详解 Spark 核心编程之 RDD 序列化 2024-05-31 spark, 分布式, 大数据 46人 已看 参考地址:https://github.com/EsotericSoftware/kryo。自定义 Kryo 序列化。
Spark-Shell使用Scala的版本 2024-05-31 scala, spark, 分布式, 大数据, 开发语言 118人 已看 在Spark-Shell中使用的Scala版本取决于你安装的Spark版本。这些技术细节共同构成了Spark大数据处理框架的核心能力和优势,使得Spark在大数据处理和分析领域得到了广泛的应用。
Spark基础:掌握RDD算子 2024-05-29 spark, 分布式, 大数据 44人 已看 Apache Spark 的核心组件之一是弹性分布式数据集(Resilient Distributed Dataset,简称 RDD)。RDD 是 Spark 中不可变、分布式对象集合的抽象,它允许你在集群上执行各种转换(transformations)和动作(actions)。以下是 RDD 的一些基础算子(operators)的概述,这些算子被分为转换(transformations)和动作(actions)两类。
Spark基础:掌握RDD算子 2024-05-29 spark, 分布式, 大数据 40人 已看 Apache Spark 的核心组件之一是弹性分布式数据集(Resilient Distributed Dataset,简称 RDD)。RDD 是 Spark 中不可变、分布式对象集合的抽象,它允许你在集群上执行各种转换(transformations)和动作(actions)。以下是 RDD 的一些基础算子(operators)的概述,这些算子被分为转换(transformations)和动作(actions)两类。
Spark入门:KMeans聚类算法 2024-05-30 spark, 分布式, 大数据 45人 已看 是机器学习中一类重要的方法。其主要思想使用样本的不同特征属性,根据某一给定的相似度度量方式(如欧式距离)找到相似的样本,并根据距离将样本划分成不同的组。聚类属于典型的方法。与监督学习(如分类器)相比,无监督学习的训练集没有人为标注的结果。在非监督式学习中,数据并不被特别标识,学习模型是为了推断出数据的一些内在结构。
从了解到掌握 Spark 计算框架(二)RDD 2024-05-30 spark, wpf, 分布式, ajax, 大数据 95人 已看 RDD(Resilient Distributed Dataset)是 Spark 中的核心数据抽象,代表着分布式的不可变的数据集合。分布式的:RDD 将数据分布存储在集群中的多个计算节点上,每个节点上都存储着数据的一个分区。这样可以实现数据的并行处理和计算。不可变的:RDD 是不可变的数据集合,一旦创建就不能被修改。任何对 RDD 进行的转换操作都会生成一个新的 RDD,原始的 RDD 不受影响。可并行计算的:RDD 支持并行计算,可以在集群中的多个计算节点上同时进行计算。
计算机毕业设计Python+Spark+PyTroch游戏推荐系统 游戏可视化 游戏爬虫 神经网络混合CF推荐算法 协同过滤推荐算法 steam 大数据 2024-05-23 爬虫, python, spark, 游戏, 神经网络, 大数据, 推荐算法 86人 已看 计算机毕业设计Python+Spark+PyTroch游戏推荐系统 游戏可视化 游戏爬虫 神经网络混合CF推荐算法 协同过滤推荐算法 steam 大数据
计算机毕业设计Python+Spark+PyTroch游戏推荐系统 游戏可视化 游戏爬虫 神经网络混合CF推荐算法 协同过滤推荐算法 steam 大数据 2024-05-23 爬虫, python, spark, 游戏, 神经网络, 大数据, 推荐算法 81人 已看 计算机毕业设计Python+Spark+PyTroch游戏推荐系统 游戏可视化 游戏爬虫 神经网络混合CF推荐算法 协同过滤推荐算法 steam 大数据
记一次Spark cache table导致的数据问题以及思考 2024-05-22 spark, 分布式, 大数据 70人 已看 这会导致shuffle后的数据进行了错位(因为之前是shuffle(200),现在变成了shuffle(10)),具体原因笔者还是没有分析清楚,但是其中涉及到的点跟规则。从以上的分析知道:是在做join的一方(包含了AQEshuffleRead-coalesced) 影响了join的另一方,导致。目前在做 Spark 升级(3.1.1升级到3.5.0)的时候,遇到了。导致的数据重复问题,这种情况一般来说是很少见的,因为一般很少用。会做一些执行前的判断,主要是做任务shuffle的协调,
PySpark面试题精选及参考答案(3万字长文) 2024-05-22 spark, 分布式, 大数据 68人 已看 PySpark是Apache Spark的Python API,它允许开发者使用Python语言来操作Spark框架,执行大数据处理和分析任务。PySpark作为Spark生态系统的一部分,继承了Spark的分布式计算能力,能够高效地处理大规模数据集。主要应用场景包括:对大量积累的数据进行批量处理和分析,例如日志数据分析、用户行为分析等。通过Spark Streaming进行实时数据流的处理,适用于实时监控系统、实时推荐系统等。
PySpark面试题精选及参考答案(3万字长文) 2024-05-22 spark, 分布式, 大数据 39人 已看 PySpark是Apache Spark的Python API,它允许开发者使用Python语言来操作Spark框架,执行大数据处理和分析任务。PySpark作为Spark生态系统的一部分,继承了Spark的分布式计算能力,能够高效地处理大规模数据集。主要应用场景包括:对大量积累的数据进行批量处理和分析,例如日志数据分析、用户行为分析等。通过Spark Streaming进行实时数据流的处理,适用于实时监控系统、实时推荐系统等。
计算机毕业设计Python+Spark+PyTroch游戏推荐系统 游戏可视化 游戏爬虫 神经网络混合CF推荐算法 协同过滤推荐算法 steam 大数据 2024-05-23 爬虫, python, spark, 游戏, 神经网络, 大数据, 推荐算法 102人 已看 计算机毕业设计Python+Spark+PyTroch游戏推荐系统 游戏可视化 游戏爬虫 神经网络混合CF推荐算法 协同过滤推荐算法 steam 大数据
spark 之数据湖 2024-05-22 spark, 前端, ajax, 分布式, 大数据 123人 已看 基本使用 可参见: https://docs.delta.io/2.3.0/quick-start.html#language-scala。
spark 之数据湖 2024-05-22 spark, 前端, ajax, 分布式, 大数据 43人 已看 基本使用 可参见: https://docs.delta.io/2.3.0/quick-start.html#language-scala。
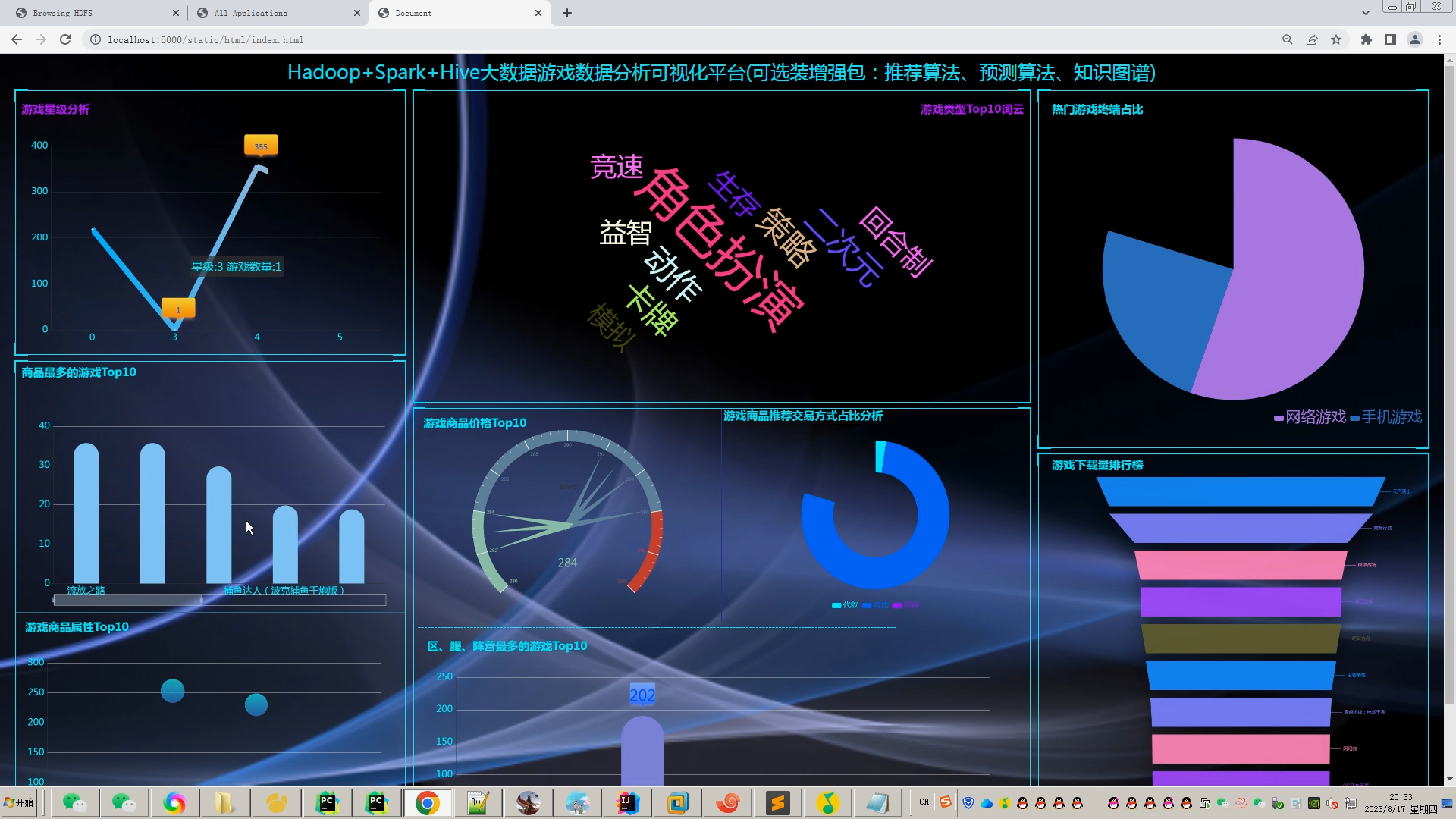
计算机毕业设计hadoop+spark+hive物流大数据分析平台 物流预测系统 物流信息爬虫 物流大数据 机器学习 深度学习 2024-05-29 hive, 机器学习, spark, 深度学习, hadoop, 大数据 65人 已看 计算机毕业设计hadoop+spark+hive物流大数据分析平台 物流预测系统 物流信息爬虫 物流大数据 机器学习 深度学习
【大数据篇】Spark:大数据处理的璀璨之星 2024-05-21 spark, 分布式, 大数据 32人 已看 结尾彩蛋:李华深吸了一口气,决定采取一系列步骤来定位和解决问题。首先,他回滚了Spark作业的最新变更,排除了因代码更新导致的错误可能性。接着,他仔细检查了作业的配置参数,如内存分配、并行度等,确保它们与集群资源相匹配。>- 然而,这些尝试都没有解决问题。李华意识到,可能需要更深入地分析作业的执行情况。他打开了Spark UI,仔细查看了作业的DAG(有向无环图)和执行阶段。在仔细观察后,他发现某个特定的Shuffle操作异常耗时,并且内存使用率极高。李华意识到这可能是问题的关键所在。他回想起之前
数据仓库、数据中台、大数据平台之间的关系 2024-05-20 数据仓库, spark, 分布式, 大数据 42人 已看 数据行业经常会出现数据仓库、数据中台、大数据平台等概念,容易产生疑问,它们中间是相等,还是包含的关系?
AIGC行业现在适合进入吗?最新AI系统ChatGPT网站源码(SparkAi创作系统) 2024-05-20 spark, 人工智能, aigc, 分布式, 大数据 110人 已看 技术成熟度:当前的AIGC技术已经能够生成高质量的文本、图像和音乐内容,甚至在某些方面超越了人类创作者的能力。市场需求:随着企业和个人对高效内容生产的需求增加,AIGC市场正在迅速扩展。据市场研究报告显示,AIGC市场规模预计在未来几年将保持高速增长。竞争环境:虽然已经有一些领先企业在该领域占据了一定的市场份额,但由于市场规模庞大,新的创业公司依然有很大的发展空间。进入AIGC行业有许多显著的优势。虽然AIGC行业充满了机会,但也存在一些挑战需要克服。如果你决定进入AIGC行业,以下是一些建议策略