yolov8 模型架构轻量化 | 极致提速度 2024-05-16 yolo, 架构, 人工智能 78人 已看 当想要提升模型在通用计算平台上的FPS(每秒帧数或帧率)时,可以从模型架构的三个关键角度出发进行优化:模型的参数数量、浮点数运算的复杂度以及模型架构的简洁性。1. 模型的参数是否足够少参数数量是影响模型推理速度的重要因素之一。参数越少的模型,其计算量和内存占用通常也越小,因此推理速度更快。优化策略模型剪枝:通过移除模型中不重要的参数(如权重较小的连接)来减少参数数量。知识蒸馏:使用一个更大的教师模型来指导一个小模型的训练,使得小模型能够学习到教师模型的性能,同时保持较小的参数规模。选择轻量级模型。
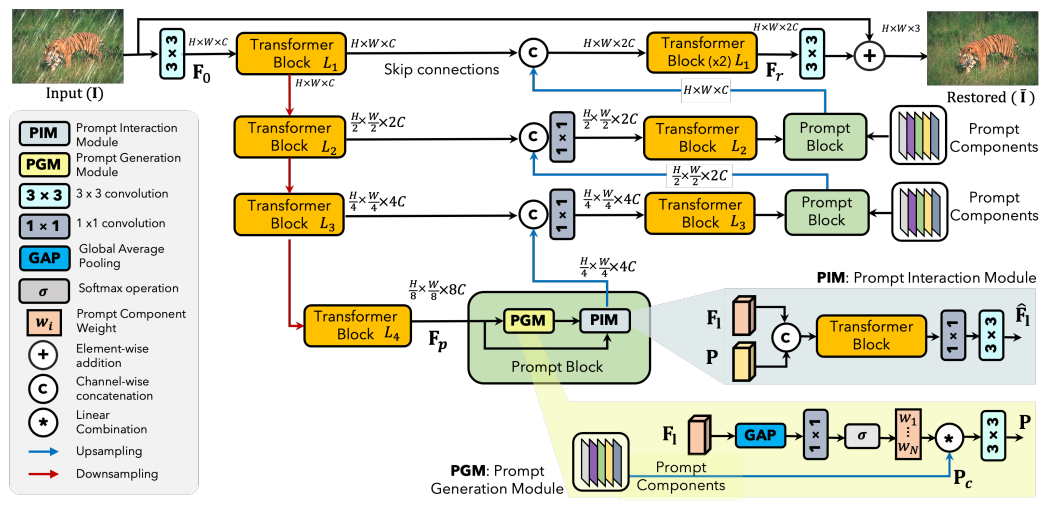
YoloV9改进策略:Block改进|PromptIR(NIPS‘2023)样|轻量高效,即插即用(适用于分类、分割、检测等多种场景) 2024-05-22 yolo, python, 深度学习, prompt, 分类 102人 已看 【代码】YoloV9改进策略:Block改进|PromptIR(NIPS‘2023)样|轻量高效,即插即用(适用于分类、分割、检测等多种场景)
[数据集][目标检测]鱼头鱼尾检测数据集VOC+YOLO格式200张2类别 2024-05-18 yolo, 机器学习, 深度学习, 目标检测, 人工智能 73人 已看 数据集格式:Pascal VOC格式+YOLO格式(不包含分割路径的txt文件,仅仅包含jpg图片以及对应的VOC格式xml文件和yolo格式txt文件)特别声明:本数据集不对训练的模型或者权重文件精度作任何保证,数据集只提供准确且合理标注。标注类别名称:["head","tail"]图片数量(jpg文件个数):200。标注数量(xml文件个数):200。标注数量(txt文件个数):200。使用标注工具:labelImg。标注规则:对类别进行画矩形框。head 框数 = 724。
[数据集][目标检测]手枪机枪刀检测数据集VOC+YOLO格式5990张3类别 2024-05-19 yolo, 计算机视觉, 目标检测, 深度学习, 人工智能 96人 已看 数据集格式:Pascal VOC格式+YOLO格式(不包含分割路径的txt文件,仅仅包含jpg图片以及对应的VOC格式xml文件和yolo格式txt文件)特别声明:本数据集不对训练的模型或者权重文件精度作任何保证,数据集只提供准确且合理标注。标注类别名称:[“Rifle”,“knife”,“pistol”]图片数量(jpg文件个数):5990。标注数量(xml文件个数):5990。标注数量(txt文件个数):5990。使用标注工具:labelImg。标注规则:对类别进行画矩形框。
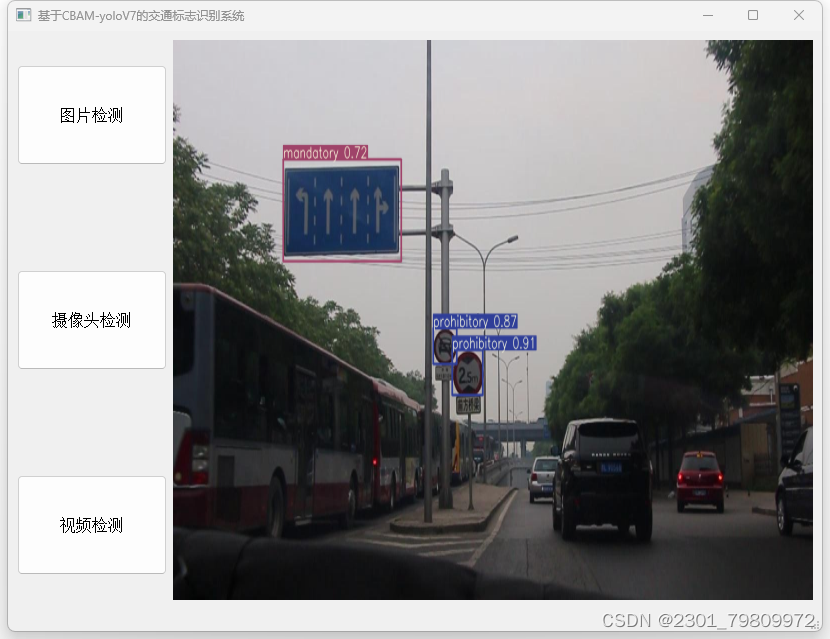
深度学习之基于YoloV7交通标志目标检测系统 2024-05-18 yolo, 深度学习, 目标检测, 人工智能, 目标跟踪 188人 已看 一、项目背景与意义交通标志在道路交通中起着至关重要的作用,它们为驾驶员提供必要的道路信息和行驶指导。然而,随着交通流量的不断增加和路况的日益复杂,传统的交通标志检测方法已经难以满足现代交通管理的需求。因此,开发一个高效、准确的交通标志目标检测系统具有重要的现实意义和广阔的应用前景。基于YoloV7的交通标志目标检测系统旨在利用深度学习技术,实现对交通标志的快速、准确识别与定位。
[保姆式教程]使用目标检测模型YOLO V5 OBB进行旋转目标的检测:训练自己的数据集(基于卫星和无人机的农业大棚数据集) 2024-05-17 yolo, 无人机 88人 已看 最近需要做基于卫星和无人机的农业大棚的旋转目标检测,基于YOLO V5 OBB的原因是因为尝试的第一个模型就是YOLO V5,后面会基于其他YOLO系列模型做农业大棚的旋转目标检测,尤其是YOLO V9,YOLO V9目前还不能进行旋转目标的检测,需要修改代码。
[保姆式教程]使用目标检测模型YOLO V5 OBB进行旋转目标的检测:训练自己的数据集(基于卫星和无人机的农业大棚数据集) 2024-05-17 yolo, 无人机 88人 已看 最近需要做基于卫星和无人机的农业大棚的旋转目标检测,基于YOLO V5 OBB的原因是因为尝试的第一个模型就是YOLO V5,后面会基于其他YOLO系列模型做农业大棚的旋转目标检测,尤其是YOLO V9,YOLO V9目前还不能进行旋转目标的检测,需要修改代码。
[数据集][目标检测]鱼头鱼尾检测数据集VOC+YOLO格式200张2类别 2024-05-18 yolo, 机器学习, 深度学习, 目标检测, 人工智能 71人 已看 数据集格式:Pascal VOC格式+YOLO格式(不包含分割路径的txt文件,仅仅包含jpg图片以及对应的VOC格式xml文件和yolo格式txt文件)特别声明:本数据集不对训练的模型或者权重文件精度作任何保证,数据集只提供准确且合理标注。标注类别名称:["head","tail"]图片数量(jpg文件个数):200。标注数量(xml文件个数):200。标注数量(txt文件个数):200。使用标注工具:labelImg。标注规则:对类别进行画矩形框。head 框数 = 724。
主干网络篇 | YOLOv8更换主干网络之MobileNeXt | 新一代移动端模型MobileNeXt来了! 2024-05-22 yolo, 网络 64人 已看 MobileNeXt是由微软研究院提出的一种高效的卷积神经网络结构,它在保持模型轻量级的同时,能够获得较高的性能。我们将利用MobileNeXt替换YOLOv8的主干网络,以期提升YOLOv8的检测性能。🌈
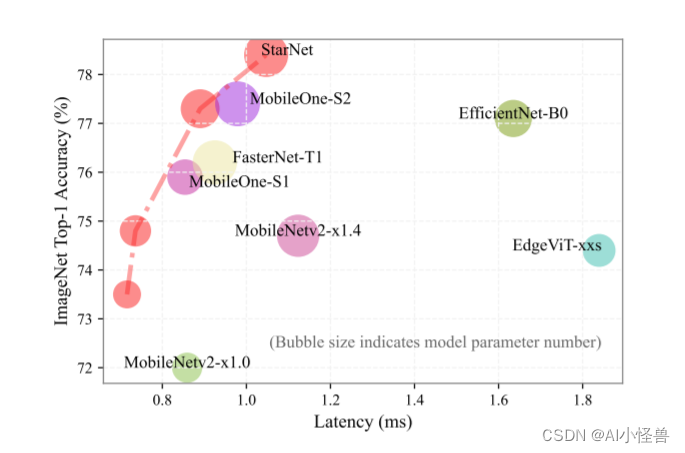
YOLOv8独家改进:逐元素乘法(star operation)二次创新 | 微软新作StarNet:超强轻量级Backbone CVPR 2024 2024-05-14 yolo, r语言, microsoft, 开发语言 142人 已看 逐元素乘法(star operation)二次创新
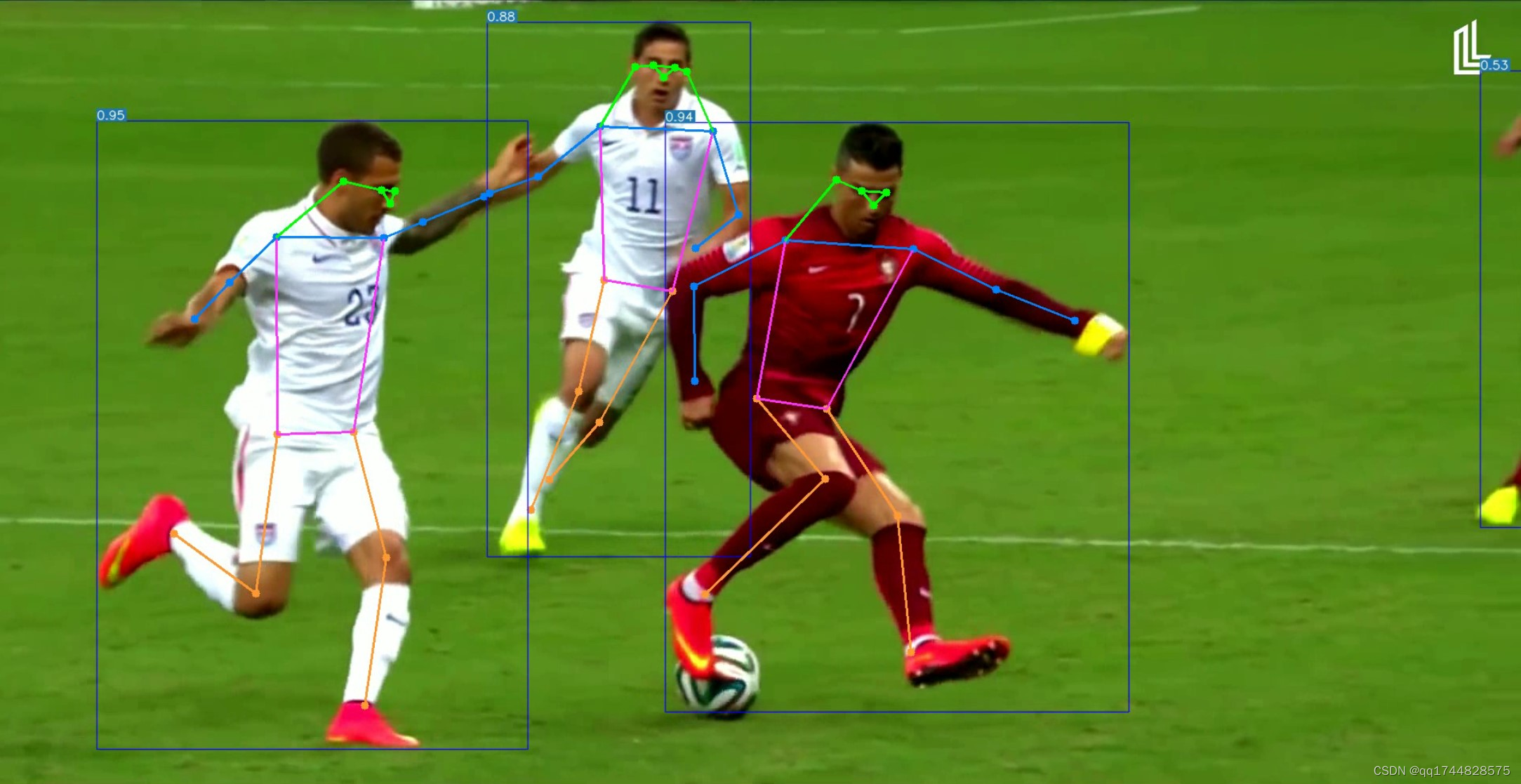
深度学习之基于YoloV7+OpenPose姿态识别系统 2024-05-17 yolo, 计算机视觉, 深度学习, 人工智能, 目标跟踪 197人 已看 一、系统背景随着深度学习技术的快速发展,其在计算机视觉领域的应用也日益广泛。姿态识别作为计算机视觉的一个重要分支,对于人机交互、运动分析、动作捕捉、虚拟现实等领域具有重要意义。YOLOv7和OpenPose作为两种先进的深度学习算法,分别在目标检测和人体姿态估计方面表现出色。因此,结合YOLOv7和OpenPose的优势,构建基于YOLOv7+OpenPose的姿态识别系统,具有广阔的应用前景。二、系统组成。
YOLOv8改进 | 卷积模块 | 用DWConv卷积替换Conv【轻量化网络】 2024-05-18 yolo, cnn, 深度学习, pytorch, 神经网络 600人 已看 YOLOv8改进,yolov8,yolov8创新,yolov8涨点
[数据集][目标检测]抽烟喝酒检测数据集VOC+YOLO格式1026张2类别 2024-05-18 yolo, 机器学习, 深度学习, 目标检测, 人工智能 78人 已看 数据集格式:Pascal VOC格式+YOLO格式(不包含分割路径的txt文件,仅仅包含jpg图片以及对应的VOC格式xml文件和yolo格式txt文件)特别声明:本数据集不对训练的模型或者权重文件精度作任何保证,数据集只提供准确且合理标注。标注类别名称:[“drinking”,“smoking”]图片数量(jpg文件个数):1026。标注数量(xml文件个数):1026。标注数量(txt文件个数):1026。使用标注工具:labelImg。标注规则:对类别进行画矩形框。
基于yolov5+streamlit目标检测演示系统设计 2024-05-12 yolo, 计算机视觉, 目标检测, 人工智能, 目标跟踪 204人 已看 首先,该系统支持图片目标检测,用户只需上传一张图片,系统便能够迅速识别出图片中的各类目标,并在图片上用不同颜色的矩形框进行标注,同时显示目标的类别和置信度。无论是监控视频、教学视频还是娱乐视频,用户只需将视频文件上传到系统中,系统便能够实时地对视频中的每一帧进行目标检测,并最终将检测结果以视频流的形式展示给用户。用户只需将摄像头接入系统,系统便能够实时地捕捉摄像头拍摄的画面,并对画面中的目标进行检测和标注。用户无需具备专业的编程知识,只需通过简单的界面操作,便能够轻松实现目标检测的可视化展示。
面向侧扫声纳目标检测的YOLOX-ViT知识精馏 2024-05-08 yolo, 计算机视觉, 目标检测, 人工智能, 目标跟踪 96人 已看 在本文中,作者提出了YOLOX-ViT这一新型目标检测模型,并研究了在不牺牲性能的情况下,知识蒸馏对模型尺寸减小的有效性。聚焦于水下机器人领域,作者的研究解决了关于较小模型的可行性以及视觉Transformer层在YOLOX中影响的关键问题。此外,作者引入了一个新的侧扫声纳图像数据集,并使用它来评估作者的目标检测器的性能。结果显示,知识蒸馏有效减少了墙体检测中的误报。另外,引入的视觉Transformer层在水下环境中显著提高了目标检测的准确性。
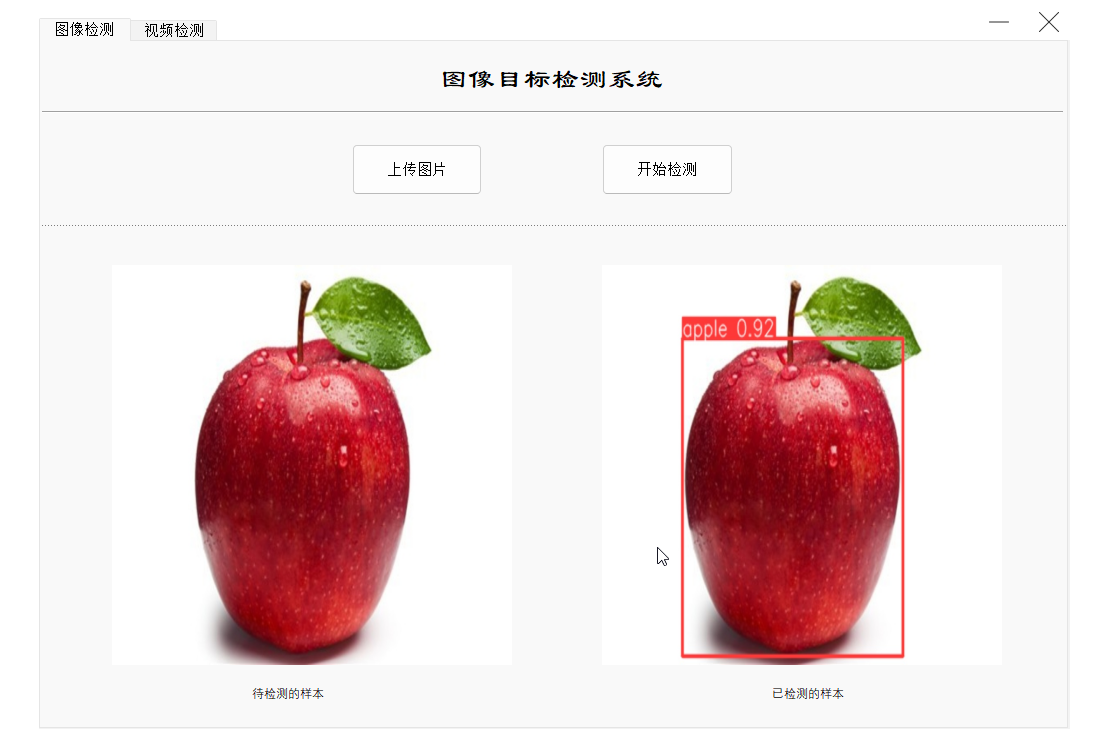
基于yolov8的水果检测系统,系统既支持图像检测,也支持视频和摄像实时检测(pytorch框架)【python源码+UI界面+功能源码详解】 2024-05-11 yolo, python, 机器学习, 音视频, 深度学习, 开发语言 99人 已看 基于yolov8的水果检测系统是在pytorch框架下实现的,这是一个完整的项目,包括代码,数据集,训练好的模型权重,模型训练记录,ui界面等。ui界面由pyqt5设计实现。
YOLOv9改进策略 | 添加注意力篇 | 利用YOLO-Face提出的SEAM注意力机制优化物体遮挡检测(附代码 + 修改教程) 2024-05-09 yolo, 计算机视觉, 深度学习, 人工智能 170人 已看 本文给大家带来的改进机制是由YOLO-Face提出能够改善物体遮挡检测的注意力机制SEAM,注意力网络模块旨在补偿被遮挡面部的响应损失,通过增强未遮挡面部的响应来实现这一目标,其希望通过学习遮挡面和未遮挡面之间的关系来改善遮挡情况下的损失从而达到改善物体遮挡检测的效果,本文将通过介绍其主要原理后,提供该机制的代码和修改教程,并附上运行的yaml文件和运行代码,小白也可轻松上手。。欢迎大家订阅我的专栏一起学习YOLO!YOLOv9有效涨点专栏-持续复现各种顶会内容-有效涨点-全网改进最全的专栏目录。
【论文阅读】<YOLOP: You Only Look Once for PanopticDriving Perception> 2024-05-09 论文阅读, yolo 58人 已看 全视驾驶感知系统是自动驾驶的重要组成部分。一个高精度的实时感知系统可以帮助车辆在驾驶时做出合理的决策。我们提出了一个全视驾驶感知网络(您只需寻找一次全视驾驶感知网络(YOLOP)),以同时执行交通目标检测、可驾驶区域分割和车道检测。它由一个用于特征提取的编码器和三个用于处理特定任务的解码器组成。我们的模型在具有挑战性的BDD100K数据集上表现得非常好,在准确性和速度方面,在所有三个任务上都实现了最先进的水平。此外,我们通过消融研究验证了我们的多任务学习模型对联合训练的有效性。
实例分割——Mask R-CNN、YOLOV8、RTMDET、DeepLab四种实例分割算法比对 2024-05-09 yolo 117人 已看 与目标检测不同,实例分割不仅识别对象的存在,还为每个检测到的对象生成一个像素级别的掩码,这允许更精细的分析和编辑。从上面这个例子可以看出,检测任务定位了对象的包围框,语义分割分割出了人这个类别,不过把所有的人一起分割了,实例分割区分出了每个人,并分别进行了分割。为了解决RoI Pooling中的量化问题,Mask R-CNN引入了RoIAlign层,它通过双线性插值精确地计算输入特征在RoI上的值,而不进行量化,从而更好地保持空间对齐,这对于生成高质量的分割掩码至关重要。
【项目】使用Yolov8 + tesseract 实现“营业执照”信息解析(OCR) + 输入可为图片或者pdf + 完整代码 + 整体方案 + 全网首发 2024-05-09 yolo, pdf, 运维, linux, ocr 162人 已看 使用Yolov8 + tesseract 实现“营业执照”信息解析(OCR) + 输入可为图片或者pdf + 完整代码 + 整体方案 + 全网首发