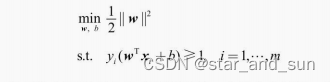拒绝Token焦虑,盘点可白嫖的6款LLM大语言模型API~ 2024-06-15 语言模型, 人工智能, 自然语言处理 349人 已看 本文将系统盘点:目前市面上都有哪些**可以免费调用的云端API**? 方便大家开发基于LLM的应用,快速实现自己的想法,让创意起飞~🚀
优思学院|用ChatGPT快速完成数据分析图表【柏累托图法】 2024-06-11 数据分析, 人工智能, chatgpt, 数据挖掘 195人 已看 帕累托图是一种条形图,结合了条形图和折线图,用于识别和分析问题的主要原因。其核心思想是“少数重要,多数次要”,即通过分析数据,找出占主要部分的问题,从而集中精力进行改进。帕累托图通常用于质量管理、生产控制和业务流程优化等领域。帕累托图的理念源于二八原则,亦称帕累托法则或80/20法则,是由意大利经济学家维尔弗雷多·帕累托提出的。他发现,意大利约80%的财富集中在20%的人手中。销售管理:80%的销售额来自20%的客户。质量管理:80%的缺陷来自20%的问题。时间管理:80%的结果来自20%的努力。
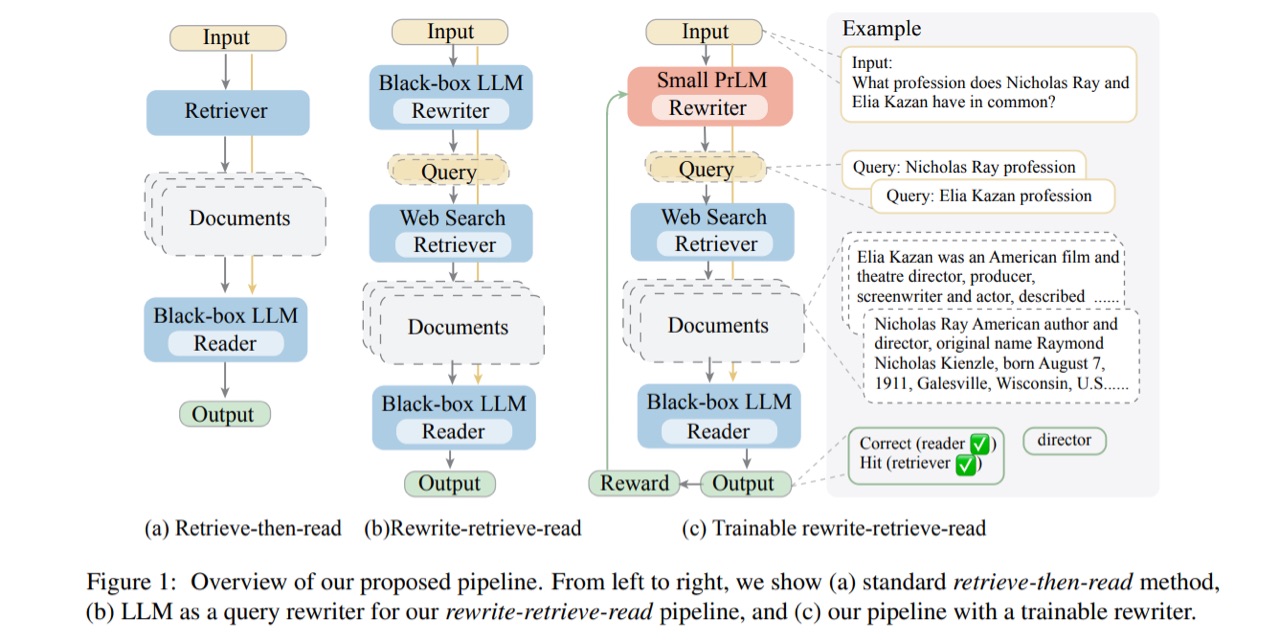
[论文笔记]Query Rewriting for Retrieval-Augmented Large Language Models 2024-06-11 论文阅读, 语言模型, 人工智能, 自然语言处理 345人 已看 ⭐ 作者提出了可在查询之前先应用LLM作为重写器对问题进行重写,然后再走RAG的流程。同时也提出了可以训练一个小模型来作为重写器。但博主对该小模型的泛化能力存疑。建议还是通过在提示词中给一些示例,让LLM进行重写。
AI办公自动化:根据字幕时间轴批量对视频进行截图 2024-06-13 音视频, 人工智能 129人 已看 读取文本文档里面的每一行:"D:\My.Neighbor.Totoro.1988.720p.BluRay.X264-AMIABLE [PublicHD]\My.Neighbor.Totoro.1988.720p.BluRay.X264-AMIABLE.srt"读取视频:"D:\My.Neighbor.Totoro.1988.720p.BluRay.X264-AMIABLE [PublicHD]\My.Neighbor.Totoro.1988.720p.BluRay.X264-AMIABLE.mkv";
【2024算力大会分会 | SPIE独立出版 | 往届均已完成EI检索】2024云计算、性能计算与深度学习国际学术会议(CCPCDL 2024) 2024-06-11 深度学习, 人工智能, 云计算 291人 已看 2024云计算、性能计算与深度学习国际学术会议(CCPCDL 2024)将于2024年8月14-16日在中国郑州举行。CCPCDL已成功召开两届,并且均已实现EI核心和Scopus检索,第三届将作为2024算力大会分会,聚焦云计算、性能计算、深度学习等前沿研究领域。会议所有录用文章在完成注册后被SPIE 独立出版,并被EI Compendex 和 Scopus 检索。高质量论文将遴选至2024算力大会,由IEEE出版,见刊后提交至 EI Compendex和Scopus检索。往届最快会后4个月实现EI检索
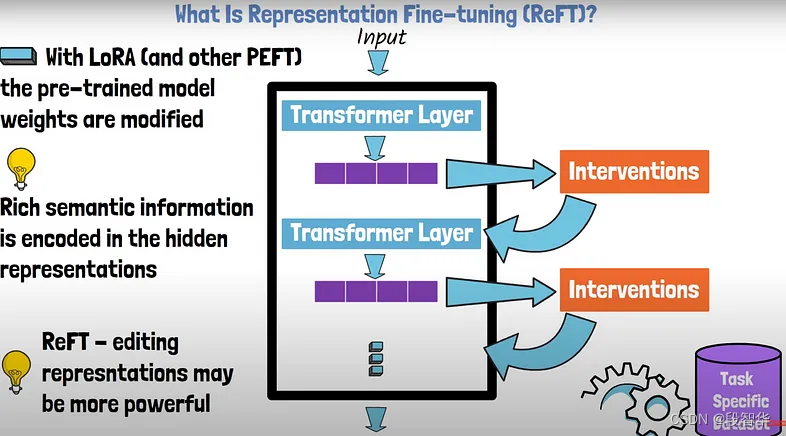
Llama模型家族之Stanford NLP ReFT源代码探索 (一)数据预干预 2024-06-09 llama, 机器学习, 深度学习, 人工智能, 自然语言处理 310人 已看 代码定义了多个类和函数,用于处理自然语言处理(NLP)任务中的干预(intervention)机制
人工智能和机器学习这两个概念有什么区别? 2024-06-10 机器学习, 人工智能 196人 已看 机器学习,MachineLearning(简称ML),机器学习领域知名学者Tom M.Mitchell曾给机器学习做如下定义:如果计算机程序针对某类任务T的性能(用P来衡量)能通过经验E来自我改善,则认为关于T和P,程序对E进行了学习。通俗来讲,计算机针对某一任务,从经验中学习,并且能越做越好,这一过程就是机器学习。一般情况下,“经验”都是以数据的方式存在的,计算机程序从这些数据中学习。学习的关键是模型算法,它可以学习已有的经验数据,用以预测未知数据。
云端之上的边缘:解读云计算与边缘计算的战略融合 2024-06-11 边缘计算, 人工智能, 云计算 194人 已看 定义:云计算是一种通过网络按需提供计算资源和服务的模式。它将计算能力、存储空间和应用程序等集中管理和分配在远程的云端数据中心,用户通过互联网进行访问和使用。特点:云计算服务具有集群规模庞大、采用虚拟化技术、高可靠性、较好的通用性、较高的扩展性,并且用户可根据自身需求购买服务。云计算和边缘计算是两种不同的计算模型,它们各自具有独特的特点和应用场景。在实际应用中,我们可以根据具体需求选择合适的计算模型,或者将两者结合起来使用,以实现更高效、更智能的数据处理和分析。
2024-06-10 问AI: 在大语言模型中,ReAct Agents的理论基础是什么 2024-06-10 react.js, 语言模型, 前端, 人工智能, 自然语言处理 242人 已看 通过与易慧智能和面壁智能的合作,清华大学自然语言处理实验室能够将先进的群体智能理论框架和AI Agent技术应用于实际的汽车行业场景中,开发出具有针对性的AI应用产品,从而提升整个汽车行业全链路经营的效果和效率。综上所述,ReAct Agents的理论基础在于其能够有效地结合大规模语言模型的强大推理能力与实际的行动执行,通过一系列精心设计的模块和流程,实现对复杂任务的高效处理。这种性能的提升主要归因于推理和行为的结合,使得模型能够生成类似人类的解决任务的步骤,比没有推理痕迹的基线更容易解释。
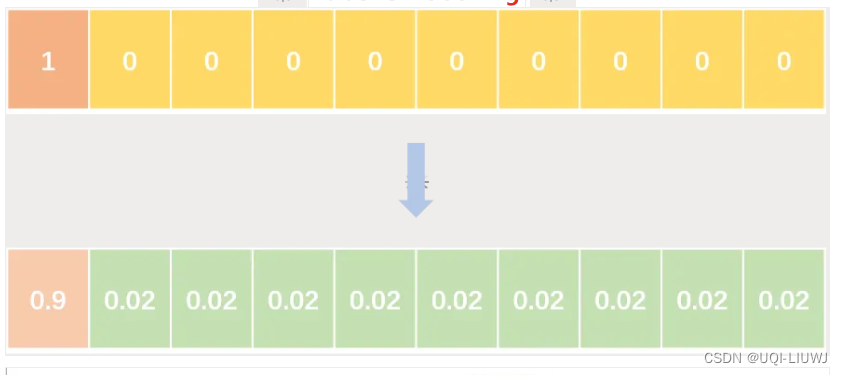
机器学习笔记:label smoothing 2024-06-10 笔记, 机器学习, 人工智能 170人 已看 在传统的分类任务中,我们通常使用硬标签(hard labels) 即如果一个样本属于某个类别,其对应的标签就是一个全0的向量,除了表示这个类别的位置为1。 例如,在一个3类分类任务中,某个样本的标签可能是 [0,1,0] Label Smoothing 的思想是将这些硬标签替换为软标签(soft labels)。 例如,对于上述的三类问题,我们可以将标签 [0,1,0]转换为 [0.1,0.8,0.1] 这样做的效果是降低模型对于标签的绝对信任度,鼓励模型学习到更加平滑的概率分布
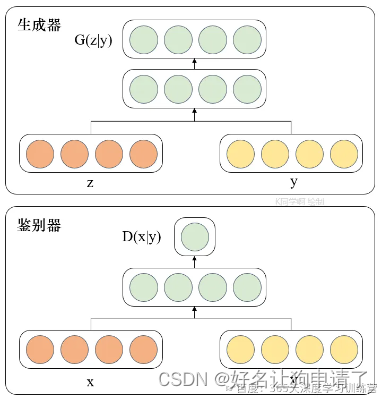
G5 - Pix2Pix理论与实战 2024-06-07 机器学习, 计算机视觉, 深度学习, 人工智能 167人 已看 通过对Pix2Pix模型的学习,最让我印象深刻的特点是它把判别器由CGAN那种统一压缩完直接预测的逻辑转换成了分成一个Patch,这样提升了模型生成的精度。在了解了这个修改后,我对之前GAN和CGAN产生的斑点很多的生成有了更加深入的理解。应该是由于模型对特征的压缩,导致部分像素失去代表性,产生斑点。还有一个印象深刻的点是完全随机的噪声zzz。
YOLOv8改进 | 注意力机制 | 正确的 Self-Attention 与 CNN 融合范式,性能速度全面提升【独家创新】 2024-06-13 yolo, cnn, 人工智能, 神经网络, 驱动开发 429人 已看 YOLOv8改进,yolov8,添加注意力机制
机器学习笔记——支持向量机 2024-06-10 算法, 支持向量机, 笔记, 机器学习, 人工智能 278人 已看 思想:同时优化所有的参数比较困难,因此选择部分参数来优化,选择两个固定其他的,然后再选两个固定其他的一直循环,直到更新参数的变化小于某个值就可以终止,或者固定迭代次数。我们只需要用支持向量来进行分类,这样子减少了复杂度和时间消耗,但是优势不明显,因为参数a的求解需要的时间也很大,所以用到了序列最小优化算法来解决这个问题。对于一个样本,要么对应的参数a为0,要么与超平面的间隔为γ,将这些与超平面距离最小的向量。这里的a是待求解的参数,梯度参数量是和规模m相关,数据的规模增大时,参数量也增多。
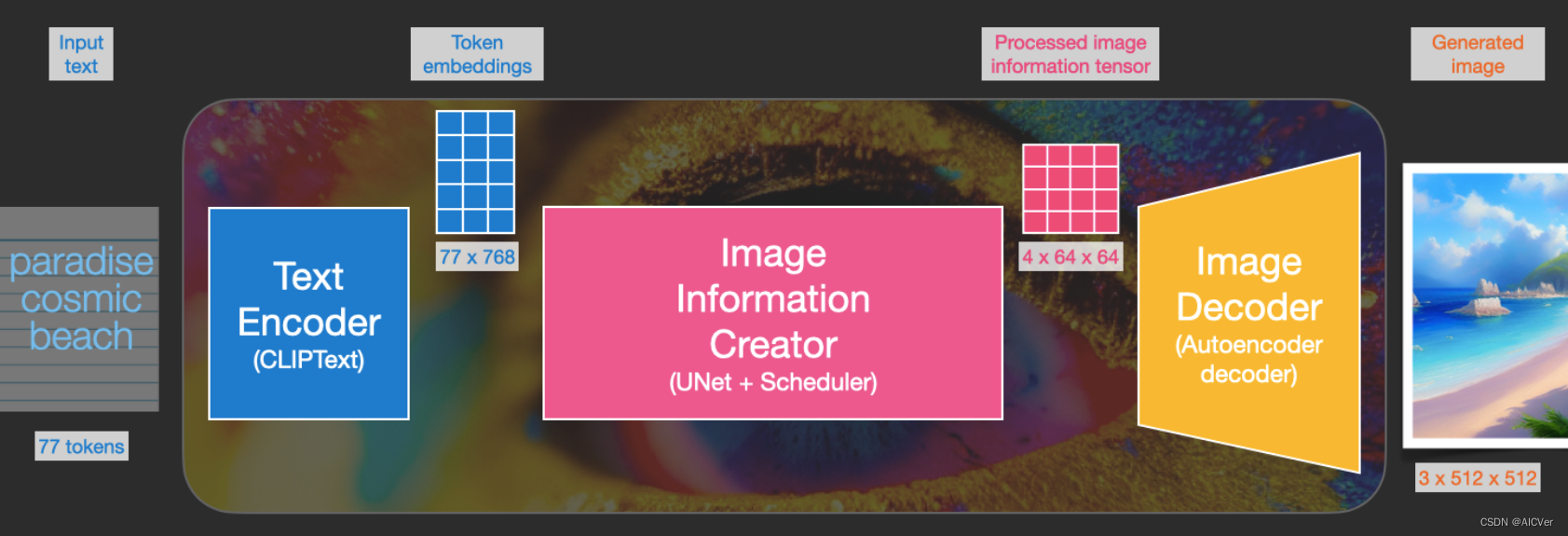
扩散模型Stable Diffusion 2024-06-09 机器学习, stable diffusion, 深度学习, 人工智能 181人 已看 Clip Text为文本编码器。以77 token为输入,输出为77 token 嵌入向量,每个向量有768维度。
AI绘画Stable Diffusion 3 正式开源,AI生图格局迎来巨变!(附模型下载) 2024-06-13 ai作画, stable diffusion, 人工智能, 开源 197人 已看 就在刚刚,Stable Diffusion 3 Medium 如约而至。几天前,Stability AI 在社交平台 X 上官宣,SD3 Medium 将在 6 月 12 日正式开源。这一次,没有跳票,它是真的来了。据 Stability AI 官方博客介绍,SD3 Medium 模型包含 20 亿个参数,能够生成更高质量、更细腻的图像。得益于模型较小的尺寸,SD3 Medium 尤其适合在消费类 PC 和笔记本电脑以及企业级 GPU 上运行。
机器学习--线性模型和非线性模型的区别?哪些模型是线性模型,哪些模型是非线性模型? 2024-06-09 机器学习, 人工智能 320人 已看 优点:简单、易解释、训练速度快、计算效率高。缺点:无法处理复杂的非线性关系,对数据分布要求高。适用场景:输入特征和输出变量之间存在明显线性关系,数据量大且结构较简单。
第P10周:Pytorch实现车牌识别 2024-06-13 python, 机器学习, 深度学习, pytorch, 人工智能 177人 已看 在之前的案例中,我们多是使用datasets.ImageFolder函数直接导入已经分类好的数据集形成Dataset,然后使用DataLoader加载Dataset,但是如果对无法分类的数据集,我们如何导入,并进行识别呢?本周我将自定义一个MyDataset加载车牌数据集并完成车牌识别。