Hadoop、MapReduce、YARN和Spark的区别与联系 2024-05-15 mapreduce, spark, hadoop, yarn, 分布式, 大数据 128人 已看 Hadoop、MapReduce、YARN和Spark都是大数据处理领域中的关键技术和工具,它们共同构建了一个完整的大数据生态系统。Hadoop提供了分布式存储和计算的能力,MapReduce是Hadoop中的核心计算框架,YARN为Hadoop提供了更强大的资源调度和管理能力,而Spark则是一个基于内存计算的快速大数据处理框架。Hadoop、MapReduce、YARN和Spark在大数据处理领域中各自扮演着不同的角色,但它们之间也存在紧密的联系。
Hadoop、MapReduce、YARN和Spark的区别与联系 2024-05-15 mapreduce, spark, hadoop, yarn, 分布式, 大数据 112人 已看 Hadoop、MapReduce、YARN和Spark都是大数据处理领域中的关键技术和工具,它们共同构建了一个完整的大数据生态系统。Hadoop提供了分布式存储和计算的能力,MapReduce是Hadoop中的核心计算框架,YARN为Hadoop提供了更强大的资源调度和管理能力,而Spark则是一个基于内存计算的快速大数据处理框架。Hadoop、MapReduce、YARN和Spark在大数据处理领域中各自扮演着不同的角色,但它们之间也存在紧密的联系。
Hadoop、Spark、HBase与Redis的适用性见解 2024-05-15 spark, hadoop, 大数据, redis, hbase 123人 已看 总结来说,Hadoop、Spark、HBase和Redis各自具有不同的适用性和优势。Hadoop适合处理大规模数据集的离线批处理任务;Spark适用于实时数据分析、机器学习等多种场景;HBase适合存储稀疏表结构的数据;而Redis则适用于需要高速读写性能、低延迟和实时性的场景。在选择使用哪个技术时,需要根据具体的业务需求和场景来综合考虑。Hadoop、Spark、HBase和Redis各自在大数据技术领域具有不同的适用性和优势。
Hadoop、MapReduce、YARN和Spark的区别与联系 2024-05-15 mapreduce, spark, hadoop, yarn, 分布式, 大数据 110人 已看 Hadoop、MapReduce、YARN和Spark都是大数据处理领域中的关键技术和工具,它们共同构建了一个完整的大数据生态系统。Hadoop提供了分布式存储和计算的能力,MapReduce是Hadoop中的核心计算框架,YARN为Hadoop提供了更强大的资源调度和管理能力,而Spark则是一个基于内存计算的快速大数据处理框架。Hadoop、MapReduce、YARN和Spark在大数据处理领域中各自扮演着不同的角色,但它们之间也存在紧密的联系。
spark概述 2024-05-15 spark, 分布式, 大数据 44人 已看 Spark的主要优点包括易用性好(支持Scala、Java和Python等语言编写应用程序)、通用性强(能够无缝集成并提供一站式解决平台)、容错性高以及执行效率高。此外,Spark还具有良好的可扩展性和灵活性,可以根据需求动态调整集群规模,并支持多种数据格式和数据源。在应用场景方面,Spark可以用于数据处理与转换(如清洗、过滤、聚合和转换数据)、构建ETL管道、实时数据流处理以及图计算等多种场景。Spark是一个由Apache软件基金会开发的开源分布式计算框架,它提供了快速、通用的大规模数据处理能力。
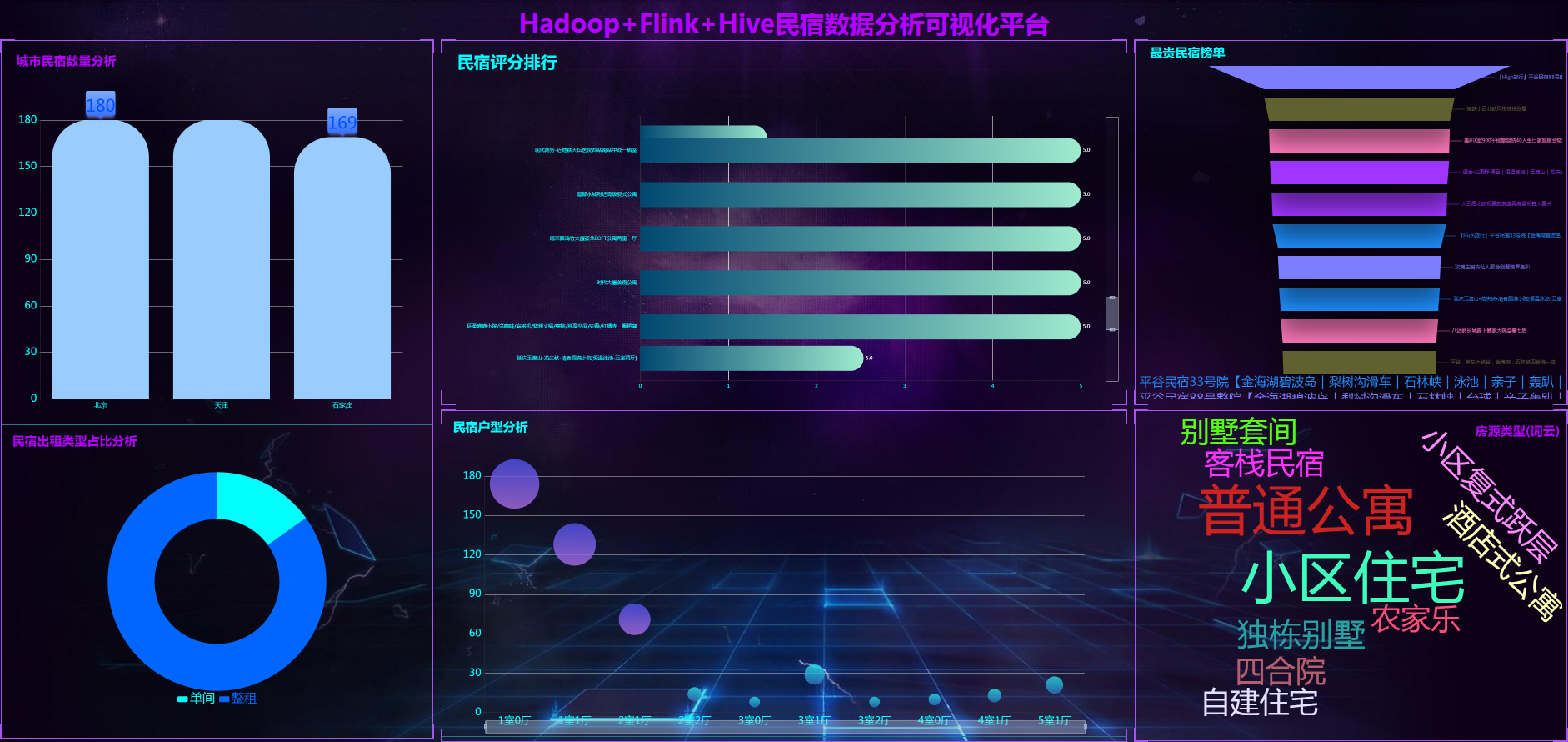
计算机毕业设计PyFlink+Spark+Hive民宿推荐系统 酒店推荐系统 民宿酒店数据分析可视化大屏 民宿爬虫 民宿大数据 知识图谱 机器学习 2024-05-19 hive, flink, 爬虫, 数据分析, 机器学习, spark, 知识图谱, 大数据 140人 已看 计算机毕业设计PyFlink+Spark+Hive民宿推荐系统 酒店推荐系统 民宿酒店数据分析可视化大屏 民宿爬虫 民宿大数据 知识图谱 机器学习
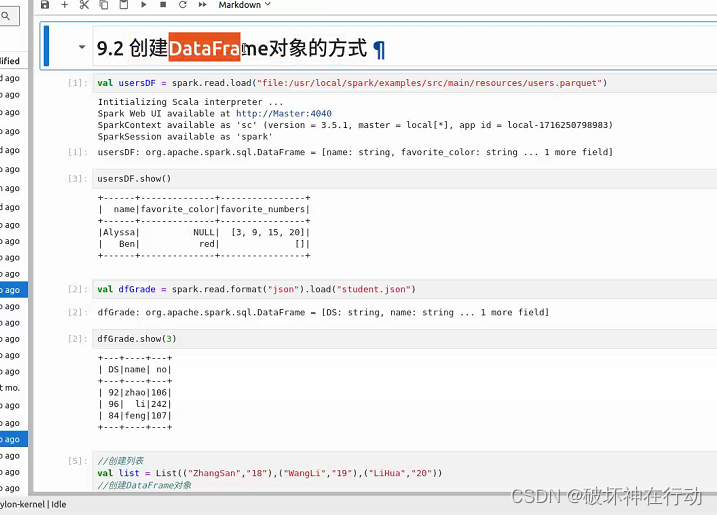
Hadoop+Spark大数据技术 实验8 Spark SQL结构化 2024-05-21 spark, hadoop, ajax, 大数据, sql 70人 已看 示例: gradedf.selectExpr("name", "name as names" ,"upper(Name)","Scala * 10").show(3)- 示例: gradedf.select("Name", "Class","Scala").show(3,false)修改名称:gradedf.select(gradedf("Name").as("name")).show()orderBy() 和 sort() 方法都可以用于对 DataFrame 进行排序,它们的功能相同。
Hadoop+Spark大数据技术 实验8 Spark SQL结构化 2024-05-21 spark, hadoop, ajax, 大数据, sql 70人 已看 示例: gradedf.selectExpr("name", "name as names" ,"upper(Name)","Scala * 10").show(3)- 示例: gradedf.select("Name", "Class","Scala").show(3,false)修改名称:gradedf.select(gradedf("Name").as("name")).show()orderBy() 和 sort() 方法都可以用于对 DataFrame 进行排序,它们的功能相同。
2.3 Spark运行架构与原理 2024-05-14 架构, spark, 分布式, 大数据 43人 已看 Spark运行架构由SparkContext、Cluster Manager和Worker构成。在集群模式下,Driver进程初始化SparkContext并向Cluster Manager申请资源,后者根据算法在Worker节点上启动Executor。Executor负责任务执行,反馈状态给Cluster Manager。任务由Task Scheduler发送给Executor执行,完成后Driver注销资源。 Spark的基本流程确保资源管理和任务执行的高效协作,支持并行计算作业的顺利完成。
使用java远程提交spark任务到yarn集群 2024-05-17 java, spark, yarn, 分布式, 大数据, 开发语言 98人 已看 公司需求中,需要用到java远程提交spark任务,方式还是用yarn提供的方法提交任务。如果你也想远程提交flink任务,请看这篇文章。
spark编程基础 2024-05-13 spark, 分布式, 大数据 38人 已看 subtract()方法用于将前一个RDD中在后一个RDD出现的元素删除,可以认为是求补集的操作,返回值为前一个RDD去除与后一个RDD相同元素后的剩余值所组成的新的RDD。使用flatMap()方法时先进行map(映射)再进行flat(扁平化)操作,数据会先经过跟map一样的操作,为每一条输入返回一个迭代器(可迭代的数据类型),然后将所得到的不同级别的迭代器中的元素全部当成同级别的元素,返回一个元素级别全部相同的RDD。转换操作是创建RDD的第二种方法,通过转换已有RDD生成新的RDD。
第十一章数据仓库和商务智能 2024-05-09 spark, 数据仓库, 分布式, 大数据 47人 已看 A:运营报表指的是业务用户直接从交易系统、应用程序或数据仓库生成报表。B:绩效管理是一套集成的组织流程和应用程序,旨在优化业务战略的执行。C:在线分析处理(OLAP)是一种为多维分析查询提供快速性能的方法。D:在线分析处理(OLAP)比在线事务处理(OLTP)对数据的实时性有更高的要求。正确答案:D 你的答案:D解析:309页~310页 1运营报表第一行,2业务绩效管理第一行,310页运营分析应用第二段第一行,D选项说反了。
SparkStructuredStreaming状态编程 2024-05-06 spark, 分布式, 大数据 42人 已看 spark官网关于spark有状态编程介绍比较少,本文是一篇个人理解关于spark状态编程。一般的流计算使用窗口函数可以解决大部分问题,但是一些比较复杂的业务,窗口函数无法解决,比如需要的数据范围大于你设定的时间窗口,那么就需要状态编程处理中间状态。
Apache Spark 的基本概念和在大数据分析中的应用 2024-05-11 apache, spark, 分布式, 大数据 52人 已看 弹性分布式数据集(Resilient Distributed Dataset,简称RDD):RDD 是 Spark 中的基本数据结构,它是一个分布式的不可变数据集合,可以在并行计算中进行操作和处理。总的来说,Apache Spark 是一个功能强大的大数据分析引擎,可以处理大规模数据集,支持多种数据处理和分析场景,是大数据分析中的重要工具之一。数据清洗和预处理:Spark 提供了丰富的数据处理和转换操作,可以对大规模数据进行清洗和预处理,如数据过滤、聚合、整理等。
离线和实时数据处理的设计区别 2024-05-09 spark, 分布式, 大数据 47人 已看 离线数据处理通常关注大规模数据集的批处理,处理时间可以从几分钟到数小时甚至更长。因此,离线处理可以容忍较高的数据延迟,不需要实时或接近实时的结果。而实时数据处理要求尽可能低的延迟,通常在毫秒或秒级别内提供实时响应。
Pyspark+关联规则 Kaggle购物篮分析案例 2024-05-01 spark, 分布式, ajax, 大数据, javascript 62人 已看 零售商期望能够利用过去的零售数据在自己的行业中进行探索,并为客户提供有关商品集的建议,这样就能提高客户参与度、改善客户体验并识别客户行为。本文将通过pyspark对数据进行导入与预处理,进行可视化分析并使用spark自带的机器学习库做关联规则学习,挖掘不同商品之间是否存在关联关系。
Spark面试整理-Spark和Flink的区别 2024-05-06 flink, 面试, spark, 分布式, 大数据 82人 已看 如果应用需要复杂的流处理、低延迟和高吞吐量,Flink可能是更好的选择。而对于批处理或对延迟要求不高的流处理任务,以及需要丰富生态系统和成熟稳定性的场景,Spark可能更加适合。Apache Spark和Apache Flink都是流行的大数据处理框架,但它们在设计理念、性能特性以及适用的使用场景上有所不同。也提供了丰富的API,包括DataStream API和Table API,同时有一定的机器学习和图处理的支持。适合于需要低延迟和高吞吐量的实时流处理应用,以及复杂的事件驱动应用。
【spark RDD】spark 之 Kryo高性能序列化框架 2024-05-07 spark, 前端, 分布式, ajax, 大数据 89人 已看 【spark RDD】spark 之 Kryo序列化框架