一、连接查询
连接查询是SQL语言最强大的功能之一,它可以执行查询时动态的将表连接起来,然后从中查询数据。
1.1、连接两表的方法
在SQL中连接两表可以有两种方法,一种是无连接规则连接,另一种是有连接规则连接。
- 无连接规则连接
无连接规则连接后得到的结果是两个表中的每一行都互相连接,即结果为笛卡尔积(笛卡尔积(Cartesian Product)是数据库和集合论中的一个概念。它是指将两个集合中的每一个元素进行配对,形成一个新的集合。在数据库的上下文中,笛卡尔积是指在 SQL 查询中将两个表的所有可能的行组合在一起,生成所有可能的行对组合)。
| SELECT *(或字段列表) FROM 表名1,表名2; |
FROM子句中的表名1和表名2是要连接的两个表的名称,用逗号(,)将其隔开;如果SELECT子句中使用星号(*),则查询结果中显示两个表的所有字段。
| SELECT * FROM t1,t2; |
运行结果显示了t1表的所有记录与t2表的所有记录进行了连接,即得到了笛卡尔积;但实际上,这并不是用户想要的结果,因为用户需要需要的是正确的连接,而并不是每行都连接起来,所以应该给连接设定连接规则。
多表无连接规则连接和两表无连接规则连接基本相同,只是在FROM子句中需要列出更多的表名,表名之间用逗号隔开,连接得到的结果同样也是笛卡尔积。
- 有连接规则连接
有连接规则连接其实就是在无连接规则的基础上,加上WHERE子句指定连接规则的连接方法。
| SELECT *(或字段列表) FROM 表名1,表名2 WHERE 连接规则; |
- 示例:
| SELECT * FROM t1,t2 WHERE t1.职工号=t2.职工号; |
其中,连接规则是:t1.职工号=t2.职工号
这种使用等于号组成的连接,实际上叫等值连接;只有两表有共同的字段时才可以使用等值连接,例如,t1和t2表有共同的字段—职工号,只有这样才可以使用等值连接的方法连接两表。
在上面的连接规则表达式中,字段名前加上了数据表的名称,并用英文中的句号(.)将其隔开,这是因为两个表中有相同的字段名,如果不加以修饰说明,DBMS将无法辩认是哪个表的字段;所以在多表连接时,如果使用表中相同名称的字段,则应当在其前面加上表名。
Tips:在多表连接时,即使不要求在表独有的字段前加表名,但建议还是加上表名;因为这样会很清楚地表示哪个字段属于哪个表,这将对以后的维护起到很好的作用。
1.2、使用笛卡尔积解决录入难题
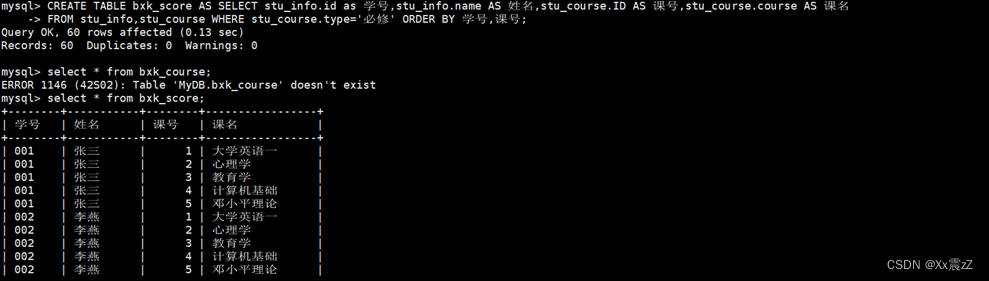
- 示例:使用stu_info表和stu_course表的笛卡尔积,生成一个必修课成绩表(bxk_score)的内容,要求是每个学生都应该选择所有的必修课。
- 如果SQL运行环境为MySQL或Oracle,则其查询语句如下
| CREATE TABLE bxk_score AS SELECT stu_info.id as 学号,stu_info.name AS 姓名,stu_course.ID AS 课号,stu_course.course AS 课名 FROM stu_info,stu_course WHERE stu_course.type='必修' ORDER BY 学号,课号; |
CREATE TABLE bxk_score AS这里的 AS 关键字表示“使用以下 SELECT 语句的结果作为新表的数据来源”。
- 如果SQL 运行环境为SQL Server,则其查询语句如下:
| SELECT stu_info.id as 学号,stu_info.name AS 姓名,stu_course.ID AS 课号,stu_course.course AS 课名 INTO bxk_score FROM stu_info,stu_course WHERE stu_course.type='必修' ORDER BY stu_info.id,stu_course.ID; |
| SELECT s.id AS 学号, s.name AS 姓名, c.ID AS 课号, c.course AS 课名 INTO bxk_score FROM stu_info s, stu_course c WHERE c.type = '必修' ORDER BY s.id, c.ID; |
- 执行顺序
- FROM:首先执行 FROM 子句。这里使用了表别名 s 和 c,表示 stu_info 表和 stu_course 表。
- WHERE:根据 WHERE 子句中的条件筛选出满足条件的行,即 stu_course 表中 type 列值为 '必修' 的行。
- SELECT:选择 stu_info 表中的 id 列并命名为 学号,选择 stu_info 表中的 name 列并命名为 姓名,选择 stu_course 表中的 ID 列并命名为 课号,选择 stu_course 表中的 course 列并命名为 课名。
- ORDER BY:对结果集按照 学号 和 课号 进行排序。
- INTO(CREATE TABLE AS SELECT):最后,将查询结果存储到名为 bxk_score 的新表中。
本例使用了多数人觉得没用的求笛卡尔积的方法很好地解决了一个录入上的难题。
1.3、使用两表连接查询数据
数据库操作中,比起使用笛卡尔积,使用有连接规则的连接查询会更频繁一些。
示例:查询名叫“张三”的学生的所有课程的平时成绩和考试成绩
分析:stu_info表中有学生姓名,但没有成绩,而存储成绩的score表中有成绩,但没有姓名,不过两个表都有一个共享字段—学号,所以可以将这两个表连接起来进行查询:
| SELECT s.id as 学号,s.name AS 姓名,c.c_id AS 课号,c.result2 AS 平时成绩,c.result1 AS 考试成绩 FROM stu_info s,score c WHERE s.name='张三' AND s.id=c.s_id ORDER BY c.result1 DESC,c.result2 DESC; |

其中WHERE子句中的条件表达式使用逻辑运算符AND,将查询条件(s.name=’张三’)和连接规则(s.id=c.s_id)整合为一体。
1.4、多表连接查询
示例:查询名叫“张三”的学生的所有课程的平时成绩和考试成绩。
分析:已经知道sut_info和score表可以用共同拥有的学号字段进行连接,接下来的问题是将stu_course表连接到上述两个表上。由于stu_info表和stu_course表没有共同字段所以不能连接,但是score表和stu_course表有共同字段—课号,因此score表和stu_course表可以连接。如此一来,经过score表的搭桥,上述三个表就可以连接了。
| SELECT s.id AS 学号, s.name AS 姓名, u.course AS 课名, c.result2 AS 平时成绩, c.result1 AS 考试成绩 FROM stu_info s INNER JOIN score c ON s.id = c.s_id INNER JOIN stu_course u ON c.c_id = u.ID WHERE s.name = '张三' ORDER BY c.result1 DESC, c.result2 DESC; |
| #使用显式的 INNER JOIN 语法来明确表示只选择匹配的记录 |
 使用INNER JOIN进行多表连接,关键字ON之后是连接表的规则;通过 INNER JOIN,查询结果只包括在所有相关表中都有匹配记录的行。
使用INNER JOIN进行多表连接,关键字ON之后是连接表的规则;通过 INNER JOIN,查询结果只包括在所有相关表中都有匹配记录的行。
当使用 INNER JOIN 连接两个表时,SQL 引擎会:
- 逐行扫描每个表。
- 比较两个表中符合 ON 子句中条件的记录。
- 只返回那些在两个表中都符合连接条件的记录。
二、高级连接查询
2.1、自连接查询
表自身与自进行连接。
- 示例:从stu_info表中,查询“张三”所在院系的所有学生的信息。
分析:首先查询“张三”所在的院系是哪个院系,其次才能查询属于该院系的所有学生的信息。
- 查询“张三”所在的院系名称
| SELECT institute AS 所属院系 FROM stu_info WHERE name = '张三'; |
- 根据查询,“张三”在“中文系”,下面查询中文系
| SELECT * FROM stu_info WHERE institute = '中文系'; |
虽然通过两次查询得到了正确的结果,但是这对于提高查询效率是不利的;因为在DBMS中,通常执行两条SELECT语句的时间,总会比执行一条SELECT语句的时间要长;遇到类似本例的查询任务,应当首选自连接查询,因为自连接查询可以用一条SELECT语句完成本例的查询任务。
| SELECT st1.* FROM stu_info AS st1,stu_info AS st2 WHERE st1.institute = st2.institute AND st2.name = '张三'; |
 其中,FROM子句后要连接的两个表都是stu_info表,只是给stu_info表分别取了两个不同的别名而已;这是为了让DBMS能够区别开查询语句中引用的字段是属于第一个stu_info表还是第二个stu_info表。
其中,FROM子句后要连接的两个表都是stu_info表,只是给stu_info表分别取了两个不同的别名而已;这是为了让DBMS能够区别开查询语句中引用的字段是属于第一个stu_info表还是第二个stu_info表。
“st1.*”:显示st1表的所有字段,如果将其改为“*”,则会显示st1和st2表的所有字段。
使用自连接查询时应特别注意,WHERE子句中表的连接规则,本例中连接规则是st1.institute=st2.institute,如果改为其他字段连接则会出错。例如,改为st1.id=st2.id,则运行结果中只有“张三”的一条记录。
-
 示例:从stu_info表中,查询与“吴用”来源地相同的所有学生的学号、姓名和所属院系。
示例:从stu_info表中,查询与“吴用”来源地相同的所有学生的学号、姓名和所属院系。
| SELECT st1.id 学号,st1.name 姓名,st1.institute 所属院系 FROM stu_info AS st1,stu_info AS st2 WHERE st2.name = '吴用' AND st1.origin=st2.origin; |
 2.2、内连接查询
2.2、内连接查询
有连接规则的连接都属于内连接,内连接包括等值连接、自然连接和不等值连接三种。内连接最大的特点是只返回两个表中互相匹配的记录,而那些不能匹配的记录就被自动去除了。
- 等值连接
连接规则由等于号(=)组合而成,如st1.institute=st2.institute,并且列出两个表中所有字段的连接,即SELECT子句中使用(*)通配符的连接就属于等值连接。
- 自然连接
在等值连接的基础上稍加改动即可得到自然连接,等值连接将两个表中的所有字段全部列出,而自然连接则不将相同的字段显示两次,即在SELECT子句中列出需要显示的字段列表。
- 不等值连接
不等值连接的连接规则由等于号以外的运算符组成,如由>、>=、<、<=、<>或BETWEEN等。
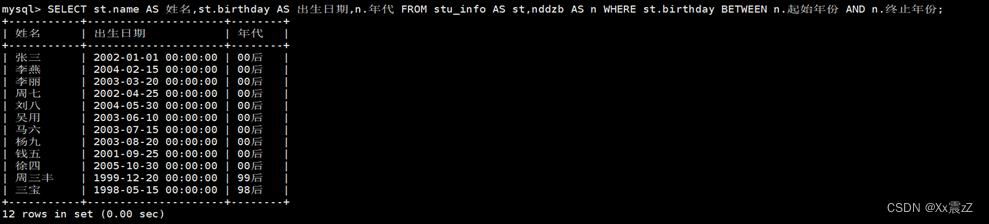
- 示例1:从stu_info表中,查询所有学生的出生年代
分析:需要将stu_info表和nddzb连接起来,但是这两个表没有共同字段,所以没办法使用等值连接,而根据题意可以使用不等值连接。连接规则是如果stu_info表的出生日期在nddzb的起始年份和终止年份之间就可以连接。

| SELECT st.name AS 姓名,st.birthday AS 出生日期,n.年代 FROM stu_info AS st,nddzb AS n WHERE st.birthday BETWEEN n.起始年份 AND n.终止年份; |
 2.3、外连接查询
2.3、外连接查询
在多表连接查询时,有时希望表的所有记录都被包含进去,即使没有匹配的记录也包含在查询结果集内,这时采用另一种连接查询方法—外连接查询;外连接有左外连接、右外连接和全外连接三种。
- 左外连接
这种连接的规则是将左外连接符号(LEFT OUTER JOIN或LEFT JOIN)左边的表的所有记录都包含到结果集中,而只将右边表中有匹配的记录包含进结果集。
| SELECT * FROM stu_info LEFT OUTER JOIN user_info ON stu_info.name=user_info.name; |
 左外连接时左边表的所有记录都会包含到查询结果中,那些没有匹配的左边表的记录会与全部是NULL值的记录连接。
左外连接时左边表的所有记录都会包含到查询结果中,那些没有匹配的左边表的记录会与全部是NULL值的记录连接。
- 右外连接
这种连接的规则是将右外连接符号(RIGHT OUTER JOIN或RIGHT JOIN)右边表的所有记录都包含到结果集中,而只将左边表中有匹配的记录才包含进结果集。
| SELECT * FROM stu_info RIGHT OUTER JOIN user_info ON stu_info.name=user_info.name; |
-
 全外连接
全外连接
这种连接的规则是将两个表的所有记录都包含到结果集中,这种连接只有一种FULL OUTER JOIN连接符。
| SELECT * FROM stu_info FULL OUTER JOIN user_info ON stu_info.name = user_info.name; |
在 MySQL 中,FULL OUTER JOIN 语法实际上是不支持的。然而,可以通过使用 LEFT JOIN 和 RIGHT JOIN 的组合来实现 FULL OUTER JOIN 的效果。
| SELECT stu_info.*, user_info.* FROM stu_info LEFT JOIN user_info ON stu_info.name = user_info.name UNION SELECT stu_info.*, user_info.* FROM stu_info RIGHT JOIN user_info ON stu_info.name = user_info.name; |
这个查询首先执行一个 LEFT JOIN,然后再执行一个 RIGHT JOIN,最后使用 UNION 操作符将两个结果集合并,从而实现 FULL OUTER JOIN 的效果。如果希望结果集中包含重复的行(即,左连接和右连接中都匹配到的行),则可以使用 UNION ALL 而不是 UNION。
2.4、交叉连接查询
交叉连接查询其实就是无连接规则的连接。
用逗号隔开表名或用CROSS JOIN关键字连接表名
| SELECT stu_info.*, user_info.* FROM stu_info,user_info; |
| SELECT stu_info.*, user_info.* FROM stu_info CROSS JOIN user_info; |
交叉连接的返回结果是一个笛卡尔积,即两个表中的每一行都互相连接,例如,一个表有10行记录,另一表有20行记录记录时,对其进行交叉连接后得到的是200行记录的查询结果。因此,当两个表很大时,要谨慎对其进行交叉连接,这样会得到一个庞大的结果集。
- 对a、b两个表进行交叉连接操作,并将结果保存到kcb表。
| #运行环境为MySQL或Oracle CREATE TABLE kcb AS SELECT * FROM a CROSS JOIN b; #运行环境为SQL Server SELECT * INTO kcb FROM a CROSS JOIN b; |
AS 关键字的主要作用是为列或表指定别名,增强 SQL 语句的可读性和简洁性。它还用于 CREATE TABLE ... AS SELECT ... 语法中,将查询结果用于创建和填充新表。
2.5、连接查询中使用聚合函数
聚合函数不仅可以用于单表查询中,还可以用在多表连接查询中。
示例:统计没有考过任何考试的学生人数
分析:stu_info表中存放的是所有学生的记录,score表中存放的是考过试的学生的成绩。要完成本例的要求,则应当使用stu_info表左外连接score表,这样stu_info表中没有考过任何考试的学生就与全部是NULL值的记录连接,而后统计score表部分“学号”为NULL值的记录个数就能得到没有考过任何考试的学生人数。
| SELECT st.id AS 学号,st.name AS 姓名,s.s_id AS 学号,s.c_id AS 课号,s.result1 AS 考试成绩 FROM stu_info AS st LEFT OUTER JOIN score AS s ON st.id=s.s_id ORDER BY s.s_id; |
| SELECT COUNT(*) AS 未考试的学生人数 FROM stu_info AS st LEFT OUTER JOIN score AS s ON st.id=s.s_id WHERE s.s_id IS NULL; |
 LEFT OUTER JOIN 从左表(stu_info)中返回所有的行,即使右表(score)中没有匹配的行。如果右表中没有匹配的行,则结果集中右表的列为 NULL。
LEFT OUTER JOIN 从左表(stu_info)中返回所有的行,即使右表(score)中没有匹配的行。如果右表中没有匹配的行,则结果集中右表的列为 NULL。
ON st.id = s.s_id:这是连接条件,将 stu_info 表的 id 列与 score 表的 s_id 列进行匹配。
由于 WHERE s.s_id IS NULL 条件的存在,COUNT(*) 只会计算那些没有在 score 表中出现的学生。
三、组合查询
SQL中还有一种组合查询,这种查询使用UNION关键字将多个SELECT语句组合起来,将多个SELECT语句的查询结果显示到一个结果集中;组合查询与连接查询不同的是,前者将多个表的查询结果竖着组合,而后者是将查询结果横着连接。
下图为组合查询与连接查询区别示意图:
 3.1、使用组合查询
3.1、使用组合查询
未完待续。。。