目录
1.容器
1.列表
基本语法:
# 字面量
[元素1, 元素2, 元素3, 元素4, ...]
# 定义变量
变量名称 = [元素1, 元素2, 元素3, 元素4, ...]
# 定义空列表
变量名称 = [ ]
变量名称 = list( )
列表可以一次存储多个数据,且可以为不同的数据类型,支持嵌套
列表的下标索引:
- 从前向后的方向,编号从0开始:0 1 2 3 4...
- 从后向前的方向,编号从-1开始:-1 -2 -3 -4...
列表的查询功能(方法)
- 查找某元素的下标
功能:查找指定元素在列表的下标,如果找不到,报错ValueError
语法:列表.index(元素)
index就是列表对象(变量)内置的方法(函数)- 修改特定位置(索引)的元素值:
语法:列表[下标] = 值- 插入元素
语法:列表.insert(下标, 元素),在指定的下标位置,插入指定的元素- 追加元素
方式1:列表.append(元素),将指定元素,追加到列表的尾部
方式2:列表.extend(其他数据容器),将其他数据容器的内容取出,依次追加到列表尾部
list1 = [1, 2, 3]
list2 = [4, 5, 6]
list1.extend(list2)
print(list1) # [1,2,3,4,5,6]- 删除元素
语法1:del列表[下标]
语法2:列表.pop(下标)- 删除某元素在列表中的第一个匹配项
语法:列表.remove(元素)- 清空列表内容
语法:列表.clear()- 统计某元素在列表内的数量
语法:列表.count(元素)- 统计列表内,有多少元素
语法:len(列表)
2.元组
元组同列表一样,都是可以封装多个、不同类型的元素在内,但最大的不同点在于:元组一旦定义完成,就不可修改
元组定义
# 定义元组字面量
(元素, 元素, ......, 元素)
# 定义元组变量
变量名称 = (元素, 元素, ......, 元素)
# 定义空元组
变量名称 = () # 方式1
变量名称 = tuple() # 方式2
注意:元组只有一个数据,这个数据后面要添加逗号,否则不是元组类型
t2 = ('Hello',)
增加、删除、修改操作不成功,但是如果元组里面嵌套了list,这个list里面是可以修改的。
3.字符串
同元组一样,字符串也是不可修改的容器
- 字符串的替换
语法:字符串.replace(字符串1,字符串2)
功能:将字符串内的全部:字符串1替换为字符串2
注意:不是修改字符串本身,而是得到了一个新的字符串- 字符串的分割
语法:字符串.split(分隔字符串)
功能:按照指定的分隔符字符串,将字符串划分为多个字符串,并存入列表对象中
注意:字符串本身不变,而是得到了一个列表对象- 字符串的规整操作(去前后空格)
语法:字符串.strip()- 字符串的规整操作(去前后指定字符串)
语法:字符串.strip(字符串)
注意,传入的是"12",其实就是:"1"和"2"都会移除,是按照单个字符- count()
- len()
- index()
3.序列
序列是指:内容连续、有序,可使用下标索引的一类数据容器
列表、元组、字符串,均可以视为序列
- 切片:从一个序列中,取出一个子序列
语法:序列[起始下标:结束下标:步长]
表示从序列中,从指定位置开始,依次取出元素,到指定位置结束,得到一个新序列
• 起始下标表示从何处开始,可以留空,留空视作从头开始
• 结束下标(不含)表示从何处结束,可以留空,留空视作取到结尾
• 步长表示,依次取元素的间隔 留空视作1
• 步长为1表示,一个个去元素
• 步长为2表示,每次跳过1个元素取
• 步长N表示,每次跳过N-1个元素取
• 步长为负数表示,反向取
4.集合
基本语法
# 定义集合字面量
{元素, 元素, ......, 元素}
# 定义集合变量
变量名称 = {元素, 元素, ......, 元素}
# 定义空集合
变量名称 = set()
和列表、元组、字符串等定义基本相同
- 列表使用:[]
- 元组使用:()
- 字符串使用:""
- 集合使用:{}
首先因为集合是无序的,所以集合不支持:下标索引访问,但是集合和列表一样,是允许修改的。
- 添加新元素
语法:集合.add(元素) 将指定元素,添加到集合内
结果:集合本身被修改,添加了新元素- 从集合中随机取出元素
语法:集合.pop()
结果:会得到一个元素的结果。同时集合本身被修改,元素被移除- 清空集合
语法:列表.clear()
结果:集合本身被清空- 取出2个集合的差集
语法:集合1.difference(集合2) 功能:取出集合1和集合2的差集(集合1有而集合2没有)
结果:得到一个新集合,集合1和集合2不变- 消除2个集合的差集
语法:集合1.difference_update(集合2)
功能:对比集合1和集合2,在集合1内,删除和集合2相同的元素
结果:集合1被修改,集合2不变- 2个集合合并
语法:集合1.union(集合2)
功能:将集合1和集合2组合成新集合
结果:得到新集合,集合1和集合2不变- len()
5.字典
字典的定义,同样使用{},不过存储的元素是一个个的:键值对
# 定义字典字面量
{key: value, key: value, ..., key: value}# 定义字典变量
my_dict = {key: value, key: value, ..., key: value}
# 定义空字典
my_dict = {}
my_dict = dict()
不允许重复,新的会把老的去掉。同集合一样,不可以使用下标索引,通过key来取值,可嵌套
- 新增元素
语法:字典[key] = value
结果:字典被修改,新增了元素- 更新元素
语法:字典[key] = value
结果:字典被修改,元素被更新
注意:字典key不可以重复,所以对已存在的key执行上述操作,就是更新value值- 删除元素
语法:字典.pop(key)
结果:获得指定的key的value,同时字典被修改,指定key的数据被删除- 清空字典
语法:字典.clear()
结果:字典被修改,元素被清空- 获取全部的key
语法:字典.keys()
结果:得到字典中全部的key- len()
2.数据容器通用操作
• max最大元素
max(数据容器)
• min最小元素
min(数据容器)
• 容器的通用转换功能
除了下标索引这个共性外,还可以通用类型转换
- list(容器):将给定容器转换为列表
- str(容器):将给定容器转换为字符串
- tuple(容器):将给定容器转换为元组
- set(容器):将给定容器转换为集合 # 抛弃value保留key
• 通用排序功能
sorted(容器,[reverse=True])
[reverse=True]表降序
3.字符串大小比较
基于ASCII码的码值大小
4.函数中多个返回值
如果一个函数要有多个返回值
按照返回值的顺序,写对应顺序的多个变量接受即可,变量之间用逗号隔开,支持不同类型的数据return
5.函数参数多种传递方式
1.位置参数
调用函数时根据函数定义的参数位置来传递参数
注意:传递的参数和定义的参数的顺序及个数必须一致2.关键字参数
函数调用时通过 “键=值” 形式传递参数
注意:函数调用时,如果有位置参数时,位置参数必须在关键字参数的前面,但关键字参数之间不存在先后顺序3.缺省参数
也叫默认参数,在函数定义的时候设定的默认值,写在最后面
作用:当调用函数时没有传递参数,就会默认使用缺省参数对应的值4.不定长参数
不定长参数也叫可变参数,用于不确定调用的是时候会传递多少个参数(不传参也可以)的场景
作用:当调用函数不确定参数个数时,可以使用不定长参数不定长参数的类型:
①位置传递 位置不定长 *号
def user_info(*args)
user_info(1, 2, 3, '小明', '男孩')
注意:传进的所有参数都会被args变量收集,它会根据传进参数的位置合并为一个元组(tuple),args是元组类型
②关键字传递 关键字不定长 **号
def user_info(**kwargs)
user_info(name='小王', age=11, gender='男孩')
注意:以字典的形式接受
6.匿名函数
1.函数作为参数传递
将函数传入作用在于:是一种计算逻辑的春娣,而非数据的传递
2.lambda匿名函数
函数的定义中
- def关键字,可以带有名称的函数
- lambda关键字,可以定义匿名函数(无名称)
有名称的函数,可以基于名称重复使用,无名称的函数,只可临时使用一次
匿名函数定义语法
lambda 传入参数: 函数体(一行代码)
- lambda是关键字,表示定义匿名函数
- 传入参数表示匿名函数的形式参数,如:x, y表示接受2个形式参数
- 函数体,就是函数的执行逻辑,要注意:只能写一行,无法写多行代码
7.文件的操作
1.文件的读取
open打开函数
open(name, mode, encoding)
name:是要打开的目标文件名的字符串(可以包含文件所在的具体路径)
mode:设置打开文件的模式(访问模式):只读、写入、追加等。
encoding:编码格式
mode:
- r:以只读方式打开文件。文件的指针将会放在文件的开头。这是默认模式
- w:打开文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,原有内容会被 删除。如果该文件不存在,创建新文件。
- a:打开一个文件用于追加,如果该文件已经存在,新的内容会被写入到已有内容之后。如果 该文件不存在,创建新文件进行写入
嘿咻 DuDuDu
read()方法
文件对象.read(num)
num表示要从文件中读取的数据长度(单位是字节),如果没有传入num,那么就表示读取文件中所有的数据
如果调用了多个read,下个read会在上个read结尾接着开始读
readlines()方法:读取文件的全部行,封装到列表中
readline()方法:一次读取一行内容
for循环读取文件行:
for line in open("python.txt", "r"):
print(line)
# 每一个line临时变量,就记录了文件的一行数据
close()关闭文件对象
文件.close()
with open 语法
with open("python.txt", "r") as f
f.readlines()
# 通过在with open的语句块中对文件进行操作
# 可以在操作完成后自动关闭close文件,避免遗忘掉close方法
2.文件的写操作
# 1.打开文件
f = open('python.txt', 'w', encoding="UTF-8)
# 2. 文件写入
f.write('hello world')
# 3.内容刷新
f.flush()
# 4.close()方法 内置了flush的功能
f.close()
注意:
- 直接调用write,内容并未真正写入文件,而是会积攒在程序的内存中,称之位缓冲区
- 当调用flush的时候,内容会真正写入文件
- 这样做是避免频繁的操作硬盘,倒置效率下降(攒一堆,一次性写磁盘)
- 原有文件内容会被全部清空
3.文件的追加
f = open('python.txt', 'a', encoding="UTF-8)
注意:
- 追加写入文件使用open函数的”a"模式进行写入
- 追加写入的方法有(和w模式一致)
- write(),写入内容
- flush(),刷新内容到硬盘
- a模式,文件不存在,会创建新文件
- a模式,文件存在,会在原有内容后面继续写入
- 可以使用 “\n” 来写出换行符
8.异常的捕获
1.捕获常规异常
try:
可能发生错误的代码
except:
如果出现异常执行的代码
2.捕获指定异常
try:
print(name)
except NameError as e:
print('name变量名称未定义错误')
注意事项:
① 如果尝试执行的代码的异常类型和要捕获的异常类型不一致,则无法捕获异常
② 一般try下方只放一行尝试执行的代码
3.捕获多个异常
当捕获多个异常时,可以要把捕获的异常类型的名字,放到except后,并使用元组的方式进行书写
try:
print(1/0)
except (NameError, ZeroDivsionError)
print('ZerioDivision错误')
4.捕获所有异常
try:
except Exception as e:
print("出现异常了")
5.异常else
else表示如果没有异常要执行的代码
6.异常的finally
finally表示的是无论是否异常都要执行的代码,例如关闭文件
try:
f = open('test.txt', 'r')
except Exception as e:
f = open('test.txt', 'w')
else:
print("没有异常,真开心")
finally:
f.close()
9.异常的传递
异常是具有传递性的
tips:当所有函数都没有捕获异常的时候,程序就会报错
10.模块
1.模块的导入方式
[from 模块名] import [模块 | 类 | 变量 | 函数 | *] [as 别名]
2.自定义模块
- __main__变量
if__main__ == "__main__"表示,只有当程序时直接执行的才会进入
if内部,如果时被导入的,则无法进入 - __all__变量
如果一个模块文件中有这个变量,当使用`from xxx import *`导入时,只能导入这个列表中的元素
11.包
从物理上看,包就是一个文件夹,在该文件夹下包含了一个__init__.py文件(有这个文件才是包,没有不是),该文件夹可用于包含多个模块文件。从逻辑上看,包的本质依然是模块
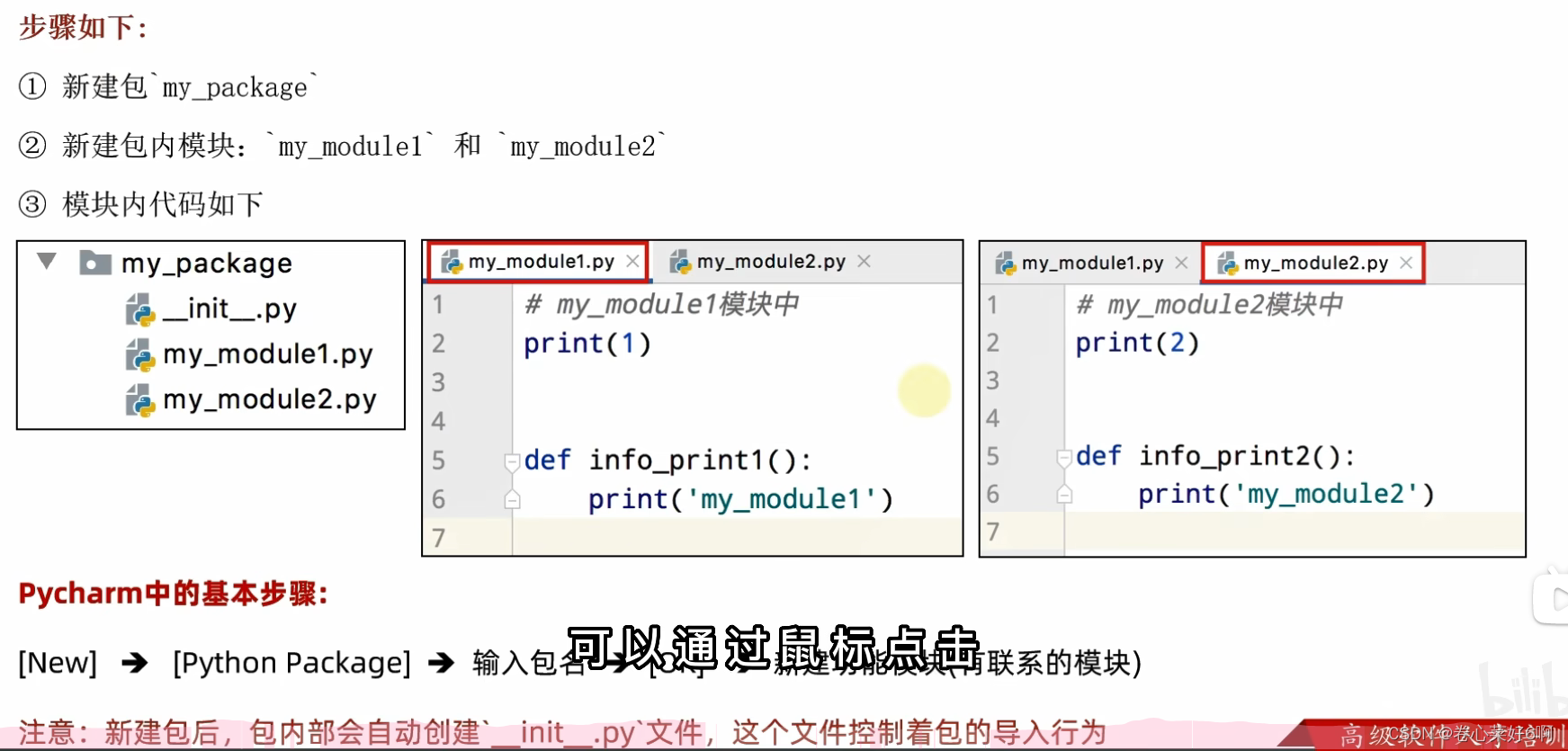
导入包
方法①
import 包名.模块名
包名.模块名.目标
方法②
from 包名 import *
模块名.目标
注意:必须在`__init__.py`文件中添加`__all__ = []`,控制允许导入的模块列表
