[数据集][目标检测]旋风检测数据集VOC+YOLO格式157张1类别 2024-06-01 yolo, 机器学习, 深度学习, 目标检测, 人工智能 32人 已看 数据集格式:Pascal VOC格式+YOLO格式(不包含分割路径的txt文件,仅仅包含jpg图片以及对应的VOC格式xml文件和yolo格式txt文件)特别声明:本数据集不对训练的模型或者权重文件精度作任何保证,数据集只提供准确且合理标注。标注类别名称:["xuanfeng"]图片数量(jpg文件个数):159。标注数量(xml文件个数):159。标注数量(txt文件个数):159。xuanfeng 框数 = 159。使用标注工具:labelImg。标注规则:对类别进行画矩形框。
YOLOv8 多种任务网络结构详细解析 | 目标检测、实例分割、人体关键点检测、图像分类 2024-06-01 yolo, 计算机视觉, 目标检测, 人工智能 50人 已看 本文仅根据模型的预测过程,即从输入图像到输出结果(图像预处理、模型推理、后处理),来展现不同任务下的网络结构,OBB 任务暂不包含。
[数据集][目标检测]猫狗检测数据集VOC+YOLO格式8291张2类别 2024-05-30 yolo, 机器学习, 深度学习, 目标检测, 人工智能 35人 已看 数据集格式:Pascal VOC格式+YOLO格式(不包含分割路径的txt文件,仅仅包含jpg图片以及对应的VOC格式xml文件和yolo格式txt文件)特别声明:本数据集不对训练的模型或者权重文件精度作任何保证,数据集只提供准确且合理标注。标注类别名称:["cat","dog"]图片数量(jpg文件个数):8291。标注数量(xml文件个数):8291。标注数量(txt文件个数):8291。使用标注工具:labelImg。标注规则:对类别进行画矩形框。cat 框数 = 4766。
[数据集][目标检测]红外兔子检测数据集VOC+YOLO格式96张1类别 2024-05-28 yolo, 计算机视觉, 深度学习, 目标检测, 人工智能 44人 已看 数据集格式:Pascal VOC格式+YOLO格式(不包含分割路径的txt文件,仅仅包含jpg图片以及对应的VOC格式xml文件和yolo格式txt文件)特别声明:本数据集不对训练的模型或者权重文件精度作任何保证,数据集只提供准确且合理标注。图片数量(jpg文件个数):96。标注数量(xml文件个数):96。标注数量(txt文件个数):96。使用标注工具:labelImg。标注类别名称:["rat"]标注规则:对类别进行画矩形框。rat 框数 = 378。
【无标题】yoloV8目标检测与实例分割--目标检测onnx模型部署 2024-05-22 yolo, 计算机视觉, 目标检测, 人工智能 42人 已看 ONNX Runtime 是一个开源的高性能推理引擎,用于部署和运行机器学习模型,其设计的目标是优化执行open neural network exchange (onnx)格式定义各模型,onnx是一种用于表示机器学习模型的开放标准。onnx模型:ONNX格式的模型文件,通常以.onnx扩展名保存,onnx文件是一种中性表示格式,独立于任何特定的深度学习框架,用于跨不同框架之间的模型转换和部署。要在不同框架或平台中部署训练的pt模型,需要利用ONNX转换工具将pt模型转换为ONNX格式。
[数据集][目标检测]伤口检测数据集VOC+YOLO格式2760张1类别 2024-05-27 yolo, 机器学习, 深度学习, 目标检测, 人工智能 83人 已看 数据集格式:Pascal VOC格式+YOLO格式(不包含分割路径的txt文件,仅仅包含jpg图片以及对应的VOC格式xml文件和yolo格式txt文件)特别声明:本数据集不对训练的模型或者权重文件精度作任何保证,数据集只提供准确且合理标注。重要说明:大部分是脚本伤口,也有一小部分是其他部分伤口。图片数量(jpg文件个数):2760。标注数量(xml文件个数):2760。标注数量(txt文件个数):2760。使用标注工具:labelImg。标注规则:对类别进行画矩形框。
[数据集][目标检测]红外车辆检测数据集VOC+YOLO格式13979张类别 2024-05-28 yolo, 计算机视觉, 深度学习, 目标检测, 人工智能 45人 已看 数据集格式:Pascal VOC格式+YOLO格式(不包含分割路径的txt文件,仅仅包含jpg图片以及对应的VOC格式xml文件和yolo格式txt文件)特别声明:本数据集不对训练的模型或者权重文件精度作任何保证,数据集只提供准确且合理标注。图片数量(jpg文件个数):13979。标注数量(xml文件个数):13979。标注数量(txt文件个数):13979。car 框数 = 247622。使用标注工具:labelImg。标注类别名称:["car"]标注规则:对类别进行画矩形框。总框数:247622。
[数据集][目标检测]红外兔子检测数据集VOC+YOLO格式96张1类别 2024-05-28 yolo, 计算机视觉, 深度学习, 目标检测, 人工智能 36人 已看 数据集格式:Pascal VOC格式+YOLO格式(不包含分割路径的txt文件,仅仅包含jpg图片以及对应的VOC格式xml文件和yolo格式txt文件)特别声明:本数据集不对训练的模型或者权重文件精度作任何保证,数据集只提供准确且合理标注。图片数量(jpg文件个数):96。标注数量(xml文件个数):96。标注数量(txt文件个数):96。使用标注工具:labelImg。标注类别名称:["rat"]标注规则:对类别进行画矩形框。rat 框数 = 378。
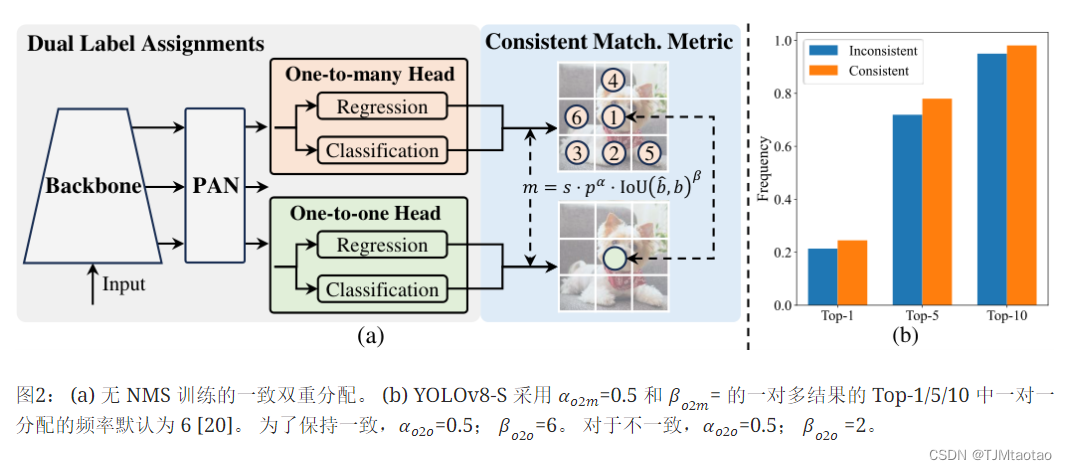
【论文阅读】 YOLOv10: Real-Time End-to-End Object Detection 2024-05-24 论文阅读, yolo, 计算机视觉, 目标检测, 人工智能 37人 已看 在过去几年中,YOLOs 因其在计算成本和检测性能之间的有效平衡而成为实时物体检测领域的主流模式。研究人员对 YOLOs 的架构设计、优化目标、数据增强策略等进行了探索,并取得了显著进展。然而,后处理对非最大抑制(NMS)的依赖阻碍了 YOLO 的端到端部署,并对推理延迟产生了不利影响。此外,YOLOs 中各种组件的设计缺乏全面彻底的检查,导致明显的计算冗余,限制了模型的能力。这使得效率不尽如人意,性能还有很大的提升空间。在这项工作中,我们旨在从后处理和模型架构两方面进一步推进 YOLO 的性能-效率边界。
[数据集][目标检测]航空发动机缺陷检测数据集VOC+YOLO格式291张4类别 2024-05-28 yolo, 机器学习, 深度学习, 目标检测, 人工智能 35人 已看 数据集格式:Pascal VOC格式+YOLO格式(不包含分割路径的txt文件,仅仅包含jpg图片以及对应的VOC格式xml文件和yolo格式txt文件)特别声明:本数据集不对训练的模型或者权重文件精度作任何保证,数据集只提供准确且合理标注。标注类别名称:[“crease”,“damage”,“dot”,“scratch”]图片数量(jpg文件个数):291。标注数量(xml文件个数):291。标注数量(txt文件个数):291。使用标注工具:labelImg。标注规则:对类别进行画矩形框。
【论文阅读】 YOLOv10: Real-Time End-to-End Object Detection 2024-05-24 论文阅读, yolo, 计算机视觉, 目标检测, 人工智能 30人 已看 在过去几年中,YOLOs 因其在计算成本和检测性能之间的有效平衡而成为实时物体检测领域的主流模式。研究人员对 YOLOs 的架构设计、优化目标、数据增强策略等进行了探索,并取得了显著进展。然而,后处理对非最大抑制(NMS)的依赖阻碍了 YOLO 的端到端部署,并对推理延迟产生了不利影响。此外,YOLOs 中各种组件的设计缺乏全面彻底的检查,导致明显的计算冗余,限制了模型的能力。这使得效率不尽如人意,性能还有很大的提升空间。在这项工作中,我们旨在从后处理和模型架构两方面进一步推进 YOLO 的性能-效率边界。
【python脚本】修改目标检测的xml标签(VOC)类别名 2024-05-28 计算机视觉, xml, 目标检测, 人工智能 40人 已看 在集成多个数据集一同训练时,可能会存在不同数据集针对同一种目标有不同的类名,可以通过python脚本修改数据内的类名映射,实现统一数据集标签名的目的。label_dict:标签类名的映射字典,key值为修改前的类名,value值为修改后的类名。new_label_dir:输出的新xml标签的目录。label_dict[‘head’] = ‘头’org_label_dir:xml标签的目录。如图,修改标签类别名成功!
YOLOv10:实时端到端目标检测 2024-05-28 yolo, 计算机视觉, 目标检测, 人工智能, 目标跟踪 69人 已看 在过去的几年里,YOLO因其在计算成本和检测性能之间的有效平衡而成为实时目标检测领域的主要范例。研究人员对 YOLO 的架构设计、优化目标、数据增强策略等进行了探索,取得了显着进展。然而,后处理对非极大值抑制(NMS)的依赖阻碍了 YOLO 的端到端部署,并对推理延迟产生不利影响。此外,YOLO中各个组件的设计缺乏全面彻底的检查,导致明显的计算冗余并限制了模型的能力。它提供了次优的效率,以及相当大的性能改进潜力。在这项工作中,我们的目标是从后处理和模型架构方面进一步提升 YOLO 的性能效率边界。
基于 PyTorch 实现目标检测、实例分割(语义分割)、全景分割、半监督对象检测多种检测任务 2024-05-20 python, 目标检测, 深度学习, pytorch, 人工智能 42人 已看 基于 PyTorch 实现目标检测、实例分割(语义分割)、全景分割、半监督对象检测多种检测任务
[数据集][目标检测]痤疮检测数据集VOC+YOLO格式915张1类别 2024-05-18 yolo, 机器学习, 深度学习, 目标检测, 人工智能 81人 已看 数据集格式:Pascal VOC格式+YOLO格式(不包含分割路径的txt文件,仅仅包含jpg图片以及对应的VOC格式xml文件和yolo格式txt文件)特别声明:本数据集不对训练的模型或者权重文件精度作任何保证,数据集只提供准确且合理标注。标注类别名称:["cuochuang"]cuochuang 框数 = 11807。图片数量(jpg文件个数):915。标注数量(xml文件个数):915。标注数量(txt文件个数):915。使用标注工具:labelImg。标注规则:对类别进行画矩形框。
【多模态融合】Cross Modal Transformer: Towards Fast and Robust 3D Object Detection 2024-05-20 3d, c语言, 计算机视觉, 目标检测, 人工智能 37人 已看 多传感器融合在自动驾驶系统中展示了其巨大优势。不同的传感器通常能提供互补的信息。例如,摄像头以透视视角捕捉信息,图像中包含丰富的语义特征,而点云则提供更多的定位和几何信息。充分利用不同传感器有助于减少不确定性,从而进行准确和鲁棒的预测。然而,由于不同模态的传感器数据在分布上的巨大差异,融合这些多模态数据一直是个挑战。当前的主流方法通常通过构建统一的鸟瞰图(BEV)表示来进行多模态特征融合,或通过查询令牌(Transformer架构)来实现多模态融合。
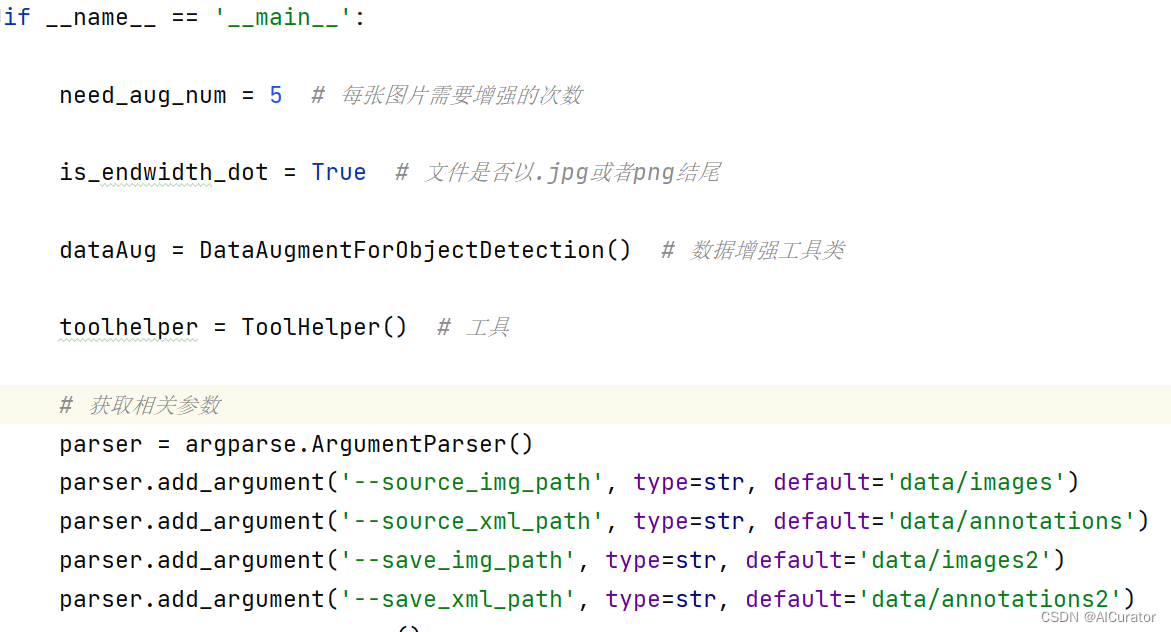
YOLOv8目标检测离线数据增强,检查标签是否越界,标签可视化! 2024-05-20 yolo, 计算机视觉, 目标检测, 人工智能 149人 已看 YOLOv8目标检测离线数据增强的方式:首先使用labelme对图像进行标注,将图像和标注文件存放到images和annotations文件夹中,然后使用离线数据增强代码对进行增强。1.在代码中设置增强次数和文件路径,选择想要数据增强的方式。
【基于 PyTorch 的 Python 深度学习】9 目标检测与语义分割(1) 2024-05-23 python, 深度学习, 目标检测, pytorch, 人工智能 34人 已看 根据吴茂贵《 Python 深度学习基于 PyTorch ( 第 2 版 ) 》撰写的学习笔记,该篇主要介绍了目标检测的相关概念及主要挑战。
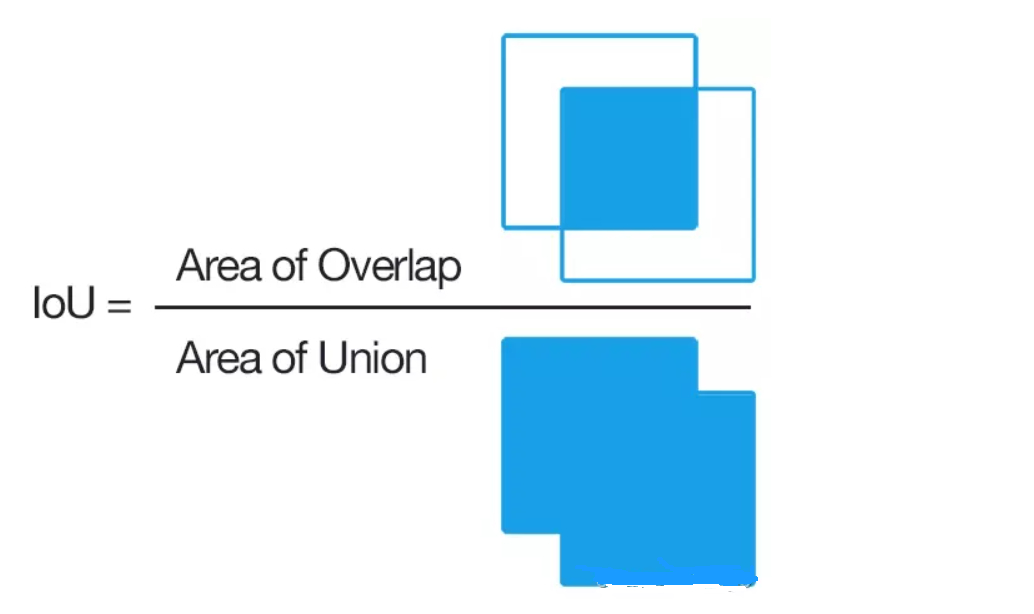
【目标检测】关于YOLO系列算法中Confidence置信度的计算和理解 2024-05-19 算法, 计算机视觉, 目标检测, 人工智能 396人 已看 关于YOLO系列算法中Confidence置信度的计算和理解
[数据集][目标检测]鱼头鱼尾检测数据集VOC+YOLO格式200张2类别 2024-05-18 yolo, 机器学习, 深度学习, 目标检测, 人工智能 24人 已看 数据集格式:Pascal VOC格式+YOLO格式(不包含分割路径的txt文件,仅仅包含jpg图片以及对应的VOC格式xml文件和yolo格式txt文件)特别声明:本数据集不对训练的模型或者权重文件精度作任何保证,数据集只提供准确且合理标注。标注类别名称:["head","tail"]图片数量(jpg文件个数):200。标注数量(xml文件个数):200。标注数量(txt文件个数):200。使用标注工具:labelImg。标注规则:对类别进行画矩形框。head 框数 = 724。