AI 前沿发展摘要 2024-05-28 人工智能 8人 已看 特点: 使用了更高质量的视觉数据和字幕训练, 现在Open-Sora 1.1能够 能够生成最长约21秒的视频。一款先进的开源语言模型,拥有30亿参数,能够高效地将用户查询转换成专业模型可以有效处理的格式。🔔 AI 前沿发展摘要。
深度学习 PyTorch 笔记 (2) :深度神经网络 DNN 2024-05-27 笔记, dnn, 深度学习, pytorch, 人工智能 156人 已看 《动手学深度学习》笔记——深度神经网络 DNN(线性回归 → softmax回归 →多层感知机→深度学习计算)教材:https://zh-v2.d2l.ai
【pytorch】关于OpenCV和PIL.Image读取图片的区别 2024-05-22 python, 深度学习, pytorch, 人工智能, opencv 169人 已看 具体来说这两种方式读取图片没有大的区别,但是建议用的方式来读。
【python】OpenCV—Tracking(10.2) 2024-05-28 python, 计算机视觉, 人工智能, opencv, 开发语言 103人 已看 借助 BackgroundSubtractor 类,可检测阴影,用阈值排除阴影,从而关注实际特征。做 gif 的时候只设置了播放一次,重复播放需要刷新。Opencv 有三种背景分割器。
【pytorch】关于OpenCV和PIL.Image读取图片的区别 2024-05-22 python, 深度学习, pytorch, 人工智能, opencv 106人 已看 具体来说这两种方式读取图片没有大的区别,但是建议用的方式来读。
猫狗分类识别⑤二值化 2024-05-22 python, 计算机视觉, 人工智能, opencv, 开发语言 100人 已看 它接受四个参数:输入图像、阈值、最大值(通常设置为255,表示白色)和二值化类型(在这个例子中使用cv2.THRESH_BINARY)。函数返回两个值:第一个是用于二值化的实际阈值(在这个例子中我们不需要,所以使用_来忽略它),第二个是二值化后的图像。在这个脚本中,我们假设去噪后的图像已经是灰度图像。可以使用cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)来实现。最后,使用cv2.imwrite函数将二值化后的图像保存到指定的文件夹中。
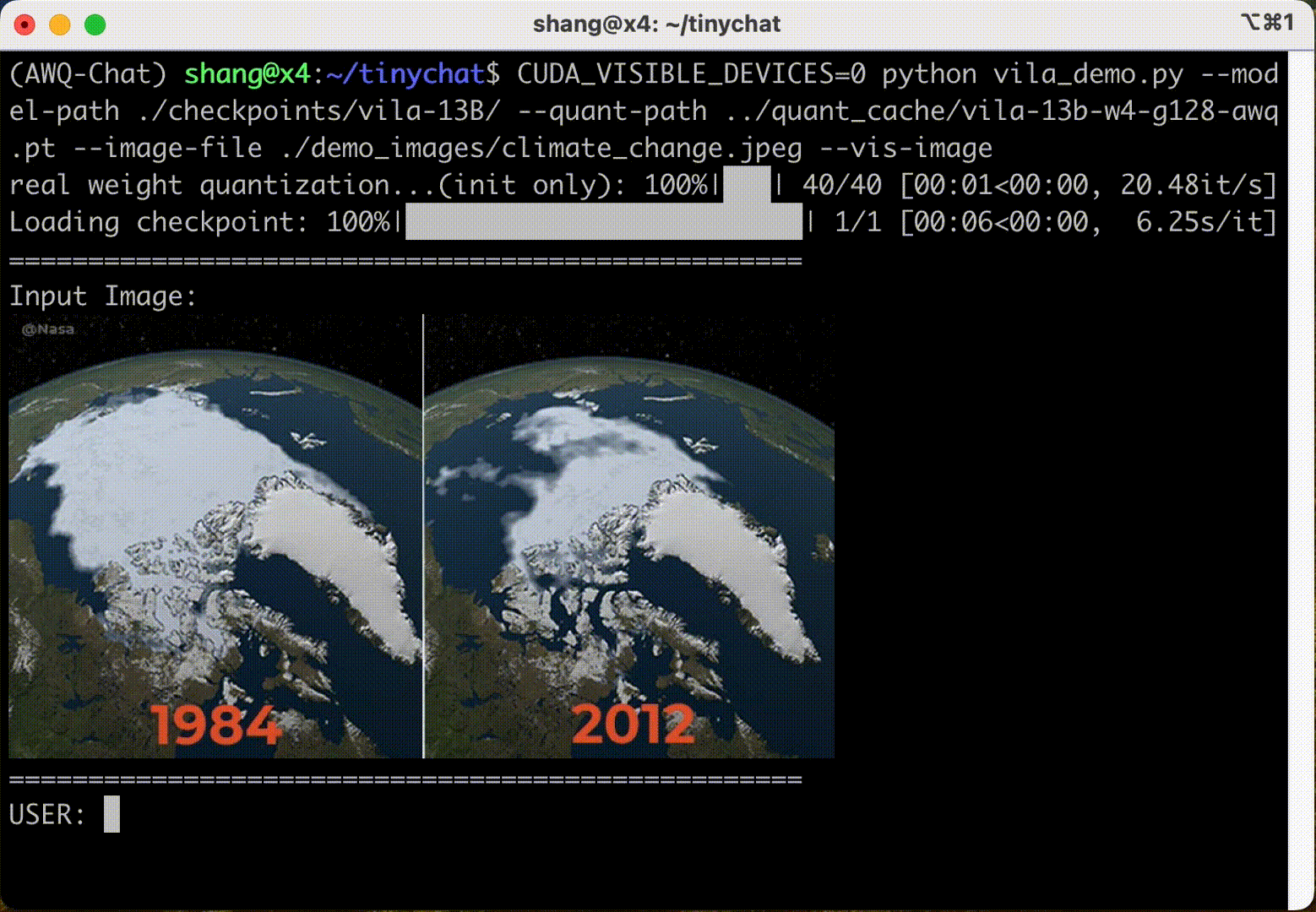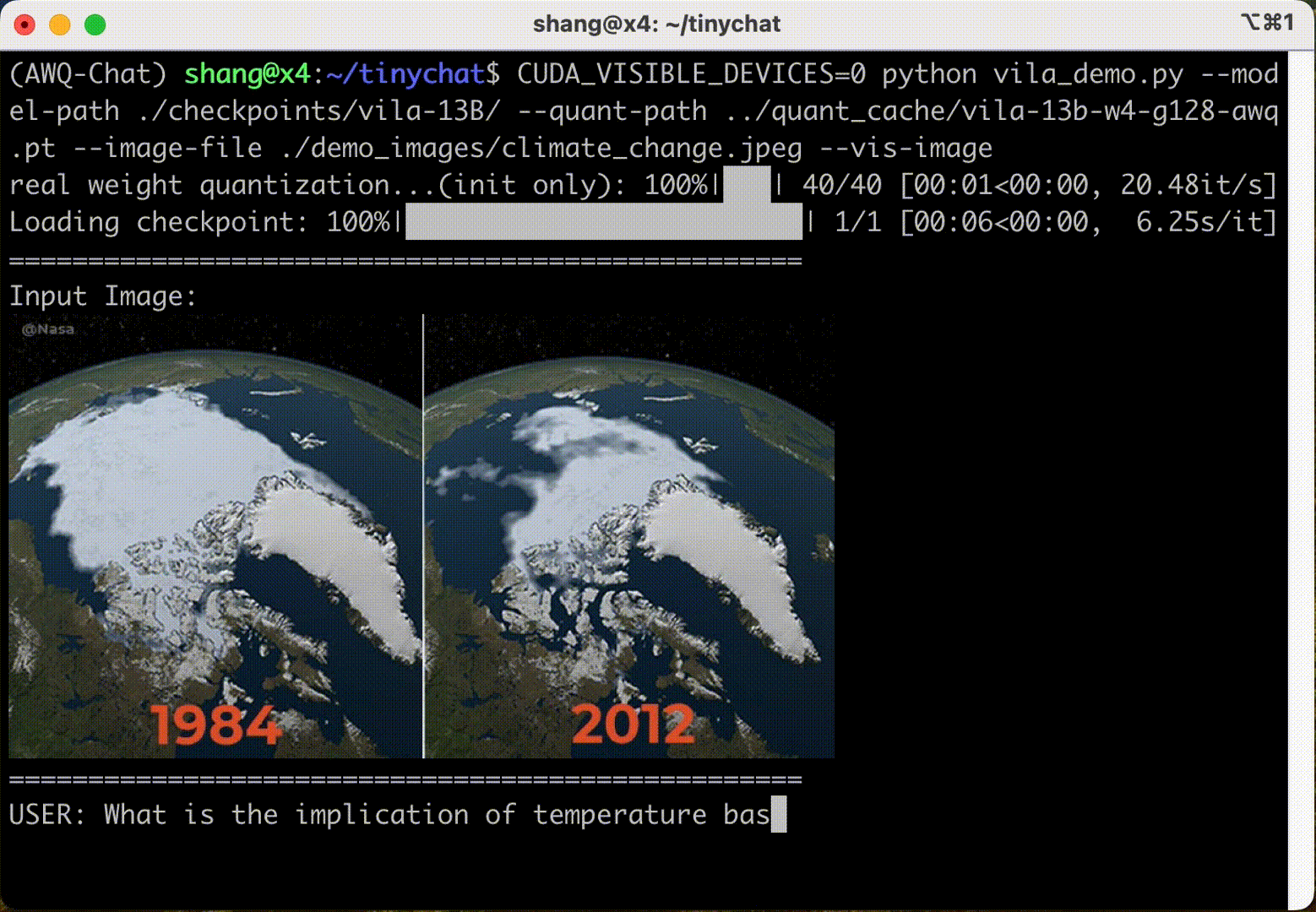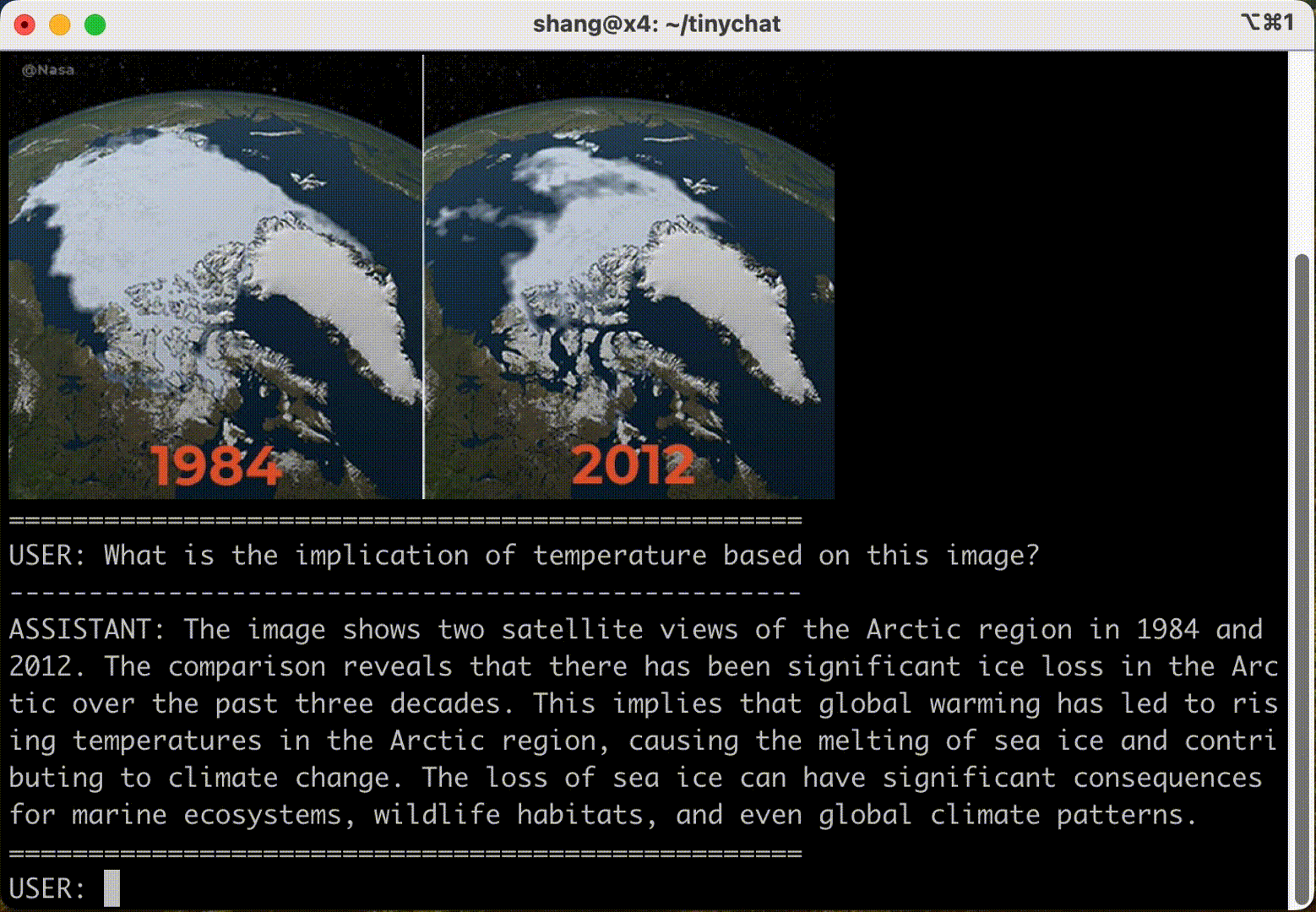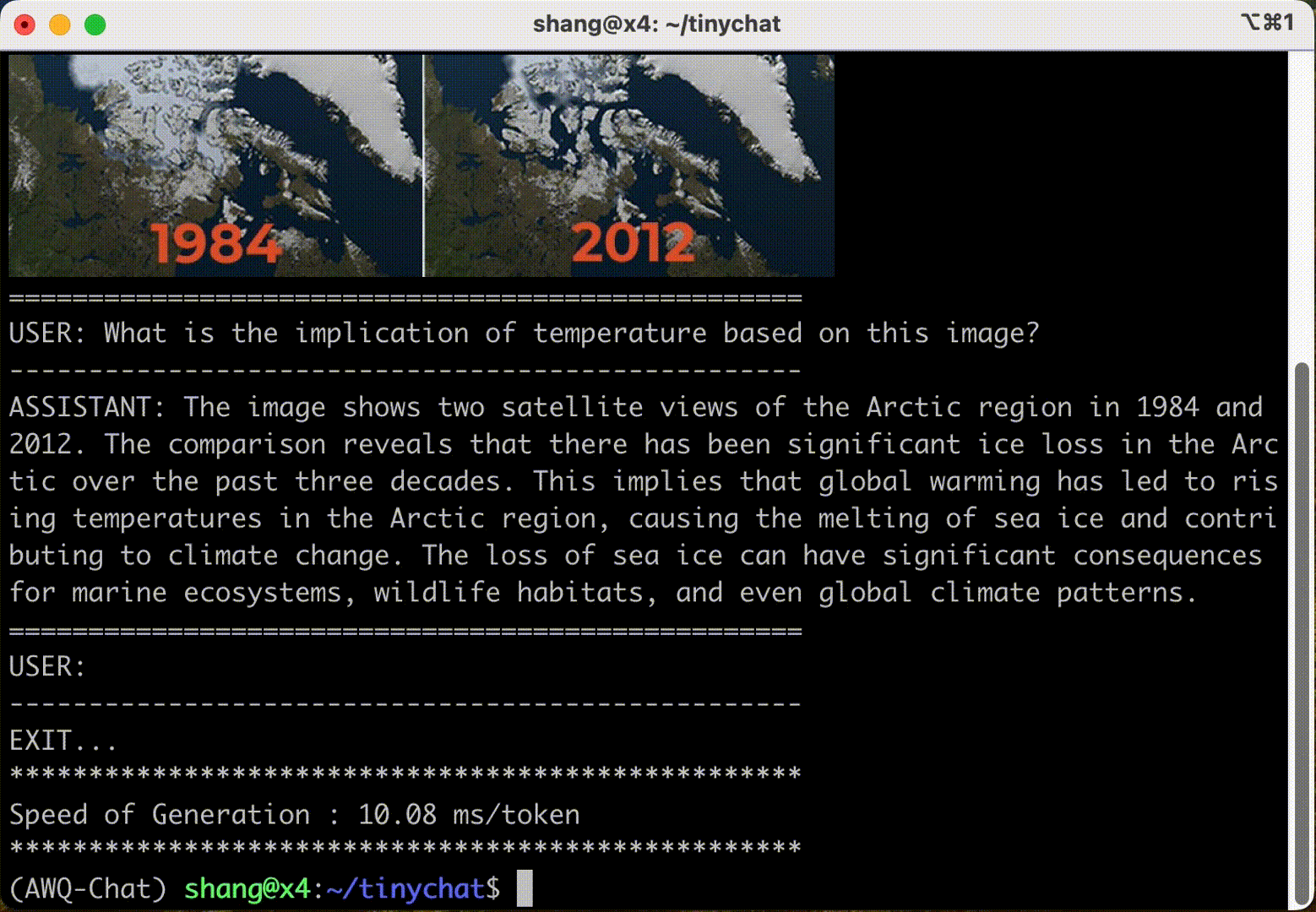
TinyChat: Visual Language Models & Edge AI 2.0 2024-05-22 edge, 语言模型, 人工智能, 自然语言处理 200人 已看 了解TinyChat和AWQ最新的技术发展。在边缘部署语言理解模型(LSTM)后,借助于视觉语言模型(VLM),可以为LLM提供更好地处理图像输入的能力,从而极大方便了文字对话问答、图片标题生成等图形内容解读任务。TinyChat最新版支持先进VLM技术 VILA,可通过AWQ轻松实现量化操作,从而为用户提供了完美的使用体验来应对图片内容处理等任务。
2024.05.27【读书笔记】丨生物信息学与功能基因组学(第九章 蛋白质结构与结构基因组学 上)【AI测试版】 2024-05-29 算法, python, 人工智能, 大数据, 开发语言 21人 已看 第九章专注于蛋白质结构及其与结构基因组学的关系。本章深入讨论了蛋白质的三维构象如何决定其功能,以及如何通过实验和计算方法来预测和确定蛋白质结构。
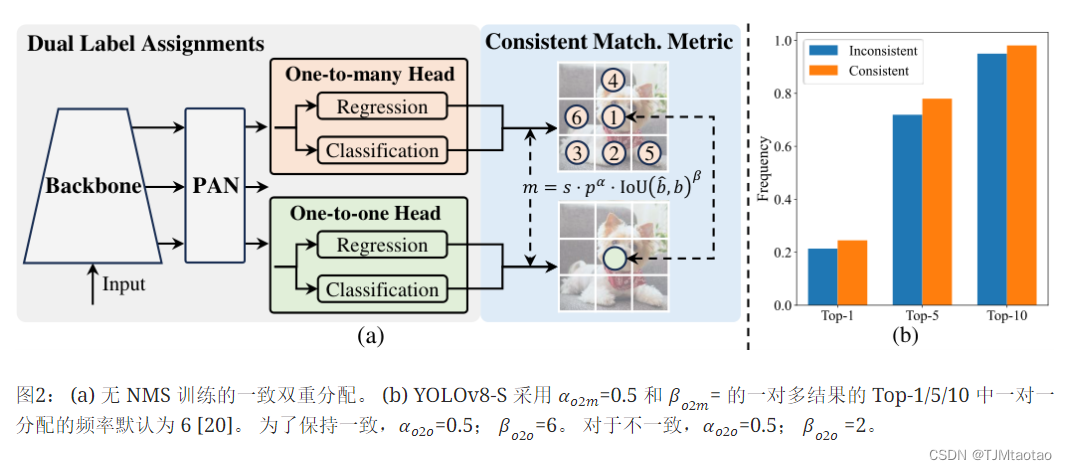
【论文阅读】 YOLOv10: Real-Time End-to-End Object Detection 2024-05-24 论文阅读, yolo, 计算机视觉, 目标检测, 人工智能 91人 已看 在过去几年中,YOLOs 因其在计算成本和检测性能之间的有效平衡而成为实时物体检测领域的主流模式。研究人员对 YOLOs 的架构设计、优化目标、数据增强策略等进行了探索,并取得了显著进展。然而,后处理对非最大抑制(NMS)的依赖阻碍了 YOLO 的端到端部署,并对推理延迟产生了不利影响。此外,YOLOs 中各种组件的设计缺乏全面彻底的检查,导致明显的计算冗余,限制了模型的能力。这使得效率不尽如人意,性能还有很大的提升空间。在这项工作中,我们旨在从后处理和模型架构两方面进一步推进 YOLO 的性能-效率边界。
微软Copilot+ PC:Phi-Silica 2024-05-22 copilot, 机器学习, 深度学习, 人工智能, microsoft 319人 已看 昨日微软宣布推出一种新的、更微型的小语言模型 (SLM)Phi-3-Silica,专为Copilot+ PC设计。Copilot+ PC本身配备强大神经处理单元 (NPU) 的个人计算机,能够应付AI计算。基于Windows的Phi-3-Silica仅仅拥有3B参数,是Phi-3系列中最小的。
【机器学习300问】103、简单的经典卷积神经网络结构设计成什么样?以LeNet-5为例说明。 2024-05-28 机器学习, 人工智能 31人 已看 简单的经典卷积神经网络结构设计成什么样?以LeNet-5为例说明。
pytorch-16 复现经典网络:LeNet5与AlexNet 2024-05-28 python, 网络, 深度学习, pytorch, 人工智能 80人 已看 对于(10,3,227,227)数据表示,10张3通道的图,图的大小(特征数)为227*227.通道数:作为卷积的输入通道数和输出通道数。特征数:特征图的大小步长stride和填充padding:线性减小特征图的尺寸池化pooling:非线性且高效减小特征图的尺寸。
Milvus的内存索引 2024-05-22 算法, 机器学习, 人工智能, milvus 277人 已看 根据适用的数据类型,milvus支持的索引可以分为两类:embedding为浮点数的索引:距离度量方法:欧几里得距离(L2)和内积,索引包括:FLAT,IVF,IVF_FLAT,IVF_PQ,IVF_SQ8,和SCANN;embedding为二进制的索引:距离度量方法:Jaccard 和 Hamming,索引包括:BIN_FLAT 和 BIN_IVF_FLAT;embedding为稀疏的索引:距离度量方法只有IP,索引包括:SPARSE_INVERTED_INDEX和SPARSE_WAND
数据挖掘与机器学习——回归分析 2024-05-28 机器学习, 人工智能, 数据挖掘 107人 已看 回归分析定义:案例:线性回归预备知识:定义:一元线性回归:如何找出最佳的一元线性回归模型:案例:python实现:多元线性回归案例:线性回归的优缺点:逻辑回归(解决分类问题)案例:定义:python实现:案例:逻辑回归优点:逻辑回归缺点:(解决分类问题)
【python脚本】修改目标检测的xml标签(VOC)类别名 2024-05-28 计算机视觉, xml, 目标检测, 人工智能 94人 已看 在集成多个数据集一同训练时,可能会存在不同数据集针对同一种目标有不同的类名,可以通过python脚本修改数据内的类名映射,实现统一数据集标签名的目的。label_dict:标签类名的映射字典,key值为修改前的类名,value值为修改后的类名。new_label_dir:输出的新xml标签的目录。label_dict[‘head’] = ‘头’org_label_dir:xml标签的目录。如图,修改标签类别名成功!
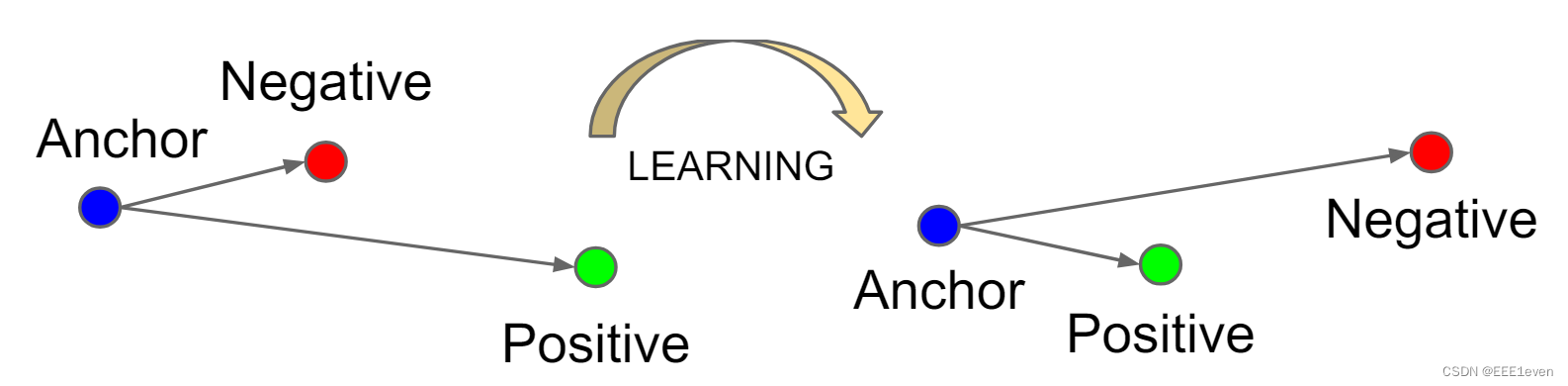
对比表征学习(一)Contrastive Representation Learning 2024-05-27 算法, 机器学习, 深度学习, 人工智能 96人 已看 主要参考翁莉莲的,本文主要聚焦于对比损失函数对比表示学习(Contrastive Representation Learning)可以用来优化嵌入空间,使相似的数据靠近,不相似的数据拉远。同时在面对无监督数据集时,对比学习是一种极其有效的自监督学习方式。
YOLOv10:实时端到端目标检测 2024-05-28 yolo, 计算机视觉, 目标检测, 人工智能, 目标跟踪 199人 已看 在过去的几年里,YOLO因其在计算成本和检测性能之间的有效平衡而成为实时目标检测领域的主要范例。研究人员对 YOLO 的架构设计、优化目标、数据增强策略等进行了探索,取得了显着进展。然而,后处理对非极大值抑制(NMS)的依赖阻碍了 YOLO 的端到端部署,并对推理延迟产生不利影响。此外,YOLO中各个组件的设计缺乏全面彻底的检查,导致明显的计算冗余并限制了模型的能力。它提供了次优的效率,以及相当大的性能改进潜力。在这项工作中,我们的目标是从后处理和模型架构方面进一步提升 YOLO 的性能效率边界。