官方的将pytorch转换为fabric简单分为五个步骤:
步骤 1:
在训练代码的开头创建 Fabric 对象
from lightning.fabric import Fabric
fabric = Fabric()步骤 2:
如果打算使用多个设备(例如多 GPU),就调用 launch()
fabric.launch()步骤 3:
在每个模型和优化器对上调用 setup() ,在所有数据加载器上调用 setup_dataloaders()
model, optimizer = fabric.setup(model, optimizer)
dataloader = fabric.setup_dataloaders(dataloader)步骤 4:
删除所有 .to 和 .cuda 调用,因为 Fabric 将自动处理
- model.to(device) # 删除
- batch.to(device) # 删除步骤 5:
将 loss.backward() 替换为 fabric.backward(loss)
- loss.backward()
+ fabric.backward(loss)结合起来:
将所有步骤结合起来,这就是代码将如何更改:
import torch
from lightning.pytorch.demos import WikiText2, Transformer
+ import lightning as L # 新增
- device = torch.device("cuda" if torch.cuda.is_available() else "cpu") # 删除
+ fabric = L.Fabric(accelerator="cuda", devices=8, strategy="ddp") # 新增
+ fabric.launch() # 新增
dataset = WikiText2()
dataloader = torch.utils.data.DataLoader(dataset)
model = Transformer(vocab_size=dataset.vocab_size)
optimizer = torch.optim.SGD(model.parameters(), lr=0.1)
- model = model.to(device) # 删除
+ model, optimizer = fabric.setup(model, optimizer) # 新增
+ dataloader = fabric.setup_dataloaders(dataloader) # 新增
model.train()
for epoch in range(20):
for batch in dataloader:
input, target = batch
- input, target = input.to(device), target.to(device) # 删除
optimizer.zero_grad()
output = model(input, target)
loss = torch.nn.functional.nll_loss(output, target.view(-1))
- loss.backward() # 删除
+ fabric.backward(loss) # 新增
optimizer.step()=======================================================================
记录一下自己代码的修改过程
训练的是DECA的修改版 (En生bs和lm(Wgan*0.01+dinov2))
主要需要将数据、模型、优化器、dataloader都放到fabric上
main_train.py中
导入lighting和Fabric并实例化,实例化的适合也可以加上【precision='32'】,float32位精度
from lightning import Fabric
import lightning as L
fabric = Fabric(accelerator="cuda",devices=None, strategy="ddp",precision='32')
fabric.launch()
# 这里的devices=None:这样就取决于命令行中CUDA_VISIBLE_DEVICES=的gpu名称
# precision='32'是使用32位精度其他参数可用内容:
fabric = Fabric()
fabric = Fabric(devices=2/4/8)
fabric = Fabric(devices=1/2/4/8/"auto", strategy="ddp"/"fspd"/"deepspeed"/"auto")在trainer实例化中也加入fabric参数:
# trainer = Trainer(model=deca, config=cfg, loss=loss, optimizer=optimizer)
trainer = Trainer(model=deca, config=cfg, loss=loss, optimizer=optimizer,fabric=fabric)deca.py中
1.导包+初始化fabric
这个import fabric就是上面实例化出来的fabric,我在trainer中又实例化了一下

2.去除原本的DP或者DDP,因为会冲突
注释了上面的DataParallel,使用fabric.setup对模型进行fabric操作
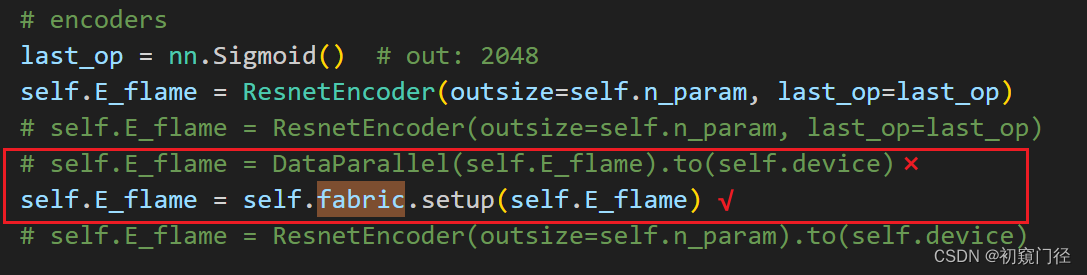 trainer.py中
trainer.py中
主要修改训练函数
1.我在这里又实例化了一遍
from lightning import Fabric
fabric = Fabric(accelerator="cuda",devices=None, strategy="ddp",precision='32')
fabric.launch()2.Trainer类中初始化时进行了添加
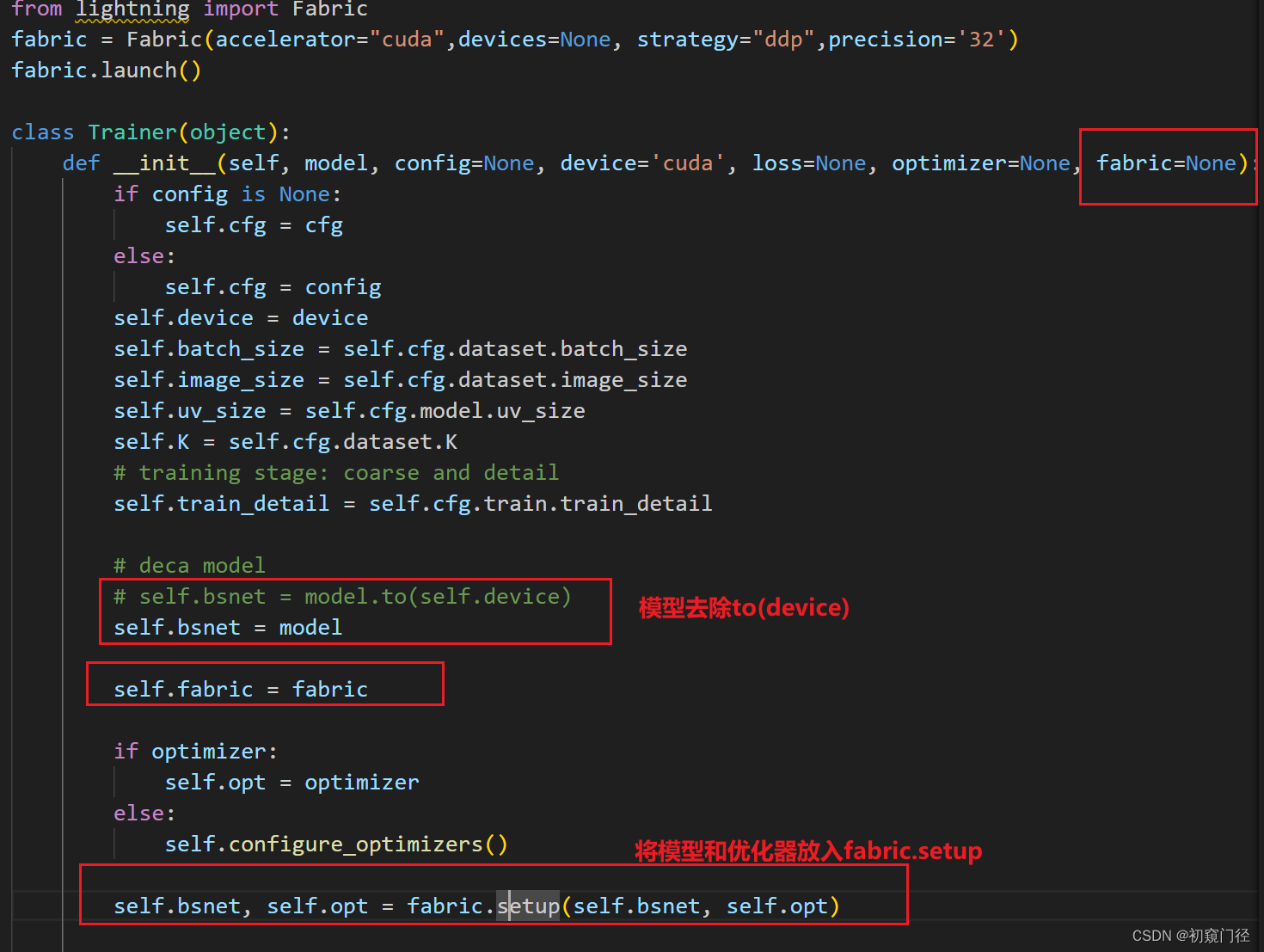
3.主要修改:training_step
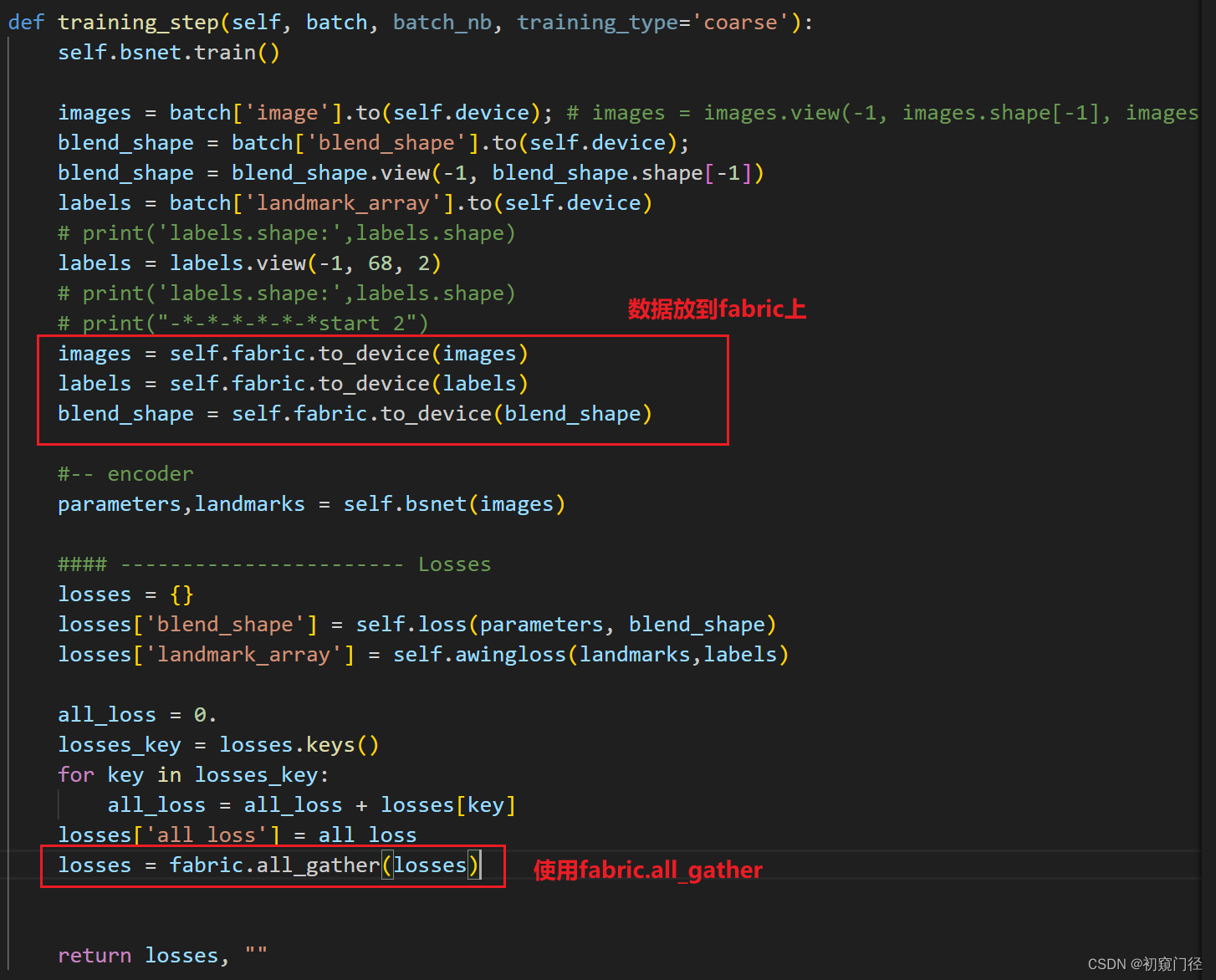 验证的话 也是这么修改
验证的话 也是这么修改
4.数据dataloader处理
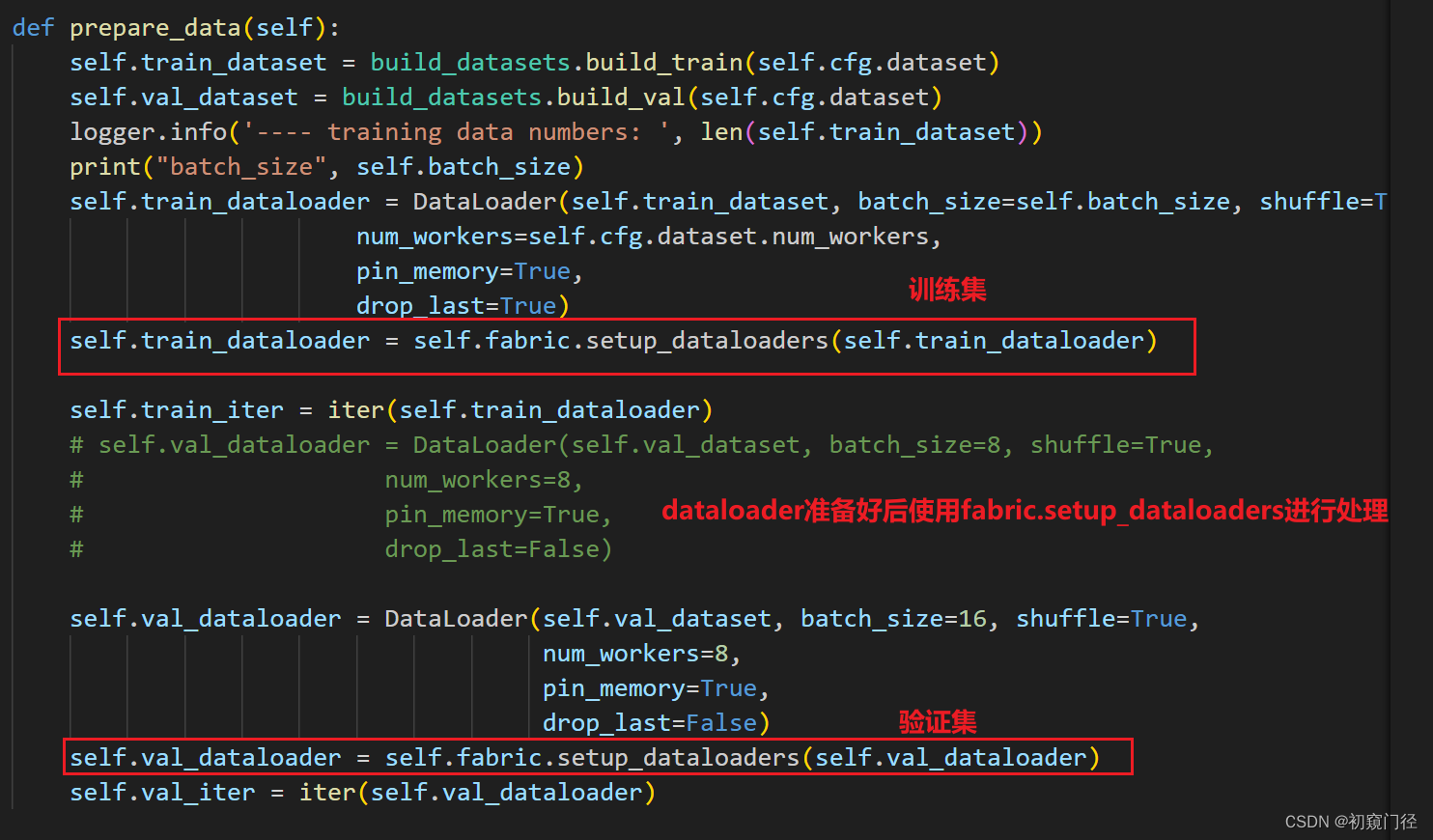
5.fit.py,关于tensorboard报错和打印损失变化
每个卡都有损失,tensorboard好像全局损失什么的,会产生冲突
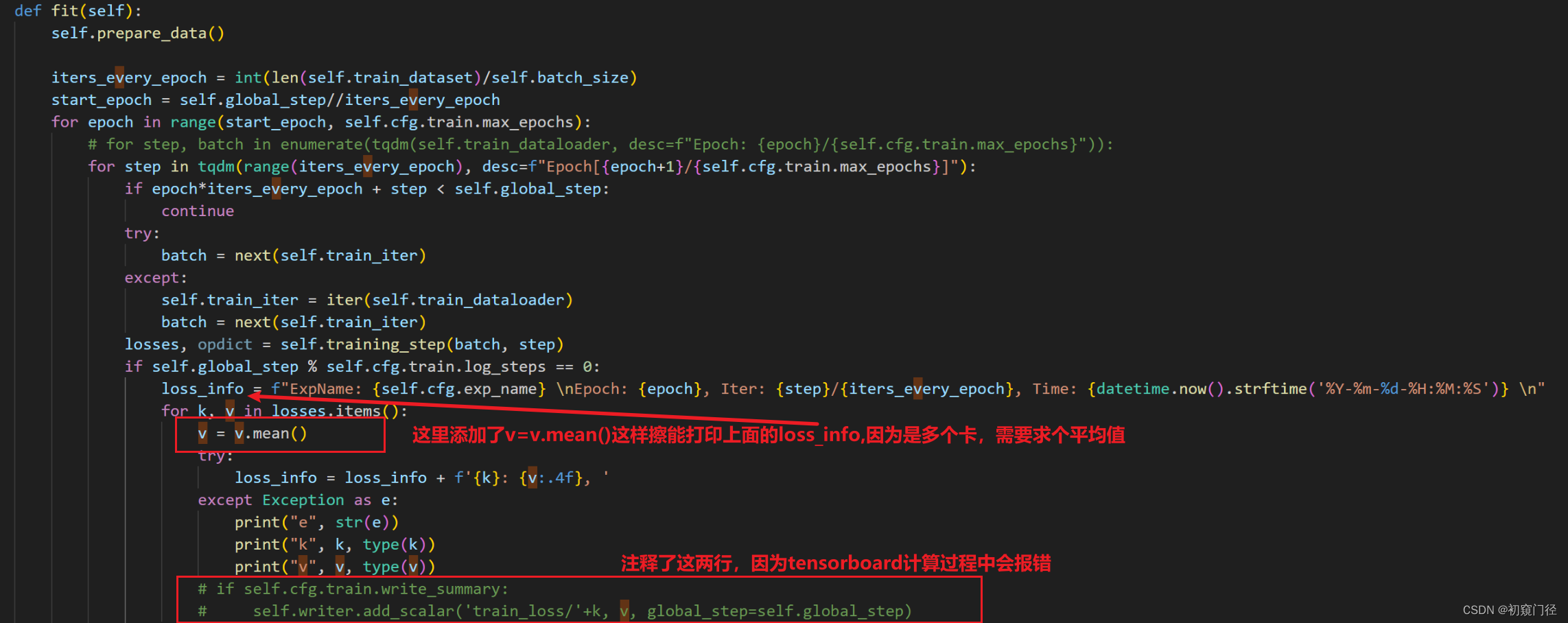
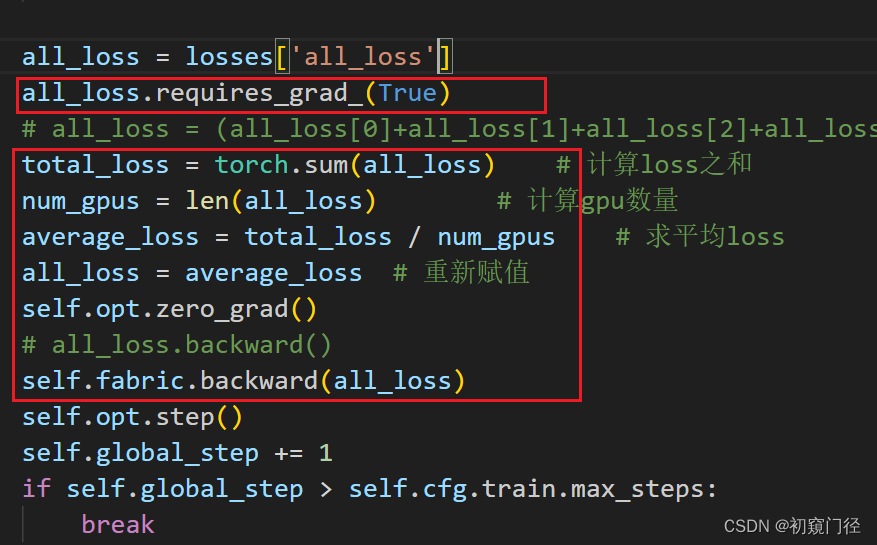
然后最后loss和backward修改
 然后就可以启动了CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 nohup python -u main_train.py --cfg configs/pretrain.yml > train.log 2>&1
然后就可以启动了CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 nohup python -u main_train.py --cfg configs/pretrain.yml > train.log 2>&1