YOLOv8数据集标注 2024-06-26 yolo 454人 已看 数据集是必不可少的部分,数据集的优劣直接影响训练效果。一般来说,一个完整的数据集应该包括训练集、测试集和验证集。通常,数据集会被划分为训练集和测试集,比如将数据集的70%用作训练集,30%用作测试集。在进行训练时,可以使用交叉验证的方法将训练集再次划分为训练子集和验证子集,用于模型的训练和验证。训练集是用于模型的训练的数据集。在训练过程中,模型使用训练集中的样本进行学习和参数调整,通过不断迭代优化模型的参数,使模型能够更好地拟合训练集中的数据。测试集是用于模型的评估的数据集。
[数据集][目标检测]猪只状态吃喝睡站检测数据集VOC+YOLO格式530张4类别 2024-06-29 yolo, 机器学习, 目标检测, 深度学习, 人工智能 400人 已看 数据集格式:Pascal VOC格式+YOLO格式(不包含分割路径的txt文件,仅仅包含jpg图片以及对应的VOC格式xml文件和yolo格式txt文件)特别声明:本数据集不对训练的模型或者权重文件精度作任何保证,数据集只提供准确且合理标注。标注类别名称:["drink","eat","sleep","stand up"]图片数量(jpg文件个数):530。标注数量(xml文件个数):530。标注数量(txt文件个数):530。使用标注工具:labelImg。标注规则:对类别进行画矩形框。
YOLO深度学习基准模型概念与应用 2024-06-29 yolo, 计算机视觉, 深度学习, 人工智能, 目标跟踪 436人 已看 YOLO(You Only Look Once)是一种先进的深度学习目标检测模型,由Joseph Redmon等人在2016年首次提出,它彻底改变了目标检测领域的游戏规则,因其独特的一阶段检测方法和实时处理能力而广受关注。
使用目标检测模型YOLO V10 OBB进行旋转目标的检测:训练自己的数据集(基于卫星和无人机的农业大棚数据集) 2024-07-02 yolo, 无人机 454人 已看 这个是在YOLO V10源码的基础上实现的。我只是在源码的基础上做了些许的改动。因为YOLOv10是是在Ultralytics的基础上开发而来,所有可以轻松地按照V8 OBB中的代码来修改。修改一个yaml文件和一个脚本脚本代码就可以实现YOLO V10 OBB
yolov10打包为exe 2024-06-20 yolo, python, 计算机视觉, 深度学习, pytorch 362人 已看 pyinstaller打包指令不要用 -F ,-F是打包为一整个exe,容易出现问题,使用以下指令。首先下载官方代码至本机,并使用conda创建虚拟环境,并安装好yolov10所需库。下载官方模型权重 yolov10m.pt ,并在根目录下创建推理代码。打包将在dist文件夹下生成exe,以及相应独立包文件,运行exe。本节实验将官方yolov10推理程序打包为exe运行。(3)安装pyinstall ,并执行打包指令。打包过程,可能会被防火墙拦截,报病毒错误。接下来将该代码打包为exe,
[数据集][目标检测]胸部解剖检测数据集VOC+YOLO格式100张10类别 2024-06-12 yolo, 机器学习, 深度学习, 目标检测, 人工智能 278人 已看 标注类别名称:[“carina”,“clavicle_left”,“clavicle_right”,“gastric_bubble”,“heart”,“humeral_head_left”,“humeral_head_right”,“lung_left”,“lung_right”,“trachea”]数据集格式:Pascal VOC格式+YOLO格式(不包含分割路径的txt文件,仅仅包含jpg图片以及对应的VOC格式xml文件和yolo格式txt文件)标注数量(txt文件个数):100。
YOLOv8改进 | Neck | 添加双向特征金字塔BiFPN【含二次独家创新】 2024-06-20 yolo, 计算机视觉, 深度学习, 人工智能, 目标跟踪 7366人 已看 BIFPN(双向特征金字塔网络)通过双向特征融合和加权特征融合的创新设计,显著提升了特征金字塔网络(FPN)的性能。其核心思想是将信息在特征金字塔中双向传递,即从高层特征图向低层特征图传递,同时也从低层特征图向高层特征图传递,确保特征信息的充分融合。同时,BIFPN引入了可学习的加权机制,通过在训练过程中自动调整权重,优化不同尺度特征图的融合效果。这种设计不仅提高了特征表示的能力,还保持了计算的高效性,使其在目标检测和图像分割等计算机视觉任务中表现出色,能够更好地应对多尺度问题和不同任务需求。
[C++]使用C++部署yolov10目标检测的tensorrt模型支持图片视频推理windows测试通过 2024-06-15 yolo, c++, 音视频, 目标检测, 开发语言 263人 已看 获取pt模型:https://github.com/THU-MIG/yolov10训练自己的模型或者直接使用yolov10官方预训练模型。将编译好的deploy.dll和deploy.lib文件放到yolov10-tensorrt-cplus/lib文件夹。下载源码:https://github.com/laugh12321/yolov10/tree/nms并安装到环境中。注意导出模型和官方yolov10的onnx是不一样的,使用yolov10-nms导出模型结构如图。
[数据集][目标检测]胸部解剖检测数据集VOC+YOLO格式100张10类别 2024-06-12 yolo, 机器学习, 深度学习, 目标检测, 人工智能 247人 已看 标注类别名称:[“carina”,“clavicle_left”,“clavicle_right”,“gastric_bubble”,“heart”,“humeral_head_left”,“humeral_head_right”,“lung_left”,“lung_right”,“trachea”]数据集格式:Pascal VOC格式+YOLO格式(不包含分割路径的txt文件,仅仅包含jpg图片以及对应的VOC格式xml文件和yolo格式txt文件)标注数量(txt文件个数):100。
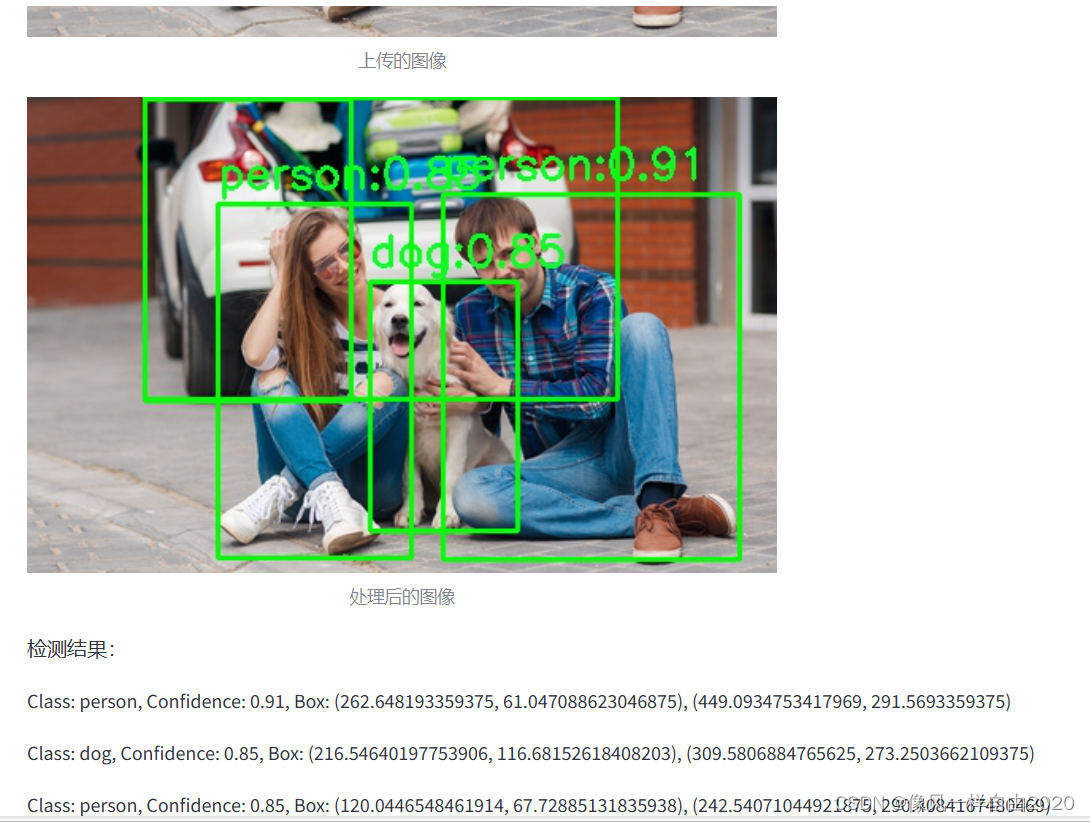
使用Stream实现Web应用,使用YOLOv8模型对图像进行目标检测为例。 2024-06-12 yolo, 计算机视觉, 目标检测, 人工智能 253人 已看 Streamlit是一个开源的Python框架,专门设计用于快速构建和共享数据应用程序。它使数据科学家和机器学习工程师能够通过编写简单的Python脚本,轻松创建美观、功能强大的Web应用程序,而无需具备前端开发的经验。其他框架或web应用可以看下面两篇博客介绍1.2.
YOLOv8改进 | 注意力机制 | 正确的 Self-Attention 与 CNN 融合范式,性能速度全面提升【独家创新】 2024-06-13 yolo, cnn, 人工智能, 神经网络, 驱动开发 337人 已看 YOLOv8改进,yolov8,添加注意力机制
[深度学习]基于C++和onnxruntime部署yolov10的onnx模型 2024-06-13 yolo, c++, 深度学习, 人工智能, 开发语言 169人 已看 使用C#部署yolov8的目标检测tensorrt模型,C# winform部署yolov10的onnx模型,YOLOv8检测界面-PyQt5实现,2024年新版【YOLOV5从入门到实战教程】B站最良心的YOLOV5全套教程(适合小白)含源码!:解析模型输出的结果,这通常涉及将输出的张量数据转换为可理解的检测结果,如边界框坐标和类别标签。:通过ONNX Runtime的推理引擎,将图像数据输入到模型中,并执行目标检测任务。:使用ONNX Runtime的API加载转换后的YOLOv10 ONNX模型。
改进YOLO系列 | YOLOv5/v7 引入 Dynamic Snake Convolution | 动态蛇形卷积 2024-06-12 yolo, python, 深度学习, pytorch, 人工智能 374人 已看 YOLO系列目标检测算法以其速度和精度著称,但对于细长目标例如血管、道路等,其性能仍有提升空间。动态蛇形卷积(DSC)是YOLOv5/v7中引入的一种改进,旨在更好地处理细长目标。DSC的核心是使用控制点序列来变形卷积核。# 根据目标框生成控制点序列# 将目标框转换为控制点序列]))DSC根据控制点序列变形卷积核。# 根据控制点序列变形卷积核DSC层继承自nn.Module类,并实现了DSC操作。# 生成控制点序列# 变形卷积核# DSC操作return out。
注意力机制篇 | YOLOv8改进之在C2f模块引入SpatialGroupEnhance注意力模块 2024-06-11 yolo 315人 已看 这篇文章介绍了一种轻量级的神经网络模块SGE,它可以调整卷积神经网络中每个子特征的重要性,从而提高图像识别任务的性能。SGE通过生成注意力因子来调整每个子特征的强度,有效抑制噪声。与流行的CNN主干网络集成时,SGE可以显著提高图像识别性能。🌈
YOLOV3总结 2024-06-07 yolo, 计算机视觉, 目标检测, 深度学习, 神经网络 227人 已看 第二个输出的26*26特征图,输出维度26*26--通过conv2d,将x由512通道数转换成256通道数--通过2倍的上采样,将13*13结构,转换26--13*13获取的感受野与中等大小目标做融合拼接。:就是通过3*3卷积核进行卷积得到2个特征图,其中第二个特征图由第一个特征图的3*3卷积区域所决定,这个时候可以说,第二个特征图的(一个函数网格)这个未知的感受野就是第一个特征图中的3*3卷积的区域。特征提取--->使用2个concat--->融入特征信息更加丰富,融入多持续特征图信息来预测。
通过fiftyone按分类下载open-images-v7数据集,并转成yolov5可直接训练的格式 2024-06-06 yolo, 机器学习, 深度学习, 人工智能, 分类 1053人 已看 print(f"{class_name}类别的样本数量为:{filtered_dataset.count()}")'test': '', # 可以根据实际情况填写测试集路径。'Mobile phone', # 移动电话 - 16。'nc': len(classes), # 类别数量。'names': classes # 类别名称列表。'Motorcycle', # 摩托车 - 6。'Bicycle', # 自行车 - 5。'Backpack', # 背包 - 10。
【YOLOV8】2.目标检测-训练自己的数据集 2024-06-06 yolo, 计算机视觉, 目标检测, 人工智能 262人 已看 Yolo8出来一段时间了,包含了目标检测、实例分割、人体姿态预测、旋转目标检测、图像分类等功能,所以想花点时间总结记录一下这几个功能的使用方法和自定义数据集需要注意的一些问题,本篇是第二篇,目标检测功能,自定义数据集的训练。YOLO(You Only Look Once)是一种流行的物体检测和图像分割模型,由华盛顿大学的约瑟夫-雷德蒙(Joseph Redmon)和阿里-法哈迪(Ali Farhadi)开发。YOLO 于 2015 年推出,因其高速度和高精确度而迅速受到欢迎。