spark3.0.1版本查询Hbase数据库例子 2024-05-31 spark, 数据库, 分布式, 大数据, hbase 114人 已看 需要采用spark查询hbase数据库的数据同步到中间分析库,记录spark集成hbase的简单例子代码
数据仓库与数据挖掘总复习练习2-3(实验六 2024.6.5) 2024-06-05 spark, 数据仓库, 人工智能, 分布式, 大数据, 数据挖掘 107人 已看 cities中index:数值,data:地名。(index中值最好不要重复,避免计算错误)一列作为index,一列作为数据。
数据仓库与数据挖掘总复习练习2-3(实验六 2024.6.5) 2024-06-05 spark, 数据仓库, 人工智能, 分布式, 大数据, 数据挖掘 101人 已看 cities中index:数值,data:地名。(index中值最好不要重复,避免计算错误)一列作为index,一列作为数据。
Spark基础:Scala内建控制结构 2024-05-29 scala, spark, 分布式, 大数据, 开发语言 132人 已看 在Scala中,控制结构是编程的基础,它们允许你根据条件执行不同的代码块,或者重复执行某些代码块。Scala的for循环非常强大,可以遍历集合、数组、列表等,并支持多种模式,包括传统的C-style for循环和更强大的for推导式(for comprehension)。Scala的模式匹配功能强大且灵活,它允许你根据输入的值匹配不同的模式,并执行相应的代码块。这在处理复杂的数据结构时特别有用。等操作中,你可能需要根据数据的某些属性来执行不同的操作,这时就需要使用到条件语句和循环结构。
Spark的性能调优——RDD 2024-06-03 c#, spark, 分布式, ajax, 大数据 116人 已看 参数是函数、或者返回值是函数的函数,我们把这类函数统称为“高阶函数”(Higher-order Functions)。换句话说,这 4 个算子,都是高阶函数。// 读取文件内容// 以行为单位做分词// 把RDD元素转换为(Key,Value)的形式// 按照单词做分组计数// 打印词频最高的5个词汇在 RDD 的编程模型中,一共有两种算子,Transformations 类算子和 Actions 类算子。
Spark Streaming概述 2024-05-29 spark, 分布式, 大数据 74人 已看 Spark Streaming的工作原理是将输入数据以某一时间间隔(如几秒)批量地处理。Spark Streaming通过定期地(如每几秒)从数据源拉取数据,并创建新的RDD来表示这些数据。总之,Spark Streaming是一个强大的实时计算框架,具有实时数据处理、微批次处理、容错性、灵活性等特点。它可以与Spark的其他组件集成,实现数据的批处理和实时处理的无缝衔接。Spark Streaming是构建在Spark上的实时计算框架,它扩展了Spark处理大规模流式数据的能力。
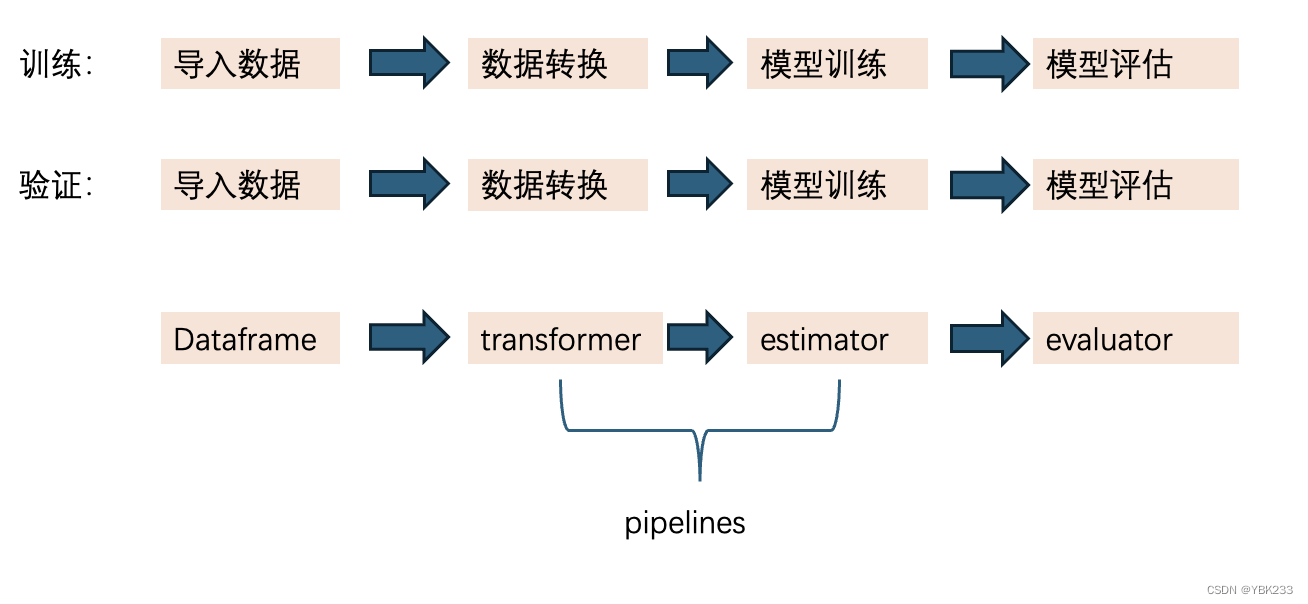
SparkML 2024-06-03 spark, 分布式, 大数据 74人 已看 Apache Spark ML 是机器学习库在 Apache Spark 上运行的模块。功能模块介绍名称功能数据模型管道API模型参数模块模型变量相关模块分类算法模块聚类算法模块推荐系统模块回归算法模块参数调整模块模型验证模块。
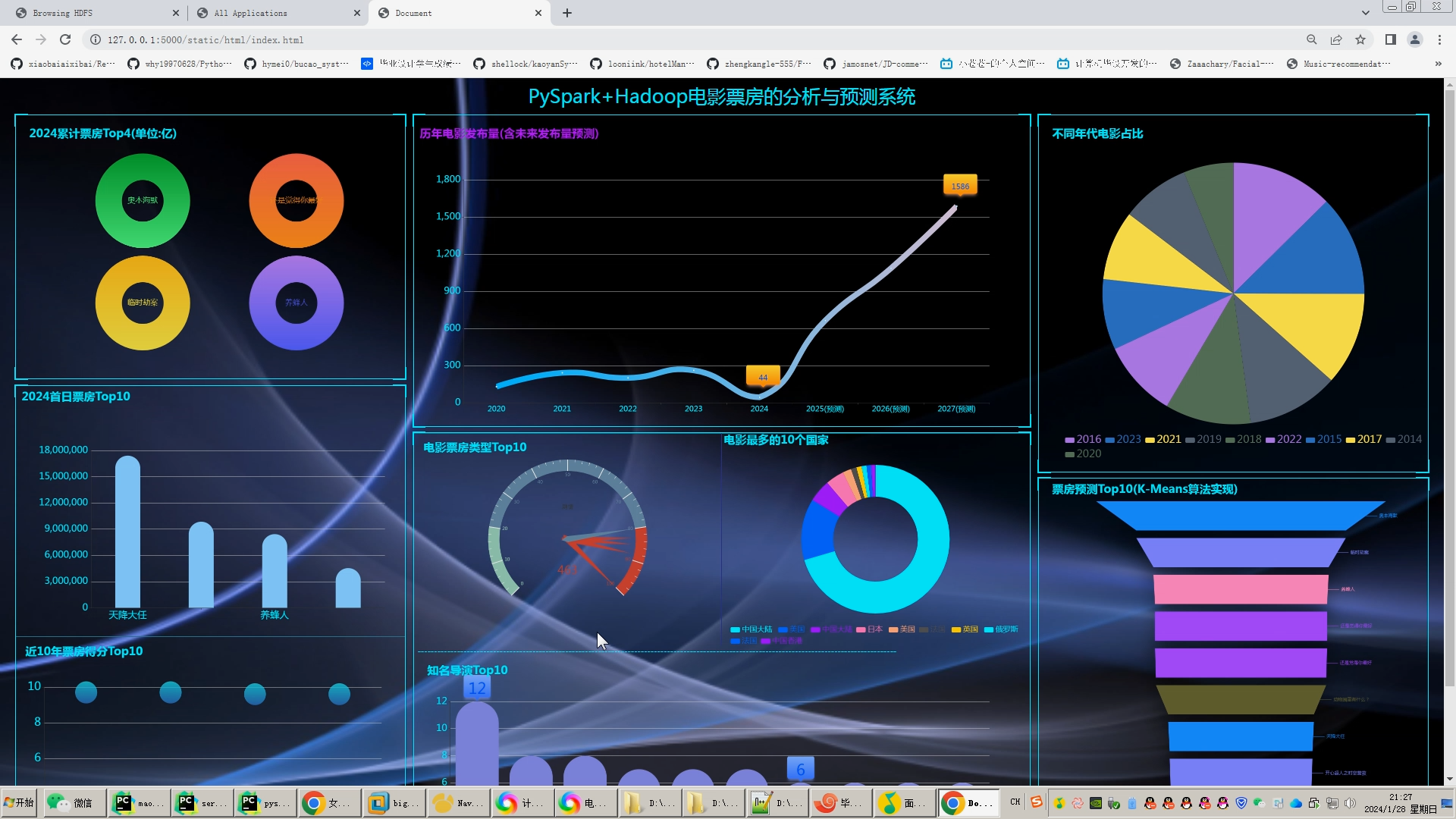
计算机毕业设计python+hadoop+spark猫眼电影票房预测 电影推荐系统 猫眼电影爬虫 电影数据可视化 电影用户画像系统 协同过滤算法 数据仓库 2024-06-04 爬虫, python, 信息可视化, 数据仓库, spark, hadoop, 开发语言 200人 已看 计算机毕业设计python+hadoop+spark猫眼电影票房预测 电影推荐系统 猫眼电影爬虫 电影数据可视化 电影用户画像系统 协同过滤算法 数据仓库
Spark_SparkOnHive_海豚调度跑任务写入Hive表失败解决 2024-05-28 hive, spark, hadoop, 分布式, 大数据 90人 已看 方法将 DataFrame 的数据插入到一个已经存在的Hive表中,如果该表已经存在,则直接将数据插入到该表中,如果表不存在,则会抛出异常。如果表不存在,则会自动创建该表,如果表已经存在,则会用DataFrame的数据覆盖该表中的数据。前段时间我在海豚上打包程序写hive出现了一个问题,spark程序向hive写数据时,报了如下bug,后来我删了建,把分区也删了,parquet格式也加了,还是报这个问题,因此排除是建表问题。后来我看代码,入库的语句如下,死活写不进去。如上,为什么会这样呢,我想了一下,
SparkyLinux简介 2024-05-30 spark, 运维, linux, 分布式, 大数据 94人 已看 MinimalGUI 版本:带有 Openbox 窗口管理器的节俭版本,只包含基本必需品,适用于希望完全灵活地创建自己桌面的用户。- MinimalCLI 版本:没有图形桌面的更节俭版本,适用于想要从头开始创建自己的桌面或不需要 GUI 的高级用户。- 标准桌面版:带有轻量级桌面环境的全功能标准桌面版本,几乎可以在任何硬件上即插即用,为家庭用户提供精选的软件选择。- 是的,Sparky 过去是、现在是,并将永远是对最终用户免费的。### **Sparky 的主要特点**
“Spark+Hive”在DPU环境下的性能测评 | OLAP数据库引擎选型白皮书(24版)DPU部分节选 2024-05-30 hive, spark, 硬件架构, 分布式, 大数据 94人 已看 在奇点云2024年版《OLAP数据库引擎选型白皮书》中,中科驭数联合奇点云针对Spark+Hive这类大数据计算场景下的主力引擎,测评DPU环境下对比CPU环境下的性能提升效果。特此节选该章节内容,与大家共享。
Spark SQL数据源 - Parquet文件 2024-06-01 spark, 分布式, ajax, 大数据, sql 133人 已看 如果你在一个集群环境中运行Spark,你需要将这部分配置更改为适合你的集群环境的设置。如果文件在HDFS或其他分布式文件系统中,你需要提供对应的URI。最后,你可以使用sbt或Maven等工具来构建和运行这个项目,或者如果你已经设置好了Spark环境,你可以使用。方法时,你可以看到DataFrame的完整模式,包括所有的列和它们的数据类型。Parquet文件通常包含嵌套的结构和复杂的数据类型,因此当你使用。替换为你的JAR文件的实际路径。如果你在本地运行,可以使用。替换为你的包含所有依赖的JAR包的路径。
Spark SQL数据源 - Hive表 2024-06-01 hive, spark, 分布式, 大数据, sql 88人 已看 Spark SQL对Hive的支持非常强大,可以直接读取和写入Hive表中的数据。Hive是一个基于Hadoop的数据仓库,它提供了SQL接口来查询和管理存储在HDFS或其他Hadoop兼容存储系统中的数据。
Spark SQL数据源 - Hive表 2024-06-01 hive, spark, 分布式, 大数据, sql 87人 已看 Spark SQL对Hive的支持非常强大,可以直接读取和写入Hive表中的数据。Hive是一个基于Hadoop的数据仓库,它提供了SQL接口来查询和管理存储在HDFS或其他Hadoop兼容存储系统中的数据。
spark SQL优化器catalyst学习 2024-06-01 学习, spark, 硬件架构, 分布式, 大数据 102人 已看 以上是一个关于 Spark SQL 优化器 Catalyst 的学习文档,希望对你有所帮助。如果你有任何问题或建议,请随时与我交流。即在资产许那阶段就提前将数据进行过滤,后续的join和shuffle数据量会大大减少。就是会提前将1 + 1计算成2,再赋给id列的每行,不用每次都计算一次1+1。就是提前将需要的列查询出来,其他不需要的列裁剪掉。一、Catalyst 概述。
大数据——Spark 2024-05-28 spark, 分布式, 大数据 58人 已看 MLlib是Spark的机器学习()库,旨在简化机器学习的工程实践工作,并方便扩展到更大规模。MLlib由一些通用的学习算法和工具组成,包括分类、回归、聚类、协同过滤、降维等,同时还包括底层的优化原语和高层的管道API。2.
pyspark==windows单机搭建 2024-05-28 spark, 分布式, 大数据 55人 已看 下载安装hadoop-3.3.5并完整替换bin目录,配置HADOOP_HOME。下载安装JDK17,配置JAVA_HOME。下载spark配置SPARK_HOME。注意要指定python的地址。