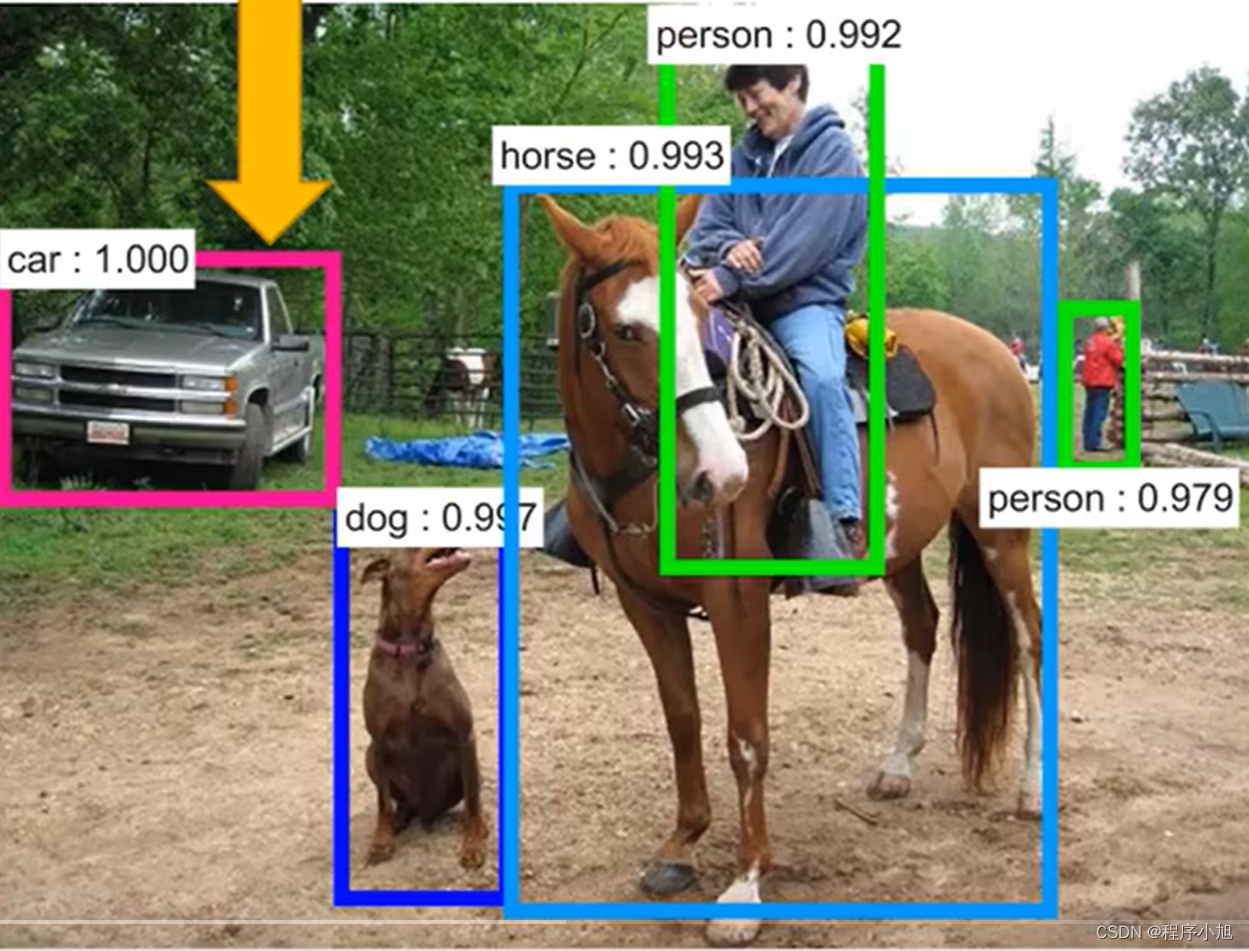
[数据集][目标检测]猪只状态吃喝睡站检测数据集VOC+YOLO格式530张4类别 2024-06-29 yolo, 机器学习, 目标检测, 深度学习, 人工智能 368人 已看 数据集格式:Pascal VOC格式+YOLO格式(不包含分割路径的txt文件,仅仅包含jpg图片以及对应的VOC格式xml文件和yolo格式txt文件)特别声明:本数据集不对训练的模型或者权重文件精度作任何保证,数据集只提供准确且合理标注。标注类别名称:["drink","eat","sleep","stand up"]图片数量(jpg文件个数):530。标注数量(xml文件个数):530。标注数量(txt文件个数):530。使用标注工具:labelImg。标注规则:对类别进行画矩形框。
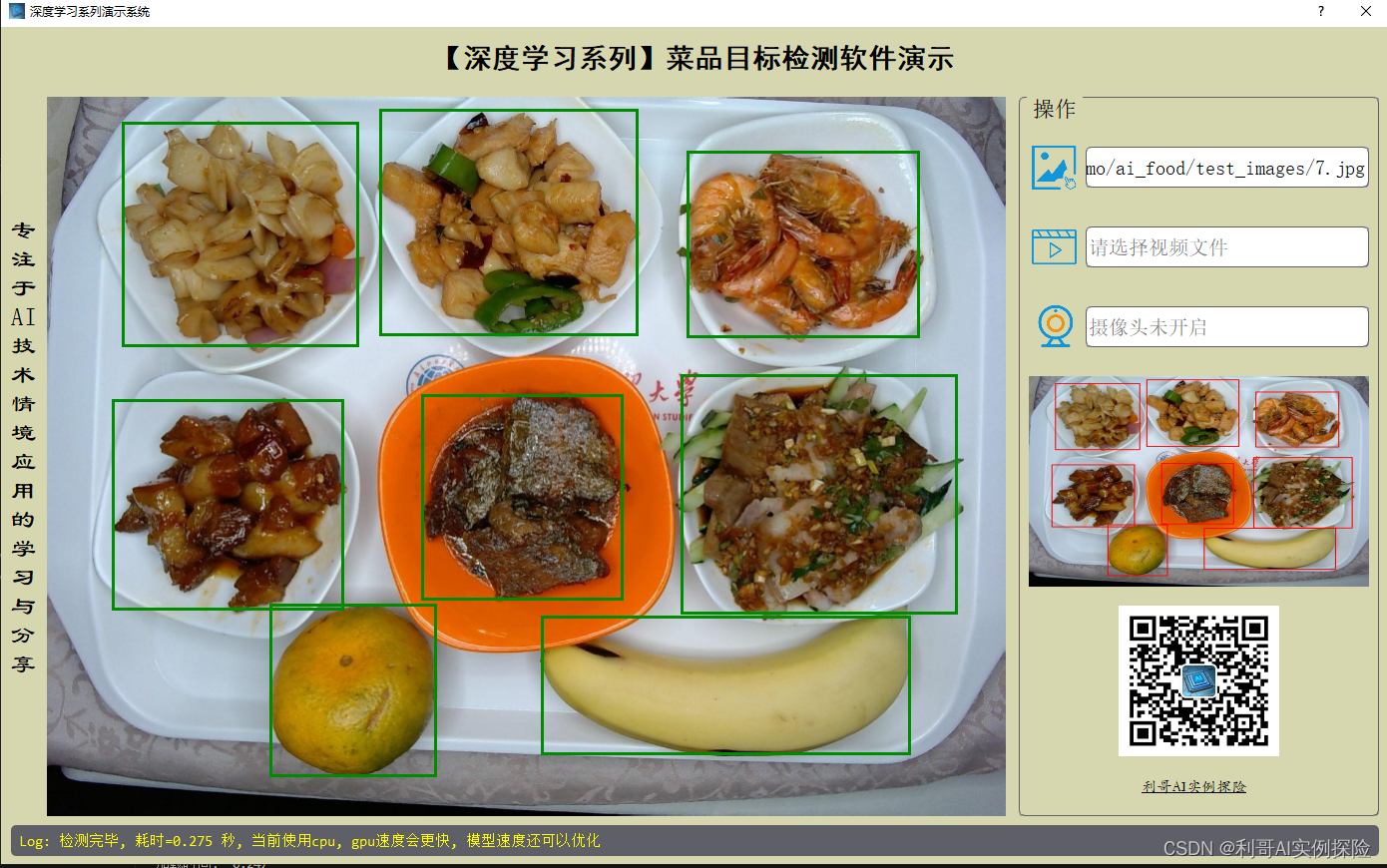
【深度学习】菜品目标检测软件系统 2024-06-25 计算机视觉, 深度学习, 目标检测, 人工智能 284人 已看 摘要:本文主要使用YOLOV8深度学习框架自训练了一个“菜品目标检测模型”,基于此模型使用PYQT5实现了一款界面软件用于功能演示。让您可以更好的了解和学习,该软件支持图片、视频以及摄像头进行目标检测,本系统所涉及的训练数据及软件源码已打包上传。后续计划:会训练特征模型进行自定义特征注册和比对。
[数据集][目标检测]胸部解剖检测数据集VOC+YOLO格式100张10类别 2024-06-12 yolo, 机器学习, 深度学习, 目标检测, 人工智能 258人 已看 标注类别名称:[“carina”,“clavicle_left”,“clavicle_right”,“gastric_bubble”,“heart”,“humeral_head_left”,“humeral_head_right”,“lung_left”,“lung_right”,“trachea”]数据集格式:Pascal VOC格式+YOLO格式(不包含分割路径的txt文件,仅仅包含jpg图片以及对应的VOC格式xml文件和yolo格式txt文件)标注数量(txt文件个数):100。
[C++]使用C++部署yolov10目标检测的tensorrt模型支持图片视频推理windows测试通过 2024-06-15 yolo, c++, 音视频, 目标检测, 开发语言 246人 已看 获取pt模型:https://github.com/THU-MIG/yolov10训练自己的模型或者直接使用yolov10官方预训练模型。将编译好的deploy.dll和deploy.lib文件放到yolov10-tensorrt-cplus/lib文件夹。下载源码:https://github.com/laugh12321/yolov10/tree/nms并安装到环境中。注意导出模型和官方yolov10的onnx是不一样的,使用yolov10-nms导出模型结构如图。
[数据集][目标检测]胸部解剖检测数据集VOC+YOLO格式100张10类别 2024-06-12 yolo, 机器学习, 深度学习, 目标检测, 人工智能 233人 已看 标注类别名称:[“carina”,“clavicle_left”,“clavicle_right”,“gastric_bubble”,“heart”,“humeral_head_left”,“humeral_head_right”,“lung_left”,“lung_right”,“trachea”]数据集格式:Pascal VOC格式+YOLO格式(不包含分割路径的txt文件,仅仅包含jpg图片以及对应的VOC格式xml文件和yolo格式txt文件)标注数量(txt文件个数):100。
目标检测—Fast RCNN 2024-06-18 计算机视觉, 目标检测, 人工智能 269人 已看 R-CNN是Ross Girshick大神的一大杰作,14年发表在CVPR上,目前已有超过2万的引用量,在目标检测领域有着里程碑式的意义。
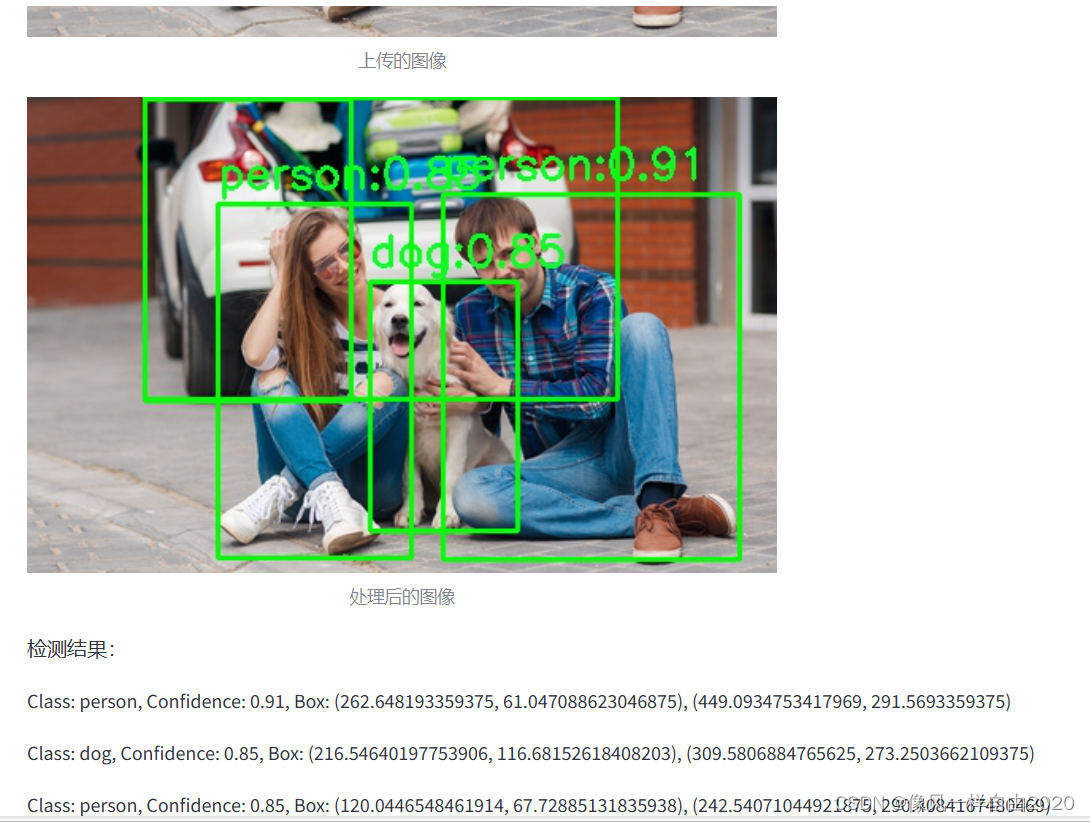
使用Stream实现Web应用,使用YOLOv8模型对图像进行目标检测为例。 2024-06-12 yolo, 计算机视觉, 目标检测, 人工智能 235人 已看 Streamlit是一个开源的Python框架,专门设计用于快速构建和共享数据应用程序。它使数据科学家和机器学习工程师能够通过编写简单的Python脚本,轻松创建美观、功能强大的Web应用程序,而无需具备前端开发的经验。其他框架或web应用可以看下面两篇博客介绍1.2.
YOLOV3总结 2024-06-07 yolo, 计算机视觉, 目标检测, 深度学习, 神经网络 211人 已看 第二个输出的26*26特征图,输出维度26*26--通过conv2d,将x由512通道数转换成256通道数--通过2倍的上采样,将13*13结构,转换26--13*13获取的感受野与中等大小目标做融合拼接。:就是通过3*3卷积核进行卷积得到2个特征图,其中第二个特征图由第一个特征图的3*3卷积区域所决定,这个时候可以说,第二个特征图的(一个函数网格)这个未知的感受野就是第一个特征图中的3*3卷积的区域。特征提取--->使用2个concat--->融入特征信息更加丰富,融入多持续特征图信息来预测。
【Node.js快速部署opencv项目】图像分类与目标检测 2024-06-09 node.js, 计算机视觉, 目标检测, 人工智能 273人 已看 在现代Web开发中,JavaScript通过Node.js得以进入后端编程领域,带来了许多前所未有的开发便利。opencv4nodejs 是一个将OpenCV的强大功能直接绑定到Node.js的库,它允许开发者在一个统一的JavaScript环境中实现复杂的图像和视频分析任务。
【YOLOV8】2.目标检测-训练自己的数据集 2024-06-06 yolo, 计算机视觉, 目标检测, 人工智能 248人 已看 Yolo8出来一段时间了,包含了目标检测、实例分割、人体姿态预测、旋转目标检测、图像分类等功能,所以想花点时间总结记录一下这几个功能的使用方法和自定义数据集需要注意的一些问题,本篇是第二篇,目标检测功能,自定义数据集的训练。YOLO(You Only Look Once)是一种流行的物体检测和图像分割模型,由华盛顿大学的约瑟夫-雷德蒙(Joseph Redmon)和阿里-法哈迪(Ali Farhadi)开发。YOLO 于 2015 年推出,因其高速度和高精确度而迅速受到欢迎。
香橙派 AIpro开发体验:使用YOLOV8对USB摄像头画面进行目标检测 2024-05-27 yolo, 计算机视觉, 目标检测, 人工智能 451人 已看 YOLOv8 作为最新的目标检测算法,以其高精度、高速度和易用性,成为许多开发者首选。而香橙派 AIpro 作为一款高性能嵌入式开发板,采用昇腾AI技术路线,集成图形处理器,拥有8GB/16GB LPDDR4X,8/20 TOPS AI算力,为 AI 应用提供了坚实的硬件基础。本篇文章将分享使用香橙派 AIpro 和 YOLOv8 结合 USB 摄像头进行物体检测的实战经验,并探讨其在实际应用中的价值。昇腾CANN框架的优势推理速度显著提升。
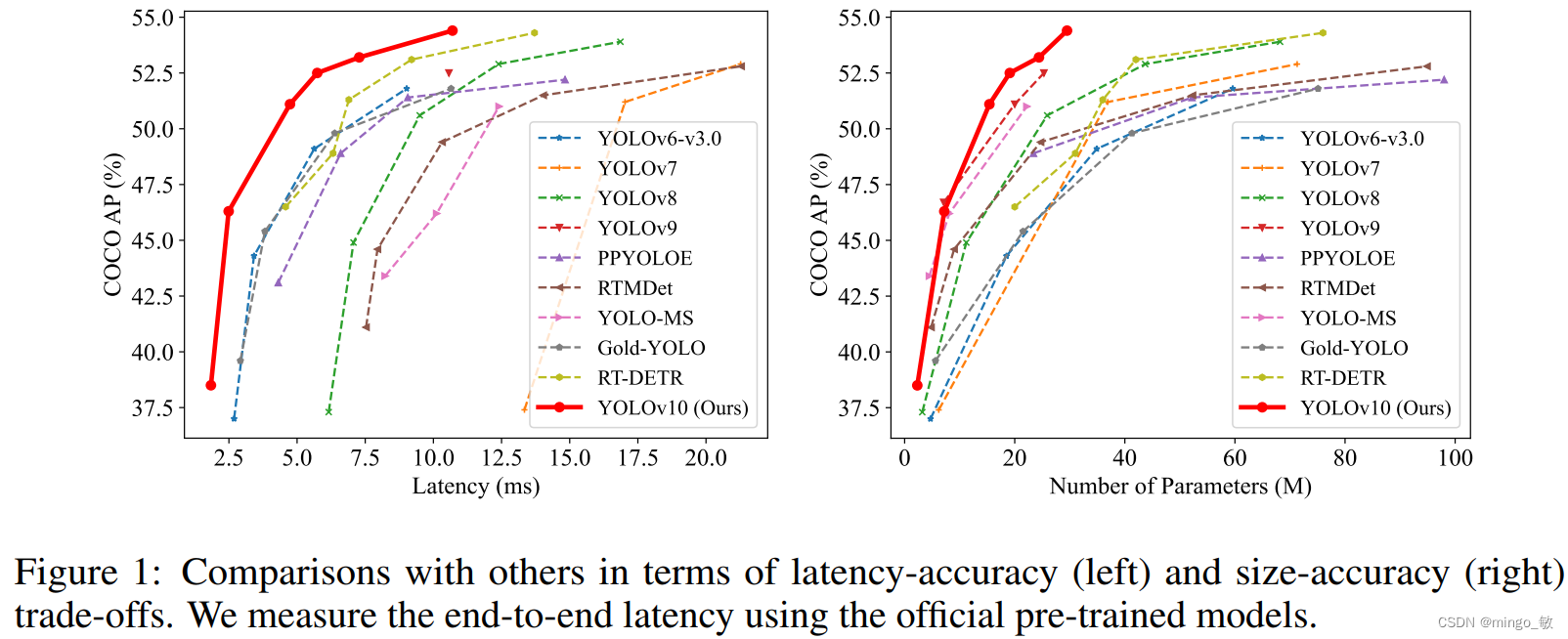
深度学习论文: YOLOv10: Real-Time End-to-End Object Detection 2024-05-27 yolo, 计算机视觉, 目标检测, 人工智能 173人 已看 YOLO在实时物体检测领域因计算成本与检测性能的平衡而领先。尽管研究人员在架构、优化目标和数据增强方面取得显著进展,但YOLO对NMS的依赖影响了其端到端部署和推理速度。此外,YOLO组件设计的不足导致计算冗余和性能限制。为此,YOLOv10专注于后处理和模型架构,提出了无NMS训练的一致对偶分配方法,实现高性能和低延迟。同时,YOLOv10采用效率-准确度驱动的策略,全面优化YOLO组件,降低计算成本并提高性能。
[数据集][目标检测]猫狗检测数据集VOC+YOLO格式8291张2类别 2024-05-30 yolo, 机器学习, 深度学习, 目标检测, 人工智能 160人 已看 数据集格式:Pascal VOC格式+YOLO格式(不包含分割路径的txt文件,仅仅包含jpg图片以及对应的VOC格式xml文件和yolo格式txt文件)特别声明:本数据集不对训练的模型或者权重文件精度作任何保证,数据集只提供准确且合理标注。标注类别名称:["cat","dog"]图片数量(jpg文件个数):8291。标注数量(xml文件个数):8291。标注数量(txt文件个数):8291。使用标注工具:labelImg。标注规则:对类别进行画矩形框。cat 框数 = 4766。
目标检测基础初步学习 2024-05-28 学习, 计算机视觉, 目标检测, 人工智能, 目标跟踪 218人 已看 在动手学习深度学习中对目标检测任务有如下的描述。图像分类任务中,我们假设图像中只有一个主要物体对象,我们只关注如何识别其类别。然而,很多时候图像里有多个我们感兴趣的目标,我们不仅想知道它们的类别,还想得到它们在图像中的具体位置。在计算机视觉里,我们将这类任务称为目标检测(object detection)或目标识别(object recognition)通过边界框给出了物体的相关位置信息我们通常使用边界框(bounding box)来描述对象的空间位置。边界框是矩形的,由矩形左上角的以及右下角的。
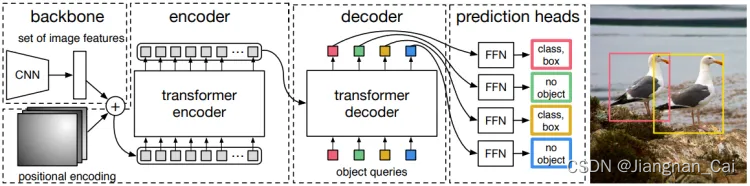
RT-DETR:端到端的实时Transformer检测模型(目标检测+跟踪) 2024-05-31 机器学习, 计算机视觉, 目标检测, 人工智能, 目标跟踪 242人 已看 博主一直一来做的都是基于的目标检测领域,相较于基于卷积的目标检测方法,如YOLO等,其检测速度一直为人诟病。终于,RT-DETR横空出世,在取得高精度的同时,检测速度也大幅提升。那么RT-DETR是如何做到的呢?在研究RT-DETR的改进前,我们先来了解下DETR类目标检测方法的发展历程吧DETRNMSDAB-DETRDETR100DETRDAB-DETRH-DETR然而,上述方法尽管已经大幅提升了检测精度,降低了计算复杂度,但其受本身高计算复杂度的制约,DETR。
【pip安装】YOLOv8目标检测初步上手 2024-06-03 yolo, 计算机视觉, 目标检测, 人工智能 237人 已看 Ultralytics YOLOv8 是一个尖端的、最先进的(SOTA)模型,它建立在以前 YOLO 版本的成功基础之上,并引入了新功能和改进,以进一步提高性能和灵活性。YOLOv8 旨在快速、准确且易于使用,使其成为广泛的对象检测和跟踪实例分割图像分类和姿态估计任务的极佳选择。
[数据集][目标检测]轮胎检测数据集VOC+YOLO格式439张1类别 2024-06-01 yolo, 计算机视觉, 目标检测, 深度学习, 人工智能 209人 已看 数据集格式:Pascal VOC格式+YOLO格式(不包含分割路径的txt文件,仅仅包含jpg图片以及对应的VOC格式xml文件和yolo格式txt文件)特别声明:本数据集不对训练的模型或者权重文件精度作任何保证,数据集只提供准确且合理标注。图片数量(jpg文件个数):439。标注数量(xml文件个数):439。标注数量(txt文件个数):439。标注类别名称:["tire"]使用标注工具:labelImg。tire 框数 = 1008。标注规则:对类别进行画矩形框。
[数据集][目标检测]脑溢血检测数据集VOC+YOLO格式767张2类别 2024-06-01 yolo, 机器学习, 深度学习, 目标检测, 人工智能 166人 已看 数据集格式:Pascal VOC格式+YOLO格式(不包含分割路径的txt文件,仅仅包含jpg图片以及对应的VOC格式xml文件和yolo格式txt文件)特别声明:本数据集不对训练的模型或者权重文件精度作任何保证,数据集只提供准确且合理标注。标注类别名称:["hemorrhage","normal"]图片数量(jpg文件个数):767。标注数量(xml文件个数):767。标注数量(txt文件个数):767。normal 框数 = 224。使用标注工具:labelImg。标注规则:对类别进行画矩形框。
[数据集][目标检测]数据集VOC格式岸边垂钓钓鱼fishing目标检测数据集-4330张 2024-06-01 机器学习, 计算机视觉, 目标检测, 人工智能, 目标跟踪 372人 已看 数据集格式:Pascal VOC格式(不包含分割路径的txt文件和yolo格式的txt文件,仅仅包含jpg图片和对应的xml)[数据集][目标检测]岸边垂钓数据集VOC格式4330张介绍_哔哩哔哩_bilibili。特别声明:本数据集不对训练的模型或者权重文件精度作任何保证,数据集只提供准确且合理标注。重要说明:检测岸边钓鱼人员的数据集,当有人拿个鱼竿或者明显在钓鱼则会被标注。标注数量(xml文件个数):4330。标注类别名称:["fishing"]标注规则:对类别进行画矩形框。