计算机毕业设计Python深度学习游戏推荐系统 Django PySpark游戏可视化 游戏数据分析 游戏爬虫 Scrapy 机器学习 人工智能 大数据毕设 2024-07-18 爬虫, 数据分析, django, 机器学习, spark, 人工智能, 游戏, scrapy, 大数据, 课程设计 1583人 已看 计算机毕业设计Python深度学习游戏推荐系统 Django PySpark游戏可视化 游戏数据分析 游戏爬虫 Scrapy 机器学习 人工智能 大数据毕设
深入探索:scikit-learn中递归特征消除(RFE)的奥秘 2024-07-05 python, 机器学习, scikit-learn, 人工智能 536人 已看 RFE是一种特征选择方法,它通过递归地构建模型并消除最不重要的特征,直到达到所需的特征数量。初始化:使用所有特征训练一个基模型。递归消除:在每一步中,移除权重最小的特征,重新训练模型。权重评估:评估每个特征对模型的贡献度,通常通过模型的系数大小来衡量。重复过程:重复上述过程,直到达到所需的特征数量。
机器学习——逻辑回归 2024-07-06 算法, 机器学习, 人工智能, 逻辑回归, 数据挖掘 537人 已看 逻辑回归是一个二分类算法,本文主要介绍了逻辑回归流程以及逻辑回归的损失评估,报考精确率和召回率,F1-score,ROC曲线和AUC指标,最后以癌症预测为案例并查看各种评估指标。
【深度学习】机器学习基础 2024-06-27 机器学习, 深度学习, 人工智能 424人 已看 机器学习就是让机器具备找一个函数的能力带有未知的参数的函数称为模型通常一个模型的修改,往往来自于对这个问题的理解,即。
机器学习Day7 2024-06-29 机器学习, 人工智能 396人 已看 支持向量机(SVM)是一种模型,它的目的是寻找一个超平面(线性、非线性)来对样本进行分割,分割的原则是间隔最大化,最终转化为一个凸二次规划问题来求解。线性支持向量机:寻找一个线性特征空间来对样本进行分割,分割的原则是间隔最大化,此时返还能力最强非线性支持向量机:当原始样本空间不是线性可分的情况,可将样本从原始空间映射到一个更高维的特征空间,使得样本在这个特征空间内线性可分非线性支持向量机可能会用到核函数核函数:将原始空间中的向量作为输入向量,并返回特征空间(转换后的数据空间,可能是高维)中向量的。
[数据集][目标检测]猪只状态吃喝睡站检测数据集VOC+YOLO格式530张4类别 2024-06-29 yolo, 机器学习, 目标检测, 深度学习, 人工智能 414人 已看 数据集格式:Pascal VOC格式+YOLO格式(不包含分割路径的txt文件,仅仅包含jpg图片以及对应的VOC格式xml文件和yolo格式txt文件)特别声明:本数据集不对训练的模型或者权重文件精度作任何保证,数据集只提供准确且合理标注。标注类别名称:["drink","eat","sleep","stand up"]图片数量(jpg文件个数):530。标注数量(xml文件个数):530。标注数量(txt文件个数):530。使用标注工具:labelImg。标注规则:对类别进行画矩形框。
昇思25天学习打卡营第6天|MindSpore-ResNet50迁移学习 2024-06-30 学习, 机器学习, 人工智能, 迁移学习 394人 已看 基于MindSpore-ResNet50模型进行迁移学习,实现狼狗与狗的分类预测。熟悉迁移学习方式,参数冻结微调,预训练模型使用
计算机公共课面试常见问题:线性代数篇 2024-06-28 面试, 机器学习, 线性代数, 人工智能 418人 已看 另一方面,我们也可以先通过一个矩阵 P,把向量 x 换到基 (i', j') 下来表示,这时在新的基下,用来表示上面同一个空间变换的是另一个矩阵 B,它同样也是把向量从x 变换到了 x',只不过是在另一个坐标系下完成的。其中 U 是 m 阶的正交矩阵,V 是 n 阶的正交矩阵,而 Σ 是一个 m × n 的对角矩阵,它对角线上的元素就是奇异值,并且是按照从大到小的顺序排列的。矩阵分解是将一个复杂的矩阵拆分成多个较简单矩阵的过程,这些较简单的矩阵通常具有一些特殊的性质,使得它们更容易分析和处理。
全面了解机器学习 2024-07-02 机器学习, 人工智能 365人 已看 在当今的 科技时代,大量结构化 和 非结构化数据是我们的 丰富资源。机器学习在 20世纪 下半叶演变为 人工智能(Al)的 一个分支,它 通过 自学习算法 从数据中 获得知识来 进行预测。机器学习并不需要 事先对 大量数据进行 人工分析,然后 提取规则 并建立模型,而是 提供了一种更为 有效的方法 来捕获 数据中的 知识,逐步提高 预测模型的性能,以 完成数据驱动的决策。
LLM大模型工程师面试经验宝典--进阶版2(2024.7月最新) 2024-07-02 python, 机器学习, 深度学习, 人工智能, 开发语言 393人 已看 监督学习中主动学习的两个基本原则是寻找多样性的数据,模型不确定性的数据,在寻找 的过程中,我们使用了一些小技巧,比如聚类去重,对抗半监督过滤,自建reward二分类等方 法。这几个小技巧,学术上没有什么高深莫测的东西,都是实践中总结出来的好用的方法。
【Python实战因果推断】10_元学习器5 2024-07-01 算法, python, 机器学习, 人工智能, 开发语言 387人 已看 这种损失也被称为 R 损失,因为它是 R 学习器最小化的损失。那么,如何最小化这个损失函数呢?其实有多种方法,但在这里你会看到最简单的一种。我非常喜欢这个学习器的一点是,它可以直接输出 CATE 估计值。这简直棒极了,因为现在你可以称其为因果损失函数了。在这个例子中,Double/Debiased-ML 的性能与 Slearner 非常相似。因此,为了更好地了解 Double-ML 的真正威力,让我们来看一个更能说明问题的例子。最小化前面的损失相当于最小化括号内的内容,但每个项的权重都是。
机器学习——强化学习状态值函数V和动作值函数Q的个人思考 2024-07-01 机器学习, 人工智能 345人 已看 最近在回顾《西瓜书》的理论知识,回顾到最后一章——“强化学习”时对于值函数部分有些懵了,所以重新在网上查了一下,发现之前理解的,包括网上的大多数对于值函数的描述都过于学术化、公式化,不太能直观的理解值函数以及值函数的推导,我琢磨了一下,所以这篇文章想通过流程图的形式跟大家分享一下我个人对值函数的思考,如果有误,请见谅。
【机器学习】ChatTTS:开源文本转语音(text-to-speech)大模型天花板 2024-06-25 机器学习, 人工智能, 开源 369人 已看 本文首先以VITS为例,对TTS基本原理进行简要讲解,让大家对TTS模型有基本的认知,其次对ChatTTS模型进行step by step实战教学,个人感觉4万小时语音数据开源版本还是被阉割的很严重,可能担心合规问题吧。其次就是没有特定的角色与种子值对应关系,需要人工去归类,期待更多相关的工作诞生。
机器学习算法(三):支持向量机(SVM)的sklearn调用 2024-06-26 支持向量机, 算法, 机器学习, 人工智能, sklearn 382人 已看 本节只会介绍SVM的一些sklearn的高级API调用接口,具体的理论推导这个模型的推导还是很复杂的,这里就不给出具体的理论了。具体理论还请读者自己想办法查阅资料吧。本来是有打算将理论也在这里附上,但很显然这个模型并不像线性回归和逻辑回归那样简单的几个公式就能够说明的,如果需要在这里讲述明白,需要大量的文字叙述,那么读者还不如去找一本详细介绍该模型的书看。最后面的sklearn网格搜索最优参数的技术很有用,要记得用哟,这个技术是通用适合sklearn里面各种模型的。
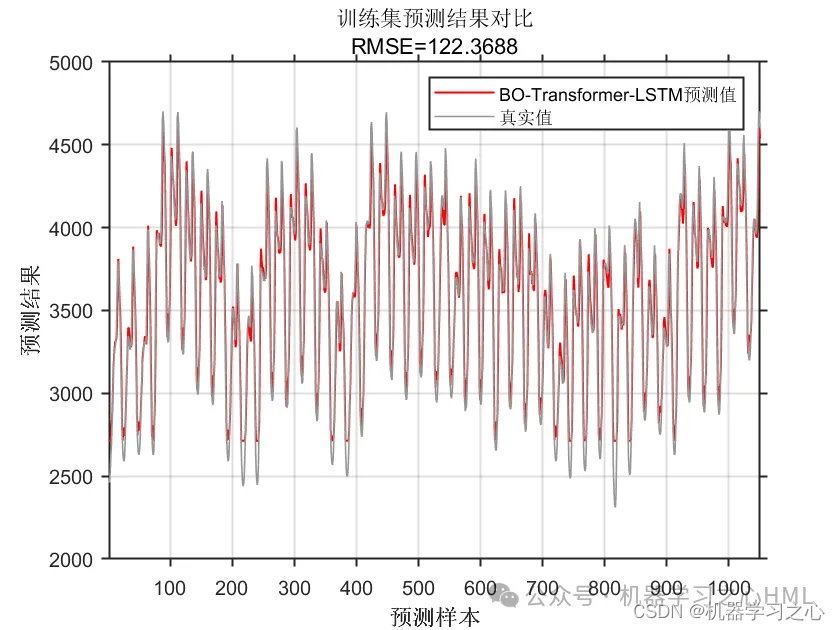
SCI一区级 | Matlab实现BO-Transformer-LSTM多变量时间序列预测 2024-06-23 matlab, lstm, 机器学习, 深度学习, 人工智能 384人 已看 SCI一区级 | Matlab实现BO-Transformer-LSTM多变量时间序列预测
第六章:必要的 Pytorch 知识 2024-06-29 python, 机器学习, 深度学习, pytorch, 人工智能 369人 已看 在上一章中,我们介绍了Model类和Tokenizers类,尤其是如何运用分词器对文本进行预处理。Transformers 库建立在 Pytorch 框架之上(Tensorflow 的版本功能并不完善),虽然官方宣称使用 Transformers 库并不需要掌握 Pytorch 知识,但是实际上我们还是需要通过 Pytorch 的DataLoader类来加载数据、使用 Pytorch 的优化器对模型参数进行调整等等。
Meet AI4S 直播预告丨房价分析新思路:神经网络直击复杂地理环境中的空间异质性 2024-06-28 机器学习, 深度学习, 人工智能, 神经网络 349人 已看 为刻画地理要素间回归关系在不同空间位置体现出的空间非平稳性,地理加权回归 (GWR) 等空间回归模型根据地理学第一定律,将空间上更邻近的样本赋予更高的权重来建立局部的回归关系。近年来,我国各城市之间的房价差异化愈发凸显,甚至是在同一个城市的同一管辖区内,不同区域的房价也会因社区环境、学区、配套商业等因素的不同而千差万别,我们通过一个简单的神经网络模型,在保留回归结果的空间可解释性的同时,优化了空间邻近性的表达,从而获得了更高的建模精度。捕捉房价的空间特异性对于其变化趋势的预测至关重要。
每天一个数据分析题(三百八十二)- 聚类 2024-06-21 聚类, 数据分析, 机器学习, 人工智能, 数据挖掘 321人 已看 内容涵盖Python,SQL,统计学,数据分析理论,深度学习,可视化,机器学习,Spark八个方向的专项练习题库,数据分析从业者刷题必备神器!如果不考虑外部信息,聚类结构的优良性度量应当采用。D. 离散系数。A. 中位数。B. 均方差。C. 平均数。