,我这里用了清华源,当然,也可以换成阿里源
https://mirrors.aliyun.com/pypi/simple 出现这个画面即说明环境安装成功
2. 数据准备
理论上现在就可以训练模型了,但是呢因为pytorch的版本问题,在yolov5-6.1中会有一个报错的问题,如果你的报错了,可以参考我之前写过的文章进行处理
修改后就可以训练模型了,但默认的以coco数据集为例进行训练,这个可以看训练脚本train.py的参数设置
def parse_opt(known=False):
parser = argparse.ArgumentParser()
parser.add_argument('--weights', type=str, default=ROOT / 'yolov5s.pt', help='initial weights path')
parser.add_argument('--cfg', type=str, default='', help='model.yaml path')
parser.add_argument('--data', type=str, default=ROOT / 'data/coco128.yaml', help='dataset.yaml path')
parser.add_argument('--hyp', type=str, default=ROOT / 'data/hyps/hyp.scratch-low.yaml', help='hyperparameters path')
parser.add_argument('--epochs', type=int, default=300)
parser.add_argument('--batch-size', type=int, default=16, help='total batch size for all GPUs, -1 for autobatch')
parser.add_argument('--imgsz', '--img', '--img-size', type=int, default=640, help='train, val image size (pixels)')
parser.add_argument('--rect', action='store_true', help='rectangular training')
parser.add_argument('--resume', nargs='?', const=True, default=False, help='resume most recent training')
parser.add_argument('--nosave', action='store_true', help='only save final checkpoint')
parser.add_argument('--noval', action='store_true', help='only validate final epoch')
parser.add_argument('--noautoanchor', action='store_true', help='disable AutoAnchor')
parser.add_argument('--evolve', type=int, nargs='?', const=300, help='evolve hyperparameters for x generations')
parser.add_argument('--bucket', type=str, default='', help='gsutil bucket')
parser.add_argument('--cache', type=str, nargs='?', const='ram', help='--cache images in "ram" (default) or "disk"')
parser.add_argument('--image-weights', action='store_true', help='use weighted image selection for training')
parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--multi-scale', action='store_true', help='vary img-size +/- 50%%')
parser.add_argument('--single-cls', action='store_true', help='train multi-class data as single-class')
parser.add_argument('--optimizer', type=str, choices=['SGD', 'Adam', 'AdamW'], default='SGD', help='optimizer')
parser.add_argument('--sync-bn', action='store_true', help='use SyncBatchNorm, only available in DDP mode')
parser.add_argument('--workers', type=int, default=8, help='max dataloader workers (per RANK in DDP mode)')
parser.add_argument('--project', default=ROOT / 'runs/train', help='save to project/name')
parser.add_argument('--name', default='exp', help='save to project/name')
parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
parser.add_argument('--quad', action='store_true', help='quad dataloader')
parser.add_argument('--cos-lr', action='store_true', help='cosine LR scheduler')
parser.add_argument('--label-smoothing', type=float, default=0.0, help='Label smoothing epsilon')
parser.add_argument('--patience', type=int, default=100, help='EarlyStopping patience (epochs without improvement)')
parser.add_argument('--freeze', nargs='+', type=int, default=[0], help='Freeze layers: backbone=10, first3=0 1 2')
parser.add_argument('--save-period', type=int, default=-1, help='Save checkpoint every x epochs (disabled if < 1)')
parser.add_argument('--local_rank', type=int, default=-1, help='DDP parameter, do not modify')
# Weights & Biases arguments
parser.add_argument('--entity', default=None, help='W&B: Entity')
parser.add_argument('--upload_dataset', nargs='?', const=True, default=False, help='W&B: Upload data, "val" option')
parser.add_argument('--bbox_interval', type=int, default=-1, help='W&B: Set bounding-box image logging interval')
parser.add_argument('--artifact_alias', type=str, default='latest', help='W&B: Version of dataset artifact to use')其中参数data是指定的使用的数据集
接下来我们看下coco128.yaml文件里的内容
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
# COCO128 dataset https://www.kaggle.com/ultralytics/coco128 (first 128 images from COCO train2017) by Ultralytics
# Example usage: python train.py --data coco128.yaml
# parent
# ├── yolov5
# └── datasets
# └── coco128 ← downloads here
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
path: ../datasets/coco128 # dataset root dir
train: images/train2017 # train images (relative to 'path') 128 images
val: images/train2017 # val images (relative to 'path') 128 images
test: # test images (optional)
# Classes
nc: 80 # number of classes
names: ['person', 'bicycle', 'car', 'motorcycle', 'airplane', 'bus', 'train', 'truck', 'boat', 'traffic light',
'fire hydrant', 'stop sign', 'parking meter', 'bench', 'bird', 'cat', 'dog', 'horse', 'sheep', 'cow',
'elephant', 'bear', 'zebra', 'giraffe', 'backpack', 'umbrella', 'handbag', 'tie', 'suitcase', 'frisbee',
'skis', 'snowboard', 'sports ball', 'kite', 'baseball bat', 'baseball glove', 'skateboard', 'surfboard',
'tennis racket', 'bottle', 'wine glass', 'cup', 'fork', 'knife', 'spoon', 'bowl', 'banana', 'apple',
'sandwich', 'orange', 'broccoli', 'carrot', 'hot dog', 'pizza', 'donut', 'cake', 'chair', 'couch',
'potted plant', 'bed', 'dining table', 'toilet', 'tv', 'laptop', 'mouse', 'remote', 'keyboard', 'cell phone',
'microwave', 'oven', 'toaster', 'sink', 'refrigerator', 'book', 'clock', 'vase', 'scissors', 'teddy bear',
'hair drier', 'toothbrush'] # class names
# Download script/URL (optional)
download: https://ultralytics.com/assets/coco128.zip
path、train、val、test
分别是给定数据集的根目录,还有train datasets的地址,还有val datasets的地址,以及test datasets地址。其实没有path也是可以的,直接在train、val和test的时候给绝对地址就可以了
coco128一共有80个类别,所以nc是80,names也是80个,不信你自己数数,但我相信,所以我从来没有数过🐶
下面的download是如果在你给的路径中找不到数据集,则会下载并自己解压
其中yolo的标注信息是txt的
如果是自己的数据集的话可以用labelimg或者labelme进行标注
安装教程:
Windows下深度学习标注工具LabelImg安装和使用指南_windows安装labelimg-CSDN博客
安装并启动labelme(超详细)_如何启动labelme-CSDN博客
但是labelme只能标注json格式的,标注以后需要写一个脚本转化为txt的
下面是我写的一个脚本,大家可以参考一下 json2txt.py:
# csdn@kay_545
# json2txt
import json
import os
def batch_process_json_to_yolo(json_folder, output_folder, classes):
# 确保输出文件夹存在
os.makedirs(output_folder, exist_ok=True)
# 获取所有 JSON 文件列表
json_files = [f for f in os.listdir(json_folder) if f.endswith('.json')]
# 遍历每个 JSON 文件
for json_file_name in json_files:
# 构建输入和输出文件路径
json_file_path = os.path.join(json_folder, json_file_name)
yolo_file_name = os.path.splitext(json_file_name)[0] + '.txt'
yolo_file_path = os.path.join(output_folder, yolo_file_name)
# 执行转换
json_to_yolo(json_file_path, yolo_file_path, classes)
print(f"已处理 {json_file_name},结果保存在 {yolo_file_path}")
def json_to_yolo(json_path, yolo_path, classes):
with open(json_path, 'r') as json_file:
data = json.load(json_file)
with open(yolo_path, 'w') as yolo_file:
for shape in data["shapes"]:
label = shape["label"]
points = shape["points"]
x1, y1 = points[0]
x2, y2 = points[1]
x_center = (x1 + x2) / 2 / data["imageWidth"] # 中心点的坐标,正确的
y_center = (y1 + y2) / 2 / data["imageHeight"]
width = abs(x2 - x1) / data["imageWidth"]
height = abs(y2 - y1) / data["imageHeight"]
class_index = classes.index(label)
yolo_file.write(f"{class_index} {x_center} {y_center} {width} {height}\n")
if __name__ == "__main__":
# 根据你的实际标签定义
classes = ["cat", "dog"]
# 输入和输出文件夹路径
json_folder_path = 'F:/engine_data/lcc/bump/bump_json/'
output_folder_path = 'F:/engine_data/lcc/bump/bump_txt/'
# 执行批量处理
batch_process_json_to_yolo(json_folder_path, output_folder_path, classes)
print(f"转换完成")3. 模型训练
准备完上述的数据以后就可以执行训练脚本了
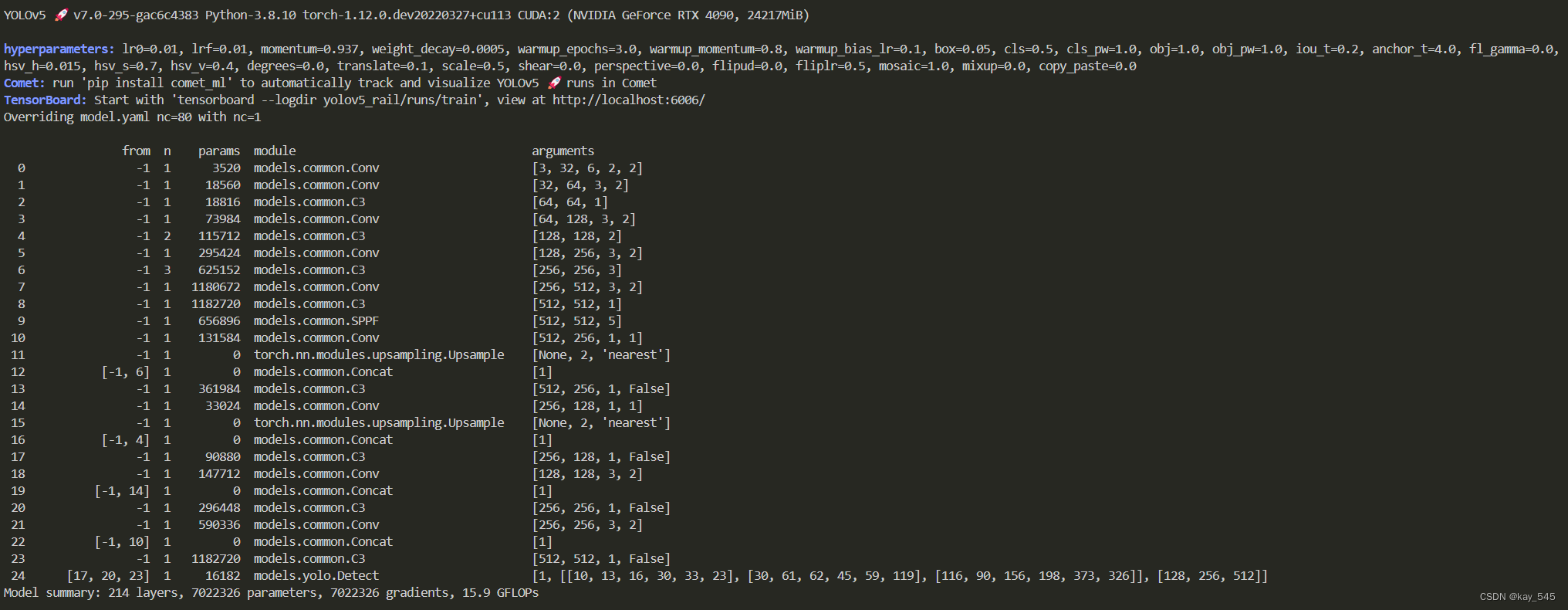
这个我是用自己的数据集进行训练,训练时,首先会打印一些模型的结构信心,还有一些参数设置,使用的哪张显卡等信息。
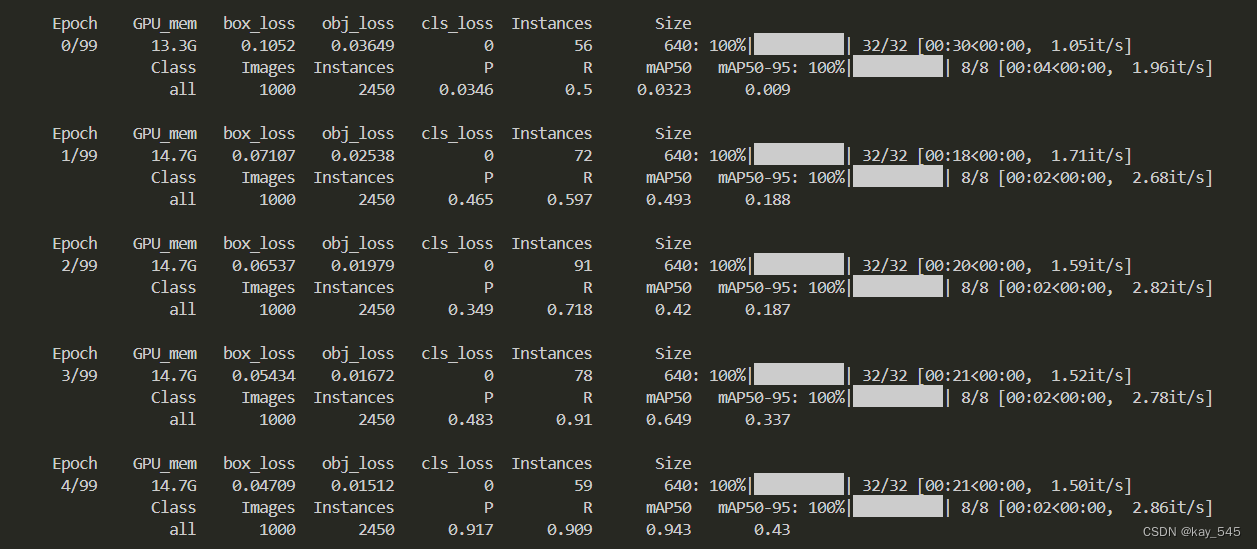 这个是训练的前5个epoch,当然YOLOv5_6.1的默认epoch是300,我为了节约时间将epoch设置为了100,从这里可以看出,模型的map已经有很大的提升了。
这个是训练的前5个epoch,当然YOLOv5_6.1的默认epoch是300,我为了节约时间将epoch设置为了100,从这里可以看出,模型的map已经有很大的提升了。
4. 后期计划
尽管yolov5已经很强大了,但是仍存在一些改进空间。后期我会在YOLOv5的结构的不同位置添加注意力机制或者是修改Backbone、修改Neck,来改进模型,增加模型的检测能力
欢迎大家关注专栏,更新后及时收到消息,如果大家还没明白的地方,欢迎在评论区提问,我将尽力解答大家的疑问。