https://zhuanlan.zhihu.com/p/602305591
https://zhuanlan.zhihu.com/p/178402798
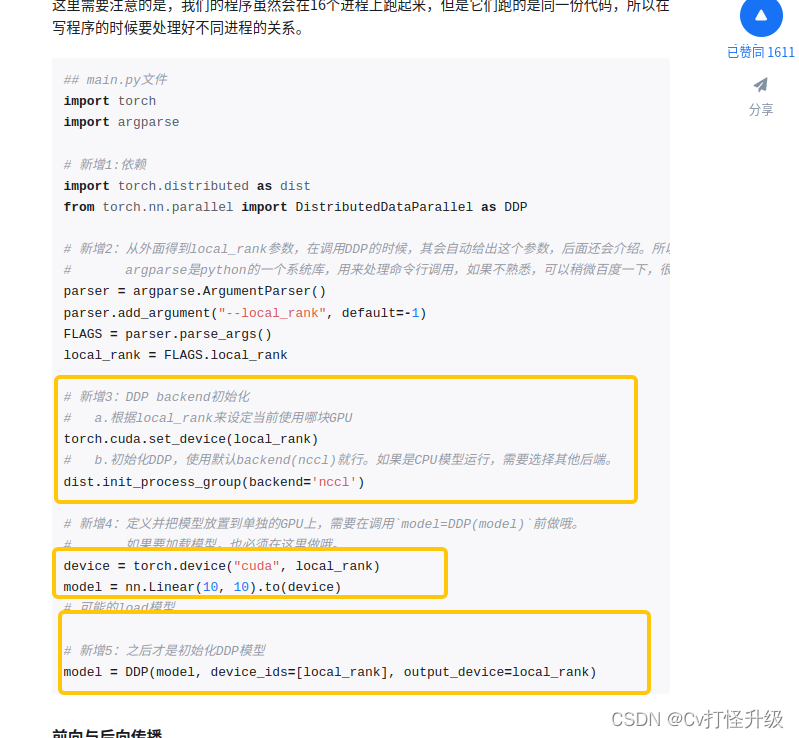
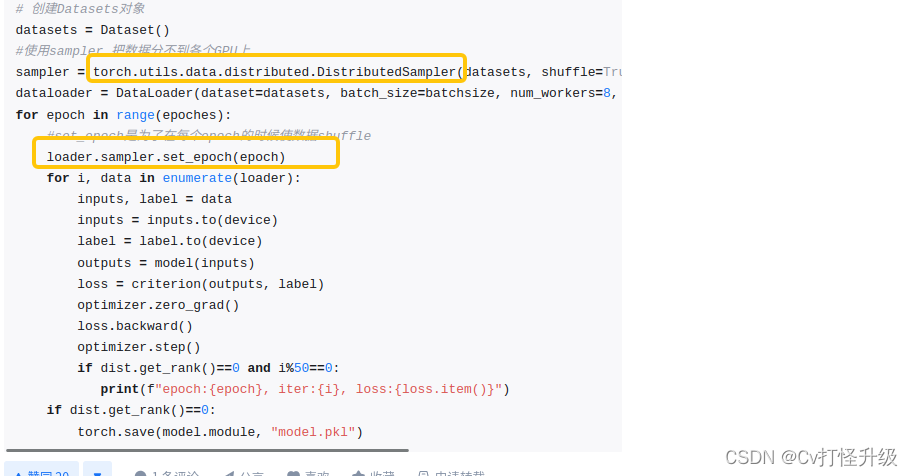
关于模型保存与加载 : 其实分为保存 有module和无module2种 ; (上面知乎这篇文章说带时带module)
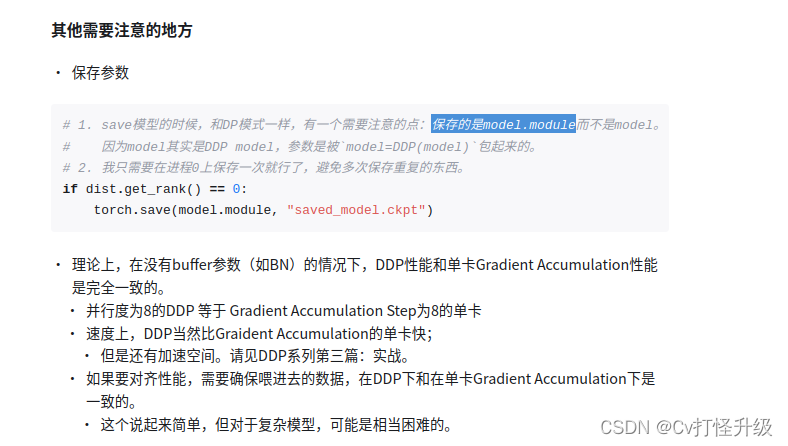
关于2种带与不带的说明:
https://blog.csdn.net/hustwayne/article/details/120324639
在project中, 是不带module的, 然后加载预训练权重,会remove一些key; 后期改为mmcv中的load_checkpoint自适应匹配kye-value;
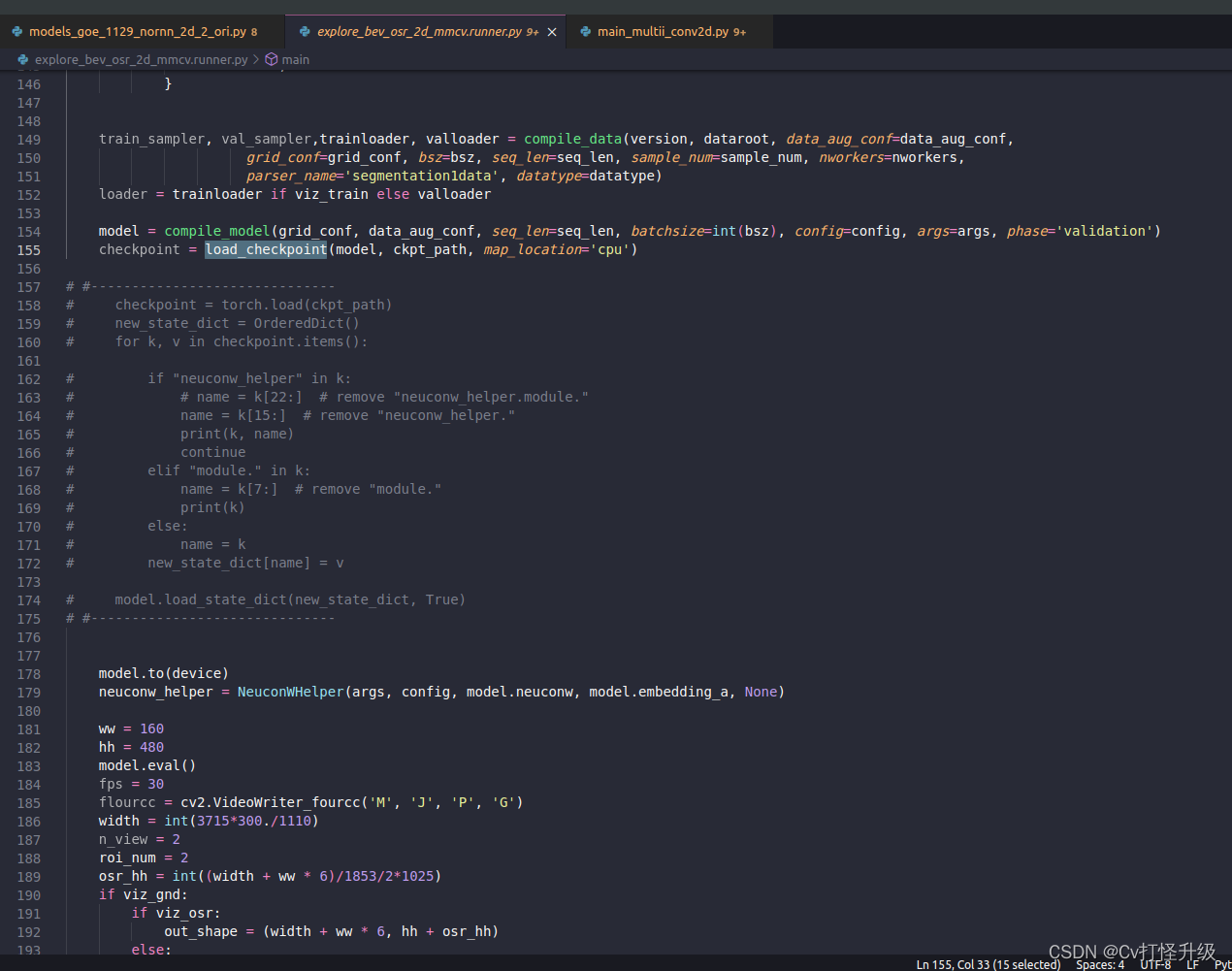
老模型main.py DDP示例
"""
Copyright (C) 2020 NVIDIA Corporation. All rights reserved.
Licensed under the NVIDIA Source Code License. See LICENSE at https://github.com/nv-tlabs/lift-splat-shoot.
Authors: Jonah Philion and Sanja Fidler
"""
import warnings
warnings.filterwarnings("error", "MAGMA*")
from fire import Fire
import argparse
import torch
import src
import os
"""
Copyright (C) 2020 NVIDIA Corporation. All rights reserved.
Licensed under the NVIDIA Source Code License. See LICENSE at https://github.com/nv-tlabs/lift-splat-shoot.
Authors: Jonah Philion and Sanja Fidler
"""
import os
import numpy as np
from time import time
from torch import nn
from src.models_goe_1129_nornn_2d_2_ori import compile_model
# from src.models_goe_1129_nornn_2d_2_zj import compile_model
from tensorboardX import SummaryWriter
from src.data_tfmap_newcxy_nextmask2 import compile_data # 当前帧拼接帧都加超界点
# from src.data_tfmap_newcxy_ori import compile_data # 不加超界点
#from src.data_tfmap import compile_data
from src.tools import SimpleLoss, RegLoss, SegLoss, SegLoss, BCEFocalLoss, get_batch_iou, get_val_info, denormalize_img, SimpleLoss
import sys
import cv2
from collections import OrderedDict
from src.config.defaults import get_cfg_defaults
from src.options import get_opts
from src.rendering.neuconw_helper import NeuconWHelper
import open3d as o3d
os.environ["CUDA_VISIBLE_DEVICES"] = "0, 1"
os.environ['LOCAL_RANK'] = "0,1"
torch.set_num_threads(8)
# os.environ["CUDA_VISIBLE_DEVICES"] = "4"
# os.environ['RANK'] = "0"
# os.environ['WORLD_SIZE'] = "1"
# os.environ['MASTER_ADDR'] = "localhost"
# os.environ['MASTER_PORT'] = "12345"
# os.environ['CUDA_LAUNCH_BLOCKING'] = '1'
"动静态分离里, 构造sample时rays要加一个type的维度"
import argparse
def project_from_lidar_2_cam(img, points, rots, trans, intrins, post_rots, post_trans):
color_arr = np.zeros((points.shape[0], 3))
# ego_to_cam
points -= trans
points = torch.inverse(rots.view(1, 3, 3)).matmul(points.unsqueeze(-1)).squeeze(-1)
depths = points[..., 2:]
points = torch.cat((points[..., :2] / depths, torch.ones_like(depths)), -1)
# cam_to_img
points = intrins.view(1, 3, 3).matmul(points.unsqueeze(-1)).squeeze(-1)
points = post_rots.view(1, 3, 3).matmul(points.unsqueeze(-1)).squeeze(-1)
points = points + post_trans.view(1, 3)
# points = points.view(B, N, Z, Y, X, 3)[..., :2]
points = points.view(-1, 3).int().numpy()
# imshow
# pts = points[0,0,2,...].reshape(-1, 2).cpu().numpy()
# image = np.zeros((128, 352, 3), dtype=np.uint8)
# for i in range(pts.shape[0]):
# cv2.circle(image, (int(pts[i, 0]), int(pts[i, 1])), 1, (255, 255, 255), 2)
# cv2.imshow("local_map", image)
# cv2.waitKey(-1)
# normalize_coord
img = np.array(img)
# for i in range(points.shape[0]):
# cv2.circle(img, (points[i,0], points[i,1]), 1, tuple(color_arr[i].tolist()), -1)
return img
def main():
# parser = argparse.ArgumentParser()
# parser.add_argument("--local_rank", default = 0, type=int)
# args = parser.parse_args()
args = get_opts()
config = get_cfg_defaults()
config.merge_from_file(args.cfg_path)
print(config)
# args.local_rank = 2
print("sssss",args.local_rank)
# 新增3:DDP backend初始化
# a.根据local_rank来设定当前使用哪块GPU
# b.初始化DDP,使用默认backend(nccl)就行。如果是CPU模型运行,需要选择其他后端。
if args.local_rank != -1:
torch.cuda.set_device(args.local_rank)
device=torch.device("cuda", args.local_rank)
torch.distributed.init_process_group(backend="nccl", init_method='env://')
version = "0"
#dataroot = "/defaultShare/aishare/share"
dataroot = "/data/zjj/data/aishare/share"
nepochs=10000
final_dim=(128, 352)
max_grad_norm=5.0
#max_grad_norm=2.0
pos_weight=2.13
logdir=f'/mnt/sdb/xzq/occ_project/occ_nerf_st/log/{args.exp_name}'
xbound=[0.0, 102., 0.85]
ybound=[-10.0, 10.0, 0.5]
zbound=[-2.0, 4.0, 1]
dbound=[3.0, 103.0, 2.]
# xbound=[0.0, 96., 0.5]
# ybound=[-12.0, 12.0, 0.5]
# zbound=[-2.0, 4.0, 1]
# dbound=[3.0, 103.0, 2.]
bsz=4
seq_len=5 #5
nworkers=1 #2
lr=1e-4
# weight_decay=1e-7
weight_decay = 0
sample_num = 1024
datatype = "single" #multi single
torch.backends.cudnn.benchmark = True
grid_conf = {
'xbound': xbound,
'ybound': ybound,
'zbound': zbound,
'dbound': dbound,
}
### bevgnd
data_aug_conf = {
'resize_lim': [(0.05, 0.4), (0.3, 0.90)],#(0.3-0.9)
'final_dim': (128, 352),
'rot_lim': (-5.4, 5.4),
# 'H': H, 'W': W,
'rand_flip': False,
'bot_pct_lim': [(0.04, 0.35), (0.15, 0.4)],
'cams': ['CAM_FRONT0', 'CAM_FRONT1'],
'Ncams': 2,
}
train_sampler, val_sampler, trainloader, valloader = compile_data(version, dataroot, data_aug_conf=data_aug_conf,
grid_conf=grid_conf, bsz=bsz, seq_len=seq_len, sample_num=sample_num, nworkers=nworkers,
parser_name='segmentationdata', datatype=datatype)
print("train lengths: ", len(trainloader))
# print("val lengths: ", len(valloader))
# device = torch.device('cpu') if gpuid < 0 else torch.device(f'cuda:{gpuid}')
writer = SummaryWriter(logdir=logdir)
model = compile_model(grid_conf, data_aug_conf, seq_len=seq_len, batchsize=int(bsz), config=config, args=args, writer=writer)
counter = 0
if 0:
print('==> loading existing model')
model_info = torch.load('/data/zjj/project/bev_osr_distort_multi_addtime_nornn_align_h5_nerf_multi2/checkpoints/models_20231113_nornn_120_21_6_b2_lall_sample1024_v1/checkpts/model_30000.pt')
# model_info = torch.load('/zhangjingjuan/NeRF/bev_osr_distort_multi_addtime_nornn_align_h5_nerf_multi2/checkpoints/models_20231114_nornn_v2/checkpts/model_50000.pt')
#model_info = torch.load('/data/zjj/bev_osr_distort_multi_addtime_nornn_align_h5_nerf_multi2/checkpoints/models_20231120_nornn_v1/checkpts/model_18000.pt')
counter = 0
new_state_dict = OrderedDict()
for k, v in model_info.items():
if 'semantic_net' in k:
continue
# if 'SEnet' in k or 'voxels' in k or 'bevencode.downchannel' in k or 'bevencode.up3' in k or 'bevencode.conv1_block' in k:
# continue
# if 'voxels' in k:
# continue
# if 'color_net' in k:
# continue
if "neuconw_helper" in k:
name = k[22:]
elif "module." in k:
name = k[7:] # remove "module."
#print(k)
else:
name = k
'''
if "module." in k:
name = k[7:] # remove "module."
else:
name = k
'''
new_state_dict[name] = v
model.load_state_dict(new_state_dict, strict=False)
model.dx.data = torch.tensor([0.85, 0.5, 1.0]).to(device)
# model.dx.data = torch.tensor([0.5, 0.5, 0.5]).to(device)
# model.nx.data = torch.tensor([204, 40, 12]).to(device)
# model.bx.data = torch.tensor([0.25, -9.75, -1.75]).to(device)
# 封装之前要把模型移到对应的gpu
model.to(device)
neuconw_helper = NeuconWHelper(args, config, model.neuconw, model.embedding_a, writer)
# DDP封装
num_gpus = torch.cuda.device_count()
if num_gpus > 1:
model = nn.parallel.DistributedDataParallel(model, device_ids=[args.local_rank],
output_device=args.local_rank,find_unused_parameters=True)
opt = torch.optim.Adam(model.parameters(), lr=lr, weight_decay=weight_decay)
# opt = torch.optim.SGD(model.parameters(), lr=lr, weight_decay=weight_decay)
loss_fn = SegLoss(pos_weight).cuda(args.local_rank)
loss_fn_ll = SegLoss(pos_weight).cuda(args.local_rank)
loss_fn_sl = SegLoss(pos_weight).cuda(args.local_rank)
loss_fn_zc = SegLoss(pos_weight).cuda(args.local_rank)
loss_fn_ar = SegLoss(pos_weight).cuda(args.local_rank)
loss_fn_rs = SegLoss(pos_weight).cuda(args.local_rank)
loss_fn_cl = SimpleLoss(pos_weight).cuda(args.local_rank)
loss_fn_lf_pred = SimpleLoss(pos_weight).cuda(args.local_rank)
loss_fn_lf_norm = RegLoss(0).cuda(args.local_rank)
# loss_fn_patch = SimpleLoss(pos_weight).cuda(args.local_rank)
val_step = 1000
t1 = time()
t2 = time()
model.train()
scaler = torch.cuda.amp.GradScaler()
train_bev = False # False
train_occ = True
for epoch in range(nepochs):
np.random.seed()
train_sampler.set_epoch(epoch)
start = time()
for batchi, (imgs, rots, trans, intrins, dist_coeffss, post_rots, post_trans, cam_pos_embeddings, binimgs, lf_label_gt, lf_norm_gt, fork_scales_gt, fork_offsets_gt, fork_oris_gt, rays, theta_mat_2d, theta_mat_3d) in enumerate(trainloader):
t0 = time()
t = t0 - t1
tt = t0 - t2
t1 = time()
# print("img_path = ", img_paths[-1][0])
if 1:
seg_preds1, seg_preds2, lf_preds, _, _ , loss_osr = model(imgs.to(device), rots.to(device), trans.to(device), intrins.to(device), dist_coeffss.to(device), post_rots.to(device),
post_trans.to(device), cam_pos_embeddings.to(device), fork_scales_gt.to(device),fork_offsets_gt.to(device),fork_oris_gt.to(device), rays.to(device), theta_mat_2d.to(device), counter, 'train')
if train_bev:
lf_pred = lf_preds[:, :, :1].contiguous()
lf_norm = lf_preds[:, :, 1:(1+4)].contiguous()
# lf_kappa = lf_preds[:, :, (1+4):(1+4+2)].contiguous()
lf_out = lf_pred.sigmoid()
out = seg_preds1.sigmoid()
out1 = seg_preds2.sigmoid()
binimgs = binimgs.to(device)
seg_preds_0 = seg_preds1[:, :, 0] * mask_gt[:, :, 0] + (-1) * (1 - mask_gt[:, :, 0])
binimgs0 = binimgs[:, :, 0] * mask_gt[:, :, 0] + (-1) * (1 - mask_gt[:, :, 0])
seg_preds_1 = seg_preds1[:, :, 1] * mask_gt[:, :, 0] + (-1) * (1 - mask_gt[:, :, 0])
binimgs1 = binimgs[:, :, 1] * mask_gt[:, :, 0] + (-1) * (1 - mask_gt[:, :, 0])
seg_preds_2 = seg_preds1[:, :, 2] * mask_gt[:, :, 0] + (-1) * (1 - mask_gt[:, :, 0])
binimgs2 = binimgs[:, :, 2] * mask_gt[:, :, 0] + (-1) * (1 - mask_gt[:, :, 0])
seg_preds_3 = seg_preds2[:, :, 0] * mask_gt[:, :, 0] + (-1) * (1 - mask_gt[:, :, 0])
binimgs3 = binimgs[:, :, 3] * mask_gt[:, :, 0] + (-1) * (1 - mask_gt[:, :, 0])
seg_preds_4 = seg_preds1[:, :, 3] * mask_gt[:, :, 0] + (-1) * (1 - mask_gt[:, :, 0])
binimgs4 = binimgs[:, :, 4] * mask_gt[:, :, 0] + (-1) * (1 - mask_gt[:, :, 0])
seg_preds_5 = seg_preds1[:, :, 4] * mask_gt[:, :, 0] + (-1) * (1 - mask_gt[:, :, 0])
binimgs5 = binimgs[:, :, 5] * mask_gt[:, :, 0] + (-1) * (1 - mask_gt[:, :, 0])
loss_ll = loss_fn_ll(seg_preds1[:, :, 0].contiguous(), binimgs[:, :, 0].contiguous()) + loss_fn_ll(
seg_preds_0.contiguous(), binimgs0.contiguous())
loss_sl = loss_fn_sl(seg_preds1[:, :, 1].contiguous(), binimgs[:, :, 1].contiguous()) + loss_fn_sl(
seg_preds_1.contiguous(), binimgs1.contiguous())
loss_zc = loss_fn_zc(seg_preds1[:, :, 2].contiguous(), binimgs[:, :, 2].contiguous()) + loss_fn_zc(
seg_preds_2.contiguous(), binimgs2.contiguous())
loss_ar = loss_fn_ar(seg_preds2[:, :, 0].contiguous(), binimgs[:, :, 3].contiguous()) + loss_fn_ar(
seg_preds_3.contiguous(), binimgs3.contiguous())
loss_rs = loss_fn_rs(seg_preds1[:, :, 3].contiguous(), binimgs[:, :, 4].contiguous()) + loss_fn_rs(
seg_preds_4.contiguous(), binimgs4.contiguous())
loss_cl = loss_fn_cl(seg_preds1[:, :, 4].contiguous(), binimgs[:, :, 5].contiguous()) + loss_fn_cl(
seg_preds_5.contiguous(), binimgs5.contiguous())
# lf_norm_gt0 = torch.unsqueeze(torch.sum(lf_norm_gt, 2), 2)
norm_mask = (lf_norm_gt > -500)
# norm_mask = ((lf_label_gt>-0.5)).repeat(1, 1, 4, 1, 1)
scale_lf = 5.
loss_lf = loss_fn_lf_pred(lf_pred, lf_label_gt.to(device)) + loss_fn_lf_norm(lf_norm[norm_mask], scale_lf*lf_norm_gt[norm_mask].to(device))
# loss_ilf = loss_fn_lf_pred(lf_ipred, lf_label_gt.to(device)) + loss_fn_lf_norm(scale_lf*lf_inorm[norm_mask], scale_lf*lf_norm_gt[norm_mask].to(device))
# loss_lf_crop = loss_fn_patch(lf_crop_preds, fork_patch_gt.to(device))
# print('lf_loss = ', loss_lf)
loss_gnd = loss_lf + loss_ll + loss_sl + loss_zc + loss_ar + loss_rs + loss_cl# + loss_ilf
# loss = loss_ll + loss_sl + loss_zc + loss_ar + loss_rs + loss_cl
if train_occ:
# loss = loss_gnd + loss_osr
loss = loss_osr
#loss = loss_gnd
opt.zero_grad()
# scaler.scale(loss).backward()
loss.backward()
clip_debug = torch.nn.utils.clip_grad_norm_(model.parameters(), max_grad_norm)
opt.step()
# except:
# continue
# scaler.step(opt)
# scaler.update()
t2 = time()
writer.add_scalar('train/clip_debug', clip_debug.item(), counter)
if counter % 10 == 0 and args.local_rank==0:
print(counter, loss.item(), time() - start)
if train_bev:
if counter % 10 == 0 and args.local_rank==0:
# print(loss_lf.item(), loss_ll.item(), loss_sl.item(), loss_zc.item(), loss_ar.item(), loss_rs.item(), loss_cl.item())
# print(counter, loss.item(), loss_gnd.item(), loss_osr.item(), time() - start)
# print(counter, loss.item(), time() - start)
writer.add_scalar('train/loss', loss, counter)
writer.add_scalar('train/loss_ll', loss_ll, counter)
writer.add_scalar('train/loss_sl', loss_sl, counter)
writer.add_scalar('train/loss_zc', loss_zc, counter)
writer.add_scalar('train/loss_ar', loss_ar, counter)
writer.add_scalar('train/loss_rs', loss_rs, counter)
writer.add_scalar('train/loss_cl', loss_cl, counter)
writer.add_scalar('train/loss_lf', loss_lf, counter)
# writer.add_scalar('train/loss_lf_crop', loss_lf_crop, counter)
writer.add_scalar('train/loss_gnd', loss_gnd, counter)
writer.add_scalar('train/loss_osr', loss_osr, counter)
writer.add_scalar('train/clip_debug', clip_debug.item(), counter)
if counter % 50 == 0 and args.local_rank==0:
_, _, iou_ll = get_batch_iou(seg_preds1[:, :, 0].contiguous(), binimgs[:, :, 0].contiguous())
_, _, iou_sl = get_batch_iou(seg_preds1[:, :, 1].contiguous(), binimgs[:, :, 1].contiguous())
_, _, iou_zc = get_batch_iou(seg_preds1[:, :, 2].contiguous(), binimgs[:, :, 2].contiguous())
_, _, iou_ar = get_batch_iou(seg_preds2[:, :, 0].contiguous(), binimgs[:, :, 3].contiguous())
_, _, iou_rs = get_batch_iou(seg_preds1[:, :, 3].contiguous(), binimgs[:, :, 4].contiguous())
_, _, iou_cl = get_batch_iou(seg_preds1[:, :, 4].contiguous(), binimgs[:, :, 5].contiguous())
writer.add_scalar('train/iou_ll', iou_ll, counter)
writer.add_scalar('train/iou_sl', iou_sl, counter)
writer.add_scalar('train/iou_zc', iou_zc, counter)
writer.add_scalar('train/iou_ar', iou_ar, counter)
writer.add_scalar('train/iou_rs', iou_rs, counter)
writer.add_scalar('train/iou_cl', iou_cl, counter)
writer.add_scalar('train/epoch', epoch, counter)
writer.add_scalar('train/step_time', t, counter)
writer.add_scalar('train/data_time', tt, counter)
if counter % 200 == 0 and args.local_rank==0:
fH = final_dim[0]
fW = final_dim[1]
image0 =np.array(denormalize_img(imgs[0, 0]))
image1 =np.array(denormalize_img(imgs[0, 1]))
# image2 =np.array(denormalize_img(imgs[0, 2]))
# image3 =np.array(denormalize_img(imgs[0, 3]))
writer.add_image('train/image/00', image0, global_step=counter, dataformats='HWC')
writer.add_image('train/image/01', image1, global_step=counter, dataformats='HWC')
# writer.add_image('train/image/02', image2, global_step=counter, dataformats='HWC')
# writer.add_image('train/image/03', image3, global_step=counter, dataformats='HWC')
writer.add_image('train/binimg/0', (binimgs[0, 1, 0:1]+1.)/2.01, global_step=counter)
writer.add_image('train/binimg/1', (binimgs[0, 1, 1:2]+1.)/2.01, global_step=counter)
writer.add_image('train/binimg/2', (binimgs[0, 1, 2:3]+1.)/2.01, global_step=counter)
writer.add_image('train/binimg/3', (binimgs[0, 1, 3:4]+1.)/2.01, global_step=counter)
writer.add_image('train/binimg/4', (binimgs[0, 1, 4:5]+1.)/2.01, global_step=counter)
writer.add_image('train/binimg/5', (binimgs[0, 1, 5:6]+1.)/2.01, global_step=counter)
writer.add_image('train/out/0', out[0, 1, 0:1], global_step=counter)
writer.add_image('train/out/1', out[0, 1, 1:2], global_step=counter)
writer.add_image('train/out/2', out[0, 1, 2:3], global_step=counter)
writer.add_image('train/out/3', out1[0, 1, 0:1], global_step=counter)
writer.add_image('train/out/4', out[0, 1, 3:4], global_step=counter)
writer.add_image('train/out/5', out[0, 1, 4:5], global_step=counter)
writer.add_image('train/lf_label_gt/0', (lf_label_gt[0, 1]+1.)/2.01, global_step=counter)
writer.add_image('train/lf_out/0', lf_out[0, 1], global_step=counter)
# writer.add_image('train/fork_patch/0', (fork_patch_gt[0, 1, 0:1]+1.)/2.01, global_step=counter)
# writer.add_image('train/fork_patch/1', (fork_patch_gt[0, 1, 1:2]+1.)/2.01, global_step=counter)
# writer.add_image('train/lf_crop_out/0', lf_crop_out[0, 1, 0:1], global_step=counter)
# writer.add_image('train/lf_crop_out/1', lf_crop_out[0, 1, 1:2], global_step=counter)
seg_ll_data = binimgs[0, 1, 0].cpu().detach().numpy()
seg_cl_data = binimgs[0, 1, 5].cpu().detach().numpy()
lf_label_data_gt = lf_label_gt[0, 1, 0].numpy()
lf_norm_data_gt = lf_norm_gt[0, 1].numpy()
lf_norm_show = np.zeros((480, 160, 3), dtype=np.uint8)
ys, xs = np.where(seg_ll_data > 0.5)
lf_norm_show[ys, xs, :] = 255
ys, xs = np.where(lf_label_data_gt> -0.5)
lf_norm_show[ys, xs, :] = 128
labels = np.logical_or(seg_ll_data[ys, xs] > 0.5, seg_cl_data[ys, xs] > 0.5)
ys = ys[labels]
xs = xs[labels]
scale = 1.7
if ys.shape[0] > 0:
for mm in range(0, ys.shape[0], 10):
y = ys[mm]
x = xs[mm]
norm0 = lf_norm_data_gt[0:2, y, x]
if norm0[0] == -999.:
continue
cv2.line(lf_norm_show, (x, y), (x+int(round(norm0[0]*50)), y + int(round(scale * (norm0[1]+1)*50))), (0, 0, 255))
norm1 = lf_norm_data_gt[2:4, y, x]
if norm1[0] == -999.:
continue
cv2.line(lf_norm_show, (x, y), (x+int(round(norm1[0]*50)), y + int(round(scale * (norm1[1]+1)*50))), (255, 0, 0))
writer.add_image('train/lf_norm_gt/0', lf_norm_show, global_step=counter, dataformats='HWC')
lf_norm_data = lf_norm[0, 1].detach().cpu().numpy()
ys, xs = np.where(np.logical_or(seg_ll_data > 0.5, seg_cl_data > 0.5))
lf_norm_show = np.zeros((480, 160, 3), dtype=np.uint8)
if ys.shape[0] > 0:
for mm in range(0, ys.shape[0], 10):
y = ys[mm]
x = xs[mm]
norm0 = lf_norm_data[0:2, y, x]/scale_lf
cv2.line(lf_norm_show, (x, y), (x+int(round(norm0[0]*50)), y+int(round(scale * (norm0[1]+1)*50))), (0, 0, 255))
norm1 = lf_norm_data[2:4, y, x]/scale_lf
cv2.line(lf_norm_show, (x, y), (x+int(round(norm1[0]*50)), y+int(round(scale * (norm1[1]+1)*50))), (255, 0, 0))
writer.add_image('train/lf_norm/0', lf_norm_show, global_step=counter, dataformats='HWC')
if counter % (1*val_step) == 0 and args.local_rank==0:
model.eval()
#mname = os.path.join(logdir, "model{}.pt".format(0))
#mname = os.path.join(logdir, "model{}.pt".format(counter))#counter))
#print('saving', mname)
#torch.save(model.state_dict(), mname)
checkpt_dir = f"{config.TRAINER.SAVE_DIR}/{args.exp_name}/checkpts/"
os.makedirs(checkpt_dir, exist_ok=True)
mname = os.path.join(checkpt_dir, f"model_{counter}.pt")
torch.save(model.state_dict(), mname)
counter += 1
if __name__ == '__main__':
main()
train.sh
PORT=${PORT:-29512}
MASTER_ADDR=${MASTER_ADDR:-"127.0.0.1"}
CUDA_VISIBLE_DEVICES=0,1 python -m torch.distributed.launch \
--master_addr=$MASTER_ADDR \
--master_port=$PORT \
--nproc_per_node=2 \ # 对应gpu数量
main_multii_conv2d.py \
--cfg_path /mnt/sdb/xzq/occ_project/occ_nerf_st/src/config/train_tongfan_ngp.yaml \
--num_epochs 50 \
--num_gpus 2 \
--num_nodes 1 \
--batch_size 2048 \
--test_batch_size 512 \
--num_workers 2 \
--exp_name models_20231207_nornn_2d_2_ori_theatmatvalid__st_v0_1bag_bsz4_rays1024_data_tfmap_newcxy_nextmask2_bevgrid_conf_adjustnearfar2
Note :
- 貌似 单机多卡不需要通讯address, port
- 多机多卡才需要
# 单机多卡示例
CUDA_VISIBLE_DEVICES=0,1 python -m torch.distributed.launch --nproc_per_node=2 train.py
老模型推理原始脚本 - remove key
"""
Copyright (C) 2020 NVIDIA Corporation. All rights reserved.
Licensed under the NVIDIA Source Code License. See LICENSE at https://github.com/nv-tlabs/lift-splat-shoot.
Authors: Jonah Philion and Sanja Fidler
"""
import os
import torch
import numpy as np
from torch import nn
from collections import OrderedDict
from src.models_goe_1129_nornn_2d_2_ori import compile_model
# from src.models_goe_1129_nornn_2d_2_ori_flash import compile_model
from tensorboardX import SummaryWriter
# from src.data_tfmap_newcxy_ori import compile_data
from src.data_tfmap_newcxy_nextmask2 import compile_data
from src.tools import SimpleLoss, RegLoss, SegLoss, BCEFocalLoss, get_batch_iou, get_val_info, denormalize_img
import sys
import cv2
os.environ["CUDA_VISIBLE_DEVICES"] = "3"
os.environ['RANK'] = "0"
os.environ['WORLD_SIZE'] = "1"
os.environ['MASTER_ADDR'] = "localhost"
os.environ['MASTER_PORT'] = "12332"
os.environ['CUDA_LAUNCH_BLOCKING'] = '1'
import argparse
import open3d as o3d
import json
from src.config.defaults import get_cfg_defaults
from src.options import get_opts
from src.utils.visualization import extract_mesh, extract_mesh2, extract_alpha
from src.rendering.neuconw_helper import NeuconWHelper
pi = 3.1415926
def convert_rollyawpitch_to_rot(roll, yaw, pitch):
roll *= pi/180.
yaw *= pi/180.
pitch *= pi/180.
Rr = np.array([[0.0, -1.0, 0.0],
[0.0, 0.0, -1.0],
[1.0, 0.0, 0.0]], dtype=np.float32)
Rx = np.array([[1.0, 0.0, 0.0],
[0.0, np.cos(roll), np.sin(roll)],
[0.0, -np.sin(roll), np.cos(roll)]], dtype=np.float32)
Ry = np.array([[np.cos(pitch), 0.0, -np.sin(pitch)],
[0.0, 1.0, 0.0],
[np.sin(pitch), 0.0, np.cos(pitch)]], dtype=np.float32)
Rz = np.array([[np.cos(yaw), np.sin(yaw), 0.0],
[-np.sin(yaw), np.cos(yaw), 0.0],
[0.0, 0.0, 1.0]], dtype=np.float32)
R = np.matrix(Rr) * np.matrix(Rx) * np.matrix(Ry) * np.matrix(Rz)
return R
def get_view_control(vis, idx):
view_control = vis.get_view_control()
if idx == 0:
### cam view
# view_control.set_front([-1, 0, 0])
# view_control.set_lookat([8, 0, 2])
# view_control.set_up([0, 0, 1])
# view_control.set_zoom(0.025)
# view_control.rotate(0, 2100 / 40)
### bev observe object depth
view_control.set_front([-1, 0, 1])
view_control.set_lookat([30, 0, 0])
view_control.set_up([0, 0, 1])
view_control.set_zoom(0.3)
view_control.rotate(0, 2100 / 20)
elif idx == 1:
view_control.set_front([-1, 0, 0])
view_control.set_lookat([8, 0, 0])
# view_control.set_lookat([8, 0, 2]) ### look down
view_control.set_up([0, 0, 1])
view_control.set_zoom(0.025)
view_control.rotate(0, 2100 / 40)
return view_control
def main():
# parser = argparse.ArgumentParser()
# parser.add_argument("--local_rank", default = 0, type=int)
# args = parser.parse_args()
args = get_opts()
config = get_cfg_defaults()
config.merge_from_file(args.cfg_path)
args.local_rank = 1
print("sssss",args.local_rank)
if args.local_rank != -1:
torch.cuda.set_device(args.local_rank)
device=torch.device("cuda", args.local_rank)
torch.distributed.init_process_group(backend="nccl", init_method='env://')
# model_path = "/mnt/sdb/xzq/occ_project/occ_nerf_st/checkpoints/models_20231128_nornn_2d_2_ori_st_v0_1bag_bsz4_rays600_data_tfmap_newcxy_ori_theta_matiszero"
# model_path = "/mnt/sdb/xzq/occ_project/occ_nerf_st/checkpoints/models_20231201_nornn_2d_2_ori_st_v0_1bag_bsz4_rays800_data_tfmap_newcxy_ori_theta_iszero_z6" # 单包, retrain 2d
# model_path = "/home/algo/mnt/xzq/occ_project/occ_nerf_st/checkpoints/models_20231204_nornn_2d_2_ori_st_v0_10bag_bsz4_rays1024_data_tfmap_newcxy_ori_theta_iszero_z6_adjustnearfar" # 10包, retrain 2d
# model_path = "/home/algo/mnt/xzq/occ_project/occ_nerf_st/checkpoints/models_20231204_nornn_2d_2_ori_flash_st_v0_1bag_bsz4_rays1024_data_tfmap_newcxy_ori_theta_iszero_z6_adjustnearfar_2"
# model_path = "/mnt/sdb/xzq/occ_project/occ_nerf_st/checkpoints/models_20231205_nornn_2d_2_ori_st_v0_1bag_bsz4_rays1024_data_tfmap_newcxy_nextmask2_theta_iszero_bevgrid_conf_adjustnearfar2"
model_path = "/mnt/sdb/xzq/occ_project/occ_nerf_st/checkpoints/models_20231207_nornn_2d_2_ori_st_v0_1bag_bsz4_rays1024_data_tfmap_newcxy_nextmask2_bevgrid_conf_adjustnearfar2"
model_name = "model_32000.pt"
ckpt_path = model_path + "/checkpts/" + model_name
to_result_path = "result/" + model_path.split('/')[-1] + '/' + model_name.split('.')[0]
viz_train = False
viz_gnd = False
viz_osr = True
# xbound=[0.0, 96., 0.5]
# ybound=[-12.0, 12.0, 0.5]
# zbound=[-3.0, 5.0, 0.5]
# dbound=[3.0, 103.0, 2.]
# xbound=[0.0, 96., 0.5]
# ybound=[-12.0, 12.0, 0.5]
# zbound=[-2.0, 4.0, 1]
# dbound=[3.0, 103.0, 2.]
xbound=[0.0, 102., 0.85]
ybound=[-10.0, 10.0, 0.5]
zbound=[-2.0, 4.0, 1]
dbound=[3.0, 103.0, 2.]
bsz=1
seq_len=5
nworkers=1
sample_num = 3200
datatype = "single" #multi single
version = "0"
dataroot = "/data/zjj/data/aishare/share"
# dataroot = "/run/user/1000/gvfs/sftp:host=192.168.1.40%20-p%2022/mnt/inspurfs/share-directory/defaultShare/aishare/share"
torch.backends.cudnn.benchmark = True
grid_conf = {
'xbound': xbound,
'ybound': ybound,
'zbound': zbound,
'dbound': dbound,
}
data_aug_conf = {
'resize_lim': [(0.05, 0.4), (0.3, 0.90)],#(0.3-0.9)
'final_dim': (128, 352),
'rot_lim': (-5.4, 5.4),
# 'H': H, 'W': W,
'rand_flip': False,
'bot_pct_lim': [(0.04, 0.35), (0.15, 0.4)],
'cams': ['CAM_FRONT0', 'CAM_FRONT1'],
'Ncams': 2,
}
# data_aug_conf = {
# 'resize_lim': [(0.125, 0.125), (0.25, 0.25)],
# 'final_dim': (128, 352),
# 'rot_lim': (0, 0),
# 'rand_flip': False,
# 'bot_pct_lim': [(0.0, 0.051), (0.2, 0.2)],
# 'cams': ['CAM_FRONT0', 'CAM_FRONT1'],
# 'Ncams': 2,
# }
train_sampler, val_sampler,trainloader, valloader = compile_data(version, dataroot, data_aug_conf=data_aug_conf,
grid_conf=grid_conf, bsz=bsz, seq_len=seq_len, sample_num=sample_num, nworkers=nworkers,
parser_name='segmentation1data', datatype=datatype)
loader = trainloader if viz_train else valloader
writer = SummaryWriter(logdir=None)
model = compile_model(grid_conf, data_aug_conf, seq_len=seq_len, batchsize=int(bsz), config=config, args=args, writer=writer,phase='validation')
checkpoint = torch.load(ckpt_path)
new_state_dict = OrderedDict()
for k, v in checkpoint.items():
if "neuconw_helper" in k:
name = k[22:] # remove "neuconw_helper.module."
# name = k[15:] # remove "neuconw_helper."
print(k, name)
continue
elif "module." in k:
name = k[7:] # remove "module."
print(k)
else:
name = k
new_state_dict[name] = v
model.load_state_dict(new_state_dict, True)
model.to(device)
num_gpus = torch.cuda.device_count()
# if num_gpus > 1:
# model = nn.parallel.DistributedDataParallel(model, device_ids=[args.local_rank],
# output_device=args.local_rank,find_unused_parameters=True)
neuconw_helper = NeuconWHelper(args, config, model.neuconw, model.embedding_a, None)
ww = 160
hh = 480
model.eval()
fps = 30
flourcc = cv2.VideoWriter_fourcc('M', 'J', 'P', 'G')
width = int(3715*300./1110)
n_view = 2
roi_num = 2
osr_hh = int((width + ww * 6)/1853/2*1025)
if viz_gnd:
if viz_osr:
out_shape = (width + ww * 6, hh + osr_hh)
else:
out_shape = (width + ww * 6, hh)
else:
if viz_osr:
out_shape = (width + ww * 6, 1080)
else:
out_shape = (0, 0)
colors = [(255, 255, 255), (255, 0, 0), (0, 255, 0), (0, 0, 255), (255, 255, 0), (255, 0, 255), (0, 255, 255)]
# vis = o3d.visualization.Visualizer()
# vis.create_window(window_name='bev')
cur_sce_name = None
count = 0
with torch.no_grad():
for batchi, (imgs, rots, trans, intrins, dist_coeffss, post_rots, post_trans, cam_pos_embeddings, binimgs, lf_label_gt, lf_norm_gt, fork_scales_gt, fork_offsets_gt, fork_oris_gt, rays, theta_mat_2d, theta_mat_3d, img_paths, sce_name) in enumerate(loader):
# for batchi, (imgs, rots, trans, intrins, dist_coeffss, post_rots, post_trans, cam_pos_embeddings, binimgs, lf_label_gt, lf_norm_gt, fork_scales_gt, fork_offsets_gt, fork_oris_gt, rays, theta_mat_2d, theta_mat_3d, sce_id_ind, idx, img_paths, sce_name) in enumerate(loader):
if count==0:
count += 1
continue
if sce_name[0] != cur_sce_name:
sname = '_'.join(sce_name[0].split('/')[-6:-3])
# output_path = model_path + "/result/" + model_name.split('.')[0] + "/" + sname + '_roi3'
output_path = to_result_path + "/" + sname
os.makedirs(output_path, exist_ok=True)
to_video_path = output_path + "/demo_" + sname + "_train.mp4"
print(to_video_path)
to_occ_gt_dir = output_path + '/occ_gts/'
to_mesh_dir = output_path + '/meshes/'
to_occ_pred_dir = output_path + '/occ_preds/'
to_img_dir = output_path + '/img_result/'
# if cur_sce_name is not None:
# videoWriter.release()
# videoWriter = cv2.VideoWriter(to_video_path, flourcc, fps, out_shape)
os.makedirs(to_occ_gt_dir, exist_ok=True)
os.makedirs(to_occ_pred_dir, exist_ok=True)
os.makedirs(to_mesh_dir, exist_ok=True)
os.makedirs(to_img_dir, exist_ok=True)
cur_sce_name = sce_name[0]
voxel_map_data = model(imgs.to(device), rots.to(device), trans.to(device),
intrins.to(device), dist_coeffss.to(device), post_rots.to(device),
post_trans.to(device), cam_pos_embeddings.to(device), fork_scales_gt.to(device),fork_offsets_gt.to(device),fork_oris_gt.to(device),
rays.to(device), theta_mat_2d.to(device), 0, 'validation')
# voxel_map_data =model(imgs.to(device),
# rots.to(device),
# trans.to(device),
# intrins.to(device),
# dist_coeffss.to(device),
# post_rots.to(device),
# post_trans.to(device),
# cam_pos_embeddings.to(device),
# fork_scales_gt.to(device),
# fork_offsets_gt.to(device),
# fork_oris_gt.to(device),
# rays.to(device),
# theta_mat_2d.to(device),
# 0,
# 'validation'
# )
output_img_merge = np.zeros((out_shape[1], out_shape[0], 3), dtype=np.uint8)
if viz_gnd:
print('viz_gnd')
# norm_mask = (lf_norm_gt > -500)
binimgs = binimgs.cpu().numpy()
lf_pred = lf_preds[:, :, :1].contiguous()
lf_norm = lf_preds[:, :, 1:(1+4)].contiguous()
seg_out = seg_preds.sigmoid()
seg_out = seg_out.cpu().numpy()
lf_out = lf_pred.sigmoid().cpu().numpy()
lf_norm = lf_norm.cpu().numpy()
H, W = 944, 1824
fH, fW = data_aug_conf['final_dim']
crop0 = []
crop1 = []
for cam_idx in range(2):
resize = np.mean(data_aug_conf['resize_lim'][cam_idx])
resize_dims = (int(fW / resize), int(fH / resize))
newfW, newfH = resize_dims
# print(newfW, newfH)
crop_h = int((1 - np.mean(data_aug_conf['bot_pct_lim'][cam_idx])) * H) - newfH
crop_w = int(max(0, W - newfW) / 2)
if cam_idx == 0:
crop0 = (crop_w, crop_h, crop_w + newfW, crop_h + newfH)
else:
crop1 = (crop_w, crop_h, crop_w + newfW, crop_h + newfH)
si = seq_len - 1
imgname = img_paths[si][0][img_paths[si][0].rfind('/')+1 :]
print('imgname = ', img_paths[-si][0])
img_org = cv2.imread(img_paths[si][0])
imgpath = img_paths[si][0][: img_paths[si][0].rfind('org/')-1]
param_path = imgpath + '/gen/param_infos.json'
param_infos = {}
with open(param_path, 'r') as ff :
param_infos = json.load(ff)
yaw = param_infos['yaw']
pitch = param_infos['pitch']
if pitch == 0.789806:
pitch = -pitch
roll = param_infos['roll']
tran = np.array(param_infos['xyz'])
H, W = param_infos['imgH_ori'], param_infos['imgW_ori']
ori_K = np.array(param_infos['ori_K'],dtype=np.float64).reshape(3,3)
dist_coeffs = np.array(param_infos['dist_coeffs']).astype(np.float64)
# cam2car_matrix
rot = convert_rollyawpitch_to_rot(roll, yaw, pitch).I
cam2car = np.eye(4, dtype= np.float64)
cam2car[:3, :3] = rot
cam2car[:3, 3] = tran.T
norm = lf_norm[0, 4]
fork = lf_out[0, 4]
img_res = np.ones((480, 160, 3), dtype=np.uint8)
colors = [(255, 255, 255), (255, 0, 0), (0, 255, 0), (0, 0, 255), (255, 255, 0),(0, 255, 255)]
for class_id in range(6):
result = seg_out[0][si][class_id]
if class_id == 5:
img_res[result> 0.4] = np.array(colors[class_id])
else:
img_res[result> 0.4] = np.array(colors[class_id])
ys, xs = np.where(result > 0.4)
pt = np.array([ys*0.2125, 0.125*xs-10, np.zeros(ys.shape), np.ones(ys.shape)])
if pt.shape[1] == 0:
continue
car2cam = np.matrix(cam2car).I.dot(pt)[:3, :]
rvec, tvec = np.array([0,0,0], dtype=np.float32), np.array([0,0,0], dtype=np.float32)
cam2img, _ = cv2.projectPoints(np.array(car2cam.T), rvec, tvec, ori_K, dist_coeffs)
for ii in range(cam2img.shape[0]):
ptx = round(cam2img[ii,0,0])
pty = round(cam2img[ii,0,1])
cv2.circle(img_org, (ptx, pty), 3, colors[class_id], -1)
# gt = binimgs[0][si][class_id]
# img_res[gt< -0.5] = np.array((128,128,128))
img_res = cv2.flip(cv2.flip(img_res, 0), 1)
img_gt = np.ones((480, 160, 3), dtype=np.uint8)
for class_id in range(6):
result = binimgs[0][si][class_id]
img_gt[result> 0.5] = np.array(colors[class_id])
img_gt[result< -0.5] = np.array((128,128,128))
img_gt = cv2.flip(cv2.flip(img_gt, 0), 1)
cv2.rectangle(img_org, (int(crop0[0]), int(crop0[1])), (int(crop0[2]), int(crop0[3])), (0,255,255), 2)
cv2.rectangle(img_org, (int(crop1[0]), int(crop1[1])), (int(crop1[2]), int(crop1[3])), (0,255,0), 2)
img_org = cv2.resize(img_org, (width, hh))
img_org_show = np.zeros((hh, width+ww*6, 3), dtype=np.uint8)*255
img_org_show[:, ww*6:] = img_org
outs = np.zeros((seq_len, hh, ww, 3), dtype=np.uint8)
outs1 = np.zeros((seq_len, hh, ww, 3), dtype=np.uint8)
outs2 = np.zeros((seq_len, hh, ww, 3), dtype=np.uint8)
gts = np.zeros((seq_len, hh, ww, 3), dtype=np.uint8)
gts1 = np.zeros((seq_len, hh, ww, 3), dtype=np.uint8)
gts2 = np.zeros((seq_len, hh, ww, 3), dtype=np.uint8)
ys, xs = np.where(lf_label_gt[0, si, 0] > -0.5)
ys1, xs1 = np.where(lf_label_gt[0, si, 0] > 0.5)
ys2, xs2 = np.where(lf_out[0, si, 0] > 0.5)
gts[si][binimgs[0, si, 0] > 0.5] = np.array(colors[0])
outs[si][seg_out[0, si, 0] > 0.5] = np.array(colors[0])
gts[si][binimgs[0, si, 4] > 0.6] = np.array(colors[4])
outs[si][seg_out[0, si, 4] > 0.6] = np.array(colors[4])
gts[si][binimgs[0, si, 5] > 0.6] = np.array(colors[5])
outs[si][seg_out[0, si, 5] > 0.6] = np.array(colors[5])
valid_mask = np.sum(gts[si], axis=-1) > 0
labels = np.where(valid_mask[ys, xs]> 0.5)
ys = ys[labels]
xs = xs[labels]
gts1[si][ys1, xs1, :] = 255
mask = torch.squeeze(lf_norm_gt[:,si,0])
# gts2[si][mask < -500] = (128, 128, 128)
if xs.shape[0] > 0:
for mm in range(0, xs.shape[0], 2):
# for mm in range(0, 800, 100):
y = ys[mm]
x = xs[mm]
norm = lf_norm_gt[0, si, 0:2, y, x].numpy()
if norm[0] == -999.:
continue
cv2.line(gts2[si], (x, y), (x+int(round((norm[1]+1)*100)), y+int(0.5*round(norm[0]*-100))), (0, 255, 0),1)
norm = lf_norm_gt[0, si, 2:4, y, x].numpy()
cv2.line(gts2[si], (x, y), (x+int(round((norm[1]+1)*100)), y+int(0.5*round(norm[0]*-100))), (255, 0, 0),1)
# print (norm)
# cv2.circle(gts2[si], (x, y), 3, (0, 255, 255))
# ys, xs = np.where(np.logical_or(seg_out[0][si][0] > 0.5, seg_out[0][si][5] > 0.5))
# ys, xs = np.where(np.logical_or(seg_out[0][si][0] > -0.5, seg_out[0][si][5] > -0.5))
valid_mask = np.sum(outs[si], axis=-1) > 0
labels = np.where(valid_mask[ys, xs]> 0.5)
ys = ys[labels]
xs = xs[labels]
outs1[si][ys2, xs2, :] = 255
if xs.shape[0] > 0:
for mm in range(0, xs.shape[0], 2):
y = ys[mm]
x = xs[mm]
norm = lf_norm[0, si, 0:2, y, x] / 5.
# print (norm)
cv2.line(outs2[si], (x, y), (x+int(round((norm[1]+1)*100)), y+int(0.5*round(norm[0]*-100))), (0, 255, 0),1)
norm = lf_norm[0, si, 2:4, y, x] / 5.
cv2.line(outs2[si], (x, y), (x+int(round((norm[1]+1)*100)), y+int(0.5*round(norm[0]*-100))), (255, 0, 0),1)
# gts2[si][lf_label_gt[0, si, 0] < -0.5] = (128,128,128)
# gts1[si][lf_label_gt[0, si, 0] < -0.5] = (128,128,128)
img_org_show[:, :ww] = img_res
img_org_show[:, ww:ww*2] = img_gt
img_org_show[:, ww*2:ww*3] = cv2.flip(cv2.flip(outs2[si], 0), 1)
img_org_show[:, ww*3:ww*4] = cv2.flip(cv2.flip(gts2[si], 0), 1)
img_org_show[:, ww*4:ww*5] = cv2.flip(cv2.flip(outs1[si], 0), 1)
img_org_show[:, ww*5:ww*6] = cv2.flip(cv2.flip(gts1[si], 0), 1)
cv2.putText(img_org_show, "NAME:" + imgname + 'seq_id: '+ str(si), (700+320, 30), cv2.FONT_HERSHEY_SIMPLEX, 1, (255, 0, 0), 2)
# print(idxs)
output_img_merge[:img_org_show.shape[0], :] = img_org_show
if viz_osr:
si = seq_len - 1
imgname = img_paths[si][0][img_paths[si][0].rfind('/')+1 :]
# print('imgname = ', img_paths[-si][0])
output_img = np.zeros((1025, 1853*2, 3), dtype=np.uint8)
to_occ_gt_path = to_occ_gt_dir + imgname.replace('.jpg', '.ply')
to_occ_pred_path = to_occ_pred_dir + imgname.replace('.jpg', '.ply')
to_mesh_path = to_mesh_dir + imgname.replace('.jpg', '.ply')
to_img_path = to_img_dir + imgname
to_bin_path = to_img_dir + imgname.replace('.jpg', '.bin')
idx = rays[0, si, :, 15] < 1
pts_gt = rays[0, si, idx, 0:3] + rays[0, si, idx, 3:6]*rays[0, si, idx, 9:10] # gt_pts
semantic_gt = rays[0, si, idx, 8].view(-1,1)
# pts = rays_all[si][0, :, :3] + rays_all[si][0, :, 3:6] * rays_all[si][0, :, 9:10]
# semantic_gt = rays_all[si][0, :, 9:10]
# np.save(to_occ_gt_path, np.concatenate([pts, semantic_gt], axis=1))
pcd_gt = o3d.geometry.PointCloud()
pcd_gt.points = o3d.utility.Vector3dVector(pts_gt.numpy())
pcd_gt.paint_uniform_color([0, 1, 0]) # 绿色
o3d.io.write_point_cloud(to_occ_gt_path, pcd_gt)
voxel_map = {
"origin": (model.bx - model.dx / 2).to(device),
"size": (model.dx * (model.nx - 1)).to(device),
"dx": model.dx.to(device),
# "origin": (model_bx - model_dx / 2).to(device),
# "size": (model_dx * (model_nx - 1)).to(device),
# "dx": model_dx.to(device),
"data": voxel_map_data[0][si:si + 1, ...],
"all_rays": rays[0, si:si + 1, :, :].view(-1, rays.shape[-1]).to(device),
"rots": rots[0, si * roi_num:si * roi_num + 1, ...],
"trans": trans[0, si * roi_num:si * roi_num + 1, ...],
"intrins": intrins[0, si * roi_num:si * roi_num + 1, ...],
"post_rots": post_rots[0, si * roi_num:si * roi_num + 1, ...],
"post_trans": post_trans[0, si * roi_num:si * roi_num + 1, ...],
# "valid_mask": valid_mask_coo[si:si + 1, ...]
}
if 1:
all_rays = rays[0,si,idx,:].view(-1,rays.shape[-1]).to(device) # 确定渲染的是第几帧的rays
sample = {
"rays": torch.cat(
(all_rays[:, :8], all_rays[:, 9:11],all_rays[:, 15:17]), dim=-1
),
"ts": all_rays[:,17], # delta_t
# "ts": torch.ones_like(all_rays[:, -1]).long()*0.,
"rgbs": all_rays[:, -3:], # 索引错的,但是不影响--rgb loss没用上
"semantics": all_rays[:, 8],
}
# pts_generate, depth_loss = neuconw_helper.generate_depth(sample, voxel_map, 0, args.local_rank) # 由渲染的depth得到预测点
# print(">>>>>>>>>>>>>>depth_loss:",depth_loss.mean())
# if depth_loss.mean() > 0.2 : print('--imgname--', imgname)
# # depth_loss_mean_list.append(depth_loss.mean().detach().cpu().numpy())
# # count_list.append(count)
# pts_pred = o3d.geometry.PointCloud()
# pts_pred.points = o3d.utility.Vector3dVector(np.array(pts_generate.detach().cpu().numpy()))
# pts_pred.paint_uniform_color([0, 0, 1])
# idx_high_loss = np.where(depth_loss.cpu().numpy()>1.25) #>0.5
# idx_mid_loss = np.where((depth_loss.cpu().numpy()>0.2)*(depth_loss.cpu().numpy()<=1.25)) #0.2~0.5
# idx_low_loss = np.where(depth_loss.cpu().numpy()<0.2) #<0.2
# # idx_lower_loss = np.where(depth_loss.cpu().numpy()<0.2) #<0.2
# np.asarray(pts_pred.colors)[idx_high_loss, :] = [1, 0, 0]
# np.asarray(pts_pred.colors)[idx_mid_loss, :] = [1, 1, 0]
# np.asarray(pts_pred.colors)[idx_low_loss, :] = [0, 1, 0]
# # o3d.io.write_point_cloud(
# # f"/home/algo/1/1/debug_pts_gen_car_" + imgname.split('.jpg')[0] + ".ply", pts_pred)
# o3d.io.write_point_cloud(os.path.join(to_occ_pred_dir + imgname.replace('.jpg', '_pred.ply')), pts_pred)
if 1:
out_info = extract_alpha(
voxel_map, dim=512, # np.int(np.round(self.scene_config["radius"]/(3**(1/3))/0.1))
# chunk=16384,
chunk=8192,
with_color=False,
embedding_a=neuconw_helper.embedding_a((torch.ones(1).cuda() * 1).long()),
renderer=neuconw_helper.renderer
)
# mesh, out_info = extract_mesh2(voxel_map, renderer=neuconw_helper.renderer)
np.save(to_occ_pred_path, out_info)
# mesh.export(to_mesh_path)
# mesh = o3d.geometry.TriangleMesh(vertices=o3d.utility.Vector3dVector(
# mesh.vertices.copy()),
# triangles=o3d.utility.Vector3iVector(
# mesh.faces.copy()))
# mesh.compute_vertex_normals()
# for idx_v in range(n_view):
# if idx_v == 0:
# vis.add_geometry(mesh, True)
# vis.add_geometry(pcd_gt, True)
# else:
# vis.add_geometry(mesh, True)
# view_control = get_view_control(vis, idx_v)
# vis.poll_events()
# vis.update_renderer()
# # vis.run()
# mesh_capture_img = vis.capture_screen_float_buffer(True)
# vis.clear_geometries()
# mesh_capture_img = np.array(np.asarray(mesh_capture_img)[..., ::-1] * 255, dtype=np.uint8)
# output_img[:, mesh_capture_img.shape[1] * idx_v:mesh_capture_img.shape[1] * (idx_v + 1),:] = mesh_capture_img
# output_img_resize = cv2.resize(output_img, (out_shape[0], osr_hh))
# output_img_merge[hh:, :] = output_img_resize
cv2.imwrite(to_img_path, output_img_merge)
# videoWriter.write(output_img_merge)
# c = cv2.waitKey(1)%0x100
# if c == 27:
# break
print(1)
count += 1
if __name__ == '__main__':
main()
**老模型-mmcv [load_checkpoint] 加载模型 **
"""
Copyright (C) 2020 NVIDIA Corporation. All rights reserved.
Licensed under the NVIDIA Source Code License. See LICENSE at https://github.com/nv-tlabs/lift-splat-shoot.
Authors: Jonah Philion and Sanja Fidler
"""
import os
from pathlib import Path
from collections import OrderedDict
import numpy as np
import torch
# from src.models_goe_1129_nornn_2d_2 import compile_model
from src.models_goe_1129_nornn_v8 import compile_model
from src.data_tfmap_newcxy_ori import compile_data
# from src.data_tfmap_newcxy_nextmask2 import compile_data
import cv2
import open3d as o3d
import json
from src.config.defaults import get_cfg_defaults
from src.options import get_opts
from src.utils.visualization import extract_alpha
from src.rendering.neuconw_helper import NeuconWHelper
from mmcv.runner import load_checkpoint
" 推理关闭数据层train_sampler -- # train_sampler = val_sampler = None"
os.environ["CUDA_VISIBLE_DEVICES"] = "4"
os.environ['RANK'] = "0"
os.environ['WORLD_SIZE'] = "1"
os.environ['MASTER_ADDR'] = "localhost"
os.environ['MASTER_PORT'] = "12331"
os.environ['CUDA_LAUNCH_BLOCKING'] = '1'
pi = 3.1415926
def convert_rollyawpitch_to_rot(roll, yaw, pitch):
roll *= pi/180.
yaw *= pi/180.
pitch *= pi/180.
Rr = np.array([[0.0, -1.0, 0.0],
[0.0, 0.0, -1.0],
[1.0, 0.0, 0.0]], dtype=np.float32)
Rx = np.array([[1.0, 0.0, 0.0],
[0.0, np.cos(roll), np.sin(roll)],
[0.0, -np.sin(roll), np.cos(roll)]], dtype=np.float32)
Ry = np.array([[np.cos(pitch), 0.0, -np.sin(pitch)],
[0.0, 1.0, 0.0],
[np.sin(pitch), 0.0, np.cos(pitch)]], dtype=np.float32)
Rz = np.array([[np.cos(yaw), np.sin(yaw), 0.0],
[-np.sin(yaw), np.cos(yaw), 0.0],
[0.0, 0.0, 1.0]], dtype=np.float32)
R = np.matrix(Rr) * np.matrix(Rx) * np.matrix(Ry) * np.matrix(Rz)
return R
def get_view_control(vis, idx):
view_control = vis.get_view_control()
if idx == 0:
### cam view
# view_control.set_front([-1, 0, 0])
# view_control.set_lookat([8, 0, 2])
# view_control.set_up([0, 0, 1])
# view_control.set_zoom(0.025)
# view_control.rotate(0, 2100 / 40)
### bev observe object depth
view_control.set_front([-1, 0, 1])
view_control.set_lookat([30, 0, 0])
view_control.set_up([0, 0, 1])
view_control.set_zoom(0.3)
view_control.rotate(0, 2100 / 20)
elif idx == 1:
view_control.set_front([-1, 0, 0])
view_control.set_lookat([8, 0, 0])
# view_control.set_lookat([8, 0, 2]) ### look down
view_control.set_up([0, 0, 1])
view_control.set_zoom(0.025)
view_control.rotate(0, 2100 / 40)
return view_control
def main():
# parser = argparse.ArgumentParser()
# parser.add_argument("--local_rank", default = 0, type=int)
# args = parser.parse_args()
args = get_opts()
config = get_cfg_defaults()
config.merge_from_file(args.cfg_path)
args.local_rank = 1
print("sssss",args.local_rank)
if args.local_rank != -1:
torch.cuda.set_device(args.local_rank)
device=torch.device("cuda", args.local_rank)
torch.distributed.init_process_group(backend="nccl", init_method='env://')
# model_path = "/mnt/sdb/xzq/occ_project/occ_nerf_st/checkpoints/models_20231128_nornn_2d_2_st_v0_1bag_bsz4_rays800_data_tfmap_newcxy_ori"
model_path = "/mnt/sdb/xzq/occ_project/occ_nerf_st/checkpoints/models_20231128_nornn_2d_2_st_v0_10bag_bsz4_rays800"
# model_path = "/home/algo/mnt/xzq/occ_project/occ_nerf_st/checkpoints/nerf_1204_nornn_v8_st_pretrain_data_tfmap_newcxy_nextmask2_1bag_adjustnearfar_newcondition" # adjust_nearfar1
model_name = "model_20000.pt"
ckpt_path = model_path + "/checkpts/" + model_name
to_result_path = "result/" + model_path.split('/')[-1] + '/' + model_name.split('.')[0] + '_p2'
viz_train = False
viz_gnd = False
viz_osr = True
bsz=1
seq_len=5
nworkers=6
sample_num = 512
datatype = "single" #multi single
version = "0"
# dataroot = "/home/algo/dataSpace/NeRF/bev_ground/data/aishare/share"
#dataroot='/defaultShare/user-data'
dataroot = "/data/zjj/data/aishare/share"
xbound=[0.0, 96., 0.5]
ybound=[-12.0, 12.0, 0.5]
zbound=[-3.0, 5.0, 0.5]
dbound=[3.0, 103.0, 2.]
grid_conf = {
'xbound': xbound,
'ybound': ybound,
'zbound': zbound,
'dbound': dbound,
}
data_aug_conf = {
'resize_lim': [(0.05, 0.4), (0.3, 0.90)],#(0.3-0.9)
'final_dim': (128, 352),
'rot_lim': (-5.4, 5.4),
# 'H': H, 'W': W,
'rand_flip': False,
'bot_pct_lim': [(0.04, 0.35), (0.15, 0.4)],
# 'bot_pct_lim': [(0.04, 0.35), (0.4, 0.4)],
'cams': ['CAM_FRONT0', 'CAM_FRONT1'],
'Ncams': 2,
}
train_sampler, val_sampler,trainloader, valloader = compile_data(version, dataroot, data_aug_conf=data_aug_conf,
grid_conf=grid_conf, bsz=bsz, seq_len=seq_len, sample_num=sample_num, nworkers=nworkers,
parser_name='segmentation1data', datatype=datatype)
loader = trainloader if viz_train else valloader
model = compile_model(grid_conf, data_aug_conf, seq_len=seq_len, batchsize=int(bsz), config=config, args=args, phase='validation')
checkpoint = load_checkpoint(model, ckpt_path, map_location='cpu')
# #------------------------------
# checkpoint = torch.load(ckpt_path)
# new_state_dict = OrderedDict()
# for k, v in checkpoint.items():
# if "neuconw_helper" in k:
# # name = k[22:] # remove "neuconw_helper.module."
# name = k[15:] # remove "neuconw_helper."
# print(k, name)
# continue
# elif "module." in k:
# name = k[7:] # remove "module."
# print(k)
# else:
# name = k
# new_state_dict[name] = v
# model.load_state_dict(new_state_dict, True)
# #------------------------------
model.to(device)
neuconw_helper = NeuconWHelper(args, config, model.neuconw, model.embedding_a, None)
ww = 160
hh = 480
model.eval()
fps = 30
flourcc = cv2.VideoWriter_fourcc('M', 'J', 'P', 'G')
width = int(3715*300./1110)
n_view = 2
roi_num = 2
osr_hh = int((width + ww * 6)/1853/2*1025)
if viz_gnd:
if viz_osr:
out_shape = (width + ww * 6, hh + osr_hh)
else:
out_shape = (width + ww * 6, hh)
else:
if viz_osr:
out_shape = (width + ww * 6, 1080)
else:
out_shape = (0, 0)
colors = [(255, 255, 255), (255, 0, 0), (0, 255, 0), (0, 0, 255), (255, 255, 0), (255, 0, 255), (0, 255, 255)]
# vis = o3d.visualization.Visualizer()
# vis.create_window(window_name='bev')
cur_sce_name = None
count = 0
with torch.no_grad():
for batchi, (imgs, rots, trans, intrins, dist_coeffss, post_rots, post_trans, cam_pos_embeddings, binimg, lf_label, lf_norm, fork_scale, fork_offset, fork_ori, rays, pose_mats_2d, pose_mats_3d, img_paths, sce_name) in enumerate(valloader):
if sce_name[0] != cur_sce_name:
sname = '_'.join(sce_name[0].split('/')[-6:-3])
# output_path = model_path + "/result/" + model_name.split('.')[0] + "/" + sname + '_roi3'
output_path = to_result_path + "/" + sname
os.makedirs(output_path, exist_ok=True)
to_video_path = output_path + "/demo_" + sname + "_train.mp4"
print(to_video_path)
to_occ_gt_dir = output_path + '/occ_gts/'
to_mesh_dir = output_path + '/meshes/'
to_occ_pred_dir = output_path + '/occ_preds/'
to_img_dir = output_path + '/img_result/'
# if cur_sce_name is not None:
# videoWriter.release()
# videoWriter = cv2.VideoWriter(to_video_path, flourcc, fps, out_shape)
os.makedirs(to_occ_gt_dir, exist_ok=True)
os.makedirs(to_occ_pred_dir, exist_ok=True)
os.makedirs(to_mesh_dir, exist_ok=True)
os.makedirs(to_img_dir, exist_ok=True)
cur_sce_name = sce_name[0]
voxel_map_data = model(imgs.to(device),
rots.to(device),
trans.to(device),
intrins.to(device),
dist_coeffss.to(device),
post_rots.to(device),
post_trans.to(device),
cam_pos_embeddings.to(device),
fork_scale.to(device),
fork_offset.to(device),
fork_ori.to(device),
rays,
pose_mats_2d.to(device),
0,
'validation'
)
output_img_merge = np.zeros((out_shape[1], out_shape[0], 3), dtype=np.uint8)
if viz_gnd:
print('viz_gnd')
# norm_mask = (lf_norm_gt > -500)
binimgs = binimgs.cpu().numpy()
lf_pred = lf_preds[:, :, :1].contiguous()
lf_norm = lf_preds[:, :, 1:(1+4)].contiguous()
seg_out = seg_preds.sigmoid()
seg_out = seg_out.cpu().numpy()
lf_out = lf_pred.sigmoid().cpu().numpy()
lf_norm = lf_norm.cpu().numpy()
H, W = 944, 1824
fH, fW = data_aug_conf['final_dim']
crop0 = []
crop1 = []
for cam_idx in range(2):
resize = np.mean(data_aug_conf['resize_lim'][cam_idx])
resize_dims = (int(fW / resize), int(fH / resize))
newfW, newfH = resize_dims
# print(newfW, newfH)
crop_h = int((1 - np.mean(data_aug_conf['bot_pct_lim'][cam_idx])) * H) - newfH
crop_w = int(max(0, W - newfW) / 2)
if cam_idx == 0:
crop0 = (crop_w, crop_h, crop_w + newfW, crop_h + newfH)
else:
crop1 = (crop_w, crop_h, crop_w + newfW, crop_h + newfH)
si = seq_len - 1
imgname = img_paths[si][0][img_paths[si][0].rfind('/')+1 :]
print('imgname = ', img_paths[-si][0])
img_org = cv2.imread(img_paths[si][0])
imgpath = img_paths[si][0][: img_paths[si][0].rfind('org/')-1]
param_path = imgpath + '/gen/param_infos.json'
param_infos = {}
with open(param_path, 'r') as ff :
param_infos = json.load(ff)
yaw = param_infos['yaw']
pitch = param_infos['pitch']
if pitch == 0.789806:
pitch = -pitch
roll = param_infos['roll']
tran = np.array(param_infos['xyz'])
H, W = param_infos['imgH_ori'], param_infos['imgW_ori']
ori_K = np.array(param_infos['ori_K'],dtype=np.float64).reshape(3,3)
dist_coeffs = np.array(param_infos['dist_coeffs']).astype(np.float64)
# cam2car_matrix
rot = convert_rollyawpitch_to_rot(roll, yaw, pitch).I
cam2car = np.eye(4, dtype= np.float64)
cam2car[:3, :3] = rot
cam2car[:3, 3] = tran.T
norm = lf_norm[0, 4]
fork = lf_out[0, 4]
img_res = np.ones((480, 160, 3), dtype=np.uint8)
colors = [(255, 255, 255), (255, 0, 0), (0, 255, 0), (0, 0, 255), (255, 255, 0),(0, 255, 255)]
for class_id in range(6):
result = seg_out[0][si][class_id]
if class_id == 5:
img_res[result> 0.4] = np.array(colors[class_id])
else:
img_res[result> 0.4] = np.array(colors[class_id])
ys, xs = np.where(result > 0.4)
pt = np.array([ys*0.2125, 0.125*xs-10, np.zeros(ys.shape), np.ones(ys.shape)])
if pt.shape[1] == 0:
continue
car2cam = np.matrix(cam2car).I.dot(pt)[:3, :]
rvec, tvec = np.array([0,0,0], dtype=np.float32), np.array([0,0,0], dtype=np.float32)
cam2img, _ = cv2.projectPoints(np.array(car2cam.T), rvec, tvec, ori_K, dist_coeffs)
for ii in range(cam2img.shape[0]):
ptx = round(cam2img[ii,0,0])
pty = round(cam2img[ii,0,1])
cv2.circle(img_org, (ptx, pty), 3, colors[class_id], -1)
# gt = binimgs[0][si][class_id]
# img_res[gt< -0.5] = np.array((128,128,128))
img_res = cv2.flip(cv2.flip(img_res, 0), 1)
img_gt = np.ones((480, 160, 3), dtype=np.uint8)
for class_id in range(6):
result = binimgs[0][si][class_id]
img_gt[result> 0.5] = np.array(colors[class_id])
img_gt[result< -0.5] = np.array((128,128,128))
img_gt = cv2.flip(cv2.flip(img_gt, 0), 1)
cv2.rectangle(img_org, (int(crop0[0]), int(crop0[1])), (int(crop0[2]), int(crop0[3])), (0,255,255), 2)
cv2.rectangle(img_org, (int(crop1[0]), int(crop1[1])), (int(crop1[2]), int(crop1[3])), (0,255,0), 2)
img_org = cv2.resize(img_org, (width, hh))
img_org_show = np.zeros((hh, width+ww*6, 3), dtype=np.uint8)*255
img_org_show[:, ww*6:] = img_org
outs = np.zeros((seq_len, hh, ww, 3), dtype=np.uint8)
outs1 = np.zeros((seq_len, hh, ww, 3), dtype=np.uint8)
outs2 = np.zeros((seq_len, hh, ww, 3), dtype=np.uint8)
gts = np.zeros((seq_len, hh, ww, 3), dtype=np.uint8)
gts1 = np.zeros((seq_len, hh, ww, 3), dtype=np.uint8)
gts2 = np.zeros((seq_len, hh, ww, 3), dtype=np.uint8)
ys, xs = np.where(lf_label_gt[0, si, 0] > -0.5)
ys1, xs1 = np.where(lf_label_gt[0, si, 0] > 0.5)
ys2, xs2 = np.where(lf_out[0, si, 0] > 0.5)
gts[si][binimgs[0, si, 0] > 0.5] = np.array(colors[0])
outs[si][seg_out[0, si, 0] > 0.5] = np.array(colors[0])
gts[si][binimgs[0, si, 4] > 0.6] = np.array(colors[4])
outs[si][seg_out[0, si, 4] > 0.6] = np.array(colors[4])
gts[si][binimgs[0, si, 5] > 0.6] = np.array(colors[5])
outs[si][seg_out[0, si, 5] > 0.6] = np.array(colors[5])
valid_mask = np.sum(gts[si], axis=-1) > 0
labels = np.where(valid_mask[ys, xs]> 0.5)
ys = ys[labels]
xs = xs[labels]
gts1[si][ys1, xs1, :] = 255
mask = torch.squeeze(lf_norm_gt[:,si,0])
# gts2[si][mask < -500] = (128, 128, 128)
if xs.shape[0] > 0:
for mm in range(0, xs.shape[0], 2):
# for mm in range(0, 800, 100):
y = ys[mm]
x = xs[mm]
norm = lf_norm_gt[0, si, 0:2, y, x].numpy()
if norm[0] == -999.:
continue
cv2.line(gts2[si], (x, y), (x+int(round((norm[1]+1)*100)), y+int(0.5*round(norm[0]*-100))), (0, 255, 0),1)
norm = lf_norm_gt[0, si, 2:4, y, x].numpy()
cv2.line(gts2[si], (x, y), (x+int(round((norm[1]+1)*100)), y+int(0.5*round(norm[0]*-100))), (255, 0, 0),1)
# print (norm)
# cv2.circle(gts2[si], (x, y), 3, (0, 255, 255))
# ys, xs = np.where(np.logical_or(seg_out[0][si][0] > 0.5, seg_out[0][si][5] > 0.5))
# ys, xs = np.where(np.logical_or(seg_out[0][si][0] > -0.5, seg_out[0][si][5] > -0.5))
valid_mask = np.sum(outs[si], axis=-1) > 0
labels = np.where(valid_mask[ys, xs]> 0.5)
ys = ys[labels]
xs = xs[labels]
outs1[si][ys2, xs2, :] = 255
if xs.shape[0] > 0:
for mm in range(0, xs.shape[0], 2):
y = ys[mm]
x = xs[mm]
norm = lf_norm[0, si, 0:2, y, x] / 5.
# print (norm)
cv2.line(outs2[si], (x, y), (x+int(round((norm[1]+1)*100)), y+int(0.5*round(norm[0]*-100))), (0, 255, 0),1)
norm = lf_norm[0, si, 2:4, y, x] / 5.
cv2.line(outs2[si], (x, y), (x+int(round((norm[1]+1)*100)), y+int(0.5*round(norm[0]*-100))), (255, 0, 0),1)
# gts2[si][lf_label_gt[0, si, 0] < -0.5] = (128,128,128)
# gts1[si][lf_label_gt[0, si, 0] < -0.5] = (128,128,128)
img_org_show[:, :ww] = img_res
img_org_show[:, ww:ww*2] = img_gt
img_org_show[:, ww*2:ww*3] = cv2.flip(cv2.flip(outs2[si], 0), 1)
img_org_show[:, ww*3:ww*4] = cv2.flip(cv2.flip(gts2[si], 0), 1)
img_org_show[:, ww*4:ww*5] = cv2.flip(cv2.flip(outs1[si], 0), 1)
img_org_show[:, ww*5:ww*6] = cv2.flip(cv2.flip(gts1[si], 0), 1)
cv2.putText(img_org_show, "NAME:" + imgname + 'seq_id: '+ str(si), (700+320, 30), cv2.FONT_HERSHEY_SIMPLEX, 1, (255, 0, 0), 2)
# print(idxs)
output_img_merge[:img_org_show.shape[0], :] = img_org_show
if viz_osr:
# si = seq_len - 1
si = 0
imgname = img_paths[si][0][img_paths[si][0].rfind('/')+1 :]
# print('imgname = ', img_paths[-si][0])
output_img = np.zeros((1025, 1853*2, 3), dtype=np.uint8)
to_occ_gt_path = to_occ_gt_dir + imgname.replace('.jpg', '.ply')
to_occ_pred_path = to_occ_pred_dir + imgname.replace('.jpg', '.ply')
to_mesh_path = to_mesh_dir + imgname.replace('.jpg', '.ply')
to_img_path = to_img_dir + imgname
to_bin_path = to_img_dir + imgname.replace('.jpg', '.bin')
idx = rays[0, si, :, 15] < 1
pts_gt = rays[0, si, idx, 0:3] + rays[0, si, idx, 3:6]*rays[0, si, idx, 9:10] # gt_pts
semantic_gt = rays[0, si, idx, 8].view(-1,1)
# pts = rays_all[si][0, :, :3] + rays_all[si][0, :, 3:6] * rays_all[si][0, :, 9:10]
# semantic_gt = rays_all[si][0, :, 9:10]
# np.save(to_occ_gt_path, np.concatenate([pts, semantic_gt], axis=1))
pcd_gt = o3d.geometry.PointCloud()
pcd_gt.points = o3d.utility.Vector3dVector(pts_gt.numpy())
pcd_gt.paint_uniform_color([0, 1, 0]) # 绿色
o3d.io.write_point_cloud(to_occ_gt_path, pcd_gt)
voxel_map = {
"origin": (model.bx - model.dx / 2).to(device),
"size": (model.dx * (model.nx - 1)).to(device),
"dx": model.dx.to(device),
# "origin": (model_bx - model_dx / 2).to(device),
# "size": (model_dx * (model_nx - 1)).to(device),
# "dx": model_dx.to(device),
"data": voxel_map_data[0][si:si + 1, ...],
"all_rays": rays[0, si:si + 1, :, :].view(-1, rays.shape[-1]).to(device),
"rots": rots[0, si * roi_num:si * roi_num + 1, ...],
"trans": trans[0, si * roi_num:si * roi_num + 1, ...],
"intrins": intrins[0, si * roi_num:si * roi_num + 1, ...],
"post_rots": post_rots[0, si * roi_num:si * roi_num + 1, ...],
"post_trans": post_trans[0, si * roi_num:si * roi_num + 1, ...],
# "valid_mask": valid_mask_coo[si:si + 1, ...]
}
all_rays = rays[0,si,idx,:].view(-1,rays.shape[-1]).to(device) # 确定渲染的是第几帧的rays
sample = {
"rays": torch.cat(
(all_rays[:, :8], all_rays[:, 9:11],all_rays[:, 15:17]), dim=-1
),
"ts": all_rays[:,17], # delta_t
# "ts": torch.ones_like(all_rays[:, -1]).long()*0.,
"rgbs": all_rays[:, -3:], # 索引错的,但是不影响--rgb loss没用上
"semantics": all_rays[:, 8],
}
# pts_generate, depth_loss = neuconw_helper.generate_depth(sample, voxel_map, 0, args.local_rank) # 由渲染的depth得到预测点
# print(">>>>>>>>>>>>>>depth_loss:",depth_loss.mean())
# if depth_loss.mean() > 0.2 : print('--imgname--', imgname)
# # depth_loss_mean_list.append(depth_loss.mean().detach().cpu().numpy())
# # count_list.append(count)
# pts_pred = o3d.geometry.PointCloud()
# pts_pred.points = o3d.utility.Vector3dVector(np.array(pts_generate.detach().cpu().numpy()))
# pts_pred.paint_uniform_color([0, 0, 1])
# idx_high_loss = np.where(depth_loss.cpu().numpy()>1.25) #>0.5
# idx_mid_loss = np.where((depth_loss.cpu().numpy()>0.2)*(depth_loss.cpu().numpy()<=1.25)) #0.2~0.5
# idx_low_loss = np.where(depth_loss.cpu().numpy()<0.2) #<0.2
# # idx_lower_loss = np.where(depth_loss.cpu().numpy()<0.2) #<0.2
# np.asarray(pts_pred.colors)[idx_high_loss, :] = [1, 0, 0]
# np.asarray(pts_pred.colors)[idx_mid_loss, :] = [1, 1, 0]
# np.asarray(pts_pred.colors)[idx_low_loss, :] = [0, 1, 0]
# # o3d.io.write_point_cloud(
# # f"/home/algo/1/1/debug_pts_gen_car_" + imgname.split('.jpg')[0] + ".ply", pts_pred)
# o3d.io.write_point_cloud(os.path.join(to_occ_pred_dir + imgname.replace('.jpg', '_pred.ply')), pts_pred)
if 1:
out_info = extract_alpha(
voxel_map, dim=512, # np.int(np.round(self.scene_config["radius"]/(3**(1/3))/0.1))
chunk=16384,
with_color=False,
embedding_a=neuconw_helper.embedding_a((torch.ones(1).cuda() * 1).long()),
renderer=neuconw_helper.renderer,
# model=model
)
# mesh, out_info = extract_mesh2(voxel_map, renderer=neuconw_helper.renderer)
np.save(to_occ_pred_path, out_info)
occ_pred = out_info.numpy()
_, alpha_static, alpha_transient, valid_masks = occ_pred[:, :3], occ_pred[:, 3], occ_pred[:, 4], occ_pred[:,5]
# output_mask = valid_masks * np.logical_and((alpha_transient > 0.2), alpha_transient < 1)
output_mask = valid_masks * (alpha_transient > 0.2)
out_for_vis = occ_pred[output_mask > 0, :5]
np.savetxt(Path(to_occ_pred_path).with_suffix('.txt'), out_for_vis)
# mesh.export(to_mesh_path)
# mesh = o3d.geometry.TriangleMesh(vertices=o3d.utility.Vector3dVector(
# mesh.vertices.copy()),
# triangles=o3d.utility.Vector3iVector(
# mesh.faces.copy()))
# mesh.compute_vertex_normals()
# for idx_v in range(n_view):
# if idx_v == 0:
# vis.add_geometry(mesh, True)
# vis.add_geometry(pcd_gt, True)
# else:
# vis.add_geometry(mesh, True)
# view_control = get_view_control(vis, idx_v)
# vis.poll_events()
# vis.update_renderer()
# # vis.run()
# mesh_capture_img = vis.capture_screen_float_buffer(True)
# vis.clear_geometries()
# mesh_capture_img = np.array(np.asarray(mesh_capture_img)[..., ::-1] * 255, dtype=np.uint8)
# output_img[:, mesh_capture_img.shape[1] * idx_v:mesh_capture_img.shape[1] * (idx_v + 1),:] = mesh_capture_img
# output_img_resize = cv2.resize(output_img, (out_shape[0], osr_hh))
# output_img_merge[hh:, :] = output_img_resize
cv2.imwrite(to_img_path, output_img_merge)
# videoWriter.write(output_img_merge)
# c = cv2.waitKey(1)%0x100
# if c == 27:
# break
# print(1)
count += 1
if __name__ == '__main__':
main()