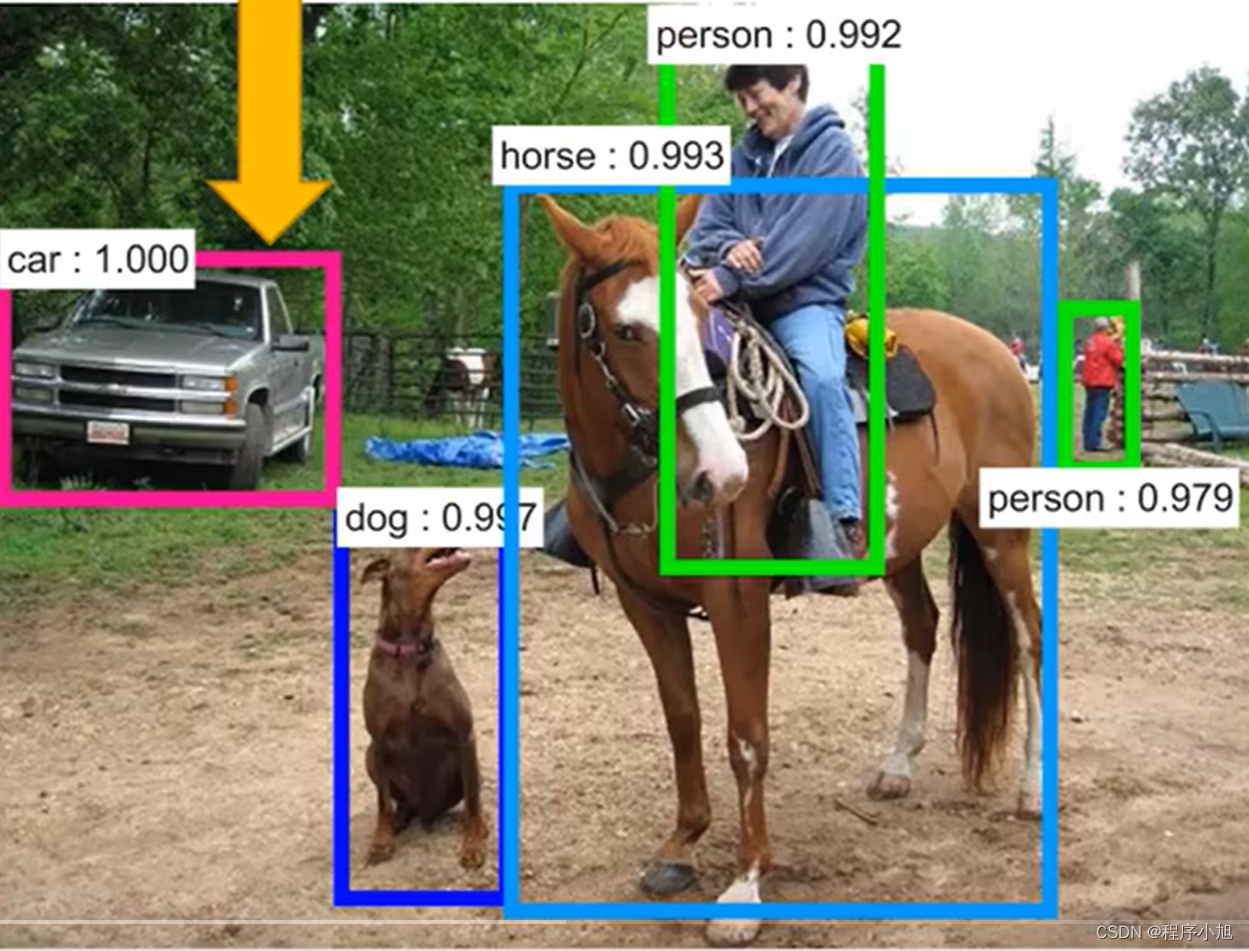
在动手学习深度学习中对目标检测任务有如下的描述。图像分类任务中,我们假设图像中只有一个主要物体对象,我们只关注如何识别其类别。然而,很多时候图像里有多个我们感兴趣的目标,我们不仅想知道它们的类别,还想得到它们在图像中的具体位置。在计算机视觉里,我们将这类任务称为目标检测(object detection)或目标识别(object recognition)通过边界框给出了物体的相关位置信息我们通常使用边界框(bounding box)来描述对象的空间位置。边界框是矩形的,由矩形左上角的以及右下角的。