代码杂谈 之 pyspark如何做相似度计算 2024-06-05 spark, 分布式, 大数据 106人 已看 在 PySpark 中,计算 DataFrame 两列向量的差可以通过使用 UDF(用户自定义函数)和 Vector 类型完成。这里有一个示例,展示了如何使用 PySpark 的。首先,确保你已经安装了 PySpark 并且正确设置了 SparkSession。
深入解析Kafka消息传递的可靠性保证机制 2024-06-08 c#, linq, kafka, 数据库, 分布式 118人 已看 Kafka在设计上提供了不同层次的消息传递保证,包括at most once(至多一次)、at least once(至少一次)和exactly once(精确一次)。每种保证通过不同的机制实现,下面详细介绍Kafka如何实现这些消息传递保证。
高并发项目-分布式Session解决方案 2024-05-31 分布式 48人 已看 / 进入到商品首页// 判断是否有用户信息// 将用户信息存入model中,返回到前端import com/*** Description: 自定义参数解析器/** 判断是否支持要转换的参数类型,简单来说,就是在这里设置要解析的参数类型// 如果参数类型是User,则进行解析 Class
win setup kafka 3.6.2 Step-by-Step Guide 2024-06-05 c#, linq, kafka, 分布式 81人 已看 【代码】win setup kafka 3.6.2 Step-by-Step Guide。
wpf工程中加入Hardcodet.NotifyIcon.Wpf生成托盘 2024-06-05 hdfs, hadoop, wpf, 分布式, 大数据 74人 已看 注意在application中一定要加入这一行代码: xmlns:tb="http://www.hardcodet.net/taskbar"3、创建ViewModelBase类。再创建TaskbarIconViewModel类继承ViewModelBase类。1、在项目中用nuget引入Hardcodet.NotifyIcon.Wpf。2、在App.xaml中创建托盘界面,代码是写在 App.xaml 里面。然后在中加入如下代码。
代码杂谈 之 pyspark如何做相似度计算 2024-06-05 spark, 分布式, 大数据 103人 已看 在 PySpark 中,计算 DataFrame 两列向量的差可以通过使用 UDF(用户自定义函数)和 Vector 类型完成。这里有一个示例,展示了如何使用 PySpark 的。首先,确保你已经安装了 PySpark 并且正确设置了 SparkSession。
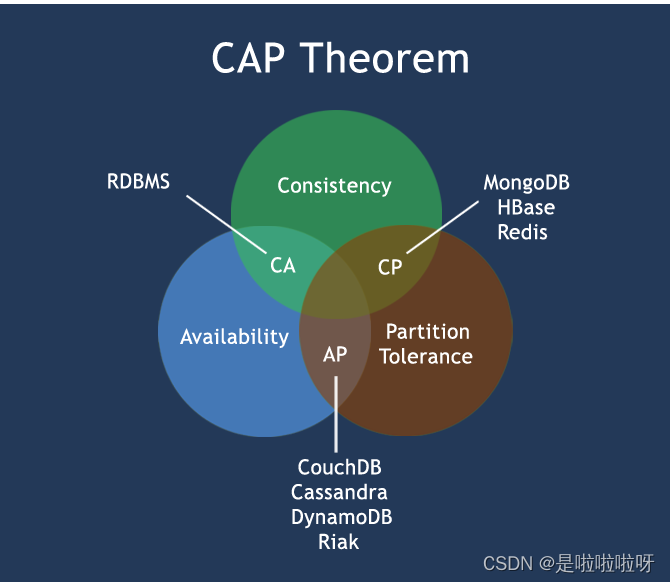
java分布式的ACP是什么 2024-06-05 java, 分布式, 开发语言 64人 已看 否则无法保证一致性,Consul 遵循CAP原理中的CP原则,保证了强一致性和分区容错性,且使用的是Raft算法,比zookeeper使用的Paxos算法更加简单。虽然保证了强一致性,但是可用性就相应下降了,例如服务注册的时间会稍长一些,因为 Consul 的 raft 协议要求必须过半数的节点都写入成功才认为注册成功;当数据出现不一致时,虽然A, B上的注册信息不完全相同,但每个Eureka节点依然能够正常对外提供服务,这会出现查询服务信息时如果请求A查不到,但请求B就能查到。
WPF音乐播放器 零基础4个小时左右 2024-06-04 hadoop, wpf, 分布式, 大数据 60人 已看 WPF做播放器 webfrom转wpf用久的熟手说得最多的是 转回去做winfrom难。小编表示 wpf 界面代码写起来 比vue webfrom react 都麻烦。ps:学wpf没有个大屏是个阻力哈哈哈。指向信息帮助类 有点深入自己看。UI源码缺失 等续集吧。细节UI 播放控制台。
Hadoop笔记 2024-06-08 笔记, hadoop, 分布式, 大数据 56人 已看 1.hadoop环境搭建,linux命令(vi);2.分布式的基本概念,cap理论(遵循此原则开发分布式数据库),hdfs,mapreduce;3.3.1;3.2重点;4.map,reduce过程,优缺点(第一二个版本);6.6.3;7.sqoop;8.Zookeeper,yarn,mapreduce优缺点解决问题。
Kafka监控系统efak的安装 2024-06-08 kafka, 分布式 65人 已看 下载地址连接不稳定,可以多次尝试直到成功连接下载。4.mysql中创建kafkaEagle库。# 配置KAFKA_EAGLE环境变量。查看到解压后包含一个安装包,再解压。关闭Kafka集群后重新启动。1.解压安装包并重命名。密码123456 登录。移至上级目录并重命名。5. 开启JMX监控。
7.8k Star! 推荐一款分布式文件管理系统 2024-06-03 r语言, 分布式 80人 已看 项目是一款基于 Spring Boot 2 + VUE CLI@3(Vue2) 框架开发的分布式文件管理系统,旨在为用户和企业提供一个简单、方便的文件存储方案,能够以完善的目录结构体系,对文件进行管理。项目使用前后台分离的模式进行开发和部署,对于开发者,前后台职责划分的比较清晰,对于使用者,可以将前后台部署到不同的机器上。
Kafka之Broker原理 2024-06-03 kafka, 分布式 53人 已看 本文介绍Broker服务器,主要讲了Broker中日志的存储,从大到小依次为Partition、Segment,副本机制的具体存储形式,是怎么进行负载均衡和容灾保障的,在Segment中我们直到了Segment是由一个Log文件和两个索引文件组成的,索引文件主要起的是一个提升查询效率的作用。随后当kafka中log文件过大的时候,kagka中提供了两种维度上的删除策略以及相同key去重压缩的compact策略。
kafka的leader和follower 2024-06-08 kafka, 分布式 52人 已看 在Linux中强制杀掉该Kafka的进程,然后观察leader的情况。kafka的leader负责读写,follower不能读写数据(确保每个消费者消费的数据是一致的),kafka一个topic有多个分区leader,一样可以实现负载均衡。如果kafka是居于ZK进行选举,ZK的压力比较大,例如某个节点崩溃,这个节点上不仅仅只有一个leader,是有不少的leader需要选举,通过ISR可以快速选举。kafka会再创建topic的时候尽量让分配分区的leader在不同的broker中,就是负载均衡。
Spark 中repartition和coalesce的区别 2024-06-04 spark, 分布式, 大数据 85人 已看 在Apache Spark中,和coalesce是两种用于重新分区RDD或DataFrame的转换操作。它们的主要区别在于它们对分区数量的处理方式和使用场景。repartition 是 coalesce shuffle为True的实现。两者使用的场景。首先,repartition 的shuffle比较慢, coalesce 虽然不需要shuffle,但是,指定coalesce保留的partition数目后,只有相应数目的executor-cores 进行合并,其他的核会进行空计算,导致机器利用效率比较低。
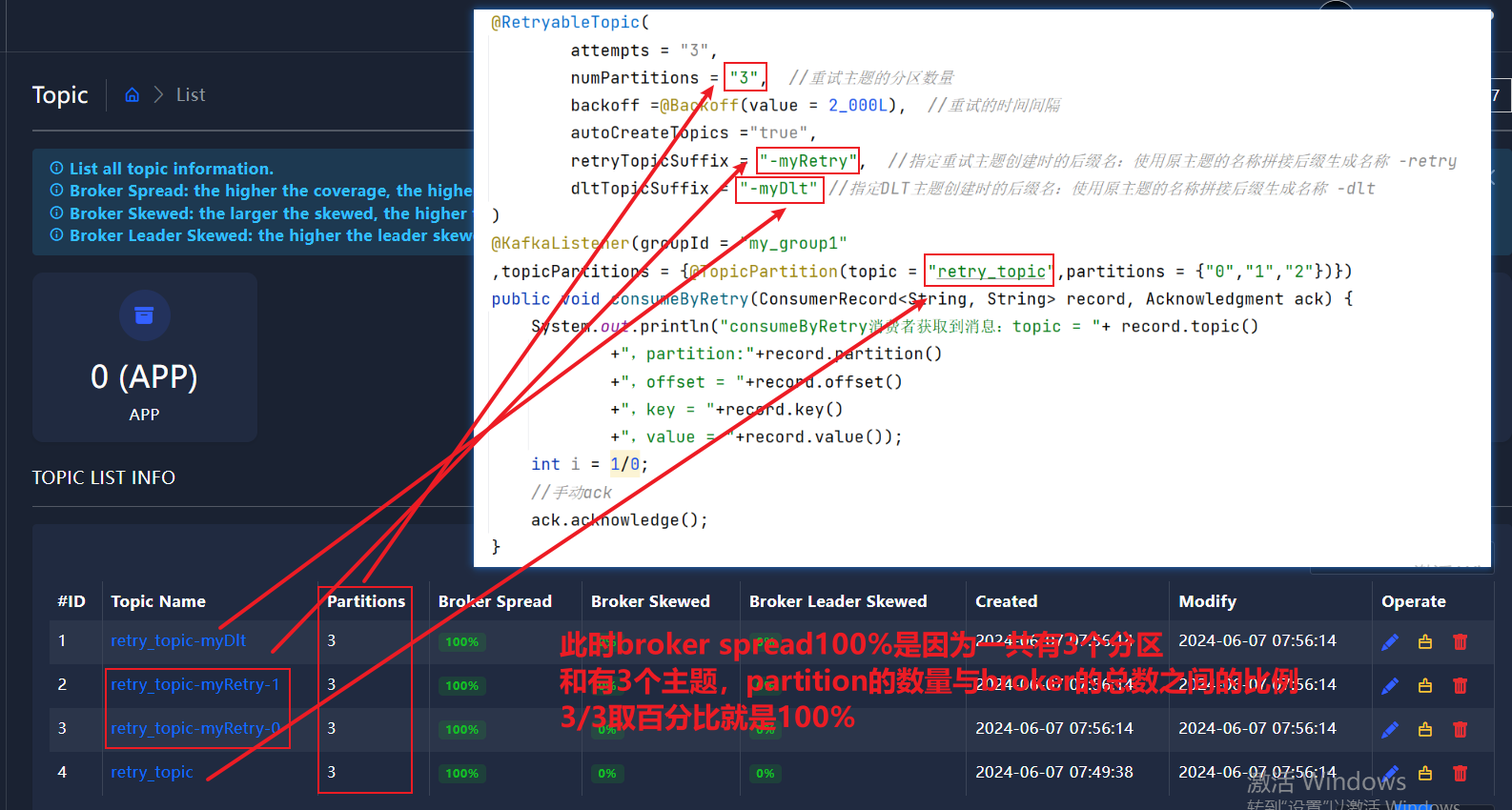
kafka-重试和死信主题(SpringBoot整合Kafka) 2024-06-07 c#, linq, kafka, 分布式, sql 48人 已看 在Kafka中,DLT通常指的是 。Dead Letter Topic(DLT)的定义与功能:DLT的使用与意义:总之,在Kafka中,DLT是一个用于处理无法被成功消费的消息的特殊Topic,它提供了一种灵活且可靠的机制来保障Kafka系统的稳定性和可靠性。3.2、引入spring-kafka依赖3.3、创建SpringBoot启动类3.4、创建生产者发送消息3.5、创建消费者消费消息
项目纪实 | 版本升级操作get!GreatDB分布式升级过程详解 2024-05-31 分布式 44人 已看 确认客户的C#驱动版本为MySQL 6.9.8,需升级驱动到MySQL 8.0.32,数据库中连接串可以添加 OldGuids=true,然后数据库连接正常,汉字写入正常;从日志中发现,实例启动期间进行了redo恢复。不升级C#驱动,将vscode工具升级到2013以上版本,数据库中连接串可以添加 OldGuids=true,之后数据库连接正常,汉字写入正常。在升级之前,万里数据库项目团队帮助客户在本地测试环境构造了相同的基础版本,导入部分生产数据,尽量复刻生产环境进行升级,显示测试升级正常。