【多模态融合】Cross Modal Transformer: Towards Fast and Robust 3D Object Detection 2024-05-20 3d, c语言, 计算机视觉, 目标检测, 人工智能 146人 已看 多传感器融合在自动驾驶系统中展示了其巨大优势。不同的传感器通常能提供互补的信息。例如,摄像头以透视视角捕捉信息,图像中包含丰富的语义特征,而点云则提供更多的定位和几何信息。充分利用不同传感器有助于减少不确定性,从而进行准确和鲁棒的预测。然而,由于不同模态的传感器数据在分布上的巨大差异,融合这些多模态数据一直是个挑战。当前的主流方法通常通过构建统一的鸟瞰图(BEV)表示来进行多模态特征融合,或通过查询令牌(Transformer架构)来实现多模态融合。
python 获取视频的时长 2024-05-20 python, 音视频, 计算机视觉, opencv, 开发语言 159人 已看 方法三:使用ffprobe命令行工具。方法一:使用moviepy库。方法二:使用cv2库。
YOLOv8目标检测离线数据增强,检查标签是否越界,标签可视化! 2024-05-20 yolo, 计算机视觉, 目标检测, 人工智能 314人 已看 YOLOv8目标检测离线数据增强的方式:首先使用labelme对图像进行标注,将图像和标注文件存放到images和annotations文件夹中,然后使用离线数据增强代码对进行增强。1.在代码中设置增强次数和文件路径,选择想要数据增强的方式。
【python进阶】txt excel pickle opencv操作demo 2024-05-23 excel, 计算机视觉, 人工智能, javascript, opencv 110人 已看 写一段代码,模拟生成accuracy逐步上升、loss逐步下降的训练日志,并将日志信息记录到 training_log.txt中。##读取YOLO数据后画出曲线图。
pillow学习2 2024-05-19 学习, 算法, 计算机视觉, pillow, 人工智能 120人 已看 在 Pillow 库中的 Image 模块中,使用函数 filter()可以对指定的图片使用滤镜效果,在Pillow 库中可以用的滤镜保存在 ImageFilter 模块中。在 Pillow 库的 Image 模块中,可以使用函数 eval()实现像素缩放处理,能够使用函数 fun()计算输入图片的每个像素并返回。在 Pillow 库的 Image 模块中,函数 rotate()的功能返回此图像的副本,围绕其中心逆时针旋转给定的度数。例如,在图像合成中,遮罩可以决定前景图像的哪些部分应该显示在背景图像上。
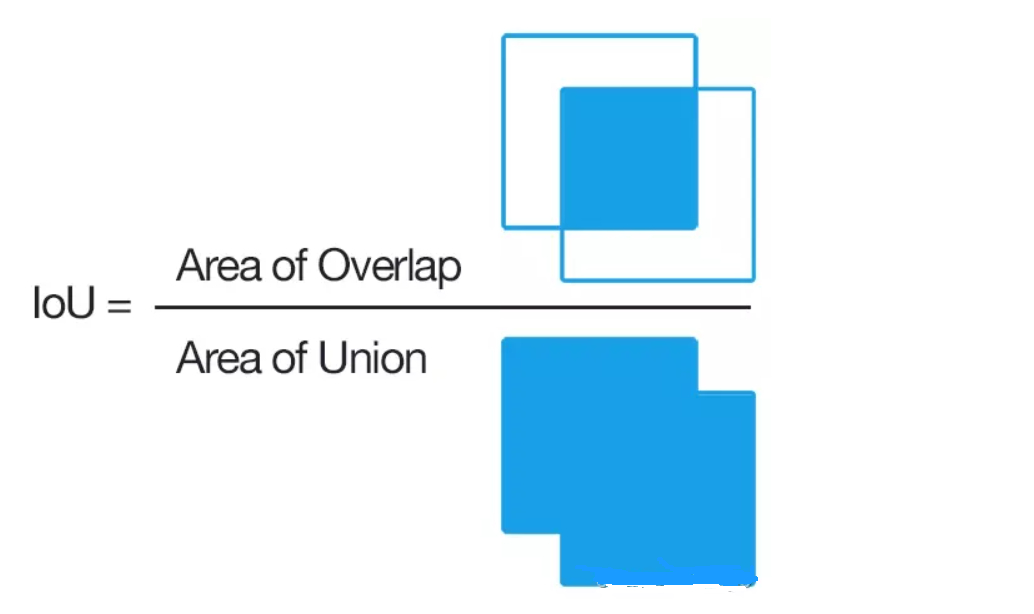
【目标检测】关于YOLO系列算法中Confidence置信度的计算和理解 2024-05-19 算法, 计算机视觉, 目标检测, 人工智能 875人 已看 关于YOLO系列算法中Confidence置信度的计算和理解
计算机视觉与深度学习实战:以Python为工具,基于不变矩的数字验证码识别 2024-05-16 python, 计算机视觉, 人工智能, 开发语言 96人 已看 随着数字化时代的到来,验证码作为一种有效的安全验证机制,广泛应用于各类网站和应用程序中。然而,对于用户而言,手动输入验证码不仅增加了操作复杂性,还可能因输入错误而导致验证失败。因此,研究基于计算机视觉和深度学习的自动验证码识别技术具有重要的实际意义和应用价值。本文将以Python为工具,探讨基于不变矩的数字验证码识别方法,旨在提高验证码识别的准确性和效率。
深度学习计算机视觉中,什么是无监督域自适应算法? 2024-05-19 计算机视觉, 深度学习, 人工智能 603人 已看 无监督域自适应(Unsupervised Domain Adaptation, UDA)算法是深度学习和计算机视觉中用于解决域间分布差异问题的一类方法。在实际应用中,训练数据(源域)和测试数据(目标域)可能来自不同的分布,这种差异会导致模型在目标域上表现不佳。无监督域自适应算法旨在减少这种分布差异,使得模型在目标域上能够更好地泛化。
[数据集][目标检测]手枪机枪刀检测数据集VOC+YOLO格式5990张3类别 2024-05-19 yolo, 计算机视觉, 目标检测, 深度学习, 人工智能 118人 已看 数据集格式:Pascal VOC格式+YOLO格式(不包含分割路径的txt文件,仅仅包含jpg图片以及对应的VOC格式xml文件和yolo格式txt文件)特别声明:本数据集不对训练的模型或者权重文件精度作任何保证,数据集只提供准确且合理标注。标注类别名称:[“Rifle”,“knife”,“pistol”]图片数量(jpg文件个数):5990。标注数量(xml文件个数):5990。标注数量(txt文件个数):5990。使用标注工具:labelImg。标注规则:对类别进行画矩形框。
计算机视觉与深度学习实战:以Python为工具,基于分水岭分割进行肺癌诊断 2024-05-23 python, 计算机视觉, 人工智能, 开发语言 92人 已看 计算机视觉是一门研究如何使机器从数字图像或视频中提取、分析和理解有用信息的学科。它涉及图像处理、模式识别、机器学习等多个领域,是人工智能领域的一个重要分支。深度学习作为机器学习的一个子集,通过模拟人脑神经网络的工作方式,实现了对图像、文本等数据的自动学习和理解。在计算机视觉领域,深度学习技术已经被广泛应用于图像分类、目标检测、图像分割等多个方面。
opencv 关于 卷积核(掩膜) 的通俗理解 2024-05-20 笔记, 计算机视觉, 人工智能, opencv 135人 已看 / 创建一个示例图像(3x3矩阵)4, 5, 6,7, 8, 9);// 定义卷积核(边缘检测或锐化)-1, 8, -1,// 创建用于存储结果的图像Mat result;// 使用不同的边缘填充方法进行卷积操作// 1. 零填充(BORDER_CONSTANT)// 2. 镜像填充(BORDER_REFLECT)// 3. 重复边缘像素填充(BORDER_REPLICATE)// 4. 环绕填充(BORDER_WRAP)return 0;
抠像标签合并到原图,jpg 和 png合并,查看标签是否准确 2024-05-22 python, 计算机视觉, 人工智能, opencv, 开发语言 108人 已看 抠像 原图 和 标签合并,查看抠像是否准确。合并后的图,是带有 羽化 效果的。
【SVG 生成系列论文(五)】Diffvg 矢量图生成的开山之作 —— MIT 与 Adobe 合作论文 2024-05-16 计算机视觉, 深度学习, 人工智能, adobe, 神经网络 1085人 已看 本文简要介绍的 Diffvg 则属于 svg 生成与编辑领域的开山之作。论文全称:Differentiable Vector Graphics Rasterization for Editing and Learning(用于编辑和学习的可微分矢量图形光栅化)项目链接:https://github.com/BachiLi/diffvg。
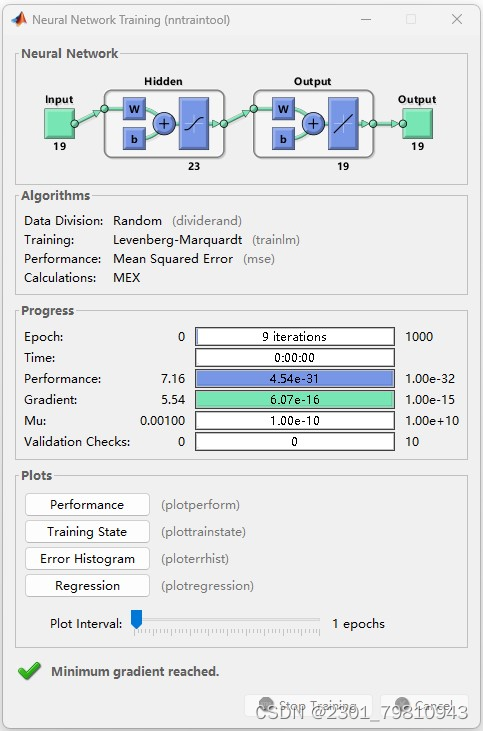
基于Matlab神经网络高铁铁道电力线安全隐患检测识别系统 2024-05-18 计算机视觉, 人工智能 86人 已看 一、项目背景与意义随着高铁交通网络的迅速发展,电力线路作为高铁运行的重要基础设施之一,其安全性和可靠性对高铁的正常运行具有至关重要的影响。然而,由于环境复杂多变、设备老化、人为破坏等因素,电力线路常常存在各种安全隐患,如绝缘破损、导线断裂、异物悬挂等。因此,开发一种高效、准确的高铁铁道电力线安全隐患检测识别系统具有重要的现实意义。本项目旨在利用Matlab神经网络技术,构建一个能够自动识别高铁铁道电力线安全隐患的智能系统。
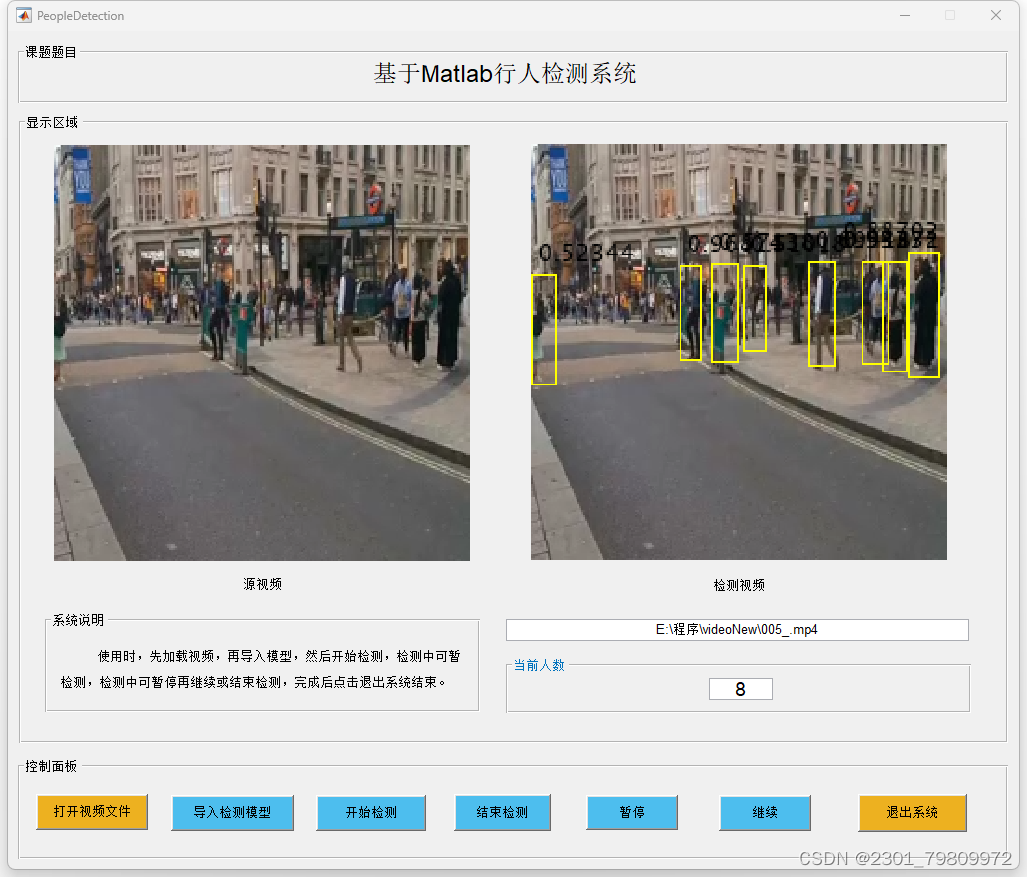
基于Matlab编写的Yolo算法行人检测系统 2024-05-18 机器学习, 计算机视觉, 人工智能, 目标跟踪 288人 已看 一、项目背景与意义在当前的视频监控和安全监控领域,对行人进行准确、高效的检测是至关重要的。传统的行人检测方法主要依赖于人工观察,这种方式存在实时性差、工作量大、易疲劳等问题。为了解决这些问题,本项目基于Matlab编程环境和Yolo(You Only Look Once)算法,开发了一套行人检测系统。该系统能够实时、准确地检测图像或视频中的行人目标,为视频监控和安全监控领域提供了一种新的解决方案。