使用python撰写axriv论文下载代码,使用kimi,智谱清言,通义千问
使用月之暗面的kimi:
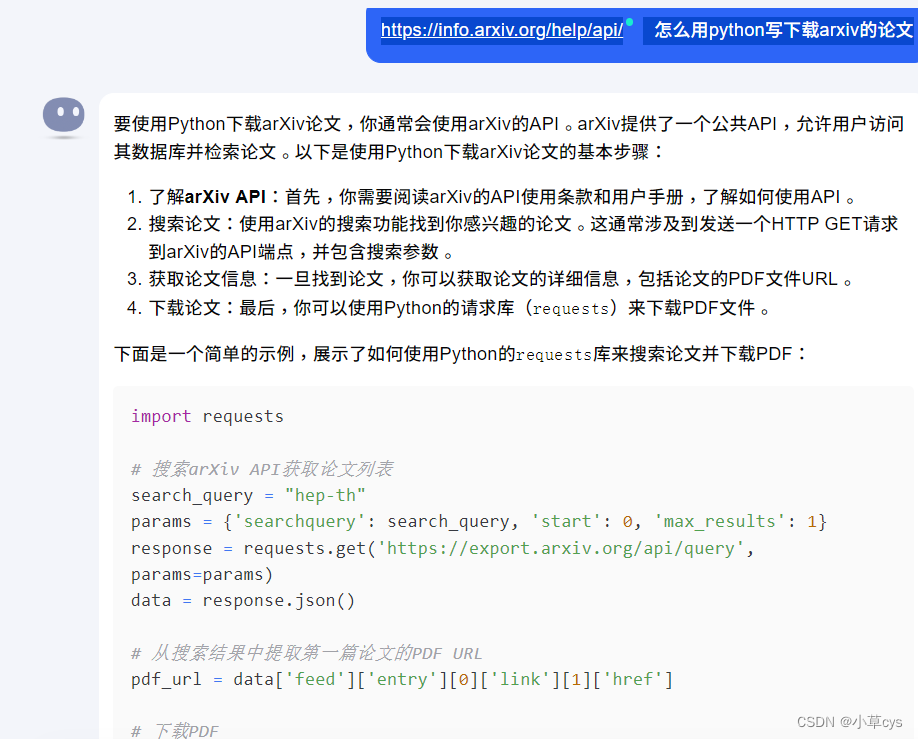
给出的代码如下,有问题,到最后一步执行不正确:
import requests
# 搜索arXiv API获取论文列表
search_query = "hep-th"
params = {'searchquery': search_query, 'start': 0, 'max_results': 1}
response = requests.get('https://export.arxiv.org/api/query', params=params)
data = response.json()
# 从搜索结果中提取第一篇论文的PDF URL
pdf_url = data['feed']['entry'][0]['link'][1]['href']
# 下载PDF
pdf_response = requests.get(pdf_url, stream=True)
# 确保请求成功
if pdf_response.status_code == 200:
# 写入文件
with open('paper.pdf', 'wb') as file:
for chunk in pdf_response.iter_content(chunk_size=128):
file.write(chunk)
print('Paper downloaded successfully.')
else:
print('Failed to download the paper.')后使用智谱清言可以得到好的代码:
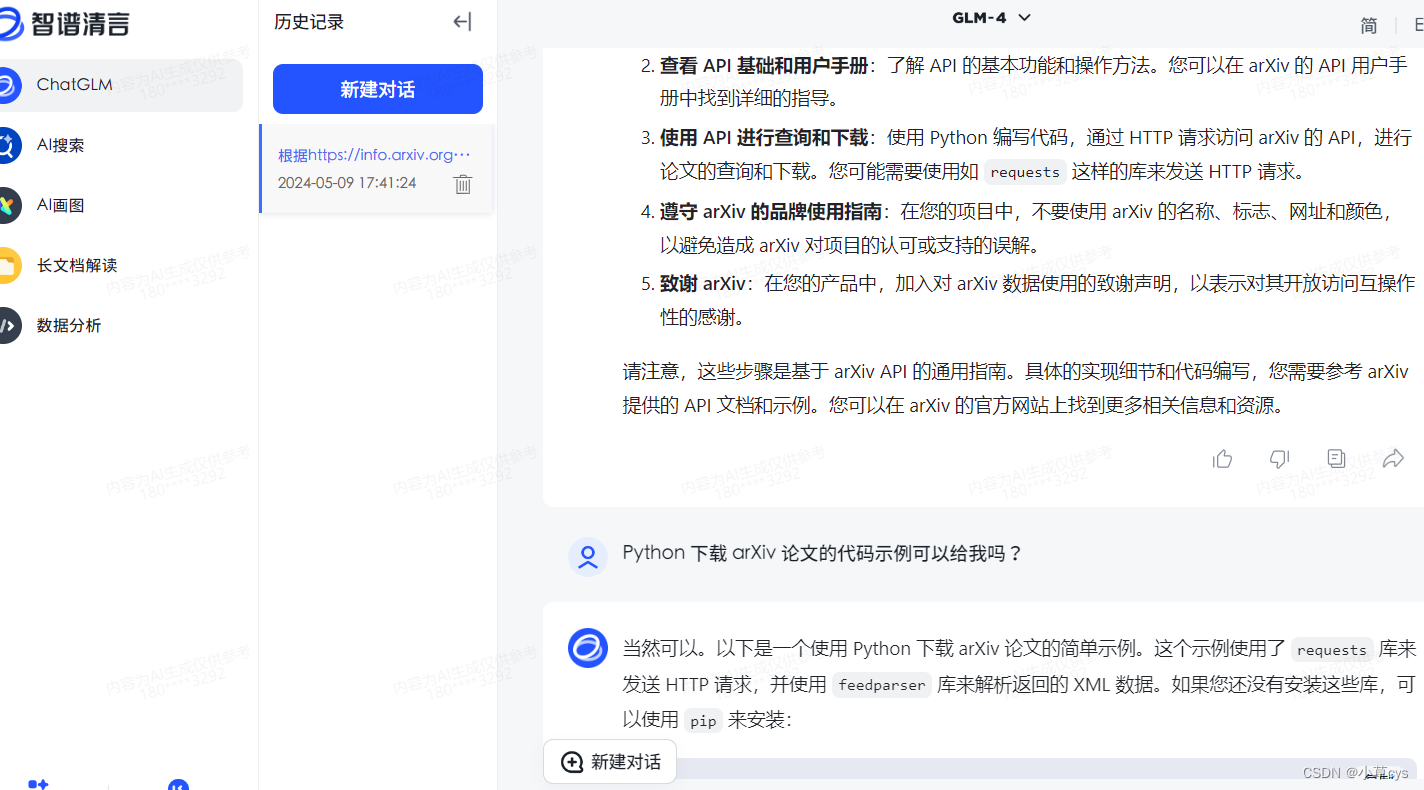
import requests
import feedparser
# 搜索arXiv API获取论文列表
search_query = "hep-th"
params = {'search_query': search_query, 'start': 0, 'max_results': 1}
response = requests.get('https://export.arxiv.org/api/query', params=params)
# 使用feedparser解析XML响应
feed = feedparser.parse(response.content)
# 从搜索结果中提取第一篇论文的PDF URL
pdf_url = feed.entries[0].links[1].href
# 下载PDF
pdf_response = requests.get(pdf_url, stream=True)
# 确保请求成功
if pdf_response.status_code == 200:
# 使用论文ID作为文件名
paper_id = feed.entries[0].id.split('/')[-1]
file_name = f"{paper_id}.pdf"
# 写入文件
with open(file_name, 'wb') as file:
for chunk in pdf_response.iter_content(chunk_size=128):
file.write(chunk)
print(f'Paper downloaded successfully as {file_name}.')
else:
print('Failed to download the paper.')
感觉是因为智谱清言可以读网址内容

但不是最新的文献,之后再看看怎么获取最新。
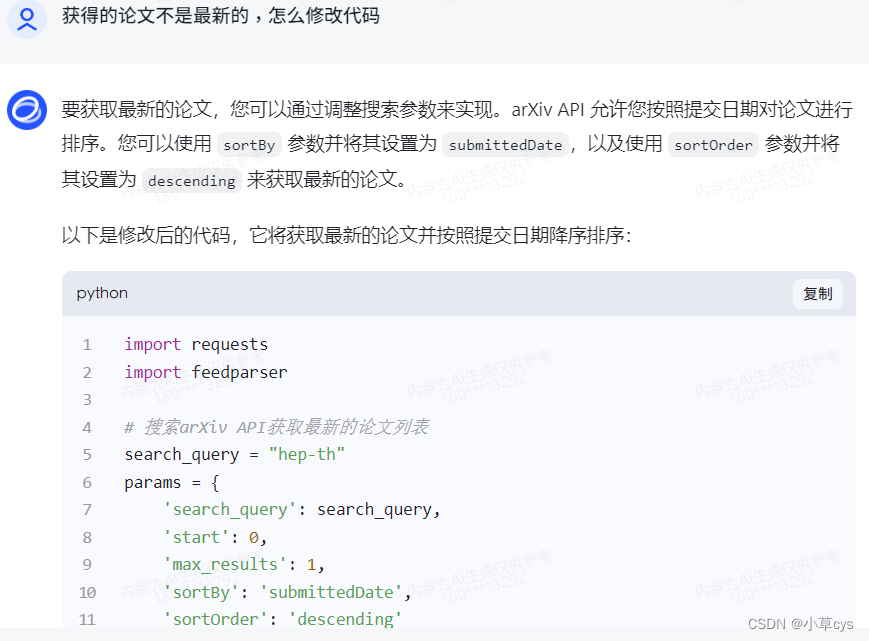
要在params加上:
'sortBy': 'submittedDate', 'sortOrder': 'descending'
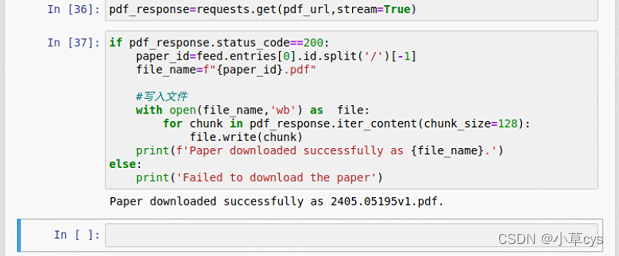
是新的文章了,但是跟关键词smart grid没啥关系,再看看有什么问题!
发现了一个问题,没有使用arxiv库,使用arxiv库得到下面的代码,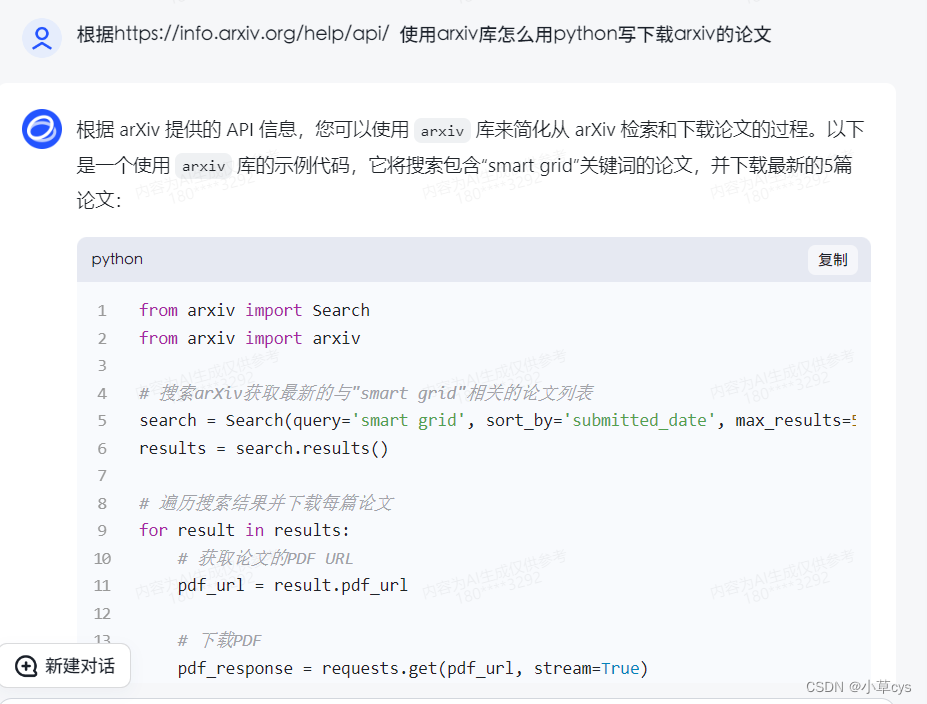
执行后发现,强制智谱清言使用arxiv库的话给有问题,可以看出并没有使用我提供网站对应的api,而是从大模型自己的认知记忆去给出的方案,还是不回去阅读网站并理解的!!!!
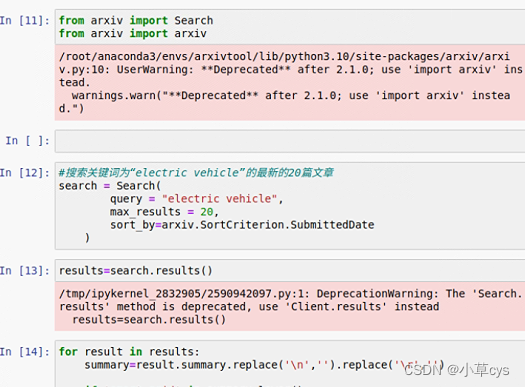
通义千问此问题效果不行,

arxiv.paper.Paper.from_id没有这个函数的,
综上处理这个问题时,智谱清言是给了一个能下到pdf的代码的,完成度很高,至于为什么跟搜索关键词不完全匹配,还需进一步排查
(由于url中不可出现空格)所以我是用electric vehicle的话,只搜索了electric
解决办法需要自己想一下,大模型没办法告诉你
search_query="all:electric AND all:vehicle"

真正执行后,下载了4篇之后就没了,我估计是被ban识别了,没有下载到10篇,所以sleep时间长一点,设置为半分钟试试!!
import requests
import feedparser
import time
# 搜索arXiv API获取最新的与"smart grid"相关的论文列表
search_query = "all:electric AND all:vehicle"
params = {
'search_query': search_query,
'start': 0,
'max_results': 10, # 下载最多10篇论文
'sortBy': 'submittedDate',
'sortOrder': 'descending'
}
response = requests.get('https://export.arxiv.org/api/query', params=params)
# 使用feedparser解析XML响应
feed = feedparser.parse(response.content)
# 遍历搜索结果并下载每篇论文
for entry in feed.entries:
pdf_url = entry.links[1].href # 获取PDF URL
# 下载PDF
pdf_response = requests.get(pdf_url, stream=True)
# 确保请求成功
if pdf_response.status_code == 200:
# 使用论文ID作为文件名
paper_id = entry.id.split('/')[-1]
file_name = f"{paper_id}.pdf"
# 写入文件
with open(file_name, 'wb') as file:
for chunk in pdf_response.iter_content(chunk_size=128):
file.write(chunk)
print(f'Paper downloaded successfully as {file_name}.')
else:
print(f'Failed to download the paper from {pdf_url}.')
# 在请求之间添加延迟
time.sleep(30) # 延迟5秒