每日温度
请根据每日 气温 列表,重新生成一个列表。对应位置的输出为:要想观测到更高的气温,至少需要等待的天数。如果气温在这之后都不会升高,请在该位置用 0 来代替。
例如,给定一个列表 temperatures = [73, 74, 75, 71, 69, 72, 76, 73],你的输出应该是 [1, 1, 4, 2, 1, 1, 0, 0]。
提示:气温 列表长度的范围是 [1, 30000]。每个气温的值的均为华氏度,都是在 [30, 100] 范围内的整数。
单调栈,其实就是栈内元素是单调递增或单调递减的栈;
通常是一维数组,要寻找任一个元素的右边或者左边第一个比自己大或者小的元素的位置,此时就要想到可以用单调栈了;
时间复杂度为O(n);
单调栈的本质是空间换时间,因为在遍历的过程中需要用一个栈来记录右边第一个比当前元素高的元素,优点是整个数组只需要遍历一次,就是用一个栈来记录遍历过的元素;
具体来说,单调栈在入栈时遵循单调原则,可以求出数组元素所能扩展到的最大长度(在栈中表现为 从栈头到栈底的顺序),但并不是指在这一段区间内是单调的,而是保证在该区间内该元素一定是最大或最小;
即:如果求一个元素右边第一个更大元素,单调栈就是递增的,如果求一个元素右边第一个更小元素,单调栈就是递减的;
对于此题来说,入栈的元素应该是元素下标本身;
使用单调栈主要有三个判断条件。
- 当前遍历的元素T[i]小于栈顶元素T[st.top()]的情况
- 当前遍历的元素T[i]等于栈顶元素T[st.top()]的情况
- 当前遍历的元素T[i]大于栈顶元素T[st.top()]的情况
把这三种情况分析清楚了,也就理解透彻了。
接下来用temperatures = [73, 74, 75, 71, 71, 72, 76, 73]为例来逐步分析,输出应该是 [1, 1, 4, 2, 1, 1, 0, 0]。
这是一个很巧妙的过程,非常完美地利用了栈的特性,举几个典例:
T[i] > T[st.top()]时
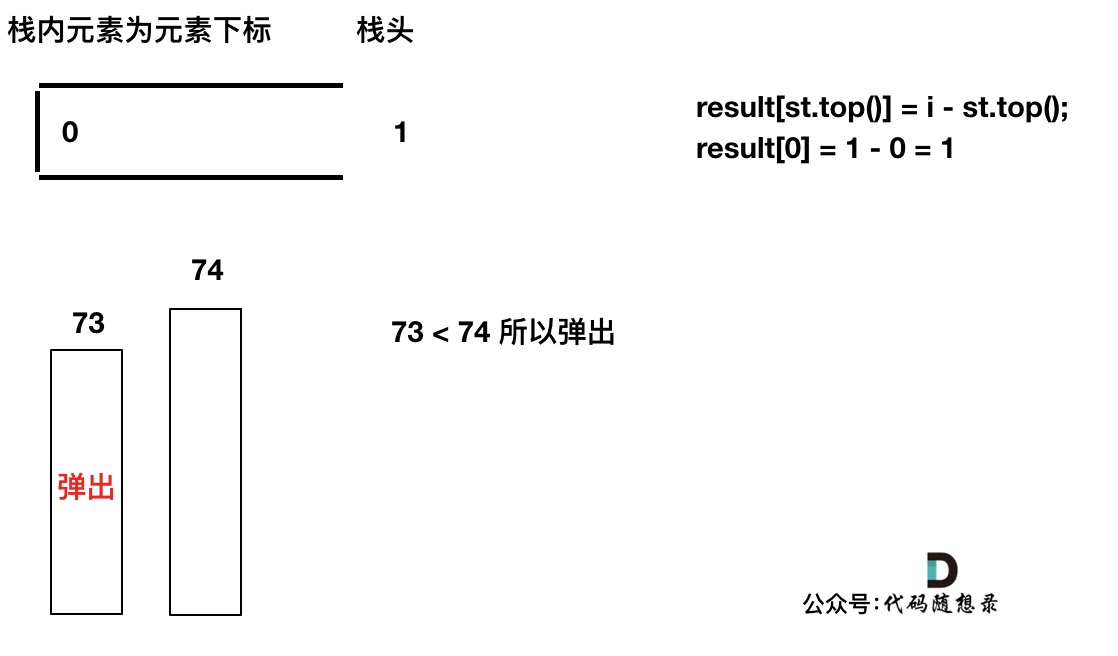
T[i] <= T[st.top()]时
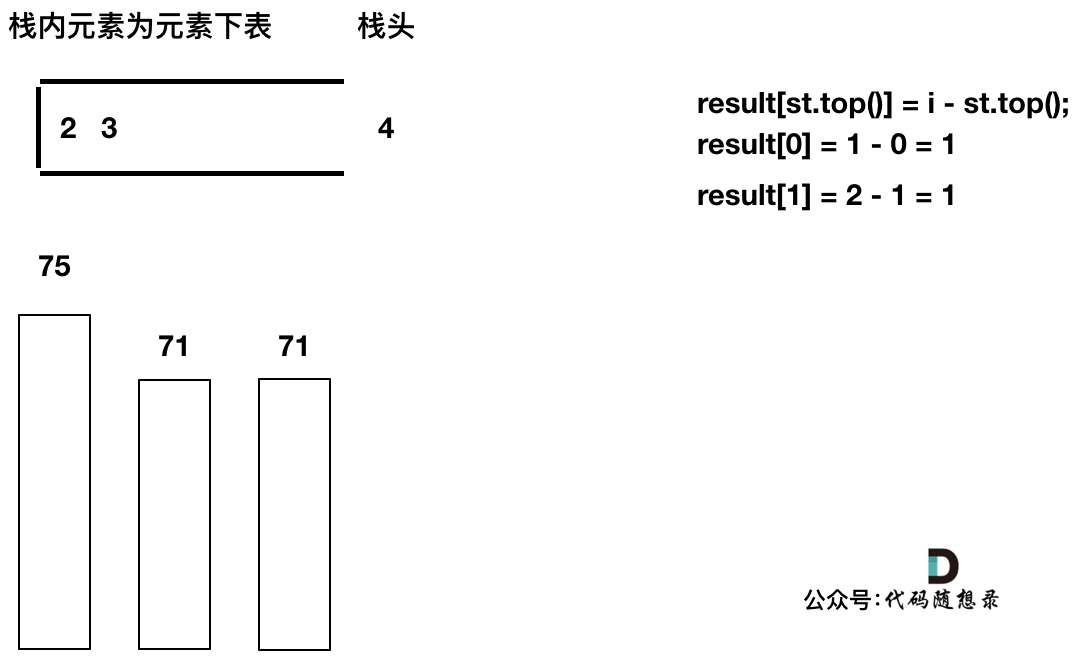
末端无法再出栈时
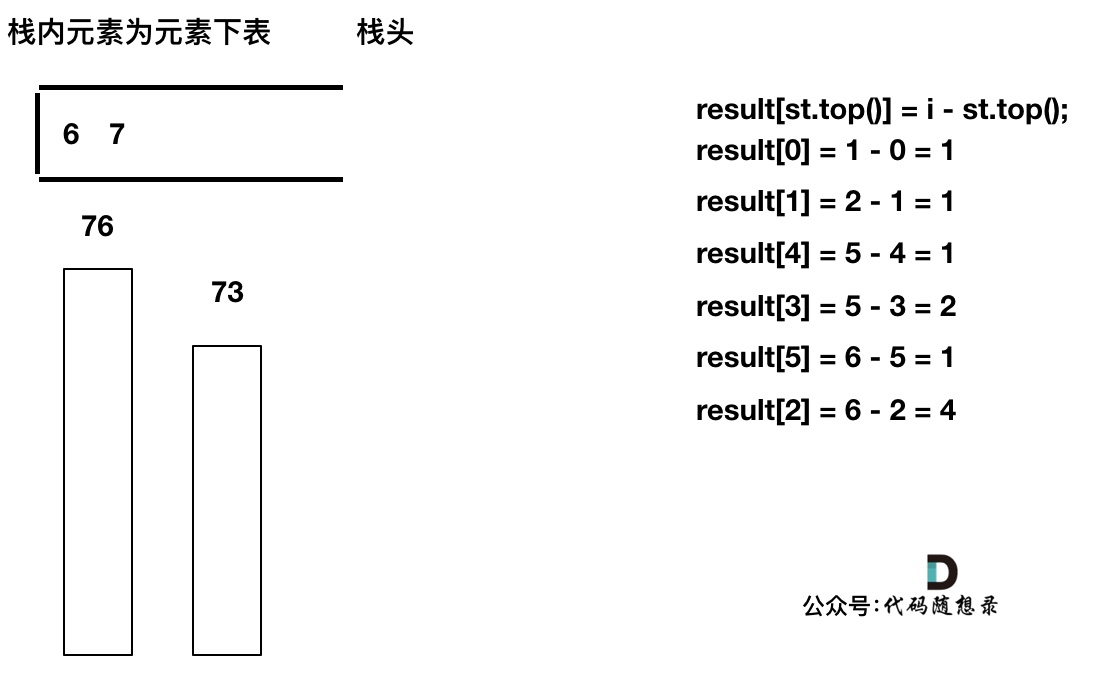
只有单调栈递增(从栈口到栈底顺序),就是求右边第一个比自己大的,单调栈递减的话,就是求右边第一个比自己小的;
整体代码如下
class Solution {
public:
vector<int> dailyTemperatures(vector<int>& T) {
// 递增栈
stack<int> st;
vector<int> result(T.size(), 0);//默认赋值为0,若最后栈里有元素没法操作,则默认为0
st.push(0);
// for (int i = 1; i < T.size(); i++) {
// if (T[i] < T[st.top()]) { // 情况一
// st.push(i);
// } else if (T[i] == T[st.top()]) { // 情况二
// st.push(i);
// } else {
// while (!st.empty() && T[i] > T[st.top()]) { // 情况三
// result[st.top()] = i - st.top();
// st.pop();
// }
// st.push(i);
// }
// }
for(int i = 0; i < T.size(); i++){
while(!(st.empty()) && T[i] > T[st.top()]){
result[st.top()] = i - st.top();
st.pop();
}
st.push(i);
}
return result;
}
};
下一个最大元素Ⅰ
给你两个 没有重复元素 的数组 nums1 和 nums2 ,其中nums1 是 nums2 的子集。
请你找出 nums1 中每个元素在 nums2 中的下一个比其大的值。
nums1 中数字 x 的下一个更大元素是指 x 在 nums2 中对应位置的右边的第一个比 x 大的元素。如果不存在,对应位置输出 -1 。
示例 1:
输入: nums1 = [4,1,2], nums2 = [1,3,4,2].
输出: [-1,3,-1]
解释:
对于 num1 中的数字 4 ,你无法在第二个数组中找到下一个更大的数字,因此输出 -1 。
对于 num1 中的数字 1 ,第二个数组中数字1右边的下一个较大数字是 3 。
对于 num1 中的数字 2 ,第二个数组中没有下一个更大的数字,因此输出 -1 。
示例 2:
输入: nums1 = [2,4], nums2 = [1,2,3,4].
输出: [3,-1]
解释:
对于 num1 中的数字 2 ,第二个数组中的下一个较大数字是 3 。
对于 num1 中的数字 4 ,第二个数组中没有下一个更大的数字,因此输出-1 。
提示:
- 1 <= nums1.length <= nums2.length <= 1000
- 0 <= nums1[i], nums2[i] <= 10^4
- nums1和nums2中所有整数 互不相同
- nums1 中的所有整数同样出现在 nums2 中
其实整体看上去和上题是一致的,就是加了一个双数组的限制;
由于返回的是一个数组,首先考虑定义的result数组的初始化:
vector<int> result(nums1.size(), -1);
由于此处需要在nums2里寻找对应的结果,所以单调栈应该遍历nums2;
至于在nums2中找到nums1的过程,这种情况使用一个map映射即可;
根据数值可快速找到下标,还可以判断nums2[i]是否在nums1中出现过;
unordered_map<int, int> umap;//<key, value>
for(int i = 0; i < nums1.size(); i++){
umap[nums[i]] = i;
}
和上题一样,遍历元素小于等于栈顶入栈,大于则出栈操作;
整体代码如下
class Solution {
public:
vector<int> nextGreaterElement(vector<int>& nums1, vector<int>& nums2) {
stack<int> st;
vector<int> result(nums1.size(), -1);
unordered_map<int, int> umap;//<key, value>
for(int i = 0; i < nums1.size(); i++){
umap[nums1[i]] = i;
}
st.push(0);
for(int i = 0; i < nums2.size(); i++){
while(!(st.empty()) && nums2[i] > nums2[st.top()]){
if(umap.count(nums2[st.top()])){
//需要注意的是,虽然 count() 函数对于 std::unordered_map 来说总是返回0或1;
//但这个函数在 std::map 和 std::multimap 这样的关联容器中是有区别的;
//在 std::map 中,count() 的行为与 std::unordered_map 相同(因为键也是唯一的);
//但在 std::multimap 中,由于允许重复的键,count() 函数会返回与给定键相关联的元素数量;
int index = umap[nums2[st.top()]];
result[index] = nums2[i];
}
st.pop();
}
st.push(i);
}
return result;
}
};