yolov8 模型架构轻量化 | 极致提速度 2024-05-16 yolo, 架构, 人工智能 103人 已看 当想要提升模型在通用计算平台上的FPS(每秒帧数或帧率)时,可以从模型架构的三个关键角度出发进行优化:模型的参数数量、浮点数运算的复杂度以及模型架构的简洁性。1. 模型的参数是否足够少参数数量是影响模型推理速度的重要因素之一。参数越少的模型,其计算量和内存占用通常也越小,因此推理速度更快。优化策略模型剪枝:通过移除模型中不重要的参数(如权重较小的连接)来减少参数数量。知识蒸馏:使用一个更大的教师模型来指导一个小模型的训练,使得小模型能够学习到教师模型的性能,同时保持较小的参数规模。选择轻量级模型。
数据挖掘与机器学习——机器学习概述 2024-05-16 机器学习, 人工智能, 数据挖掘 87人 已看 机器学习的英文名称叫Machine Learning,简称ML,该领域主要研究的是如何使计算机能够模拟人类的学习行为从而获得新的知识。机器学习与数据挖掘的联系:简单来说,机器学习就是让计算机从大量的数据中学习到相关的规律和逻辑,然后利用学习来的规律来预测以后的未知事物。机器学习中非常重要的概念:训练,预测,模型二、机器学习的分类按任务类型进行分类按监督模式进行分类最新方向:增强学习和深度学习。
前馈全连接神经网络对鸢尾花数据集进行分类 2024-05-16 算法, 机器学习, 人工智能, 数据挖掘, 分类 99人 已看 函数,将这个对象转换为一个pandas DataFrame,这样就可以更方便地查看和分析训练过程中的指标变化。绘制画图,model.evaluate()函数是用来评估一个训练好的模型在测试数据集上的性能。构建一个10层网络,隐藏层每层对应16个神经元,激活函数都是relu函数,输入输出神经元判断。
腾讯云与百川智能达成战略合作,加速AI大模型迭代升级 2024-05-17 腾讯云, 人工智能, 云计算 166人 已看 腾讯将始终保持开放的心态,与不同行业、不同领域的模型厂商合作,联合打造最接近产业的实用级AI,共同推动大模型实现能力更强、覆盖更广、应用更深,助力大模型产业繁荣发展。未来,随着双方合作的不断深化,腾讯云将不断加强在技术、产品、生态等方面能力,持续打造更好的大模型AI基础设施,助力百川智能快速发展,为大模型产业注入源源不断的强劲动能。值得一提的是,双方还将围绕生态领域进行长期合作,实现技术与生态的深度融合,为客户提供更为精准和个性化的服务,全面提高百川智能的服务水平,带来创新营收增长。
sklearn监督学习--k近邻算法 2024-05-22 python, 机器学习, 近邻算法, 人工智能, sklearn 195人 已看 这一算法对于有很多特征(几百或更多)的数据集往往效果不好,对于大多数特征的大多数取值都为0的数据集来说,这一算法的效果尤其不好。与之相反,如果你的模型过于简单,那么你可能无法抓住数据的全部内容以及数据中的变化,你的模型甚至在训练集上的表现就很差。但是,如果我们的模型过于复杂,我们开始过多关注训练集中每个单独的数据点,模型就不能很好地泛化到新数据上。k-NN算法最简单的版本只考虑一个最近邻,也就是与我们想要预测的数据点最近的训练数据点。可以发现,左上角新数据点的预测结果与只用一个邻居时的预测结果不同。
GPT-4o:人工智能的新里程碑与未来潜力 2024-05-18 百度, 人工智能, gpt 95人 已看 随着GPT-4o的不断迭代和优化,我们期待它在未来能够带来更多令人惊叹的创新和进步。它不仅提升了文字理解和生成能力,特别是在专业和学术领域的表现,使得它能够撰写出更为精准、流畅的文章,甚至在模拟律师或医生的角色时,能提供专业意见。然而,对于40岁以上的人来说,无论是健身还是日常生活中,也需要重新评估他们的习惯,以适应AI带来的改变,比如避免过度依赖技术来替代人类互动。同时,GPT-4o的问世也带来了一些新的挑战,如写作检测工具如Turnitin,开始调整其算法以检测AI生成内容的痕迹,防止学术欺诈行为。
深度神经网络——什么是自动编码器? 2024-05-23 机器学习, dnn, 深度学习, 人工智能, 神经网络 141人 已看 自动编码器是一种无监督机器学习算法,它通过反向传播进行训练,目标值被设置为与输入值相等。其核心目标是对输入数据进行压缩,转换成一个更小的表示形式,如果需要原始数据,可以从压缩后的数据中重建。
数据挖掘与机器学习——常用的python操作 2024-05-16 python, 机器学习, 人工智能, 数据挖掘, 开发语言 79人 已看 counter = 100 # 整型变量miles = 1000.0 # 浮点型变量name = "John" # 字符串变量ndarray: 多维数组对象,用于存储单一数据类型的数组。ufunc: 用于对数组进行元素级运算的函数。Series: 一维数组型对象,适用于标签化的数据。DataFrame: 二维表格型数据结构,有行索引和列索引。
【目标检测】关于YOLO系列算法中Confidence置信度的计算和理解 2024-05-19 算法, 计算机视觉, 目标检测, 人工智能 878人 已看 关于YOLO系列算法中Confidence置信度的计算和理解
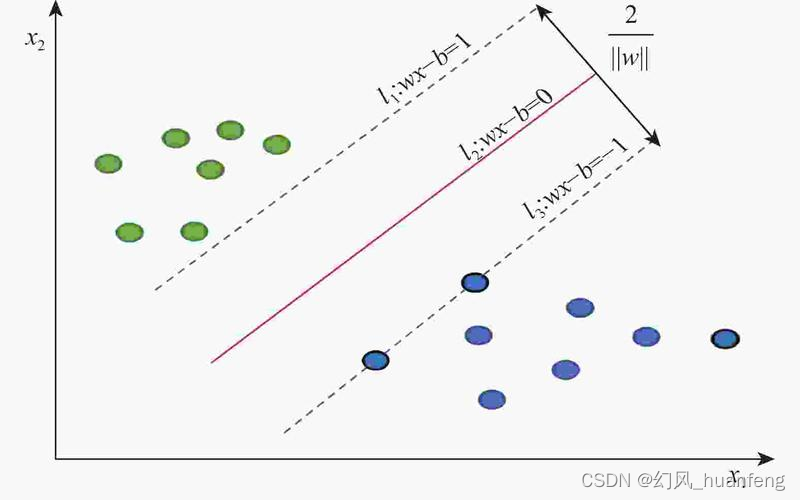
探索支持向量机中样本点的三重角色 2024-05-16 支持向量机, 算法, 机器学习, 人工智能, 数据挖掘 99人 已看 其次,边界向量还能够提高模型的鲁棒性。在实际应用中,我们经常会遇到一些特殊的样本点,它们可能具有特殊的性质或特征,但却不位于分类边界上。虽然非支持向量在SVM的决策过程中不直接发挥作用,但它们在模型的训练和评估过程中却具有不可忽视的作用。在这个过程中,样本点的作用举足轻重,它们扮演着三种不同的角色,共同构筑了SVM的坚实基石。在SVM中,除了支持向量和边界向量外,其余的样本点被称为非支持向量。这意味着当新的样本点出现时,SVM能够利用这些已知的支持向量来做出准确的分类决策,从而实现对新数据的良好适应。
计算机视觉与深度学习实战:以Python为工具,基于不变矩的数字验证码识别 2024-05-16 python, 计算机视觉, 人工智能, 开发语言 97人 已看 随着数字化时代的到来,验证码作为一种有效的安全验证机制,广泛应用于各类网站和应用程序中。然而,对于用户而言,手动输入验证码不仅增加了操作复杂性,还可能因输入错误而导致验证失败。因此,研究基于计算机视觉和深度学习的自动验证码识别技术具有重要的实际意义和应用价值。本文将以Python为工具,探讨基于不变矩的数字验证码识别方法,旨在提高验证码识别的准确性和效率。
AI Earth——高分一号(中国四维日新图产品 ) 2024-05-18 人工智能, 数码相机 78人 已看 是以景为单位进行更新的遥感影像服务产品,该产品可提供长时间序列的高精度、高质量的历史影像服务。主要应用于国家土地执法督察、土地利用变更调查、土地利用动态遥感监测、环保固体废弃物监测、地质灾害监测、应急救灾、重大工程监测等业务。产品具有持续快速更新、历史影像齐全、在线服务、视觉效果好等特点。
[数据集][目标检测]鱼头鱼尾检测数据集VOC+YOLO格式200张2类别 2024-05-18 yolo, 机器学习, 深度学习, 目标检测, 人工智能 95人 已看 数据集格式:Pascal VOC格式+YOLO格式(不包含分割路径的txt文件,仅仅包含jpg图片以及对应的VOC格式xml文件和yolo格式txt文件)特别声明:本数据集不对训练的模型或者权重文件精度作任何保证,数据集只提供准确且合理标注。标注类别名称:["head","tail"]图片数量(jpg文件个数):200。标注数量(xml文件个数):200。标注数量(txt文件个数):200。使用标注工具:labelImg。标注规则:对类别进行画矩形框。head 框数 = 724。
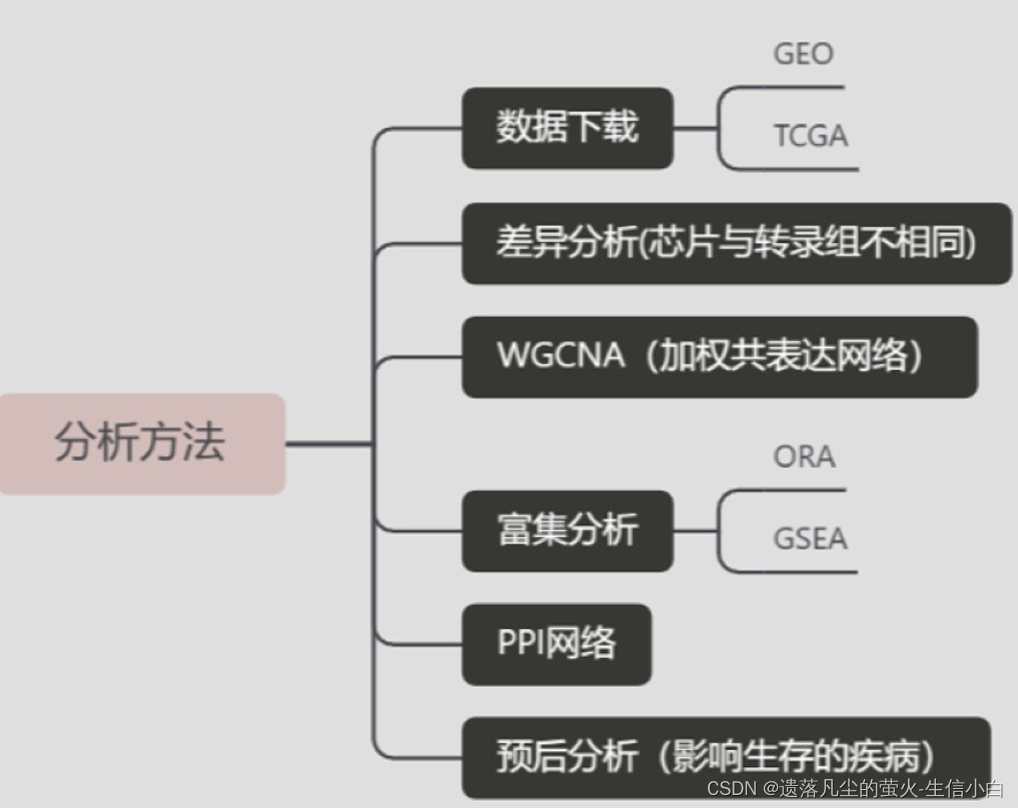
GEO数据挖掘-GEO背景知识+表达芯片分析思路 2024-05-16 人工智能, 数据挖掘 96人 已看 1.图表分析2.GEO背景介绍及分析思路3.代码分析流程4.复杂数据分析提示:这是GEO数据挖掘的大概内容:广义的基因有 6w+个,如何缩小范围到课题相关?1.数据从哪里来2.有什么类型的数据可挖掘基因表达芯片转录组单细胞突变(
深度学习计算机视觉中,什么是无监督域自适应算法? 2024-05-19 计算机视觉, 深度学习, 人工智能 604人 已看 无监督域自适应(Unsupervised Domain Adaptation, UDA)算法是深度学习和计算机视觉中用于解决域间分布差异问题的一类方法。在实际应用中,训练数据(源域)和测试数据(目标域)可能来自不同的分布,这种差异会导致模型在目标域上表现不佳。无监督域自适应算法旨在减少这种分布差异,使得模型在目标域上能够更好地泛化。
[数据集][目标检测]手枪机枪刀检测数据集VOC+YOLO格式5990张3类别 2024-05-19 yolo, 计算机视觉, 目标检测, 深度学习, 人工智能 120人 已看 数据集格式:Pascal VOC格式+YOLO格式(不包含分割路径的txt文件,仅仅包含jpg图片以及对应的VOC格式xml文件和yolo格式txt文件)特别声明:本数据集不对训练的模型或者权重文件精度作任何保证,数据集只提供准确且合理标注。标注类别名称:[“Rifle”,“knife”,“pistol”]图片数量(jpg文件个数):5990。标注数量(xml文件个数):5990。标注数量(txt文件个数):5990。使用标注工具:labelImg。标注规则:对类别进行画矩形框。
快速入门PyTorch自然语言处理,实现文本分类 2024-05-22 python, 深度学习, pytorch, 人工智能, 自然语言处理 124人 已看 PyTorch为处理自然语言处理任务提供了一个直观且强大的平台,从创建简单的神经网络到处理词嵌入和文本分类,该框架简化了开发过程。随着深入使用PyTorch探索NLP,不妨尝试挑战一些更高级的领域,例如序列到序列模型、注意力机制和迁移学习。PyTorch社区提供了丰富的资源、教程和预训练模型,为大家学习和实践提供了强有力的支持。
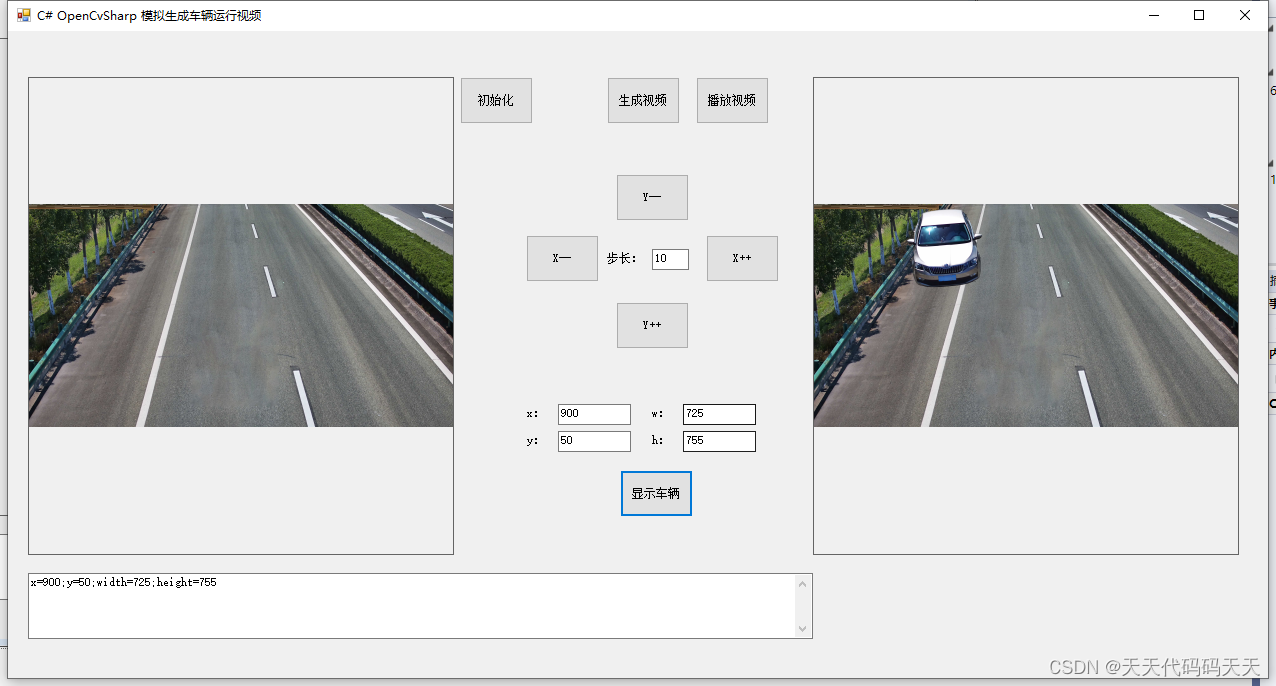
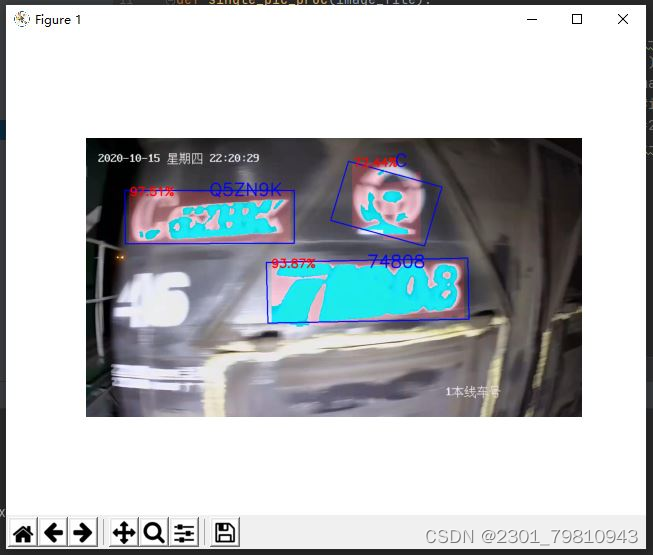
深度学习之基于Pytorch火车车厢号 2024-05-22 python, 机器学习, 深度学习, pytorch, 人工智能 419人 已看 一、项目背景在铁路物流、车辆管理以及旅客服务等领域,准确快速地识别火车车厢号具有重要意义。传统的车厢号识别方法通常依赖于人工读取,这种方法不仅效率低下,而且容易出错。随着深度学习技术的快速发展,尤其是卷积神经网络(CNN)在图像识别领域的广泛应用,我们提出了一个基于PyTorch的火车车厢号识别项目。二、项目目标本项目的目标是开发一个能够自动从火车图像中识别出车厢号的系统。该系统应能够处理不同光线、角度和车厢类型下的图像,并准确地识别出车厢号。
WWW 2024最佳论文|大型语言模型的机制设计 2024-05-22 语言模型, 人工智能, 自然语言处理 118人 已看 本论文针对多个大语言模型(LLM)的激励相容聚合问题,提出了一种基于token的拍卖机制(token auction)。通过线性组合和log-linear组合两种aggregation函数,实现了根据不同广告客户的出价比例生成相应的联合广告文案。实验结果表明,所提机制能够以一种平滑、可解释的方式实现多个LLM的聚合,为自动生成广告创意提供了新的思路。疑惑和想法除了token-level的建模,是否可以设计出其他粒度(如phrase-level、sentence-level)的机制?