【StableDiffusion】Embedding 底层原理,Prompt Embedding,嵌入向量 2024-06-13 算法, 机器学习, 人工智能, embedding, prompt 198人 已看 Embedding 是将自然语言词汇,映射为 固定长度 的词向量 的技术· 说到这里,需要介绍一下 One-Hot 编码 是什么。· One-Hot 编码· 这有坏处,它不仅计算量更大,而且,它是,因为每个词汇表中,每个 One-Hot 矩阵对应的 prompt 都不同。来看看,降维算法能够将这些被 Embedding 转化了的向量在 2维 坐标系上展现成什么样:很明显,意思越是不相同的词语,他们的向量距离在二维平面上也相距越远越是意思相近的词语(cat,猫;
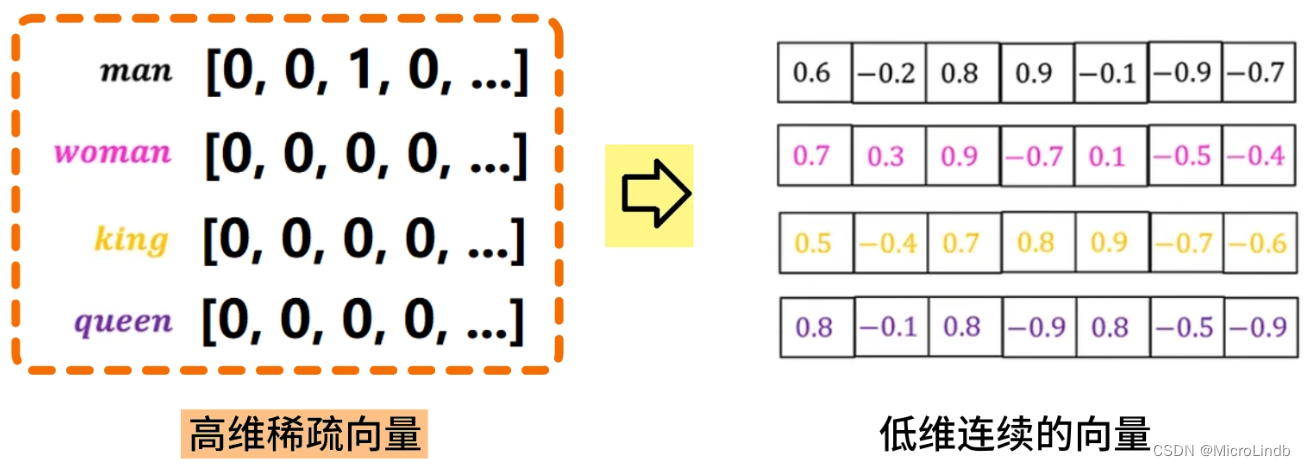
精通推荐算法8:Embedding表征学习 -- 总体架构 2024-05-29 算法, 架构, 机器学习, 人工智能, embedding, 推荐算法 207人 已看 同时,它包含大量语义信息,可以很好地度量特征间的相似度,并具备一定的模糊查找能力。一般来说,两个特征越相似,其。常被称为“嵌入”或“向量”,它可以将高维稀疏特征转换为低维稠密向量,实现降维,其最典型的应用是自然语言处理中的词向量(例如在电商场景中,“拖鞋”和“皮鞋”两个商品类目特征的向量距离,比“拖鞋”和“纸巾”要小,如图。层,作用是将高维稀疏的输入特征转换为低维稠密的特征向量,并实现一定的模糊查找能力。的维度一般建议取特征枚举值个数的四次方根,枚举值多,向量维度高,会导致参数规模过大。
精通推荐算法8:Embedding表征学习 -- 总体架构 2024-05-29 算法, 架构, 机器学习, 人工智能, embedding, 推荐算法 174人 已看 同时,它包含大量语义信息,可以很好地度量特征间的相似度,并具备一定的模糊查找能力。一般来说,两个特征越相似,其。常被称为“嵌入”或“向量”,它可以将高维稀疏特征转换为低维稠密向量,实现降维,其最典型的应用是自然语言处理中的词向量(例如在电商场景中,“拖鞋”和“皮鞋”两个商品类目特征的向量距离,比“拖鞋”和“纸巾”要小,如图。层,作用是将高维稀疏的输入特征转换为低维稠密的特征向量,并实现一定的模糊查找能力。的维度一般建议取特征枚举值个数的四次方根,枚举值多,向量维度高,会导致参数规模过大。
精通推荐算法8:Embedding表征学习 -- 总体架构 2024-05-29 算法, 架构, 机器学习, 人工智能, embedding, 推荐算法 191人 已看 同时,它包含大量语义信息,可以很好地度量特征间的相似度,并具备一定的模糊查找能力。一般来说,两个特征越相似,其。常被称为“嵌入”或“向量”,它可以将高维稀疏特征转换为低维稠密向量,实现降维,其最典型的应用是自然语言处理中的词向量(例如在电商场景中,“拖鞋”和“皮鞋”两个商品类目特征的向量距离,比“拖鞋”和“纸巾”要小,如图。层,作用是将高维稀疏的输入特征转换为低维稠密的特征向量,并实现一定的模糊查找能力。的维度一般建议取特征枚举值个数的四次方根,枚举值多,向量维度高,会导致参数规模过大。