软件设计师之一考就过:成绩版
考点40:排序算法(必须记住:插冒归快堆)
1、直接插入排序(这里以从小到大排序为例)
◆要注意的是,前提条件是前i-1个元素是有序的,第i个元素依次从第i-1个元素往前比较,直到找到一个比第i个元素值小的元素,而后插入,插入位置及其后的元素依次向后移动。
◆当给出一队无序的元素时,首先,应该将第1个元素看做是一个有序的队列
而后从第2个元素起,按插入排序规则,依次与前面的元素进行比较,直到找到一个小于他的值,才插入。示例如下图所示:
下图中,59依次向前比较,先和68比较,再和57比较,发现57比他小,才插入。
[外链图片转存中…(img-sfqIGhMd-1719793350145)]
**第一轮:**从第二位置的 6 开始比较,比前面 7 小,交换位置。
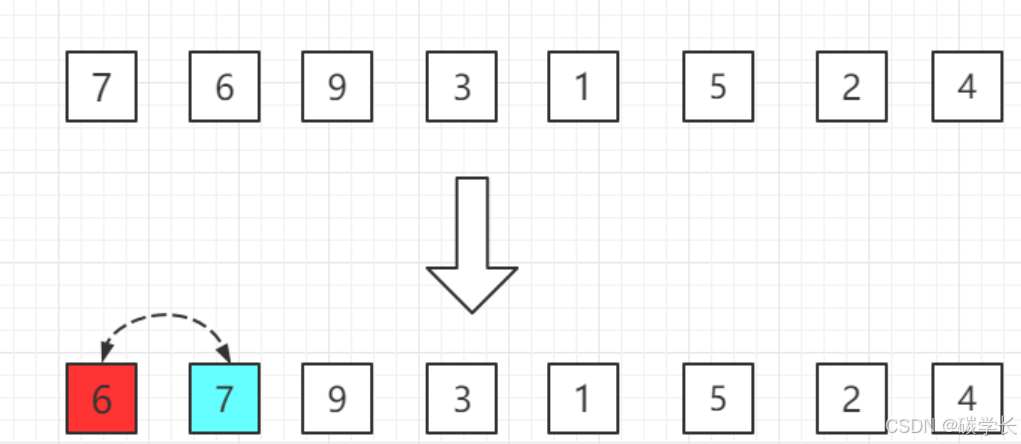
**第二轮:**第三位置的 9 比前一位置的 7 大,无需交换位置。

**第三轮:**第四位置的 3 比前一位置的 9 小交换位置,依次往前比较。
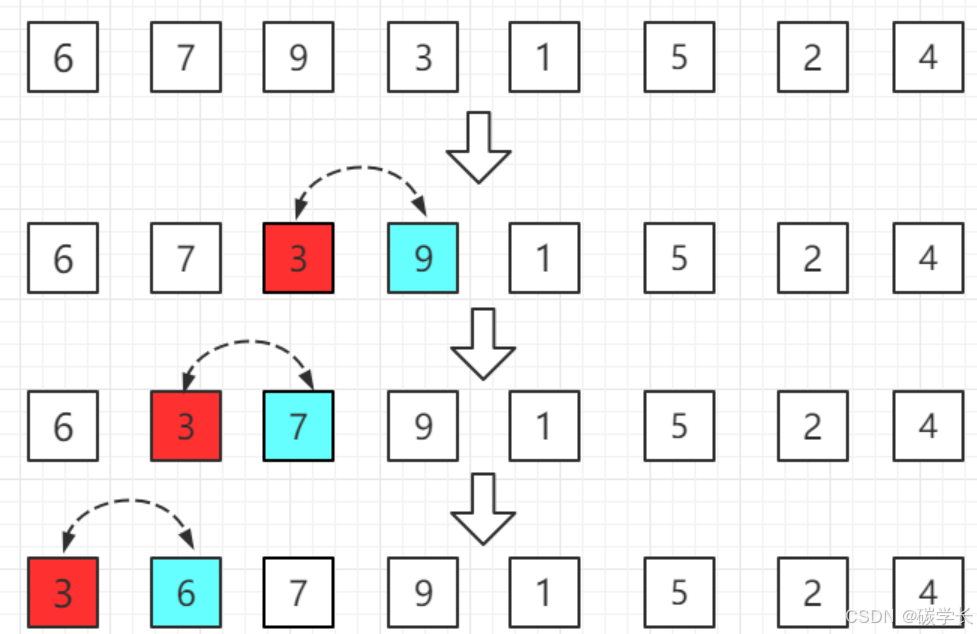
**第四轮:**第五位置的 1 比前一位置的 9 小,交换位置,再依次往前比较。
[外链图片转存中…(img-QsUNxoBg-1719793350146)]
…
就这样依次比较到最后一个元素。
2、冒泡排序
◆n个记录进行冒泡排序的方法是:
首先将**第一个记录的关键字和第二个记录的关键字进行比较,若为逆序,则交换这两个记录的值,**然后比较第二个记录和第三个记录的关键字依此类推,直至第n-1个记录和第n个记录的关键字比较过为止。上述过程称为一趟冒泡排序,其结果是关键字最大的记录被交换到第n个记录的位置上。
然后进行第二趟冒泡排序,对前n-1个记录进行同样的操作,其结果是关键字次大的记录被交换到第n-1个记录的位置上。最多进行n-1趟所有记录有序排列。若在某趟冒泡排序过程没有进行相邻位置的元素交换处理,则可结束排序过程。
◆示例给的是从后往前排序,也是可以的,需要从最后两个元素开始进行比较,将较小的元素交换到前面去,依次进行比较交换。比较是为了交换,交换次数很多。区分冒泡排序和简单选择排序。
冒泡:像水里的泡泡一样,一直网上冒。
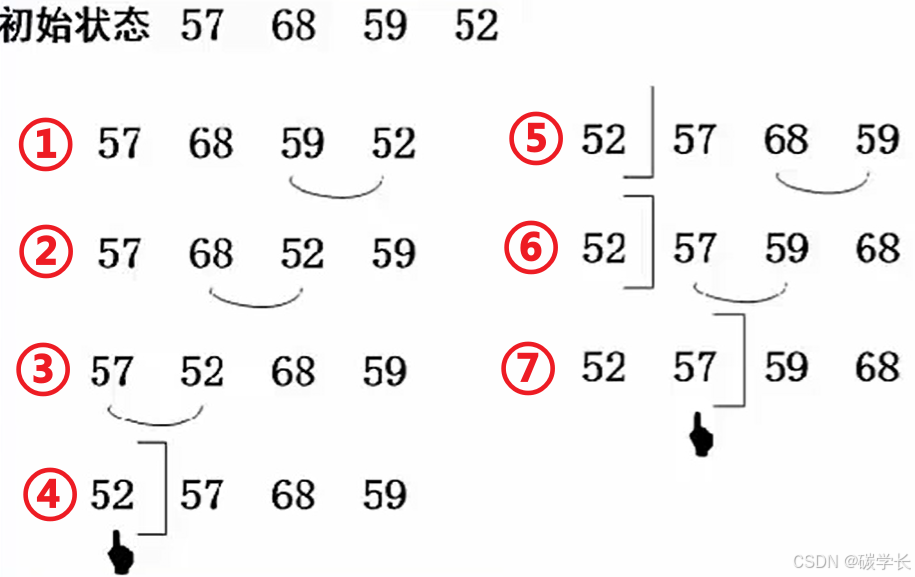
比如上图按照 从小到大排序,得到结果:(这里从后往前排序为例)
第一步:先比较59、52,然后 52 和 59 交换。
第二步:比较 68、52,然后交换 68 和 52。
第三步:比较 57、52,然后交换 57 和 52。
然后类推…
相较于简单选择排序而言,冒泡排序有以下不同:
1、简单选择排序是多次比较,1次交换(比较出最小的和第一个进行交换)
2、冒泡排序是一次比较、一次交换,多次比较,多次交换(相邻两个数字比较、交换)
3、归并排序
◆所谓“归并”,**是将两个或两个以上的有序文件合并成为一个新的有序文件。**归并排序的一种实现方法是把一个有n个记录的无序文件看成是由n 个长度为1的有序子文件组成的文件,然后进行两两归并,得到[n/2]个长度为2或1的有序文件,再两两归并,如此重复,直至最后形成包含n个记录的有序文件为止。这种反复将两个有序文件归并成一个有序文件的排序方法称为两路归并排序。
◆要仔细理解上述过程,一般归并排序都是用来合并多个线性表的,对单列数据,二路归并排序可以对元素进行两两合并,示例如下:
◆对第三次归并,将52与28比较,28小,放入新表头,52再与33比较,33放入新表,52再与72比较,52放入新表,57再与72比较,57放入新表…

1、第一次时,两路归并 则,两个为一组,比如[57、68]一组,[59、52]一组,然后每组内部比较大小,进行排序,于是得到结果:
[57,68],[52,59],[28,72],[33,96] 每组内都按照从小到大排序了。
2、然后会将第一次的结果,还按两路归并,即[57,68],[52,59]为一组,
则为[57,68,52,59],
[28,72],[33,96]为一组,
则为[28,72,33,96]
3、然后对于上面进行组内排序,于是得到[52,57,59,68]、[28,33,72,96]
4、然后将上面两组按 两路归并 合为一组,然后组内排序,得到最终结果。
4、快速排序(分而治之,分治法)
◆快速排序是将n个记录分成两块,再递归,实际分成两块的方法如图所示:设定一个基准为57,设定两个指针high=1,low=n,从low指向的第n个元素开始,与基准值进行比较,若小于基准值,则与基准进行交换low–,此时,转而从high指向的第1个元素开始和基准值进行比较,若大于基准值,则和基准值进行交换,此时,又转而从low一指向的值和基准进行比较,重复上述过程。
◆要注意的是:每次都是和基准值进行比较,因此最终是以基准值为中间,将队列分成两块。只有当和基准值发生了交换,才变换high和low指针的计数,否则会一直low–下去。
◆上图中,最终以57为界,左边都是小于57的元素,右边都是大于57的元素,完成一次快速排序,接着对两块再分别进行递归即可。
[外链图片转存中…(img-OSfoiXJq-1719793350147)]
比如上述数字,
第一次以57为基准,最后得到左侧都小于57,右侧都大于57.这是第一趟快速排序。
第一次比较时,是先比较最后一个元素(从第n个元素开始),此时19小于57,则 low指针执行 low–,然后 19和57交换位置,而 high 指针指向(除原来57的第一个元素,也就是现在除去19的第一个元素68),然后开始比较 68 和 57,68大于57,然后交换 68和57的位置,此时又会比较 low–指向的位置(第n-1),即比较 24 和 57,小于 57,则 low-- 继续,然后交换 57和24的位置,转而又会从前面的 high 指针指向的 59,继续比较…如此重复…(只要发生了交换,就转换指针low和high,即转换方向,进行比较,没有交换就继续当前指针,不转换方向)
所以这里的基准值最好是接近于中位数。一般以待排序的第一个元素为基准值。
然后对左边的数据和右侧的数据进行快速排序,比如左侧以19为基准,右侧以96为基准。
然后不断递归,直到满足从小到大的序列。
5、堆排序
[外链图片转存中…(img-u8vAXXWw-1719793350147)]
左侧称之为小根堆(比如一个完全二叉树,孩子(左右)结点都大于根节点),右侧称之为大根堆(比如一个完全二叉树,孩子结(左右)点都小于根节点)。大根堆用于排成从大到小;小跟堆用于排成从小到大。
[外链图片转存中…(img-qseyr6J9-1719793350147)]
由上图可知,首先将给出的数组按完全二叉树规则建立,而后,找到此完全
二叉树的最后一个非叶子节点(也即最后一颗子树),比较此非叶子节点和其
两个孩子结点的大小,若小,则与其孩子结点中最大的结点进行交换;依据此
规则再去找倒数第二个非叶子节点,这是只有一层的情况,当涉及到多层次时因此,又要进行变换。
第一步,按照序列(55,60,40,10,80,65,15,5,75)按照层次遍历建立一个完全二叉树。(即从上到下、从左到右。)
第二步,此时还不是大根堆,只是建立了一个完全二叉树。所以需要调整满足:左右子结点大于根节点。
**此时需要先找出最后一个非叶子结点。**首先,这里的非叶子节点有55、60、40、10,最后一个非叶子结点就是10。
然后比较左右子节点大小,比非叶子节点大,就调换位置,于是10下去,75上去了。
第三步,找倒数第二个非叶子节点,这里找到 40,比较,然后65上去;
第四步,找倒数第三个非叶子节点,这里找到60,比较,然后80上去。
第五步,找倒数第四个非叶子结点,这里找到55,比较,然后80上去。
此时还没有结束,因为55下去之后,75和60都比55大,此时还需要继续调整、变换,比如 55 下去,75换上去。然后对比是否符合。
然后整体查看树是否满足,不满足的再局部进行调整。
所以整体上来说,堆排序是先进行从小到上的比较、变换;然后再从上到下进行局部调整(防止从小到上比较、变换时,把小的数字换下来,导致左右子结点都比根节点大)。(这里以大根堆为例的)
这里还以大根堆举例:
◆建立初始堆后,开始排序,每次取走堆顶元素(必然是最大的),而后将堆
中最后一个元素移入堆顶,而后按照初始建堆中的方法与其孩子结点比较大小,依次向下判断交换成为一个新的堆,再取走堆顶元素,重复此过程。
◆堆排序适用于在多个元素中找出前几名的方案设计,因为堆排序是选择排序,而且选择出前几名的效率很高。
下图为大根堆的示意图:就是不断的调整堆,使其最终满足大根堆。
[外链图片转存中…(img-IUIAGrZ7-1719793350147)]
6、希尔排序(适合于数据比较多的、大数据)
◆希尔排序又称“缩小增量“排序是对直接插入排序方法的改进。
◆希尔排序的基本思想是:
先将整个待排记录序列分割成若干子序列,然后分别进行直接插入排序,待整个序列中的记录基本有序时,再对全体记录进行一次直接插入排序。
◆具体做法是:先取一个小于n的整数d1 作为第一个增量,把文件的全部记录分成d1个组,将所有距离为d1倍数的记录放在同一个组中,在各组内进行直接插入排序;然后取第二个增量d2(d2<d1),重复上述分组和排序工作,依此类推,直至所取的增量di=1(di<di-1<…<d2<d1),即所有记录放在同一组进行直接插入排序为止。
◆按上述,希尔排序实际是为了解决大数据的排序问题,当待排序的数据很多时,使用直接插入排序效率很低,因此,采取分组的方法,使问题细化,可以提高效率,适用于多数据。

| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | |
|---|---|---|---|---|---|---|---|---|---|---|
| 48 | 37 | 64 | 96 | 75 | 12 | 26 | 48_ | 54 | 03 |
如上有10个数字,编号 1-10,当增量序列为 5、3、1时,也就是编号1的数字(48)和 编号 6的数字(12)(因为增量为5,1 + 5 = 6)为同一个组。(1,6,11…,因为编号总共为10,所以是2个数字为一组)
同理编号2的数字 37 和 编号7的数字 26 为一组。
编号3的数字 64 和 编号 8的数字 48_ 为一组。
编号4的数字 96 和 编号9的数字 54 为一组。
编号 5的数字 75 和 编号 10的数字 03 为一组。
所以分成了 5 组。然后分别对每组进行插入排序。
所以第一组 48 和 12 就调换了个位置,即此时 12 编号为 1,48编号为6.
同理,48_ 的编号变为了 3,64的编号变为了8
54的编号变为了4,96的编号变为了9
03的编号变为了5,75的编号变味了10,于是得到,第一趟排序结果:
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | |
|---|---|---|---|---|---|---|---|---|---|---|
| 12 | 26 | 48_ | 54 | 03 | 48 | 37 | 64 | 96 | 75 |
然后按照 增量序列 5、3、1 的 3 进行分组:
即:编号1的12和编号4的54、编号7的37、编号10的75为一组(1、4、7、10)
编号2的26和编号5的03、编号8的64为一组(2、5、8)
(3、6、9)编号的为一组
然后每组进行插入排序,排序后位置调换,得到第二组排序结果:
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | |
|---|---|---|---|---|---|---|---|---|---|---|
| 12 | 03 | 48_ | 37 | 26 | 48 | 54 | 64 | 96 | 75 |
然后按照增量序列为 5、3、1 的 1 进行分组:
即 编号(1,2,3,4,5,6,7,8,9,10) 所有数字为一组。进行插入排序,从而得到最终结果。
不管前面的增量是多少,最后一轮的排序的增量一定为1.
7、简单选择排序
◆n个记录进行简单选择排序的基本方法是:通过n-i(1≤i≤n)次关键字之间的比
较,从n-i+1个记录中选出关键字最小的记录,并和第i个记录进行交换,当i等于n 时所有记录有序排列。
◆按上述,本质就是每次选择出最小的元素进行交换,**主要是选择比较过程(n-i次比较),而交换过程只有一次。**示例如下

比如上述4个数字里先找出最小的 52,然后这个最小值与4个数字里的第1个数字的位置进行交换。
然后,在剩下的数字 68,59, 57三个数字中找到最小的 57,然后与这三个数字中的第1个数字 68 交换位置。
然后再比较剩余的 59,68找出最小的,判断是否交换位置。
最后就得到了最后的排序结果。
8、基数排序(了解即可)
基数排序是基于多个关键字来进行多轮排序的,本质也是将问题细分,如图例子,分别按个位、十位、百位的大小作为关键字进行了排序,最终得出结果:
[外链图片转存中…(img-SkRbAKdS-1719793350148)]
9、内部排序算法总结
[外链图片转存中…(img-PBWMEm4d-1719793350148)]
所以答案为 A。

真题2:对n个数排序,最坏情况下时间复杂度最低的算法是(C)排序算法。
A、插入 B、冒泡 C、归并 D、快速
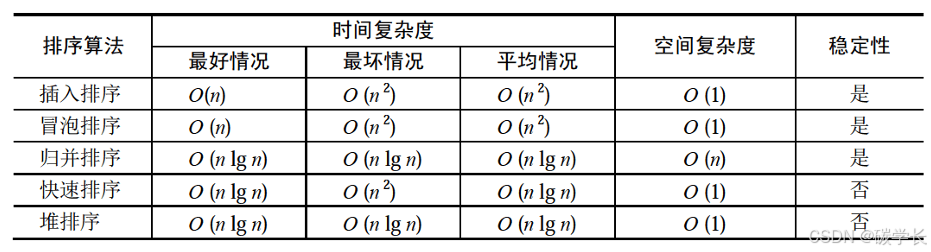
插帽龟快堆
真题3:下列排序算法中,占用辅助存储空间最多的是(A)
A、归并排序 B、快速排序、C、堆排序 D、冒泡排序
[外链图片转存中…(img-2cQPxwj8-1719793350148)]
[外链图片转存中…(img-qBo3fjYw-1719793350149)]

背诵口诀
插帽龟 快堆,空(空间)龟N(恩)
(1)若待排序的记录数目n较小,可采用直接插入排序和简单选择排序。由于
直接插入排序所需的记录移动操作较简单选择排序多,因此当记录本身信息量较大时,用简单选择排序方法较好。
(2)若待排序记录按关键字基本有序,则宜采用直接插入排序或冒泡排序。
(3)当n 很大且关键字的位数较少时,采用链式基数排序较好。
(4)若n较大,则应采用时间复杂度为0(nlogn)的排序方法,例如快速排序、堆排序或归并排序。
如果两个相等的元素A和B在排序前A在B的前面,但在排序后B在A的前面,那么这种排序算法就是不稳定的。
1、直接插入:
从前开始,后前比较,相邻对调,小的排前,前方无序(从小到大排序)
先从第二位开始,后一位的数字与前一位的数字比较、交换,一直到这个数字不需要交换为止。然后再继续下一位数字的比较、交换。
前方无序:当前在前的相对小的数字,只是跟后方相邻的数字相对较小,不一定比更后面还没排序的数字小。
n个数可能为n次比较、交换,所以 时间 n2,相邻所以空间为1。
数字相等不交换即可,所以稳定。
2、冒泡排序:
从后开始,后前比较,相邻对调,小的排前,比较剩余(从小到大排序)
n个数可能为n次比较、交换,所以 时间 n2,相邻所以空间为1。
数字相等,可以不交换,所以稳定。
3、归并排序:
N 个数据,每2(3、4、5等)个为一组,组内排序;排好序的组,再每2(3、4、5等)个组合并为一个大组,再组内排序…直至合并为完整的一个组,再最后一次组内排序。
二分,所以时间是nlogn,两表合并一个新表,需要n空间
稳定。
4、快速排序:
一个基准值,交换则变向(low、high),一分为二。左右继续,直至完全有序。
折半查找,就是 logn,n 个数字就是 nlogn 空间;每次一个基准值,所以空间是 nlogn。
左右分组,相等数字可能变化,不稳定。
5、堆排序:
以序建堆(完全二叉树),非叶子节点与其左右孩子比较、交换,整体一遍,再局部微调。
二叉树二分,所以时间是nlogn,父子节点交换空间为1.
二分,则相等数字序列可能变化,所以不稳定。
6、简单选择:
从后开始,最小前置,位置对调,小的最前,前方有序,比较剩余(从小到大排序)
先从最后一位开始,找出最小的数字,将最小的数字与第1位的数字交换位置;然后在剩余的 n-1 个数字里,再从最后一位开始,找出最小的数字,将最小的数字与剩余的 n-1 个数字里的第1位,也就是当前所有数字的第2位交换位置…依次类推。
前方有序:最小的、第2小的、第3小的…都已经在第1位、第2位、第3位…有序排列了,只需要逐渐在后面无序的数字里找到最小的再排到前面有序的后面即可。
n个数可能为n次比较,1次交换,所以 时间 n2,相邻所以空间为1。
数字相等,与最前交换可能有问题(两个数字哪个与第一个交换成了问题),所以不稳定。
7、希尔排序:
增量分组,组内直接插入排序,位置编号对调,最后增量为1,最后全量直接插入排序(从小到大排序)
时间复杂度 n1.3,组内直接插入,所以空间为1
数字相等,跨组交换,组较多,序列可能变化,不稳定。
8、基数排序:
基于关键字排序。稳定。
[外链图片转存中…(img-hj26mrh4-1719793350149)]
直接插入:
第一次比较: 1 与 1 比较,不交换
第二次比较:第2个1 与 2 比较,不交换
第三次比较:2 与 4 比较,不交换
第四次比较:4 与 7 比较,不交换
第五次比较:7 与 5 比较,交换
第六次比较:4 与 5 比较,不交换,结束。
一共 6 次比较。
归并:需要看是几路合并,两路合并,就是两两为一个数组。
两路归并:
第一遍:
第一次:1 与 1 比较,不交换
第二次:2 与 4 比较,不交换
第三次:7 与 5 比较,交换
第二遍:
[1,1,2,4] 一组,[5,7]一组。
第一个1与2 比较 不交换。
第二个1与2比较 不交换
第三遍:
[1,1,2,4,5,7] 一组。
第一个1与5比较,不交换
第二个1与5比较,不交换
2与5比较,不交换
4与5比较,不交换
一共 3+2+4 = 9 次比较。
堆:
先建立完全二叉树:
[外链图片转存中…(img-gknelXUY-1719793350149)]
先最后一个非子节点进行比较:
左侧的1 与 4 、7 比较,这里比较 2 次(1与4比较,4与7比较,得到最大的7),7 对调。得到:
此时比较了2次。
[外链图片转存中…(img-JtBVzYl2-1719793350149)]
然后比较 2 的非叶子节点,比较 2 和 5,交换,得到:
这里比较了1次。
[外链图片转存中…(img-Pt7rsJLA-1719793350149)]
然后比较1的非叶子节点,即1和7、5比较(1与7比较,7与5比较,得到最大的),交换7到顶部。得到:
这里比较了2次。
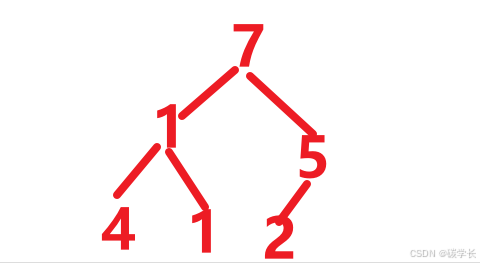
整体调了一遍,还需要进行局部比较、调整:
比较非叶子节点的1和其左右节点,即1和4、1比较(1和4,4与叶子节点1比较,得出最大的4),然后交换4。得到:
这里比较了2次。
[外链图片转存中…(img-5puwb4E9-1719793350149)]
此时4换上去了,则还需要比较其与其父节点的关系,即比较 7 和 4、5(7和4比较、7和5比较,得到最大的4),不需要交换。至此结束。得到:
这里比较了2次。
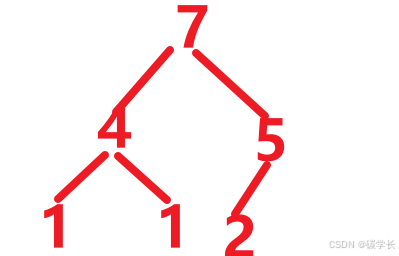
因此一共比较了 9 次。
快速排序:
先以第1个数字基准进行排序:即以1为基准:
先1与最后的5比较,不交换。
再1与倒数第二的7比较,不交换。
再1与倒数第三的4比较,不交换。
再1与倒数第四的2比较,不交换。
再1与倒数第五的1比较,不交换。
这里比较了5次。
然后再以剩余的五个数字[1,2,4,7,5] 中的第1个数字为基准,即以1为基准:
同理:1与5比较,不交换;1与7比较,不交换;1与4比较,不交换;1与2比较,不交换;
这里比较了4次。
然后再以剩余的4个数字[2,4,7,5]中的第1个数字为基准,即以2为基准:
同理:2 与5比较,不交换;2与7比较,不交换;2与4比较,不交换;
这里比较了3次。
然后再以剩余的3个数字[4,7,5]中的第1个数字为基准,即以4为基准:
同理:4与5比较,不交换;4与7比较,不交换。
这里比较了2次。
然后再以剩余的2个数字[7,5]中的第1个数字7为基准:
同理:7与5比较,交换。结束。
这里比较了1次。
所以总共比较了:5 + 4 + 3 + 2 + 1 = 15次。
所以答案为 A,B。直接插入排序,比较6次。
考点41、算法
[外链图片转存中…(img-LqMiow4S-1719793350150)]
所以答案为:D、A

[外链图片转存中…(img-vVl3FWJk-1719793350150)]
T(n) = 8T(n/2) + n2 则:
T(n) = 8 * (8 * T(n/2/2) + (n/2)2 ) + n2
= 82T(n/4) + 2n2+ n2
= 82 (8 * T(n/4/2) + (n/4)2 ) + 2n2 + n2
= 83T(n/8) + 4n2 + 2n2+ n2
=8nT(n/(2n) + 2n-1n2 + 2n-2n2 + … + 21n2+ 20n2
可以看到,肯定是远远大于 n2,所以时间复杂度是 n3
n 足够大,则 X 最大 为 63.
所以答案为:D、C。复杂度为 n2,最大值为63.
动态规划:0-1背包、最长公共子序列、矩阵链乘,一定得到最优解
贪心算法:部分背包、Dijkstra算法、Kruskal算法,只能局部最优
回溯法:迷宫类
分治法:折半查找
[外链图片转存中…(img-w40TKaCV-1719793350150)]
[外链图片转存中…(img-QPIF3wTq-1719793350150)]
1、分治法:分组且子问题相同且独立,最后合并。递归法。
◆分治法的设计思想是将一个难以直接解决的大问题分解成一些规模较小的相同问题,以便各个击破,分而治之。如果规模为n的问题可分解成k个子问题1<k≤n,这些子问题互相独立且与原问题相同。分治法产生的子问题往往是原问题的较小模式,这就为递归技术提供了方便。
◆一般来说,分治算法在每一层递归上都有3 个步骤。
(1)分解。将原问题分解成一系列子问题。
(2)求解。递归地求解各子问题。若子问题足够小则直接求解
(3)合并。将子问题的解合并成原问题的解。
◆凡是涉及到分组解决的都是分治法,且分组时分为的问题相同。
例如归并排序算法完全依照上述分治算法的3 个步骤进行。
(1)分解。将n 个元素分成各含n/2 个元素的子序列,
(2)求解。用归并排序对两个子序列递归地排序。
(3)合并。合并两个已经排好序的子序列以得到排序结果。
2、动态规划法:分组且子问题可能相同、可能独立,记录每个子问题的答案,寻找全局最优(最大、最小等),递归法。一定能得到全局最优。
◆动态规划算法与分治法类似,其**基本思想也是将待求解问题分解成若干个子问题,先求解子问题,然后从这些子问题的解得到原问题的解。**与分治法不同的是,适合用动态规划法求解的问题,**经分解得到的子问题往往不是独立的。**若用分治法来解这类问题,则相同的子问题会被求解多次,以至于最后解决原问题需要耗费指数级时间。
◆然而,不同子问题的数目常常只有多项式量级。如果能够保存已解决的子问题的答案,在需要时再找出已求得的答案,这样就可以避免大量的重复计算,从而得到多项式时间的算法。为了达到这个目的,可以**用一个表来记录所有已解决的子问题的答案。不管该子问题以后是否被用到,只要它被计算过,就将其结果填入表中。**这就是动态规划法的基本思路。
◆**动态规划算法通常用于求解具有某种最优性质的问题。**在这类问题中,可能会有许多可行解,每个解都对应于一个值,我们希望找到具有最优值(最大值或最小值)的那个解。当然,最优解可能会有多个,动态规划算法能找出其中的一个最优解。设计一个动态规划算法,通常按照以下几个步骤进行。
(1)找出最优解的性质,并刻画其结构特征。
(2)递归地定义最优解的值。
(3)以自底向上的方式计算出最优值。
(4)根据计算最优值时得到的信息,构造一个最优解。
◆步骤(1)~(3)是动态规划算法的基本步骤。在只需要求出最优值的情形
步骤(4)可以省略。若需要求出问题的一个最优解,则必须执行步骤
(4)。
◆对于一个给定的问题,若其具有以下两个性质,可以考虑用动态规划法来求
解。
(1)最优子结构。如果一个问题的最优解中包含了其子问题的最优,也就是说
该问题具有最优子结构。当一个问题具有最优子结构时,提示我们动态规划法可能会适用,但是此时贪心策略可能也是适用的。
(2)**重叠子问题。重叠子问题指用来解原问题的递归算法可反复地解同样的子问题,而不是总在产生新的子问题。**即当一个递归算法不断地调用同一个问题时,就说该问题包含重叠子问题。
动态规划的典型应用:0-1背包问题:即要么不放,要么全放。
两个条件:容量不能超过 W,且价值最大。
[外链图片转存中…(img-NOlirxhR-1719793350150)]
真题:最优子结构
[外链图片转存中…(img-v6IqTssQ-1719793350151)]
答案:B、B、A、B
3、贪心法:类似动态规划,但得到的是局部最优、可能近似最优,不一定是全局最优。
◆和动态规划法一样,贪心法也经常用于解决最优化问题。与动态规划法不同的是,贪心法在解决问题的策略上是仅根据当前已有的信息做出选择,而且一旦做出了选择,不管将来有什么结果,这个选择都不会改变。换而言之,贪心法并不是从整体最优考虑,它所做出的选择只是在某种意义上的局部最优。 这种局部最优选择并不能保证总能获得全局最优解,但通常能得到较好的近似最优解。
◆贪心法问题一般具有两个重要的性质。
(1)**最优子结构。**当一个问题的最优解包含其子问题的最优解时,称此问题具
有最优子结构。问题具有最优子结构是该问题可以采用动态规划法或者贪心法求解的关键性质。
(2)**贪心选择性质。**指问题的整体最优解可以通过一系列局部最优的选择,即
贪心选择来得到。这是贪心法和动态规划法的主要区别。证明一个问题具有贪心选择性质也是贪心法的一个难点。
相较于0-1背包问题:n 个背包,要么不放,要么全放;
而背包问题:n个背包,可以放部分。
[外链图片转存中…(img-fVO5eg2m-1719793350151)]
4、回溯法:N皇后
◆概念:有**“通用的解题法”之称,可以系统地搜索一个问题的所有解或任一
解。在包含问题的所有解的解空间树中,按照深度优先的策略**,从根节点出发搜索解空间树。搜索至任一结点时,总是**先判断该结点是否肯定不包含问题的解,**如果不包含,则跳过对以该结点为根的子树的搜索,逐层向其祖先结点回溯;否则,进入该子树,继续按深度优先的策略进行搜索。
◆可以理解为先进行深度优先搜索,一直向下探测,当此路不通时,返回上一层探索另外的分支,重复此步骤,这就是回溯,意为先一直探测,当不成功时再返回上一层。
一般用于解决迷宫类的问题。

0-1 背包问题: 要么都放、要么都不放(即完整的放,即一个物体,不能切开、拆开的放,这个物体要么放,要么不放)。
已知最大放入5个物品,背包容量最大为10,每个物体要么放,要么不放。
经过推算可以得到最大装包价值为:
排序为:[重量,价值]
[2,6],[2,3],[6,5],[5,4],[4,6]
动态规划采用的是递归法。类似于分治法,而分治法采用的是分组、分子问题。
根据重量限制能放:
2 + 4 + 2,价值为: 6 + 6 + 3 = 15
或
4 + 6,价值为:6 + 5 = 11
或
2 + 2 + 5,价值为 6 + 3 + 4 = 13
或
2 + 2 + 6,价值为 6 + 3 + 5 = 14
或
…
根据答案选项,已经可以验证答案为 C。
即62题答案为 C。
0-1背包的时间复杂度为 O(nW),记住即可。
即63题答案为 A。
部分背包问题,归并排序算法。归并排序算法:分组,排序,合并。时间服复杂度为 nlgn
单位重量价值:6/2 = 3;3/2 = 1.5 ; 5/6≈0.8333 ;4/5 = 0.8;6/4 = 1.5;
从大到小排序:
[单位重量价值,价值,重量]
[3,6,2]、[1.5,3,2]、[1.5,6,4]、[0.83,5,6]、[0.8,4,5]
或
[3,6,2]、[1.5,6,4]、[1.5,3,2]、[0.83,5,6]、[0.8,4,5]
已知最大放入5个物品,背包容量最大为10,
所以:2+2+4 = 8 < 10,放了3个,还可以再放2个,所以最大价值:6 + 3 + 6 + 2 * 0.8333 = 15 + 1.6666 ≈ 16.67。
所以 64 答案为 D、65 答案为 B。
[外链图片转存中…(img-GA7uxipA-1719793350151)]
该题的算法思路中只考虑了左端的房子的右侧放消防栓是否可以覆盖,但没有考虑一个消防栓是否同时覆盖左右两侧的。
所以这是一种考虑局部最优解的算法思路。所以是贪心算法的思路。
贪心的时间复杂度为: 考虑第1栋,第2栋…第n栋,所以是线性的,所以是 O(n)
只需要装5个即可:即30装一个(覆盖10、20、30、35),80装一个(覆盖60、80),160装一个、210装一个、280装一个(覆盖260和300)
所以答案为:
62:C
63:B
64:B
65:C**(贪心法可能得到近似最优解,也可能得不到,对有些实例,可能得不到最优)**
考点42:成熟度模型 CMM
1、能力成熟度模型
能力成熟度模型:CMM
[外链图片转存中…(img-IFQPhGXn-1719793350151)]
能力成熟度模型集成 CMMI
[外链图片转存中…(img-JqqSIcrd-1719793350151)]
考点43:软件工程、项目管理、关系代数
1、关系代数、关系模式
[外链图片转存中…(img-eBVIR3jD-1719793350151)]
2、信息系统开发方法
1、结构化方法(生命周期法):适用于需求明确,中小型项目,适合数据处理领域的项目
结构是指系统内各个组成要素之间的相互联系、相互作用的框架。
结构化方法也称为生命周期法,是一种传统的信息系统开发方法,由**结构化分析(Structured Analysis,SA)(系统分析阶段)、结构化设计(Structured Design,SD)(系统设计阶段)和结构化程序设计(Structured Programming,SP)(系统实施阶段)**三部分有机组合而成,其精髓是自顶向下、逐步求精和模块化设计。
结构化方法的主要特点:
(1)开发目标清晰化。结构化方法的系统开发遵循“用户第一”的原则。
(2)开发工作阶段化。每个阶段工作完成后,要根据阶段工作目标和要求进
行审查,这使各阶段工作有条不紊地进行,便于项目管理与控制。
(3)开发文档规范化。结构化方法每个阶段工作完成后,要按照要求完成相
应的文档,以保证各个工作阶段的衔接与系统维护工作的遍历。
(4)设计方法结构化。在系统分析与设计时,从整体和全局考虑,因
自顶向下地分解;在系统实现时,根据设计的要求,先编写各个具体的功能模块,然后自底向上逐步实现整个系统。
结构化:就要求所有需求都确定好、只能自顶向下(不能回去)。要模块化的设计、阶段化的开发等。
这种生命周期法在早期的软件开发中是可行的,因为早期的软件开发需求简单且明确等。
◆结构化方法的不足和局限
(1)开发周期长:按顺序经历各个阶段,直到实施阶段结束后,用户才能使
用系统。
(2)难以适应需求变化:不适用于需求不明确或经常变更的项目。
(3)**很少考虑数据结构:**结构化方法是一种面向过程,面向数据流的开发方
法,很少考虑数据结构。
◆结构化方法常用工具
结构化方法一般利用图形表达用户需求,常用工具有数据流图、数据字典、结构化语言、判定表以及判定树等。
2、面向对象:适合于大规模、特别复杂的项目
任何现实世界的事物都可以看作一个对象,类是对象的集合体。比如公共交通这个类将汽车、自行车这样的对象集合在公共交通类当中。
面向对象(Object-Oriented,OO)方法认为,客观世界是由各种对象组成的,任何事物都是对象,每一个对象都有自己的运动规律和内部状态,都属于某个对象类,是该对象类的一个元素。复杂的对象可由相对简单的各种对象以某种方式而构成,不同对象的组合及相互作用就构成了系统。
面向对象方法的特点:
(1)使用OO方法构造的系统具有更好的复用性,其关键在于建立一个全面、
合理、统一的模型(用例模型和分析模型)
(2)OO方法也划分阶段,但其中的系统分析、系统设计和系统实现三个阶段
之间已经没有“缝隙”。也就是说,这三个阶段的界限变得不明确,某项工作
既可以在前一个阶段完成,也可以在后一个阶段完成;前一个阶段工作做得不
够细,在后一个阶段可以补充。
(3)面向对象方法可以普遍适用于各类信息系统的开发。
面向对象方法的不足之处
必须依靠一定的面向对象技术支持,在大型项目的开发上具有一定的局限性
不能涉足系统分析以前的开发环节。
当前,一些大型信息系统的开发,通常是将结构化方法和OO方法结合起来。
首先,使用结构化方法进行自顶向下的整体划分;
然后,自底向上地采用OO方法进行开发。
因此,结构化方法和O0方法仍是两种在系统开发领域中相互依存的、不可替代的方法。
3、原型法:适用于需求不明确、分析层面难度大、技术层面难度不大
[外链图片转存中…(img-UVqsBcpj-1719793350152)]
原型化方法也称为快速原型法,或者简称为原型法。它是一种根据用户初步需求,利用系统开发工具,快速地建立一个系统模型展示给用户,在此基础上与用户交流,最终实现用户需求的信息系统快速开发的方法。
按是否实现功能分类:分为水平原型(行为原型,功能的导航)、垂直原型(结构化原型,实现了部分功能)
按最终结果分类:分为抛弃式原型、演化式原型。
◆原型法的特点
原型法可以使系统开发的周期缩短、成本和风险降低、速度加快,获得较高的综合开发效益。
原型法是以用户为中心来开发系统的,用户参与的程度大大提高,开发的系统符合用户的需求,因而增加了用户的满意度,提高了系统开发的成功率。
由于用户参与了系统开发的全过程,对系统的功能和结构容易理解和接受,有利于系统的移交,有利于系统的运行与维护。
◆原型法的不足之处
开发的环境要求高。管理水平要求高。
◆由以上的分析可以看出,原型法的优点主要在于能更有效地确认用户需求。从直观上来看,原型法适用于那些需求不明确的系统开发。
事实上,对于分析层面难度大、技术层面难度不大的系统,适合于原型法开发。
◆从严格意义上来说,目前的原型法不是一种独立的系统开发方法,而只是一种开发思想,它只支持在系统开发早期阶段快速生成系统的原型,没有规定在原型构建过程中必须使用哪种方法。因此,它不是完整意义上的方法论体系。这就注定了原型法必须与其他信息系统开发方法结合使用。
4、统一过程(RUP)
◆统一过程(RUP)
提供了在开发组织中分派任务和责任的纪律化方法。它的目标是在可预见的日程和预算前提下,确保满足最终用户需求的高质量产品。
◆3个显著特点:用例驱动、以架构为中心、迭代和增量。
◆4个流程:初始阶段、细化阶段、构建阶段和交付阶段。 每个阶段结束时都要安排一次技术评审,以确定这个阶段的目标是否已经达到。
◆适用:一个通用过程框架,可以用于种类广泛的软件系统、不同的应用领域
不同的组织类型、不同性能水平和不同的项目规模。
用例驱动:比如做一个图书馆管理系统,学生去借书。借书就是一个用例,即以实际的使用场景的例子来驱动。
[外链图片转存中…(img-KoG3q3Ef-1719793350152)]
3、逆向工程、再工程
[外链图片转存中…(img-HpiwCR6D-1719793350152)]
4、项目管理
1、范围管理
范围管理确定在项目内包括什么工作和不包括什么工作。
需求是:你要什么;
范围是:需求的边界;
◆产品范围和项目范围
产品范围是指产品或者服务所应该包含的功能。产品范围是否完成,要根据产品是否满足了产品描述来判断。产品范围是项目范围的基础,产品范围的定义是产品要求的描述。
项目范围是指为了能够交付产品,项目所必须做的工作。项目范围的定义是产生项目管理计划的基础。判断项目范围是否完成,要以范围基准来衡量。项目的范围基准是经过批准的项目范围说明书、WBS和WBS词典。
产品范围描述是项目范围说明书的重要组成部分,因此,产品范围变更后,首先受到影响的是项目的范围。
◆WBS 将项目整体或者主要的可交付成果分解成容易管理、方便控制的若干个子项目或者工作包,子项目需要继续分解为工作包,持续这个过程,**直到整个项目部分解为可管理的工作包,这些工作包的总和是项目的所有工作范围。**最普通的WBS 如下表所示:
[外链图片转存中…(img-Lh3KKvB6-1719793350152)]
2、进度管理(会考)
◆进度管理就是采用科学的方法,确定进度目标,编制进度计划和资源供应计划,进行进度控制,在与质量、成本目标协调的基础上,实现工期目标。
◆具体来说,包括以下过程:
(1)活动定义:确定完成项目各项可交付成果而需要开展的具体活动。
(2)活动排序:识别和记录各项活动之间的先后关系和逻辑关系。
(3)活动资源估算:估算完成各项活动所需要的资源类型和效益。
(4)活动历时估算:"估算完成各项活动所需要的具体时间。
(5)进度计划编制:分析活动顺序、活动持续时间、资源要求和进度制约因素,制订项目进度计划。
(6)进度控制:根据进度计划开展项目活动,如果发现偏差,则分析原因或进行调整。
活动资源估算的方法主要有:专家判断法、替换方案的确定、公开的估算数据、估算软件(依靠软件的强大功能,可以定义资源可用性、费率等)、自下而上的估算(把复杂的活动分解为更小的工作)。
软件规模估算模型:COCOMO模型(会考)
◆COCOMO模型:常见的软件规模估算方法。常用的代码行分析方法作为其中一种度量估计单位,以代码行数估算出每个程序员工作量,累加得软件成本。
模型按其详细程度可以分为三级:
(1)基本COCOMO模型是一个静态单变量模型,它用一个以已估算出来的原代码行数(LOC)为自变量的经验函数计算软件开发工作量。
(2)中间COCOMO模型在基本COCOMO模型的基础上,再用涉及产品、硬件人员、项目等方面的影响因素调整工作量的估算。
(3)详细COCOMO模型包括中间COCOMO模型的所有特性,将软件系统模型分为系统、子系统和模块3个层次,更进一步考虑了软件工程中每一步骤(如分析、设计)的影响。
基本COCOMO模型:只考虑代码行
中间COCOMO模型:考虑代码行之外,还考虑软硬件、人员等
详细COCOMO模型:考虑代码行之外,还考虑软硬件、人员等,以及软件工程的每一步:系统分析、系统设计等。
◆COCOMOⅡ模型:COCOMO的升级,也是以软件规模作为成本的主要因素考虑多个成本驱动因子。该方法包括三个阶段性模型,即应用组装模型、早期设计阶段模型和体系结构阶段模型。包含三种不同规模估算选择**:对象点、功能点和代码行。**
应用组装模型:需求分析阶段,以 对象点 为估算
早期设计阶段模型:设计阶段,以 功能点 为估算
体系结构阶段模型:开发阶段,以 代码行 为估算
Gantt 图(甘特图)和项目计划评审技术(Program Evaluation& Review Technique,PERT)图
◆进度安排的常用图形描述方法有Gantt 图(甘特图)和项目计划评审技术(Program Evaluation& Review Technique,PERT)图。
[外链图片转存中…(img-g6su4s2r-1719793350152)]
甘特图:反应了任务的并行关系
PERT 图: 反应了任务的依赖关系
3、成本管理
项目成本管理包括 成本估算、成本预算、成本控制三个过程。
估算:是估计多少钱,比如100万。
预算:拿到了100万,怎么分配、怎么花。
控制:节约。
◆成本的类型(考点)
(1)可变成本:随着生产量、工作量或时间而变的成本为可变成本。可变成本又称变动成本。(比如材料,生产一个手机要一个屏幕的材料,2个手机就要2个屏幕的材料。)
(2)固定成本:不随生产量、工作量或时间的变化而变化的非重复成本为固定成本。(比如厂房)
(3)直接成本:直接可以归属于项目工作的成本为直接成本。如项目团队差旅费、工资、项目使用的物料及设备使用费等。(项目团队的人独有的成本:差旅费、员工个人的工资、设备使用费)
(4)间接成本:来自一般管理费用科目或几个项目共同担负的项目成本所分摊给本项目的费用,就形成了项目的间接成本,如税金、额外福利和保卫费用等。(需要分摊的:税金、额外福利、管理层的工资)
(5)机会成本:是利用一定的时间或资源生产一种商品时,而失去的利用这些资源生产其他最佳替代品的机会就是机会成本,泛指一切在做出选择后其中一个最大的损失。(比如农民只有一块地,可以用来养猪或养鸡或养羊,养猪可以赚10万,养鸡可以赚8万,养羊可以赚12万,农民选择了养猪,而放弃了养鸡或养羊,这里损失的最大利益是12万(8万的鸡、12万的羊中最大的就是12万),所以这里机会成本就是12万,养猪的获得成本就是10万,一般来说都要获得成本大于机会成本,所以最合适的是这里选择养羊获得12万,机会成本损失10万(养猪和养鸡中最大的为10万))
(6)沉没成本:是指由于过去的决策已经发生了的,而不能由现在或将来的任何决策改变的成本。沉没成本是一种历史成本,对现有决策而言是不可控成本,会很大程度上影响人们的行为方式与决策,在投资决策时应排除沉没成本的干扰。(沉没成本是要排除的成本,比如电影票已经买了、钱已经花了,如果电影确实非常烂,不是去选择不管烂不烂都去把这个电影看了(因为钱已经花了),而是花了钱之后明确知道电影很烂,就直接放弃去看。)
学习曲线:重复生成产品时,**产品的单位成本会随着产量的扩大呈现规律性递减。**估算成本时,也要考虑此因素。(比如刚开始学习、做这个工作要10天,后续再做类似的工作就只需要3天了,随着不断地熟悉,单位成本就降低了)
4、软件配置管理
5、质量管理
◆质量是**软件产品特性的综合,表示软件产品满足明确(基本需求)或隐含(期望需求)要求的能力。**质量管理是指确定质量方针、目标和职责,并通过质量体系中的质量计划、质量控制、质量保证和质量改进来使其实现的所有管理职能的全部活动;
◆主要包括以下过程:
(1)质量规划:识别项目及其产品的质量要求和标准,并书面描述项目将如何达到这些要求和标准的过程。
(2)质量保证:一般是每隔一定时间(例如,每个阶段末)进行的,主要通过系统的质量审计((软件评审)和过程分析来保证项目的质量。
(3)质量控制:实时监控项目的具体结果,以判断它们是否符合相关质量标准,制订有效方案,以消除产生质量问题的原因。
质量模型、质量特性:(常考)
功能性:一组功能及其指定的性质有关的一组属性,包括安全性、准确性、适合性等
可靠性:在规定的一段时间和条件下,软件维持其性能水平有关的一组软件特性,包括容错性、易恢复、成熟等
可用性:于使用的难易程度及规定或隐含用户对使用方式所做的评价有关的软件属性,包括易理解、易操作等
效率(性能):与在规定条件下,软件的性能水平和所用资源之间的关系有关的一组软件属性,包括几秒内打开、吞吐量等
可维护性:与进行指定的修改所需的努力有关的一组软件属性,包括易分析、稳定、可修改、可测试。
可移植性:与软件可从某一环境转移到另一环境的能力有关的一组软件属性。包括适应性、易安装、一致性、可替换等。
质量审计(软件评审)、过程分析是软件质量保证的主要活动。
5、自然连接
[外链图片转存中…(img-GXtkmEHV-1719793350153)]
自然连接是除去重复属性的等值连接。是连接运算的一个特例。是最常用的连接运算。
两个关系:R(A,B,C,D),S(C,D,E,F),则自然连接为: 满足 R.C = S.C 且 R.D = S.D 的,结果为 R.A,R.B,R.C,R.D,E,F (去除后一个关系中同名且属性值满足的)
考点44:Python
真题1:在 Python3中,(C)不是合法的异常处理结构。
A、try…except… B、try…except…finally C、try…catch… D、raise
真题2:在Python3中,表达式list(range[11]))[10:0:-2]的值为([10,8,6,4,2])
真题3:在Python3中,执行语句x=input(),如果从键盘输入123并按回车键,则x的值为(‘123’)
模拟题:
Pyton 类型强转的写法,则是将需要转换的数据括起来 A
A、int(42.7) B、(int)42.7
观察打印结果:
for i in range(1,5):
print(i)
输出为:1,2,3,4
左闭右开
a_list = [7,6,5,4,3,2]
a_list.insert(3,‘h’)
结果:[7,6,5,‘h’,4,3,2]
a_list = [7,6,5,4,3,2,‘a’]
print(a_list[2:4]) // 左闭右开;但如果下标从0开始算的话,不存在闭的说法
print(a_list:index(‘a’))
结果:[5,4]、6
a=(1,2,3,4,5,6)
a = a[:2] +(10,) + a[2:]
pirnt(a)
结果:(1,2,10,3,4,5,6) // 左闭右开
python 内置函数有:abs(绝对值)、divmod(商合余数)
round(四舍五入)、bool(1) = True
complex() // 创建一个新的复数 返回复数 0j
str:返回字符串表现 str(None) => ‘None’
bytearray 创建新的字节数组
memoryview 内存查看对象
ord:返回 Unicode 字符转整数
chr: 整数转 Unicode 字符
oct:将整数转化成 8 进制 数字符串
hex:将整数转换成 16进制字符串
python 保留字
import keyword
keyword.kwlist
python 内置数据结构
python内置的常用数据类型有:数值、字符串、列表、元组、字典、集合等
不可变类型:数值、字符串、元组
可变类型:列表、字典、集合
python 运算符is和==的区别
运算符is和==的区别
Python中对象包含三要素:id、type、value。
其中id用来唯一标识对象,type用来标识对象的类型,value用来标识对象的值。
is用来判断两个变量引用的值是否为同一个,用id来判断。
==用来判断两个对象的值是否相等,用value来判断。
isinstance(object, classinfo)用来判断type,如果对象的类型与参数二的类型(classinfo)相同则返回 True,否则返回 False。
python 列表生成式
[x * x for x in range(1, 11)]
结果:[1, 4, 9, 16, 25, 36, 49, 64, 81, 100]
python 字符串格式化%和.format()的区别
format()方法拥有比%更广的适用范围。
需要在一个位置添加元素或者列表类型的代码时,最好使用format方法。
python 流程控制
if 条件表达式1:
语句块1
elif 条件表达式2:
语句块2
……
else:
语句块n
python 异常处理
# 自定义异常
class MyException(Exception):
def __init__(self, code):
self.code = code
if a == 5:
# 抛出异常
raise MyException(5)
异常处理:
try:
print("可能会出错的代码")
a = 1 / 0
except:
print("出错")
finally:
print("一定会执行")
python 自定义函数
Python中用def来定义普通函数。
Python用关键字Lambda定义匿名函数。
考点45:下午题一:结构化开发方法、数据流图
真题1:
阅读下列说明和数据流图,回答问题1至问题4,将解答填入答题纸的对应栏内。
【说明】
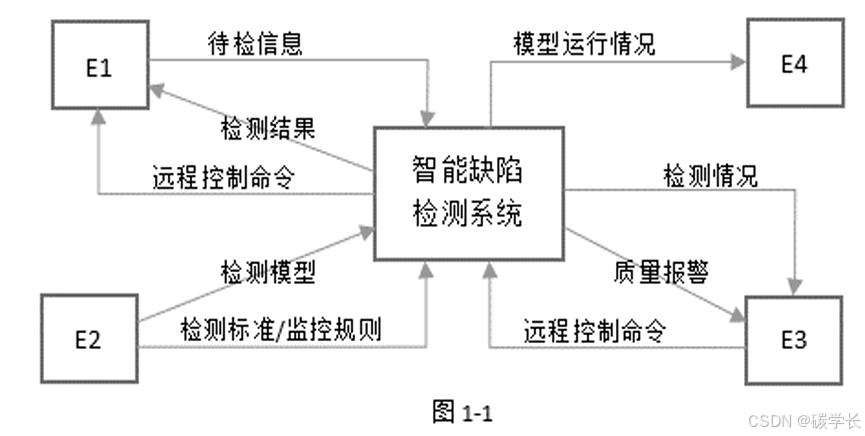
某工厂制造企业开发了智能检测系统以有效提升检测效率,节约人力资源,该系统的主要功能包括:
(1)基础信息管理。管理员对检测标准和监控规则等基础信息设置。
(2)检测模型部署。管理员对常用机器学习方法建立检测模型分布
(3)图像采集。实时将检测多样的产品待检测建分存储,包括产品结构,生产时间,图像信号和产品图像。
(4)缺陷检测。根据检测模型和检测质量标准对图像采集所收到的产品检测信息中所有图像进行检测或所有图像检测合格。若一个产品出现一张图像检测不合格,就表示该产品不合格,对不合格产品,其检测结果包括,产品型号和不合格类型。
5)质量检测。根据监控规则对产品质量进行监控,将检测情况展示给检测业务员,若不满足条件,向检测业务员发送质量报警,检测是质量发起远程控制部分,向检测设备发送控制指令进行处理。
(6)模型监控。在系统中部署的模型、产品的检测信息结合基础信息进行监测分析将模型运行情况发给监控人员
现采用结构化方法对智能检测系统,进行分析与设计,获得如图1-1的上下文数据流图和图 1-2的数据流图:
[外链图片转存中…(img-LI6skp7q-1719793350153)]
问题1(4分)
使用说明中的语句给出图1-1中的实体 E1~E4 的名称。
E1:检测设备 E2:管理员 E3:检测业务员 E4:监控人员
问题2(3分)
使用说明中的语句给出图1-2中的数据存储D1~D3的名称
D1:模型信息表 D2:检测信息表 D3:基础信息表
解析:根据进入数据流的箭头来确定名称。
问题3(5分)
根据说明和图中术语,补齐图1-2中缺失的数据及起点和终点。
数据流名称 起点 终点
产品监测信息 P2 P3
监控规则 D3 P5
远程控制命令 E3 P5
基础信息 D3 P6
解析:
可以通过以下几个点来补充缺失:
1、加工必须有输入和输出(即入箭头和出箭头)
2、加工的输入必须足以产生输出
3、父图中的加工的输入(或输出)数据流必须与子图的输入(或输出)数据流在数量和名字上相同
4、父图中的一个输入(或输出)数据流对应于子图中几个输入(或输出)数据流
[外链图片转存中…(img-j0sVlYcP-1719793350153)]
数据流的流向必须经过加工,即必须起点和终点中至少有一个是数据存储、加工,即可以是:数据存储、加工 或 加工、数据存储 或 加工、加工。
[外链图片转存中…(img-X7uLYQNt-1719793350153)]
问题4(3分)
根据说明,采用结构化语言对缺陷检测的加工逻辑进行描述。
接收到产品检测信息
对所有图像进行检测
IF 一个产品出现一张图像检测不合格
THEN 该产品不合格
不合格的产品的检测结果包括产品类型和不合格类型
ENDIF
解析:
结构化语言:顺序语句、选择语句、循环语句
选择语句:
IF 条件 THEN
分支内容
ELSE IF 条件 THEN
分支内容
ELSE
分支内容
ENDIF
循环语句:
WHILE 下雨
DO
{
在家
IF 不下雨 THEN
出门
ENDIF
}
ENDDO
真题2:
阅读下列说明和数据流图,回答问题1至问题4,将解答填入答题纸的对应栏内。
【说明】
某停车场运营方为了降低运营成本,减员增效,提供良好的停车体验,欲开发无人值守停车系统,该系统的主要功能是:
(1)信息维护。管理人员对车位(总数、空余车位数等)计费规则等基础信息进行设
置。
(2)会员注册。车主提供手机号、车牌号等信息进行注册,提交充值信息(等级、绑定并授权支付系统进行充值或交费的支付账号)不同级别和充值额度享受不同停车折扣点。
(3)车牌识别。当车辆进入停车场时,若有(空余车位数大于1),自动识别车牌号后进行道闸控制,当车主开车离开停车场时,识别车牌号,计费成功后,请求道闸控制。
(4)计费。更新车辆离场时间,根据计费规则计算出停车费用,若车主是会员,提示停车费用:若储存余额够本次停车费用,自动扣费,更新余额,若储值余额不足,自动使用授权缴费账号请求支付系统进行支付,获取支付状态。若非会员临时停车,提示停车费用,车主通过扫描费用信息中的支付码调用支付系统自助交费,获取支付状态。
(5)道闸控制。根据道闸控制请求向道闸控制系统发送放行指令和接收道闸执行状态。若道闸执行状态为正常放行时,对入场车辆,将车牌号及其入场时间信息存入停车记录,修改空余车位数:对出场车辆更新停车状态,修改空余车位数。当因道闸重置系统出现问题(断网断电或是故障为抬杠等情况),而无法在规定的时间内接收到其返回的执行状态正常放行时,系统向管理人员发送异常告警信息,之后管理人员安排故障排查处理,确保车辆有序出入停车场。
现采用结构化方法对无人值守停车系统进行分析与设计,获得如图1-1所示的上下文数据流图和图 1-2所示的0层数据流图。
[外链图片转存中…(img-uA5HDHTT-1719793350154)]
问题1(5 分)
使用说明中的词语,给出图1-1中的实体E1~E5的名称:
E1:车辆 E2:车主 E3:支付系统 E4:管理人员 E5:道闸控制系统
问题2(3分)
使用说明中的词语,给出图1-2中的数据存储D1~D3的名称
D1:停车记录表 D2:会员信息表 D3:基础信息表
问题 3(4分)
根据说明和图中术语,补充图1-2中缺失的数据流及其起点和终点。
数据流名称 起点 终点
道闸控制请求 P1 P5
计费规则 D3 P3
更新余额 P3 D2
修改空余车位数 P5 D3
解析:
可以通过以下几个点来补充缺失:
1、加工必须有输入和输出(即入箭头和出箭头)
2、加工的输入必须足以产生输出
数据流名称可以是动词或名词,需要依据给的图来动态确定,如果图中的其他数据流为动词,则这里也写动词;为名词则写名词,将所给题中的动作梳理出来。
[外链图片转存中…(img-pdqXmVpl-1719793350154)]
问题4(3分)
根据说明,采用结构化语言对“道闸控制”的加工逻辑进行描述。
收到道闸控制请求
IF 道闸执行状态为正常放行时
THEN
IF 入场车辆
THEN 将车牌号及其入场时间信息停入车停记录,
修改空余车位数
ELSE
更新停车状态,修改空余车位数
ENDIF
ELSE
向管理人员发送异常告警信息
ENDIF
其他题型
1、加工的分解
加工的分解、描述需要注意三个错误:
1、加工有输入但没有输出
2、加工有输出但没有输入
3、加工的输入不足以产生输出
子加工就是子事件:
比如 根据说明中的术语,说明“使用单车”可以分解为哪些子加工?(2分)
答:扫码/手动开锁、更新行程、锁车结账
2、数据流的组成
数据流的组成:数据流就是数据名称,即有哪些名词(数据流)组成,比如:
农事信息请求 = 账号 + 密码 + 查询条件
农事信息请求的数据流由账号、密码、查询条件组成。
3、数据流图平衡原则
父子图的数据流图的平衡:
父图中某加工的输入输出数据流必须与子图的输入输出数据流在数量和名字上相同;
父图中的一个输入(或输出)数据流对应于子图中几个输入(或输出)数据流。
考点46:下午题二:E-R 图、关系模式
真题1:
阅读下列说明,回答问题1至问题4,将解答填入答题纸的对应栏内。
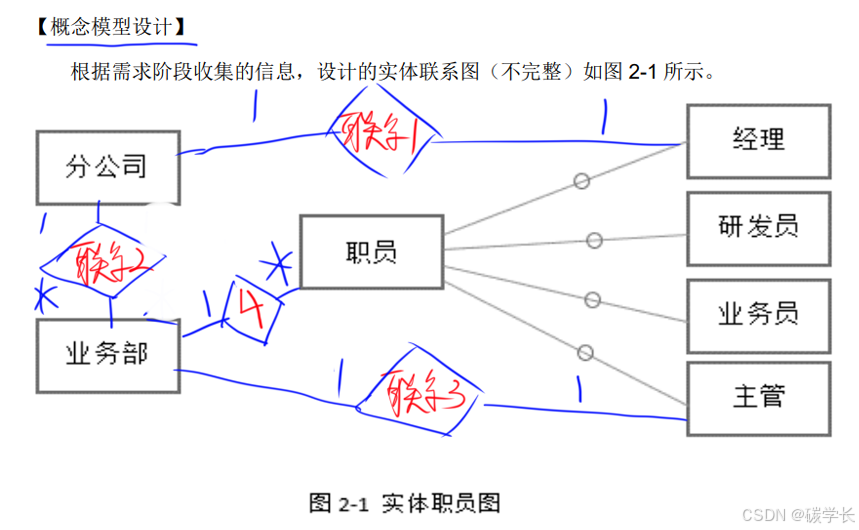
【说明】 M集团拥有多个分公司,为了方便集团公司对各个分公司职员进行有效管理,集团公司 决定构建一个信息平台以满足公司各项业 务管理需求。 【需求分析结果】
(1)分公司关系模式需要记录的信息包括分公司编号、名称、经理号、联系地址和电 话。分公司编号唯一标记分公司关系模式中的每一个元组,每个分公司各有一名经理,负责 分公司的管理工作,每个分公司设立仅为本分公司服务的多个业务部,业务部包括:研发部、 财务部、采购部、交易部等。
(2)业务部关系模式需要记录的信息包括业务部编号、名称、地址、电话和分公司编 号。业务部编号唯一标记业务部关系模式中的每 一个元组,每个业务部各有一名主管负责 业务部的管理工作,每个业务部有多名职员,每个职员只能来源于一个业务部。
(3)职员关系模式需要记录的信息包括职员号、姓名、所属业务部编号、岗位、电话、 家庭成员姓名和成员关系。其中岗位包括:经理、主管、研发员、业务员等。 【概念模型设计】 根据需求阶段收集的信息,设计的实体联系图(不完整)如图2-1所示。
[外链图片转存中…(img-jVsWephZ-1719793350154)]
【逻辑结构设计】 根据概念模型设计阶段完成的实体联系图,得出如下关系模式(不完整):
分公司(分公司编号,名称, (a) ,联系地址)
业务部(业务部编号,名称, (b) ,电话),
职员(职员号,姓名,岗位, (c) ,电话,家庭成员姓名,成员关系)
【问题1】( 4分)
根据问题描述,补充4个联系,完善图2-1的实体联系图,联系名可用联系1、联系2、 联系3和联系4代替,联系的类型为1:1、1:n和m:n(或1:1、1:* 和 * 😗)
【问题2】( 3分)
根据题意将以上关系模式中的空(a)〜(c)的属性补充完整,并填入对应位置。
(a):经理号,电话
(b):地址,分公司编号,主管号
(c):所属业务部编号
【问题3】( 4分)
(1)分析分公司关系模式的主键和外键
(2)分析业务部关系模式的主键和外键
分公司主键:分公司编号
分公司外键:经理号
业务部主键:业务部编号
业务部外键:分公司编号,主管号
【问题4】( 4分) 在职员关系模式中,假设每个职员有多名家属成员,那么职员关系模式存在什么问题? 应如何解决?
职员关系模式存在数据冗余,修改异常,插入异常,删除异常等问题。
应将“职员”关系模式进行分解,分解之后的关系模式如下:
职员1(职员号,姓名,岗位,所属业务部编号,电话)
职员2(职员号,家庭成员姓名,成员关系)
解析:
联系 是 菱形
实体 是 方形
属性 是 椭圆形
不要只看题目中包含的还有看实体联系图来确定。
真题2:
阅读下列说明,回答问题1至问题4,将解答填入答题纸的对应栏内。
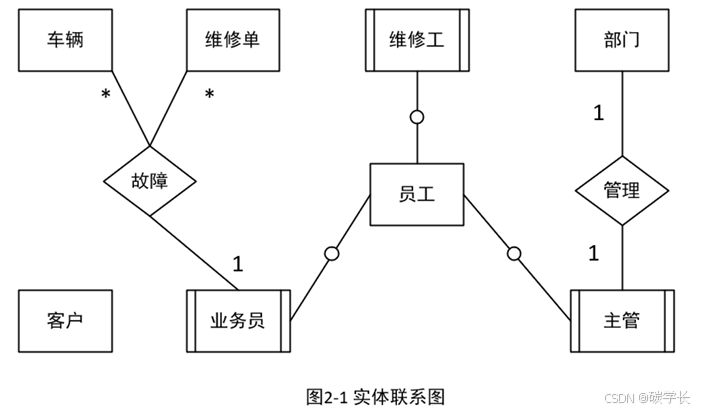
【说明】 某汽车维修公司为了便于管理车辆的维修情况,拟开发一套汽车维修管理系统,请根据 下述需求描述完成该系统的数据库设计。
【需求分析结果】
(1)客户信息包括:客户号、客户名、客户性质、折扣率、联系人、联系电话。客户 性质有个人或单位。客户号唯一标识客户关系中的每一个元组。
(2)车辆信息包括:车牌号、车型、颜色和车辆类别。一个客户至少有一辆车,一辆 车只属于一个客户。
(3)员工信息包括:员工号、员工名、岗位、电话、家庭住址。其中,员工号唯一标 识员工关系中的每一个元组。岗位有业务员、维修工、主管。业务员根据车辆的故障情况填 写维修单。
(4)部门信息包括:部门号、名称、主管和电话。其中,部门号唯一确定部门关系的 每一个元组。每个部门只有一名主管,但每个部门有多名员工,每名员工只属于一个部门。
(5)维修单信息包括:维修单号、车牌号、维修内容、工时。其中,维修单号唯一标 识维修单关系中的每一个元组。一个维修工可以接多张维修单,但一张维修单只对应一个维 修工。
【概念模型设计】
根据需求阶段收集的信息,设计的实体联系图(不完整)如图2-1所示。
【逻辑结构设计】
根据概念模型设计阶段完成的实体联系图,得出如下关系模式(不完整):
客户(客户号,客户名, (a) ,折扣率,联系人,联系电话)
车辆(车牌号, (b) ,车型,颜色,车辆类别)
员工(员工号,员工名,岗位, (c) ,电话,家庭住址)
部门(部门号,名称,主管,电话)
维修单(维修单号, (d) ,维修内容,工时)
【问题1】( 6分)
根据问题描述,补充3个联系,完善图2-1的实体联系图。联系名可以用联系1、联系 2 和联系3代替,联系的类型为1:1、1:n和m:n(或1:1、1: * 和 * : * )
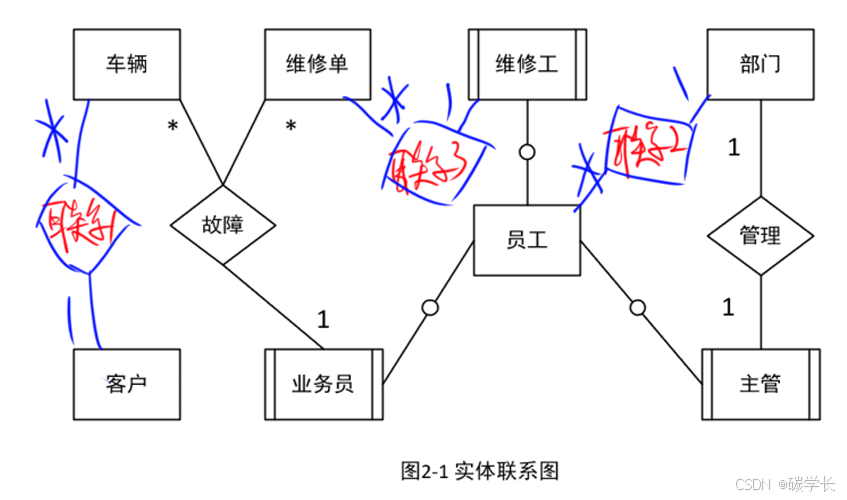
解析:
一定要画 棱形的 联系
【问题2】( 4分)
根据题意,将关系模式中的空(a)〜(d)的属性补充完整,并填入答题纸对应的位置 上。
(a):客户性质
(b):客户号
(c):部门号
(d)车牌号,维修工
解析:
一定要根据题目文字和实体联系图来综合回答,题目文字包含的可能不全或不明显。
【问题3】( 2分)
分别给出车辆关系和维修单关系的主键和外键。
“车辆”关系的
主键:车牌号
外键:客户号
“维修单”关系的
主键:维修单号
外键:车牌号,维修工
【问题4】( 3分)
如果一张维修单涉及多项维修内容,需要多个维修工来处理,那么哪个联系类型会发生 何种变化?你认为应该如何解决这一问题?
这个联系类型会从*:1变成 * :* 。
应该先将维修单关系中的维修工删除掉,然后将这个联系转换成一个独立的关系模式,关系模式如下:
维修(维修单号,维修工,维修内容)
这样维修的主键是(维修单号,维修内容)
外键是:维修工
其他题型
1、实线:主键 虚线:外键
[外链图片转存中…(img-avIHGqmo-1719793350154)]
[外链图片转存中…(img-T7WiWnwY-1719793350155)]
2、不增加新的实体的 画法
【需求分析结果】
(1)记录供应商的信息,包括供应商的名称,地址和一个电话。
(2)记录零件的信息,包括零件的编码,名称和价格。
(3)记录车型信息,包括车型的编号,名称和规格。
(4)记录零件采购信息,某个车型的某种零件可以从多家供应商采购,某种零件也可以被多 个车型采用,某家供应商也可以供应多种零件,还包括采购数量和采购日期。
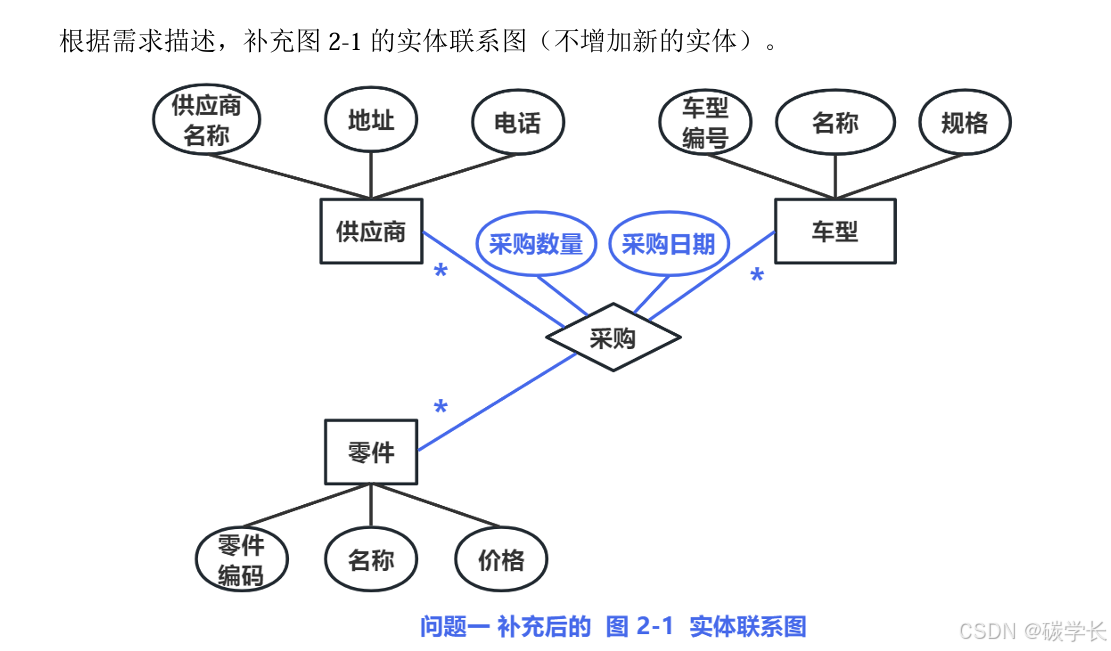
3、主键和全码
- 候选码:能够唯一标识一条记录的最小属性集
- 主码:某个能够唯一标识一条记录的最小属性集(是从候选码里人为挑选的一条)
- 外码:如果一个关系中的一个属性是另外一个关系中的主码则这个属性为外码
- 全码:当所有的属性共同构成一个候选码时,这时该候选码为全码。(教师,课程,学生)假如一个教师可以讲授多门课程,某门课程可以有多个教师讲授,学生可以听不同教师讲授的不同课程,那么,要区分关系中的每一个元组,这个关系模式]R的候选码应为全部属性构成 (教师、课程、学生),即主码。
- 主属性:包含在任一候选码中的属性称主属性。简单来说,主属性是候选码所有属性的并集。
- 非主属性 不包含在候选码中的属性称为非主属性。 非主属性是相对于主属性来定义的。
4、传递依赖
员工号->岗位,岗位->基本工资;根据 Armstrong 公理系统的传递律规则,员工号->基本工资。
5、弱实体
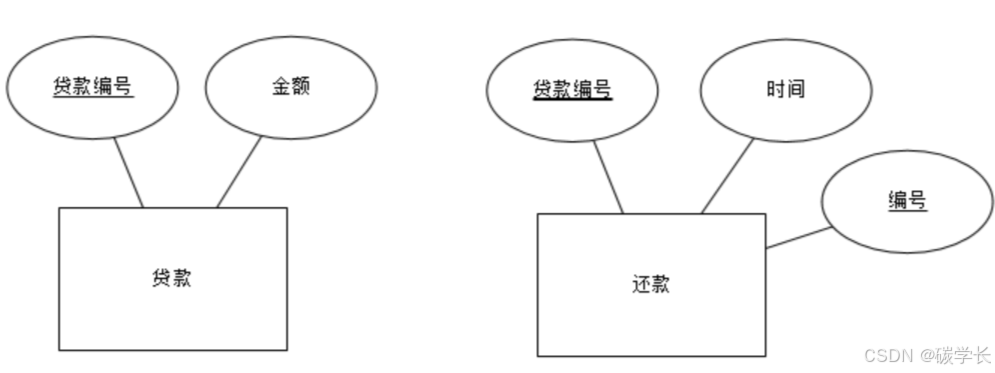
我们发现属性会冗余,贷款编号是贷款的主码,也是还款的外码和主码。
为了消除冗余,我们只能消除还款的贷款编号属性。
但这样会出现一个问题,还款是还的谁的款??
为了解决这个问题,我们设置一个特殊的联系集 还贷,它还能够给还款实体集提供一个额外的属性,即贷款编号。这里还贷叫做标识性联系。
弱实体:双线矩形框
标识联系:双线菱形框
[外链图片转存中…(img-w4b39kjR-1719793350155)]
考点 47:下午题三:UML 类图与设计模式
◆用例图:静态图,展现了一组**用例、参与者以及它们之间的关系。用例图中的参与者是人、硬件或其他系统可以扮演的角色;用例是参与者完成的一系列操作,用例之间的关系有扩展、包含、泛化。**如下:
扩展、包含、泛化是用例图特有的。
[外链图片转存中…(img-rMq3nBts-1719793350155)]
扩展: 当执行A操作之后,B操作可能做也可能不做,B不是必要的。图像的箭头是 B 指向 A比如查询到书籍信息后,如果查询到不一致,则可能需要去修改书籍信息;如果查询到一致,则不用去修改书籍信息。再比如支付付钱,如果支付宝余额里的钱够,就直接支付了;如果不够,则会从银行卡里先转钱,再支付。这里的银行卡转钱的操作就是可能做也可能不做的。
包含: 当执行A操作之前,必须先执行B操作。图像的箭头是 A 指向 B 比如要登记、查询外借信息,必须先用户登录,不登录就没有权限登记、查询。
**泛化:**表示父子关系。一般与特殊的关系。比如动物与小鸟;班级与二班;学生与小明等
真题1:
阅读下列说明和UML图,回答问题1至问题3,将解答填入答题纸的对应栏内。
【说明】 某房产公司欲开发一个房产信息管理系统,其主要功能描述如下:
(1)公司销售的房产(Property)分为住宅(House)和公寓(Cando)两类。针对每 套房产,系统存储房产证明、地址、建造年份、建筑面积,销售报价、房产照片以及销售状 态(在售,售出,停售)等信息。对于住宅,还需存储楼层、公摊面积、是否有地下室等信息;对于公寓,还需存储是否有阳台等信息。
(2)公司雇佣了多名房产经纪(Agent),负责销售房产,系统中需要存储房产经纪的 基本信息,包括:姓名、家庭住址、联系电话、受雇的起止时间等。一套房产同一时段仅由 一名房产经纪负责销售,系统中会记录房产经纪负责每套房产的起始时间和终止时间。
(3)系统用户(User)包括房产经纪和系统管理员(Manager),用户需经过系统身份验证之后才能登录系统。房产经纪登录系统之后,可以录入负责销售的房产信息,也可以查询所负责的房产信息。房产经纪可以修改其负责的房产信息,但需要经过系统管理员的审批授权。
(4)系统管理员可以从系统中导出所有房产的信息列表,系统管理员定期将售出和停 售的房产信息进行归档,若公司确定不再销售某套房产,系统管理员将该房产信息从系统中删除。
现采用面向对象方法开发该系统,得到如图 3-1 所示的用例图和图 3-2 所示的初始类 图。
[外链图片转存中…(img-2gKZs55b-1719793350155)]
【问题1】( 7分)
(1)根据说明中描述,分别给出图3-1中A1到A2所对应的参与者名称以及U1到U3 所对应的用例名称。
(2)根据说明中描述,分别给图3-1中(a)和(b)用例之间的关系。
A1:房产经纪
A2:系统管理员
U1:审批授权
U2:修改房产信息
U3:删除房产信息
(a): << include >> (b): << extend >>
解析:
用例中均为动词
因此 处理出 参与者 及其对应的动词即可。
(a) 用例是 房产经纪的修改房产信息 与 系统管理员的 导出房产信息之间的关系。
系统管理员要导出房产信息,必须要 房产经纪先修改房产信息(假设是一个新的系统,还没有房产信息,则需要录入房产信息,录入之后如果要导出最新的房产信息,则必须要先修改)。所以是 include 包含关系。
(b)用例是 系统管理员的 删除房产信息 与 归档 之间的关系,归档 不一定要删除,当然删除也可以。所以这是扩展关系,即 extend。
[外链图片转存中…(img-vkKGrDN4-1719793350155)]
[外链图片转存中…(img-clcSULa7-1719793350156)]
【问题2】( 6分)
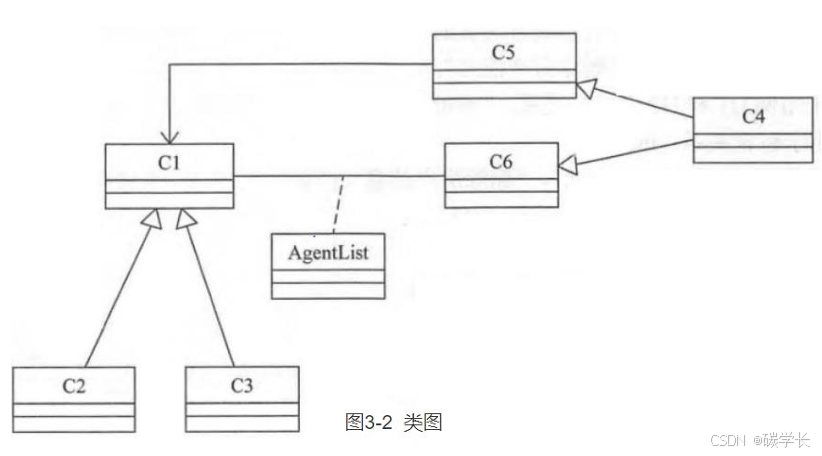
根据说明中描述,分别给图3-2中C1〜C6所对应的类名称。
[外链图片转存中…(img-hCiXV6zv-1719793350156)]
答案:**C1:Property C2:House C3:Cando C4:User C5:Manager C6:Agent **
解析:
根据上图已知:
C4 与 C5、C6 是泛化关系,C4 是 一般,C5、C6 是特殊;
C2、C3 与 C1 是泛化关系,C1 是一般,C2、C3 是特殊;
C1、C6 是关联的 AgentList
类 C5 依赖于 类 C1。
结合题目中的英文:
房产(Property)分为住宅(House)和公寓(Cando)
房产经纪(Agent)
系统用户(User)包括房产经纪和系统管理员(Manager)
所以 要么 C4 是房产、C1 是 Agent;要么 C4 是 Agent、C1是房产;
而 C5 关联于 C1,Agent 是关联 房产的,所以 C1 是房产
因此推出以上答案。
UML 类图详解
UML 类图
- 用于描述系统中的类(对象)本身的组成和类(对象)之间的各种静态关系。
- 类之间的关系:
依赖、泛化(继承)、实现、关联、聚合与组合
强到弱依次为:组合>聚合>关联>依赖。
[外链图片转存中…(img-JPBRIshx-1719793350156)]
1、泛化关系(generalization)
[外链图片转存中…(img-LA5a8shb-1719793350156)]
泛化:表示父子关系。一般与特殊的关系。比如动物与小鸟;班级与二班;学生与小明等
泛化关系其实就是继承关系:指的是一个类(称为子类、子接口)继承(extends)另外的一个类(称为父类、父接口)的功能,并可以增加自己额外的一些功能,继承是类与类或者接口与接口之间最常见的关系;
在Java中此类关系通过关键字 extends明确标识。
在UML类图中,继承通常使用 空心三角+实线 表示
[外链图片转存中…(img-KT5LodvM-1719793350156)]
代码层面:
// 普通用户
public class User {
private Long id;
private String name;
}
// 员工
public class Employee extends User {
private BigDecimal salary;
}
// 客户
public class Customer ectends User {
private String address;
}
2、实现关系(realization)

- 实现关系:指的是一个class类实现 interface接口(可以实现多个接口)的功能;实现是类与接口之间最常见的关系;
- 在Java中此关系通过关键字
implements明确标识。 - 在UML类图中,实现通常使用
空心三角+虚线表示
[外链图片转存中…(img-Ee9lfktU-1719793350156)]
代码层面
// 普通用户
public interface Vehicle {
// 抽象方法:行驶
void drive();
}
public class Car implements Vehicle {
private Engine engine;
public Car(Engine engien) {
this.engine = engine;
}
// 实现接口中的drive 方法
@Override
public void derive() {
entine.start();
}
}
3、依赖关系(dependent)
[外链图片转存中…(img-95naorfH-1719793350157)]
- 依赖关系:指的是类与类之间的联接。依赖关系表示一个类依赖于另一个类的定义。一般而言,依赖关系在Java语言中体现为成员变量、局域变量、方法的形参、方法返回值,或者对静态方法的调用。
- 表示一个A类依赖于B类的定义,如果A对象离开B对象,A对象就不能正常编译,则A对象依赖于B对象(A类中使用到了B对象);
- 比如某人要过河,需要借用一条船,此时人与船之间的关系就是依赖; 表现在代码层面,类B作为参数被类A在某个method方法中使用。
在UML类图中,依赖通常使用虚线箭头表示
代码层面
public class BClass{
}
public class AClass{
private BClass b1; // 依赖关系情况1:成员变量. 这也是关联关系
public void doWork(BClass b2){ // 依赖关系情况2: 方法参数
}
public void doWork(){
BClass b3; // 依赖关系情况3: 方法内的局部变量
}
}
public class EmployeeServiceImpl implements IEmployeeService{
private EmployeeMapper employeeMapper;
public PageResult query(QueryObject qo){
// TODO
return null;
}
}
[外链图片转存中…(img-CNWzGgOQ-1719793350157)]
4、关联关系(association)
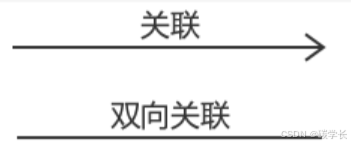
- 关联关系:指的是类与类之间的联接,它使一个类知道另一个类的属性和方法(实例变量体现)。A类依赖于B对象,并且把B作为A的一个成员变量, 则A和B存在关联关系.
- 关联可以是双向的,也可以是单向的。两个类之前是一个层次的,不存在部分跟整体之间的关系。
- 在UML类图中,关联通常使用实线箭头表示
[外链图片转存中…(img-ws3PDMks-1719793350157)]
5、聚合关系(aggregtion)

-
聚合关系是关联关系的一种特例,他体现的是整体与部分,是一种“弱拥有”的关系,即has-a的关系。聚合是整体和个体之间的关系。
-
例如,汽车类与引擎类、轮胎类,以及其它的零件类之间的关系便整体和个体的关系。
与关联关系一样,聚合关系 也是通过实例变量实现的。但是关联关系所涉及的两个类是处在同一层次上的,而在聚合关系中,两个类是处在不平等层次上的,一个代表整体,另一个代表部分。 -
聚合关系表示整体和个体的关系,整体和个体可以相互独立存在,一定是有两个模块分别管理整体和个体。
-
在UML类图中,聚合通常使用空心菱形+实线箭头表示
[外链图片转存中…(img-fmWhlYpG-1719793350157)]
6、组合关系(composition)

- 组合关系是关联关系的一种特例,他体现的是一种contains-a(包含)的关系,这种关系比聚合更强,也称为强聚合。
- 它要求普通的聚合关系中代表整体的对象负责代表部分对象的生命周期,组合关系是不能共享的。代表整体的对象需要负责保持部分对象和存活,在一些情况下将负责代表部分的对象湮灭掉。代表整体的对象可以将代表部分的对象传递给另一个对象,由后者负责此对象的生命周期。换言之,代表部分的对象在每一个时刻只能与一个对象发生组合关系,由后者排他地负责生命周期。部分和整体的生命周期一样。
- 整体和个体不能独立存在,一定是在一个模块中同时管理整体和个体,生命周期必须相同(级联)。
- 在UML类图中,组合通常使用实心菱形+实线箭头表示
[外链图片转存中…(img-jr52P1AM-1719793350157)]
【问题3】( 2分)
图3-2 中AgentList 是一个英文名称,用来进一步阐述C1和C6之间的关系,根据说 明中的描述,给出AgentList的主要属性。
答案:AgentList 的主要属性有:房产经纪负责该房产的起始时间和结束时间
解析:
[外链图片转存中…(img-ZUYCy2VR-1719793350158)]
C1 Property
C6 Agent
AgentList 在 C1、C6 关联关系中,结合题目中的话:一名房产经纪负责一套房产。所以 AgentList 代表的是 房产经纪与反铲的关系,这里就是房展经纪负责的每套房产的起始时间和终止时间。
真题2
阅读下列说明和UML图,回答问题1至问题3,将解答填入答题纸的对应栏内。
【说明】
某游戏公司欲开发一款吃金币游戏。游戏的背景为一种回廊式迷宫(Maze),在迷宫的 不同位置上设置有墙。迷宫中有两种类型的机器人(Robos):小精灵(PacMan)和幽灵 (Ghost)。游戏的目的就是控制小精灵在迷宫中游走,吞吃迷宫路径上的金币,且不能被幽 灵抓到。幽灵在迷宫中游走,并会吃掉遇到的小精灵。机器人游走时,以单位距离的倍数计 算游走路径的长度。当迷宫中至少存在一个小精灵和一个幽灵时,游戏开始。
机器人上有两种传感器,使机器人具有一定的感知能力。这两种传感器分别是:
(1)前向传感器(FrontSensor)。探测在机器人当前位置的左边、右边和前方是否有 墙(机器人遇到墙时,必须改变游走方向)。机器人根据前向传感器的探测结果,决定朝哪 个方向运动。
(2)近距离传感器(ProxiSensor)。探测在机器人的视线范围内(正前方)是否存在 隐藏的金币或幽灵。近距离传感器并不报告探测到的对象是否正在移动以及朝哪个方向移动。 但是如果近距离传感器的连续两次探测结果表明被探测对象处于不同的位置,则可以推到出 该对象在移动。
另外,每个机器人都设置有一个计时器(Timer),用于支持执行预先定义好的定时事件。 机器人的动作包括:原地向左或向右旋转90°、向前或向后移动。
建立迷宫:用户可以使用编辑器(Editor)编写迷宫文件,建立用户自定义的迷宫。将 迷宫文件导入游戏系统建立用户自定义的迷宫。
现采用面向对象分析与设计方法开发该游戏,得到如图3-1所示的用例图以及图3-2所 示的初始类图。
[外链图片转存中…(img-AVLPOEN9-1719793350158)]
[外链图片转存中…(img-XnZrx64n-1719793350158)]
[外链图片转存中…(img-PK1LKBHH-1719793350158)]
解析:

其他题型
1、设计模式
【问题3】(3分) 在该系统的开发过程中遇到了新的要求:用户能够在系统中对其所关注的数字资源注册他引 通知,若该资源的他引次数发生变化,系候可以及时通知该用户,为了实现这个新的要求,可以 在图3-2所示的类图中增加哪种设计模式?用150字以内文字解释选择该模式的原因。
答:观察者模式,该模式适合当一个对象的状态发生改变时,所有依赖于它的对象都得到通 知并被自动更新,符合问题描述中的当资源他引次数发生变化,便通知所有关注该资源的用户。
【问题3】( 4分) 现需将图3-1 所示的界面改造为一个更为通用的GUI应用,能够实现任意计量单位之 间的换算,例如千克和克之间的换、厘米和英寸之间的换算等等。为了实现这个新的需求, 可以在图3-3 所示的类图上增加哪种设计模式?请解释选择该设计模式的原因(不超过50 字)。
应当增加“策略模式”,策略模式将一系列的算法封装起来,并使得它们可以相互替换。适用于需要使用一个算法的不同变体的场景。
考点 48:下午题四:数据结构与算法、C 代码
动态规划:0-1背包、最长公共子序列、矩阵链乘,一定得到最优解:最佳切割、字符序列
2013下半年:矩阵链乘(相乘)
[外链图片转存中…(img-5xyW7mCZ-1719793350158)]

2014 下半年:最长公共子序列
[外链图片转存中…(img-Vm48fHGD-1719793350159)]
[外链图片转存中…(img-lc8igHzx-1719793350159)]
贪心算法:部分背包、Dijkstra算法、Kruskal算法,只能局部最优
2013上半年
[外链图片转存中…(img-20eNcxA5-1719793350159)]
[外链图片转存中…(img-7X8rJZUD-1719793350159)]
根据题中说明和代码注释,算法首先初始化数组d和s中的元素;然后将m个任务分配到 m 台机器上,此时将任务 0,1,…,m-1 分别分配到机器 0,1,…,m-1 上,同时设置 d、s和 count 数组中的相关元素的值,故空格(1)填写 d[] =t[i];接下来将剩下的 n-m 个任务分配到 m 台机器上,从任务 m开始,因此空格(2)填写i=m,确定首先空闲的机器k,将当前尚未分配的第一个任务分配到机器k上,并设置 d、s和 count 数组中的相关元素的值,故空格(3)填写s[k[count[k]]=i;最后确定从任务开始到结束所需要的时间,从所有机器的运行时间中选择运行时间最长的机器的运行时间,即最大的 d,因此空格(4)填写 max< d{i]。
回溯法:迷宫类,深度优先:无向连通图的哈密尔顿回路算法、N皇后
分治法:折半查找:分奇偶
2014上半年
[外链图片转存中…(img-jtHpYGTo-1719793350159)]
[外链图片转存中…(img-4bHcTXRi-1719793350159)]
考点49:下午题六:设计模式 JAVA 代码
| 创建型 | 定义 | 关键字 |
|---|---|---|
| Acstract Factory 抽象工厂 | 提供一个接口,可以创建一系列相关或相互依赖的接口,而无需指定它们具体的类 | 抽象接口 |
| Builder构建器 | 将一个复杂类的表示与其构造相分离,使得相同的构建过程能够得到不同的表示 | 类和构造分离 |
| Factory Method 工厂方法 | 定义一个创建对象的接口,但由子类决定需要实例化哪一个类。 | 子类决定实例化 |
| Prototype 原型 | 用原型实例指定创建对象的类型,并且通过拷贝这个原型来创建新的对象 | 原型实例、拷贝 |
| Singleton 单例 | 保证一个类只有一个实例,并提供一个访问它的全局访问点 | 唯一实例 |
| 结构型 | 定义 | 关键字 |
|---|---|---|
| Adapter 适配器 | 将一个类的接口转换转换成用户希望得到的另一种接口。使得原本不相容的接口得以协同工作。 | 转换、兼容接口 |
| Bridge 桥接模式 | 将对象组合成树型结构以表示“整体-部分”的层次结构,使得用户对单个对象和组合对象的使用具有一致性。 | 整体-部分、树形结构 |
| Decorator 装饰 | 动态的给一个对象添加一些额外职责。 | 附加职责 |
| Facade 外观 | 定义一个高层接口,为一组接口提供一个一致的外观。 | 对外统一接口 |
| Flyweight 享元 | 提供支持大量细粒度对象共享的有效方法 | 细粒度、共享 |
| Proxy 代理 | 为对象提供一种代理以控制对这个对象的访问 | 代理控制 |
| 行为型 | 定义 | 关键字 |
|---|---|---|
| Chain of Responsibility 责任链 | 通过给多个对象处理请求的机会,减少请求的发送者与接收者之间的耦合。将接受对象链接起来,在链中传递请求 | 传递请求、职责链接 |
| Command 命令模式 | 将一个请求封装为一个对象,用不同的请求对客户进行参数化,将请求排队或记录请求日志,支持可撤销的操作。 | 日志记录、可撤销 |
| Interpreter 解释器 | 给定一种语言,定义它的文法表示,并定义一个解释器,该解释器用来根据文法表示来解释语言中的句子 | 解释器、虚拟机 |
| Iterator迭代器 | 提供一种方法来顺序访问一个聚合对象中的各个元素而不暴露该对象的内部表示 | 顺序访问、不暴露内部 |
| Mediator 中介者 | 用一个中介对象封装一系列对象交互。使得各对象不需要显式地相互调用,还可以独立改变对象间的交互 | 不直接引用 |
| Memento 备忘录 | 在不破坏封装性的前提下,捕获一个对象的内部状态,并在该对象之外保存这个状态,从而可以在以后将该对象恢复到原先保存的状态 | 保存、恢复 |
| Observer 观察者 | 定义对象间的一种一对多的依赖关系,当一个对象的状态发生改变时,所有依赖于它的对象都得到通知并自动更新 | 通知、自动更新 |
| State 状态 | 允许一个对象在其内部状态改变时改变它的行为 | 状态编程类 |
| Strategy 策略 | 定义一系列算法,把它们一个个封装起来,并且使它们之间可以互相替换。 | 算法替换 |
| Template Method 模板方法 | 定义一个操作中的算法骨架,而将一些步骤延迟到子类中,使得子类可以不改变一个算法的结构即可重新定义算法的某些特定步骤 | |
| Visitor 访问者 | 表示一个作用于某对象结构中的各元素的操作,使得在不改变各元素的类的前提下定义作用于这些元素的新操作 | 数据和操作分离 |
1、原型 Prototype
[外链图片转存中…(img-HQJ9Zmvb-1719793350159)]
2、桥接 Bridge
[外链图片转存中…(img-lUryOfW9-1719793350160)]
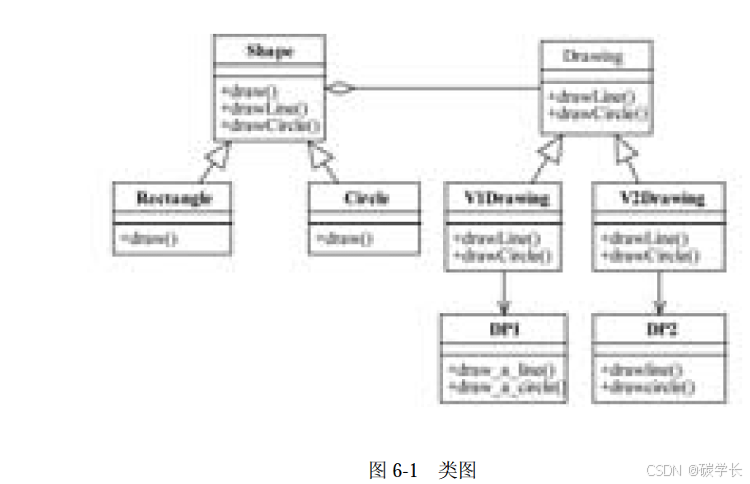
[外链图片转存中…(img-bPZkqhyh-1719793350160)]

3、Observer 观察者
[外链图片转存中…(img-4cD26vaW-1719793350160)]
[外链图片转存中…(img-CrvlIpaF-1719793350160)]

4、Command 命令模式
[外链图片转存中…(img-psnPAy2v-1719793350161)]
[外链图片转存中…(img-YSMDg0JG-1719793350161)]
5、状态 State
[外链图片转存中…(img-PTr6c18W-1719793350161)]
抽象类 对应 抽象方法
[外链图片转存中…(img-bEqWTMTs-1719793350161)]
考点50:错题集详解
第六题:JAVA 代码
[外链图片转存中…(img-y9nl6aeZ-1719793350162)]
[外链图片转存中…(img-rlinPCTO-1719793350162)]
import java.util.*;
interface Patient {
(1)public String getName() ;
}
interface Disposer {
(2)public void dispose(Patient patient) ;
}
class Registry implements Disposer { // 挂号
public void dispose(Patient patient) {
System.out.println("I am registering..." + patient.getName());
}
}
class Doctor implements Disposer { // 医生门诊
public void dispose(Patient patient) {
System.out.println("I am diagnosing..." + patient.getName());
}
}
class Pharmacy implements Disposer { // 取药
public void dispose(Patient patient) {
System.out.println("I am giving medicine... " + patient.getName());
}
}
class Facade {
private Patient patient;
public Facade(Patient patient) {
this.patient = patient; // 构造函数中用 this
}
void dispose() {
Registry registry = new Registry();
Doctor doctor = new Doctor();
Pharmacy pharmacy = new Pharmacy();
registry.dispose(patient); // 方法中不用 this
doctor.dispose(patient);
pharmacy.dispose(patient);
}
}
class ConcretePatient implements Patient {
private String name;
public ConcretePatient(String name) {
this.name = name; // 构造函数中用 this
}
public String getName() {
return name; // 方法中不用 this
}
}
public class FacadeTest {
public static void main(String[] args) {
Patient patient = (3) new ConcreatePatient("任意字符串") ;
(4)Facade f = (5) new Facade(patient);
(6) f.dispose( ) ;
}
}
第三题:UML 类图
[外链图片转存中…(img-vIqodqeY-1719793350162)]
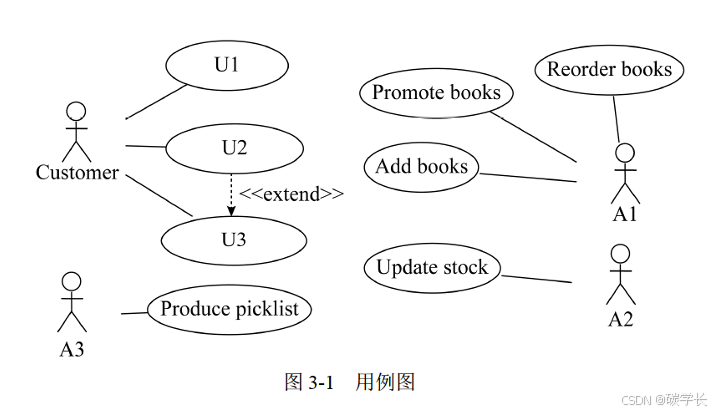
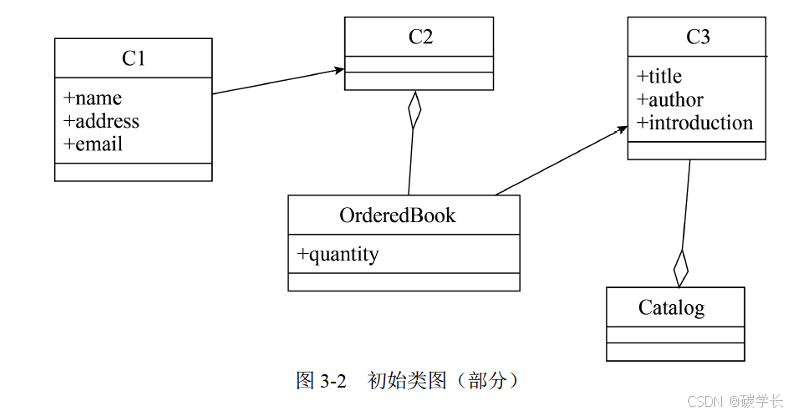
[外链图片转存中…(img-oyZPGl6E-1719793350163)]
[外链图片转存中…(img-YlTwDDCC-1719793350163)]
所以 U1:Register details U2: Print order U3: Buy books
注意:要填写的类名一定是题目中出现的,而不需要自己再组合、组装。
即 C1 是 Customer,C2:Order,C3:Books
而不会是 C2 是 什么 OrderBooks 等这种组合的。
注意:基本事件流 就是完成这件事的完整流程,完整流程中的可选事件就是备选事件流。
U3 购买书籍的基本事件流就是:
基本事件流:顾客登录系统,浏览书籍信息,选择所需购买的书籍及其数量,进入验证界面,输入注册码,生成订单
备选事件流:
(1)书籍的购买数量大于其库存量,提示库存不足
(2)注册码不正确,提示验证码错误
(3)顾客要求打印订单信息
[外链图片转存中…(img-h7Yj5MfK-1719793350163)]
[外链图片转存中…(img-VzNTfffK-1719793350164)]
[外链图片转存中…(img-MEdNRSZV-1719793350165)]
注意 用例的参与者,题目中某些动作的主语是谁;注意关联关系。
第二题:E-R图
[外链图片转存中…(img-Amqm9jfZ-1719793350165)]
注意:这样的实体联系图,应该如下图这样补充:靠近实体的位置,描述 1 或 * 的关系。
[外链图片转存中…(img-KvRMSEnH-1719793350165)]
[外链图片转存中…(img-8vm0ObaH-1719793350165)]
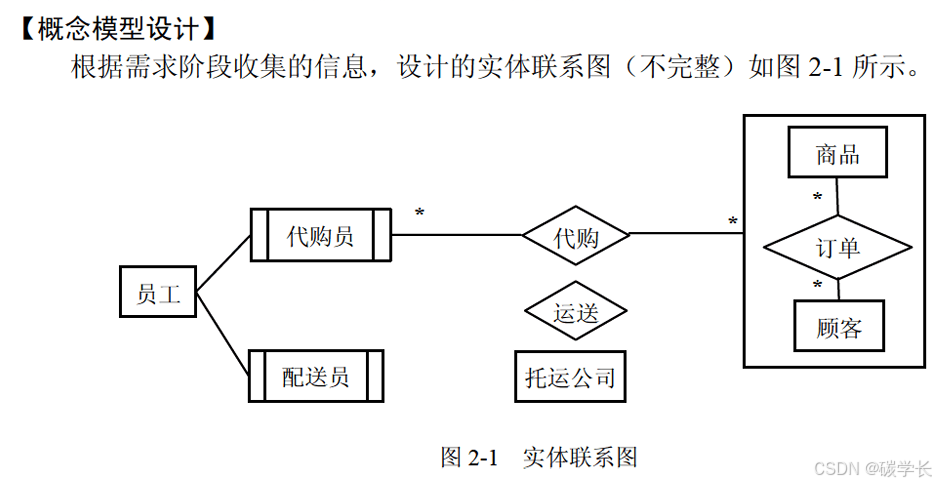
[外链图片转存中…(img-xwNbqkQj-1719793350166)]
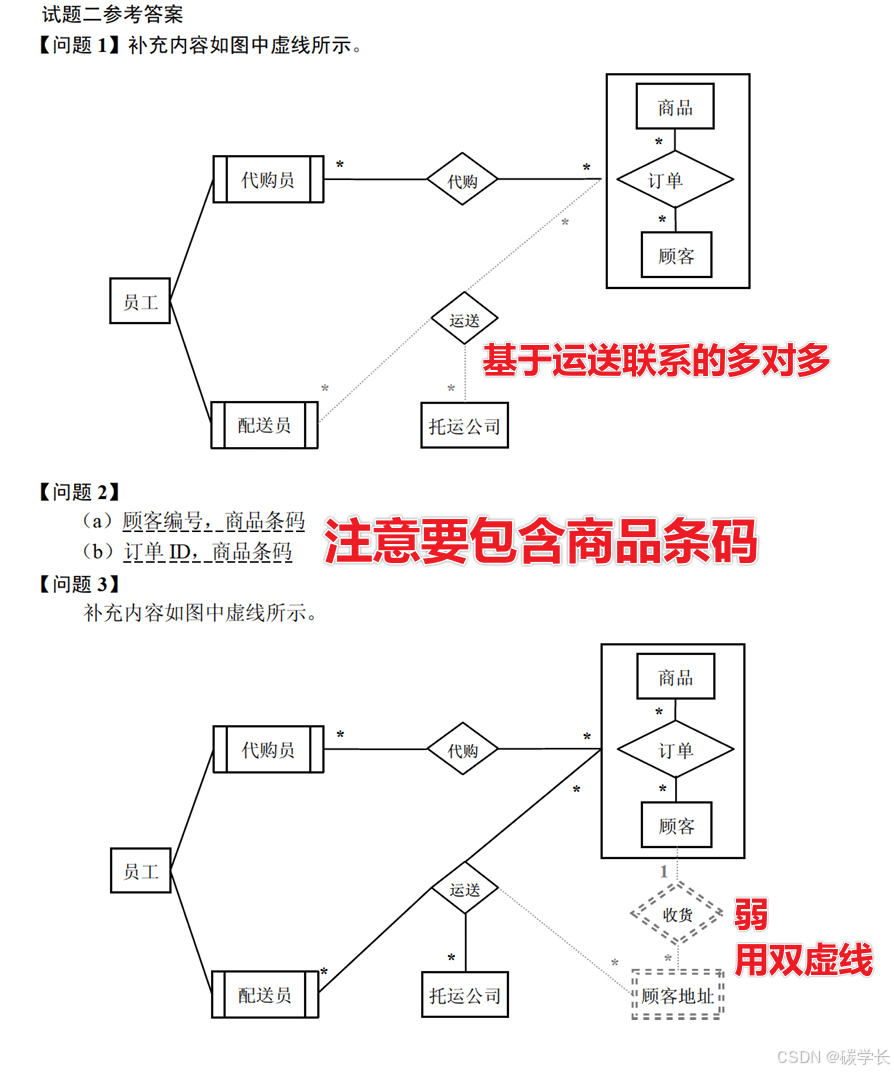
注意 联系必须有 棱形,实体用方形。
订单有商品数量,也要有商品条码,来确定商品。
代购是去代购商品的,所以也要有商品条码,再根据订单 ID 可以去订单里找到商品数量等。
[外链图片转存中…(img-OmLe7OfN-1719793350166)]
第一题:数据流图
[外链图片转存中…(img-7pqe8yLn-1719793350166)]
[外链图片转存中…(img-FL8EnAno-1719793350166)]
[外链图片转存中…(img-PnpO1Ywy-1719793350166)]
[外链图片转存中…(img-lqAMb8Tu-1719793350166)]
注意:根据、包括;存储于;更新;…中等关键词。
[外链图片转存中…(img-8qblzz3Z-1719793350167)]
注意:查询 、更新、删除,去哪查询,查询结果返回给谁;谁给谁更新;谁给谁删除等等。
[外链图片转存中…(img-UZRKAk7w-1719793350167)]
注意并字, 应该是 5 到 E1 而不是 D4 到 E1
[外链图片转存中…(img-9DDKMvQn-1719793350167)]
选择题
[外链图片转存中…(img-KK75tK73-1719793350167)]
[外链图片转存中…(img-NsaAZysB-1719793350167)]
颜色包括亮度、色调、饱和度。
饱和度指的是颜色的纯度,即颜色的深浅;
色调指的是与混合光谱中主要光波长 相联系
亮度:与颜色重混合了多少白色或黑色有关
[外链图片转存中…(img-513ZKJQV-1719793350167)]
逆波兰式也叫后缀式,利用(栈)进行求值。
[外链图片转存中…(img-pOuuCuad-1719793350167)]
[外链图片转存中…(img-sIOzBZlP-1719793350168)]
[外链图片转存中…(img-o0UHvnCY-1719793350168)]
[外链图片转存中…(img-5IIYA1y7-1719793350168)]
[外链图片转存中…(img-43dk8Jdu-1719793350168)]
[外链图片转存中…(img-p4LRQ4JE-1719793350168)]
[外链图片转存中…(img-jV7E8eZ9-1719793350168)]
[外链图片转存中…(img-Vjbs8RJQ-1719793350168)]
[外链图片转存中…(img-qLR6XK2N-1719793350169)]
[外链图片转存中…(img-IMYuPq4y-1719793350169)]
[外链图片转存中…(img-qkgSnRRr-1719793350169)]
[外链图片转存中…(img-nWLhigRT-1719793350169)]
[外链图片转存中…(img-mrtZXopf-1719793350169)]
[外链图片转存中…(img-PVZgEEnw-1719793350169)]
[外链图片转存中…(img-Cjn3PhYk-1719793350169)]
[外链图片转存中…(img-3NgzOoeX-1719793350169)]
统一过程:
起始阶段:项目的初创活动:项目计划等
精化阶段:需求分析和架构演进
构建阶段:系统的构建,产生实现模型
移交阶段:软件提交
[外链图片转存中…(img-nKaqWhnY-1719793350170)]
重载是同一个类中方法之间的关系,而覆盖是父类和子类之间的关系
[外链图片转存中…(img-q0Z5s27L-1719793350170)]
[外链图片转存中…(img-pBijezWK-1719793350170)]
D 是黑盒测试。
白盒测试的原则除了上面的 ABC,还有一点:测试程序内部数据结构的有效性等。
[外链图片转存中…(img-aqludd5X-1719793350170)]
RSA、DSA、ECC 公开密钥加密;非对称加密
[外链图片转存中…(img-44g2XPW4-1719793350170)]
[外链图片转存中…(img-KDxuP8EN-1719793350170)]
[外链图片转存中…(img-RIGcYtA3-1719793350170)]
[外链图片转存中…(img-4jrUEEo4-1719793350170)]
[外链图片转存中…(img-RQUWSr39-1719793350171)]
[外链图片转存中…(img-tqAUO9b7-1719793350171)]
[外链图片转存中…(img-3ZfipoJC-1719793350171)]
[外链图片转存中…(img-jrEBnIwB-1719793350171)]
[外链图片转存中…(img-pTo7jJ4J-1719793350171)]
甘特:甘,日期,与时间有关。
PERT:箭头
[外链图片转存中…(img-W2vB7yap-1719793350171)]
执行了COMMIT 语句,则可将T对数据库的更新写入数据库;
COMMIT 后已经永久保存了,ROLLBACK 不能撤销。
[外链图片转存中…(img-NlA8Kw4J-1719793350171)]
[外链图片转存中…(img-NqpqP4EO-1719793350172)]