【面试八股总结】MySQL索引(二):B+树数据结构、索引使用场景、索引优化、索引失效 2024-05-28 面试, 职场和发展, 数据结构, b树 134人 已看 B 树是一个,每一个节点最多可以包括 M 个子节点,M 称为 B 树的阶,所以 B 树就是一个多叉树。叶子节点(最底部的节点)才会存放实际数据(索引+记录),非叶子节点只会存放索引;所有索引都会在叶子节点出现,叶子节点之间构成一个有序链表;非叶子节点的索引也会同时存在在子节点中,并且是在子节点中所有索引的最大(或最小)。非叶子节点中有多少个子节点,就有多少个索引;
数据结构的快速排序(c语言版) 2024-05-31 算法, java, c语言, 数据结构, 开发语言 99人 已看 快速排序是一种常用的排序算法,它是基于分治策略的一种高效排序算法。2.快排的适用场景大规模数据排序:快速排序的平均时间复杂度为O(nlogn),在处理大规模数据时比其他算法如冒泡排序、插入排序更加高效。内存受限的环境:快速排序是一种就地排序算法,不需要额外的存储空间,这在内存受限的环境(如嵌入式系统)中更有优势。数据较为随机分布:快速排序的性能最佳情况发生在数据较为随机分布的情况下。如果数据已经基本有序或完全逆序,则会退化为O(n^2)的时间复杂度。
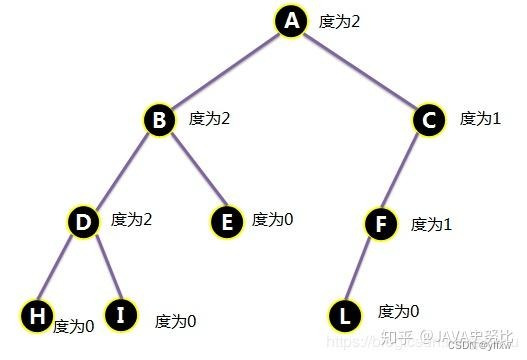
【数据结构】详解二叉树 2024-05-31 算法, 数据结构 64人 已看 在这个方法中,我们用firstchild指针找当前节点的第一个孩子节点(A),再用pnextbrother指针找到后续的孩子节点(B,C)找完之后接着用firstchild找到D,然后重复上面的操作,直到找完为止;对于深度为K的,有n个结点的二叉树,当且仅当其每一个结点都与深度为K的满二叉树中编号从1至n的结点一一对应时称之为完全二叉树。:若一个结点含有子结点,则这个结点称为其子结点的父结点;:以某结点为根的子树中任一结点都称为该结点的子孙。:一个结点含有的子树的根结点称为该结点的子结点;
数据结构的快速排序(c语言版) 2024-05-31 算法, java, c语言, 数据结构, 开发语言 97人 已看 快速排序是一种常用的排序算法,它是基于分治策略的一种高效排序算法。2.快排的适用场景大规模数据排序:快速排序的平均时间复杂度为O(nlogn),在处理大规模数据时比其他算法如冒泡排序、插入排序更加高效。内存受限的环境:快速排序是一种就地排序算法,不需要额外的存储空间,这在内存受限的环境(如嵌入式系统)中更有优势。数据较为随机分布:快速排序的性能最佳情况发生在数据较为随机分布的情况下。如果数据已经基本有序或完全逆序,则会退化为O(n^2)的时间复杂度。
[每周一更]-(第99期):MySQL的索引为什么用B+树? 2024-05-31 mysql, 数据库, 数据结构, b树 132人 已看 B+树通过将数据存储在叶子节点并使用链表连接叶子节点,实现了高效的范围查询和排序操作,同时减少了磁盘I/O操作的次数,提供了稳定的查询性能。理解为什么MySQL选择使用B+树而不是B树或其他树结构,首先需要深入了解B+树和B树的特性及其在数据库检索中的表现。B+树:在B树的基础上,将非叶节点改造为不存储数据的纯索引节点,进一步降低了树的高度;红黑树:通过舍弃严格的平衡和引入红黑节点,解决了AVL旋转效率过低的问题,但是在磁盘等场景下,树仍然太高,IO次数太多;各种树解决的问题以及面临的新问题。
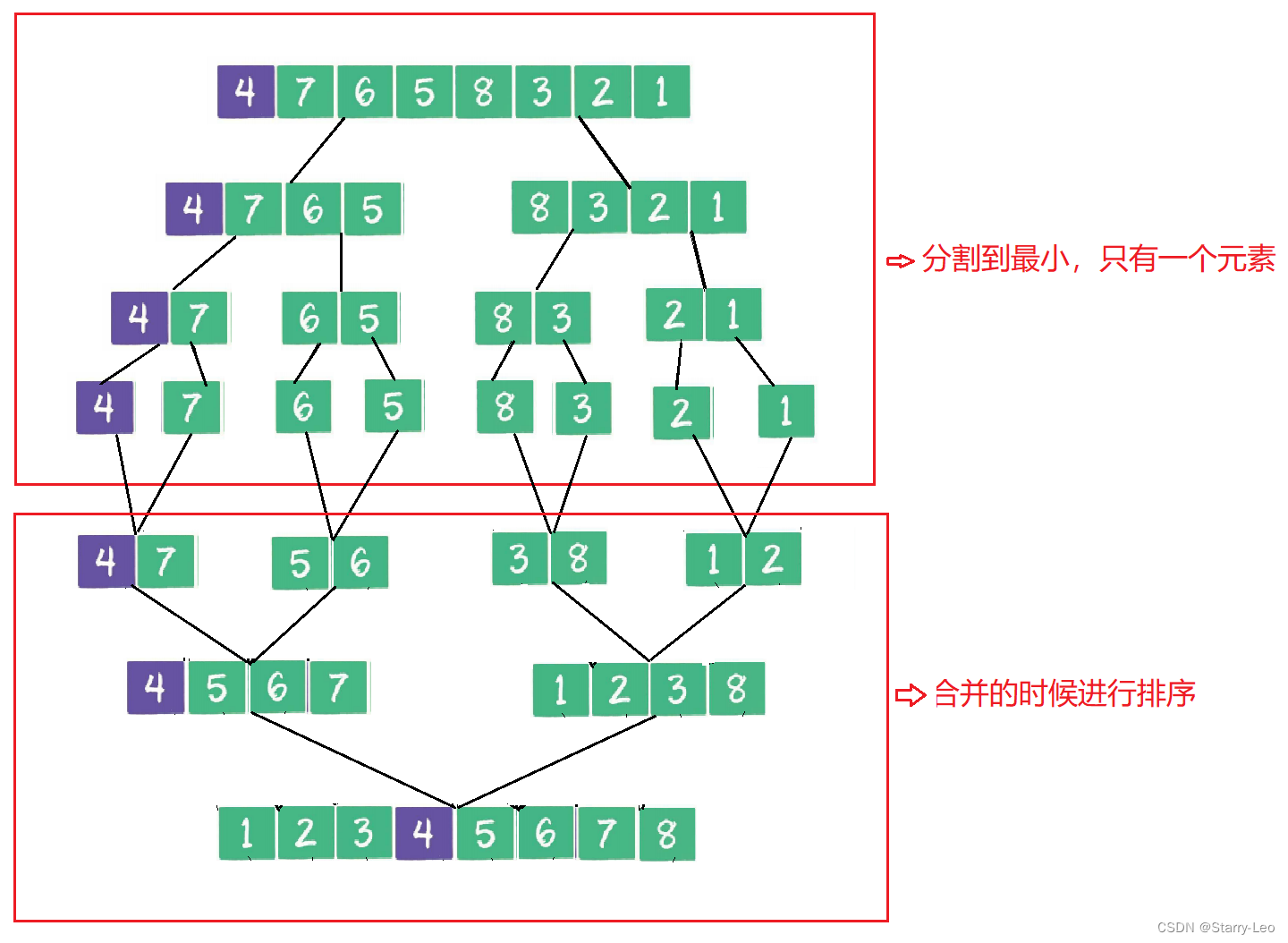
算法(十)归并排序 2024-05-31 算法, java, 排序算法, 数据结构, 开发语言 90人 已看 归并排序(merge sort)是一个采用了分治法的典型应用,首先将数据一半一半的向下拆分,直到拆分到最小元素为止;然后从拆分的最小元素开始,按照原路径进行合并,合并的时候进行排序;直到全部元素合并完成,排序完成。归并排序使用了递归思想(一级一级向下拆分、然后按照原路径一级一级向上合并)
P3881 2024-05-31 算法, java, leetcode, 数据结构, 开发语言 90人 已看 二分:枚举两个牛之间的最小距离,左端点是1,右端点是篱笆总长度。如果两头牛之间距离是Mid不合法,则返回0(false);如果两头牛之间距离是Mid合法,则返回1(true)。
java实现 将List<User> 里面很多数据的几个字段提取出来快速写到txt 文件里面 2024-05-28 原型模式, list, 数据结构 168人 已看 方法来确保数据被立即写入到文件中,而不是等到缓冲区满了才写入。虽然在大多数情况下,当流关闭时缓冲区会被自动刷新,但为了确保数据被立即写入,最好是在写入数据后调用。List 这个里面有很多的数据,现在要把他里面的a,B,C,D这4个字段提取出来,并且把数据都写到txt 文件里面,每一个数据一行,各个数值用逗号隔开。,你可以确保在流关闭之前数据被立即写入到文件中。这样可以避免在某些情况下出现数据未被写入的问题。在 BufferedWriter 写入数据后,有时候需要调用。
Java—选择排序 2024-05-22 算法, java, 排序算法, 数据结构, 开发语言 79人 已看 它的基本思想是从待排序的数据中选择最小(或最大)的元素,放到已排序序列的末尾(或开头),然后再从剩余未排序的元素中选择最小(或最大)的元素,放到已排序序列的末尾(或开头),以此类推,直到全部元素排序完成。选择排序的时间复杂度为O(n^2),其中n为待排序数组的长度。尽管选择排序的时间复杂度较高,但它简单易懂,适用于小规模数据的排序。对于大规模数据,更高效的排序算法如快速排序和归并排序更为常用。以上代码通过遍历整个数组,找到剩余未排序部分的最小值,并将其与当前位置的元素交换,重复这个过程直到数组排序完成。
数据结构——不相交集(并查集) 2024-05-27 算法, 数据结构 58人 已看 一、基本概念一、基本概念关系:定义在集合S上的关系指对于a,b∈S,若aRb为真,则a与b相关等价关系:满足以下三个特性的关系R称为等价关系(1)对称性,aRb为真则bRa为真;(2)反身性,aRa为真;(3)传递性,aRb为真,bRc为真,则aRc为真等价类:等价类E是集合S的子集,其中E内的任意两个元素构成等价关系不相交集:将集合S分为若干个等价类,等价类之间不包含相同的元素,对于x∈S,x只属于S中一个等价类。由于子集之间不包含相同的元素,将这样的集合称为不相交集。
04-树5 Root of AVL Tree(浙大数据结构PTA习题) 2024-05-29 数据结构 48人 已看 本题主要考察平衡二叉树的四种平衡调整情况,即左单旋、右单旋、左-右双旋、右-左双旋。
java中String、List、数组之间的转换方式 2024-05-29 运维, linux, list, windows, 数据结构 97人 已看 在Java中,StringList和数组(如String[])之间的转换是常见的操作。下面是如何在它们之间进行转换的示例。
数据结构-堆排序问题 2024-05-27 算法, 数据结构 54人 已看 在建堆之后,函数进入一个循环,每次循环中,它将堆顶元素(当前堆中的最小元素)与当前堆的最后一个元素交换。然后,堆的大小减少 1,并且对剩余的堆进行向下调整以保持最小堆性质。如果相反的话,会导致根节点变化,从而导致逻辑混乱,数组里面的数值少的时候是不明显的,但是多的时候就不行了。函数来构建一个小顶堆(最小堆)。:循环继续进行,直到堆的大小减小到 0。1,需要在数组里面进行排序,我们可以采取在数组建堆。函数实现了一个堆排序算法,它接收一个整数数组。2,然后交换收尾元素,每次调整的数值减少1。
C语言序列化与反序列化--TCL中支持的数据结构(二) 2024-05-30 java, c语言, 前端, 数据结构, javascript 107人 已看 如果您计划在您的平台上使用tpl的f格式字符序列化double,首先要确保您的double是64位的。变长数组可以包含简单或复杂的元素——例如,整型数组A(i),整型/双精度对数组A(if),甚至是嵌套数组A(A(if))。一般来说,尽可能使用固定长度的数组,必要时使用可变长度的数组。)都有自己的索引号。将索引号传递给tpl_pack和tpl_unpack,以指定要处理哪个变长数组(或者索引号为0的情况下的非数组)。当您解包二进制缓冲区时,tpl将自动分配它,并将用它的地址和长度填充tpl_bin结构。