Colly 是一款用 Go 语言编写的优雅网络爬虫框架,速度快、灵活且易于使用
关键特性包括:
- 线程安全。
- 用户友好的 API。
- 支持 XHR(Ajax)和 WebSocket。
- 缓存和持久化。
- 支持速度限制和分布式爬取。
- 强大的可扩展性。
colly采集器配置
- AllowedDomains: 设置收集器使用的域白名单,设置后不在白名单内链接,报错:Forbidden domain。
- AllowURLRevisit: 设置收集器允许对同一 URL 进行多次下载。
- Async: 设置收集器为异步请求,需很Wait()配合使用。
- Debugger: 开启Debug,开启后会打印请求日志。
- MaxDepth: 设置爬取页面的深度。
- UserAgent: 设置收集器使用的用户代理。
- MaxBodySize : 以字节为单位设置检索到的响应正文的限制。
- IgnoreRobotsTxt: 忽略目标机器中的robots.txt声明。
创建采集器:配置可以写在里面,也可以写在外面。
collector := colly.NewCollector(
colly.AllowedDomains("www.baidu.com",".baidu.com"),//白名单域名
colly.AllowURLRevisit(),//允许对同一 URL 进行多次下载
colly.Async(true),//设置为异步请求
colly.Debugger(&debug.LogDebugger{}),// 开启debug
colly.MaxDepth(2),//爬取页面深度,最多为两层
colly.MaxBodySize(1024 * 1024),//响应正文最大字节数
colly.UserAgent("Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) "),
colly.IgnoreRobotsTxt(),//忽略目标机器中的`robots.txt`声明
)1、执行流程
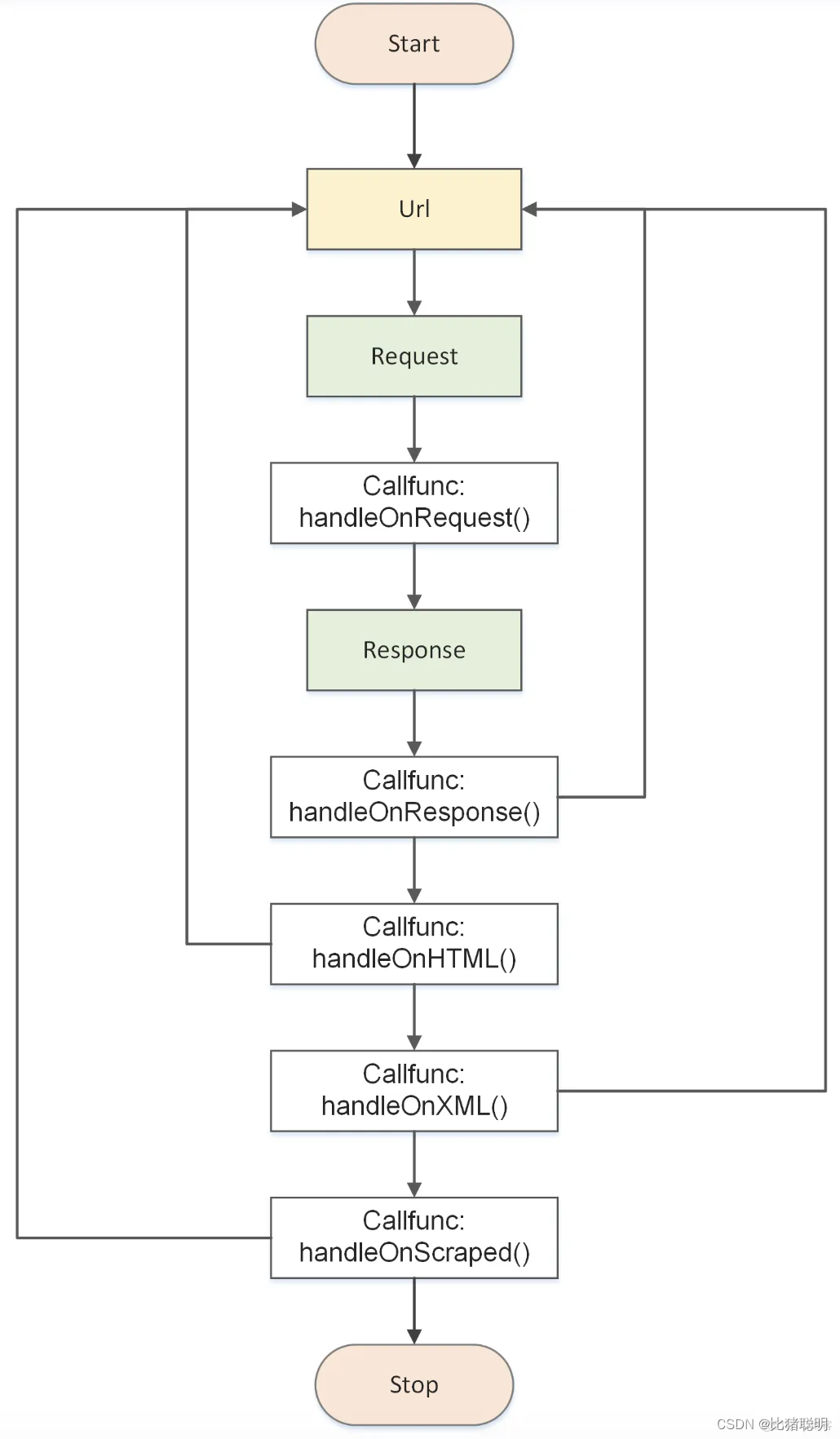 2、回调函数
2、回调函数
colly附加各种不同类型的回调函数,来控制收集作业或获取信息

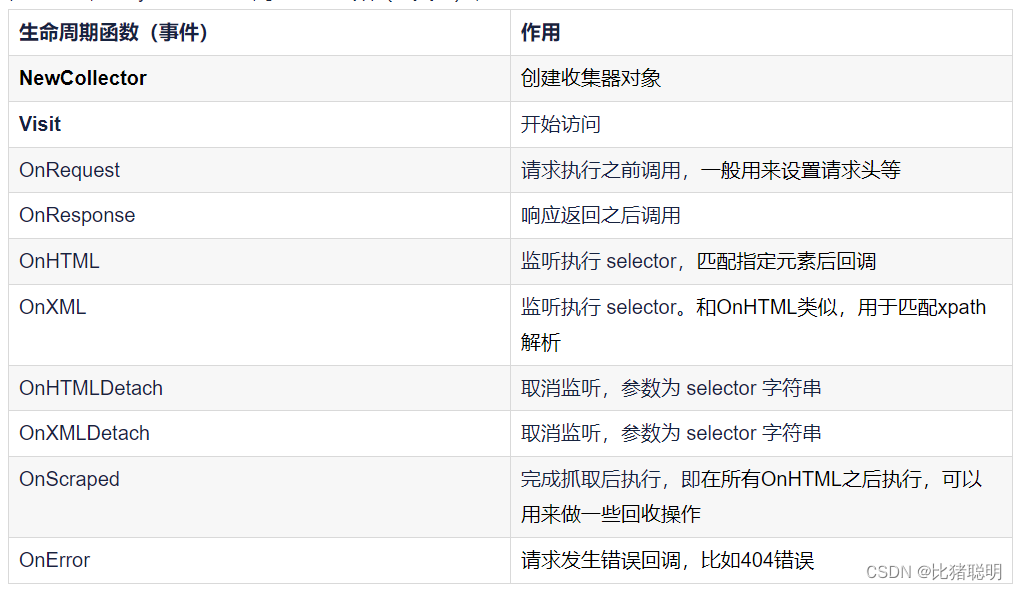
3、安装
go get -u github.com/gocolly/colly4、案例
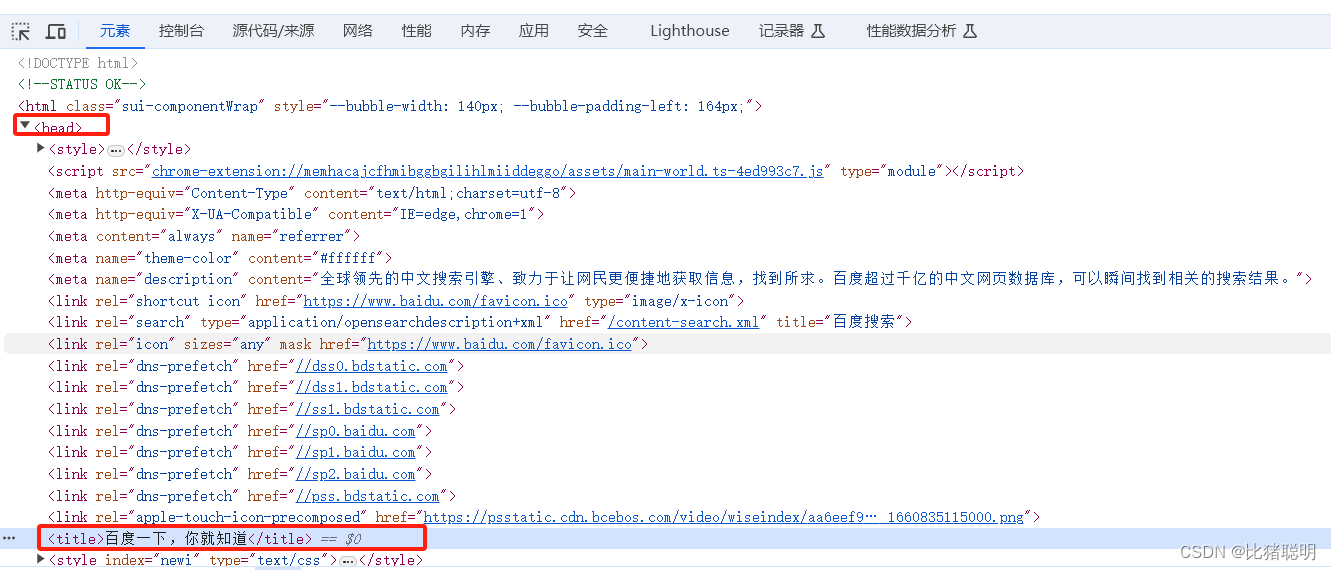
案例一:爬取网络页面标题
package main
import (
"fmt"
"github.com/gocolly/colly"
)
func main() {
// 创建Collector实例
c := colly.NewCollector()
// 设置请求处理逻辑
c.OnHTML("head > title", func(e *colly.HTMLElement) {
fmt.Println("网页标题:", e.Text)
})
// 设置错误处理逻辑
c.OnError(func(r *colly.Response, err error) {
fmt.Println("请求错误:", err)
})
// 开始爬取
c.Visit("http://www.baidu.com")
}
案例二:爬取指定元素内容
package main
import (
"fmt"
"github.com/gocolly/colly"
)
func main() {
// 创建Collector实例
c := colly.NewCollector()
// 设置请求处理逻辑,第一个参数是查询选择器,类似CSS选择器一样的语法
c.OnHTML("body > div#wrapper > div#head > div#s-top-left > a", func(e *colly.HTMLElement) {
// 打印出每个新闻标题链接的文本和它的 href 属性
fmt.Println("栏目:", e.Text)
fmt.Println("链接地址:", e.Attr("href"))
})
// 设置错误处理逻辑
c.OnError(func(r *colly.Response, err error) {
fmt.Println("请求错误:", err)
})
// 开始爬取
c.Visit("http://www.baidu.com")
}

案例三:爬取图片
package main
import (
"fmt"
"github.com/gocolly/colly"
"github.com/google/uuid"
"io"
"net/http"
"os"
"path/filepath"
"strings"
)
func init() {
dirName := "img" // 要创建的文件夹名称
// 使用filepath.Join可以更好地处理路径分隔符,使其跨平台
dirPath := filepath.Join(".", dirName)
// 判断目录是否存在
if _, err := os.Stat(dirPath); os.IsNotExist(err) {
// 如果不存在,则创建
err = os.Mkdir(dirPath, 0755) // 0755 是权限位,表示所有者有读、写、执行权限,组用户和其他用户有读和执行权限
if err != nil {
fmt.Printf("创建目录失败: %v\n", err)
return
}
fmt.Printf("目录 '%s' 创建成功。\n", dirPath)
} else if err != nil {
// 其他错误处理
fmt.Printf("检查目录状态时发生错误: %v\n", err)
return
} else {
// 目录已存在
fmt.Printf("目录 '%s' 已存在,无需创建。\n", dirPath)
}
}
func main() {
//实例化默认收集器
c := colly.NewCollector()
// 在访问页面之前执行的回调函数
c.OnRequest(func(r *colly.Request) {
fmt.Println("OnRequest函数是在发起请求前被调用:", r.URL.String())
})
// 在访问页面之后执行的回调函数
c.OnResponse(func(r *colly.Response) {
fmt.Println("OnRespo