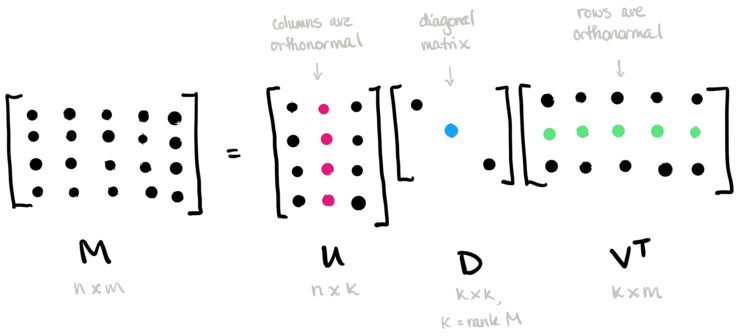
【课程总结】Day5(下):PCA降维、SVD分解、聚类算法和集成学习 2024-06-03 集成学习, 机器学习, 人工智能 356人 已看 人们早就知晓,相比凉爽的天气,蟋蟀在较为炎热的天气里鸣叫更为频繁。数十年来,专业和业余昆虫学者已将每分钟的鸣叫声和温度方面的数据编入目录,通过将数据绘制为图表如下:此曲线图表明温度随着鸣叫声次数的增加而上升。我们可以绘制一条直线来近似地表示这种关系,如下所示:事实上,虽然该直线并未精确无误地经过每个点,但针对我们拥有的数据,清楚地显示了鸣叫声与温度之间的关系(即y = mx + b)。如果我们输入一个新的每分钟的鸣叫声值 x1推断(预测)温度 y′,只需将 x1 值代入此模型即可。
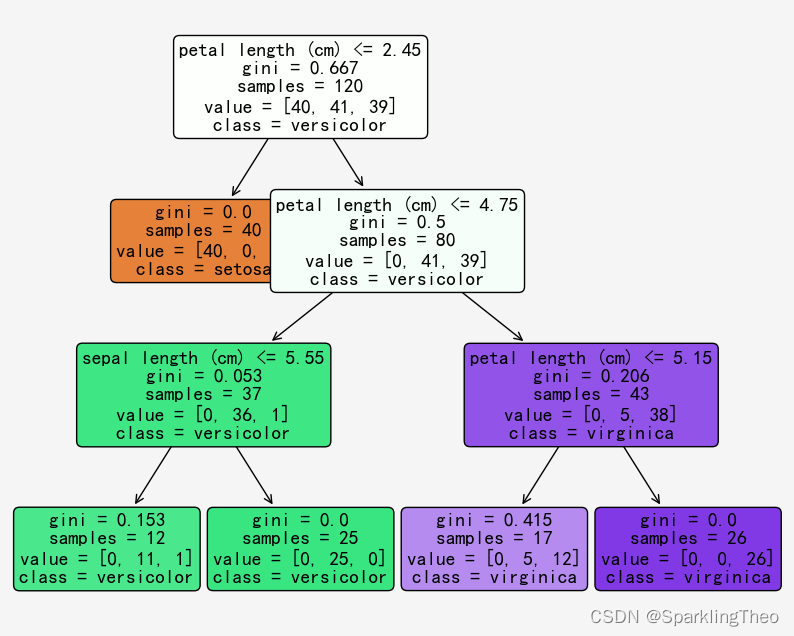
决策树|随机森林 GBDT XGBoost|集成学习 2024-05-27 算法, 集成学习, 机器学习, 随机森林, 决策树 371人 已看 本文首先介绍了决策树的数学背景,同时介绍集成学习相关的bagging boosting 模型理论,最后介绍了随机森林模型和两种最常用的随机森林模型算法GBDT 和XGBoost
决策树|随机森林 GBDT XGBoost|集成学习 2024-05-27 算法, 集成学习, 机器学习, 随机森林, 决策树 362人 已看 本文首先介绍了决策树的数学背景,同时介绍集成学习相关的bagging boosting 模型理论,最后介绍了随机森林模型和两种最常用的随机森林模型算法GBDT 和XGBoost
7集成学习评分卡 2024-05-15 集成学习, 机器学习, 人工智能 285人 已看 梯度提升最强大的特性之一是它适用于各种各样的损失函数。这意味着我们也可以设计自己的、更加适用于某一特定问题的损失函数来处理我们的数据集和任务的特定属性。某些情况下我们可能需要高召回率(更少的假阴性,在医学诊断中)或高精准率(更少的假阳性,例如,在垃圾邮件检测中),而不是高准确率。在许多此类场景中,通常需要自定义损失函数。
机器学习(五) -- 监督学习(4) -- 集成学习方法-随机森林 2024-05-21 算法, 集成学习, 机器学习, 随机森林, 人工智能 340人 已看 tips:标题前有“***”的内容为补充内容,是给好奇心重的宝宝看的,可自行跳过。文章内容被“文章内容”删除线标记的,也可以自行跳过。!!”一般需要特别注意或者容易出错的地方。本系列文章是作者边学习边总结的,内容有不对的地方还请多多指正,同时本系列文章会不断完善,每篇文章不定时会有修改。由于作者时间不算富裕,有些内容的《算法实现》部分暂未完善,以后有时间再来补充。见谅!文中为方便理解,会将接口在用到的时候才导入,实际中应在文件开始统一导入。
机器学习-12-sklearn案例02-集成学习 2024-05-10 集成学习, python, 机器学习, 人工智能, sklearn 337人 已看 本文是sklearn的案例总结部分,包括完整的算法使用过程,集成学习的使用过程,模型融合的使用过程