目录
一、正则表达式
1.1 定义与作用
正则表达式分为两种:
- 基本正则表达式 grep、sed默认使用基础正则
- 扩展正则表达式 grep -E、sed -r、awk使用扩展正则
正则表达式与通配符的区别:
正则表达式主要用来匹配文本内容或命令结果
通配符主要用于匹配文件名
1.2 元字符的含义
. 匹配任意单个字符,可以是一个汉字
[] 匹配指定范围内的任意单个字符,示例:[zhou] [0-9] [] [a-zA-Z] [[:alpha:]] [0-9a-zA-Z]= [:alnum:]
[^] 匹配指定范围外的任意单个字符,取反,示例:[^zhou] [^a.z] [a.z]
[:alnum:] 字母和数字
[:alpha:] 代表任何英文大小写字符,亦即 A-Z, a-z
[:lower:] 小写字母,示例:[[:lower:]],相当于[a-z]
[:upper:] 大写字母
[:blank:] 空白字符(空格和制表符)
[:space:] 包括空格、制表符 (水平和垂直)、换行符、回车符等各种类型的空白,比[:blank:]包含的范围广
[:cntrl:] 不可打印的控制字符(退格、删除、警铃...)
[:digit:] 十进制数字
[:xdigit:]十六进制数字
[:graph:] 可打印的非空白字符
[:print:] 可打印字符
[:punct:] 标点符号
\n #匹配换行符
\t #匹配制表符
\w #匹配单词构成部分,等价于[_[:alnum:]]
\W #匹配非单词构成部分,等价于[^_[:alnum:]]
\S #匹配任何非空白字符。等价于 [^ \f\n\r\t\v]。
\s #匹配任何空白字符,包括空格、制表符、换页符等等。等价于 [ \f\n\r\t\v]。注意Unicode 正则表达式会匹配全角空格符!!!注意!!!
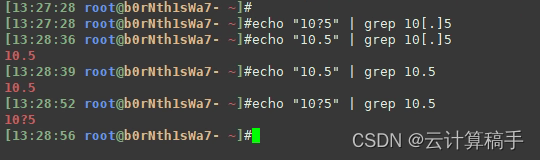
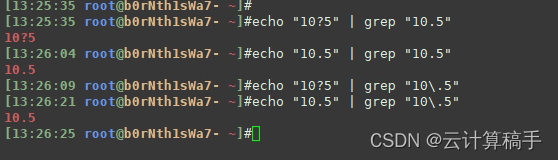
1. 所有的字符类在[]中就表示其原来的含义,如[.]表示匹配一个.符号
2. 若想在""中表示字符类的原来含义,则需要加上转义符\,如grep "10\.5",匹配"10.5",而非"10任意单个字符5"
3.特殊元字符在中括号中如何匹配:
- 想要在中括号中匹配^,需要将^放在[]中的非开头位置,如[a^]
- 想要在中括号中匹配-,需要将-放在[]中的开头或结尾位置,如[-ab]、[ab-]
- 想要在中括号中匹配],需要将]放在[]中的开头位置,如[]abd]
1.3 量词的含义
| 量词符号 | 含义 |
|---|---|
| * | 匹配符号前的字符0到正无穷次 |
| \? | 匹配符号前的字符0次或1次 |
| \+ | 匹配符号前的字符1到正无穷次 |
| \{n,\} | 匹配符号前的字符最少n次 |
| \{,n\} | 匹配符号前的字符最多n次 |
| \{n\} | 匹配符号前的字符n次 |
| .* | 匹配任意字符1到正无穷次 |
echo google | grep "go\{2\}gle" #表示o出现两次
google #匹配成功
echo aaa | grep "[abc]\{3\}" #匹配三次abc字母中的一个,也就是有3^3=27种匹配结果
aaa #可以匹配成功1.4 位置锚定
| 符号 | 含义 |
|---|---|
| ^ |
行首 |
| $ | 行尾 |
| ^PATTERN$ | PATTERN占单独一行 |
| ^$、^[[:space:]]*$ | 空行 |
| \>、\b | 词首 |
| \<、\b | 词尾 |
如何查看/etc/fstab中不以#开头的非空行
grep "^[^#]" /etc/fstab
echo hello-123 |grep "\b123" #匹配成功
echo hello 123 |grep "\b123" #匹配成功
echo hello:123 |grep "\b123" #匹配成功
echo hello_123 |grep "\b123" #匹配不成功,因为除了字母数字和下划线_,其他都算单词分隔符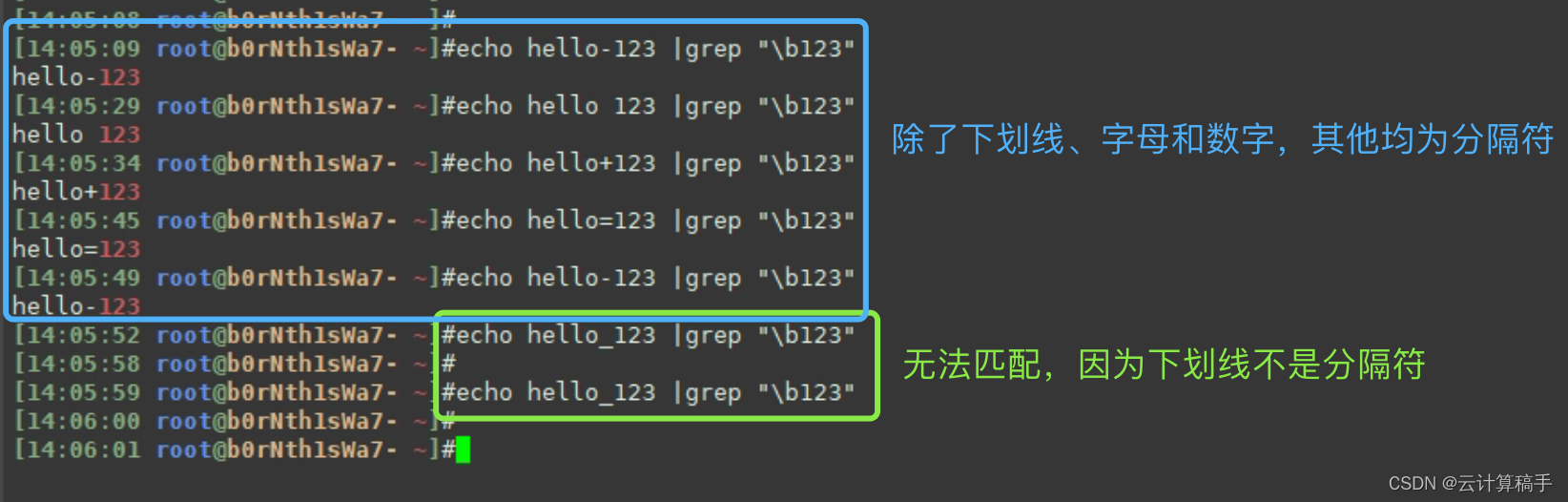
1.5 分组与其他
分组:
( ) 将多个字符捆绑在一起,当作一个整体处理,如:(root)+
后向引用:分组括号中的模式匹配到的内容会被正则表达式引擎记录于内部的变量中,这些变量的命名
方式为: \1, \2, \3, ... 分组
\1 表示从左侧起第一个左括号以及与之匹配右括号之间的模式所匹配到的字符
或者:
\|,表示或者的意思
分组:
echo abcabcabc | grep "\(abc\)\{3\}" #匹配abc这个整体出现三次
或者:
echo 1abc | grep "\(1\|2\)abc" #匹配1abc或者2abc
拓展:
ifconfig ens33 | grep netmask |grep -oE "([0-9]{1,3}.){3}[0-9]{1,3}"|head -n1 #匹配ip地址二、文本三剑客
2.1 grep用法
grep [选项] ...查找条件 目标文件/标准输入选项:
-color=auto #对匹配到的文本着色显示
-m # 匹配#次后停止 匹配到 #行停止 #为1表示使用懒汉式
grep -m 1 root /etc/passwd #多个匹配只取第一个
-v 显示不被pattern匹配到的行,即取反
grep -Ev '^[[:space:]]*#|^$' /etc/fstab
-i 忽略字符大小写
-n 显示匹配的行号
-c 统计匹配的行数
grep -c root /etc/passwd #统计匹配到的行数
-o 仅显示匹配到的字符串
-q 静默模式,不输出任何信息 写脚本
-A # after, 后#行
grep -A3 root /etc/passwd #匹配到的行后3行业显示出来
-B # before, 前#行
-C # context, 前后各#行
-e 实现多个选项间的逻辑or关系,如:grep –e ‘cat ' -e ‘dog' file
grep -e root -e bash /etc/passwd #包含root或者包含bash 的行
-w 匹配整个单词
grep -w root /etc/passwd
useradd rooter
-E 使用ERE,相当于egrep
-F 不支持正则表达式,相当于fgrep
-f file 根据模式文件,处理两个文件相同内容 把第一个文件作为匹配条件 grep -f a b
-r 递归目录,但不处理软链接 开始搜索目录
-R 递归目录,但处理软链接
如何统计当前主机的链接状态
ss -nat | grep -v "^State" | cut -d" " -f1| sort | uniq -c
3 ESTAB
15 LISTEN
如何统计当前连接主机数
ss -nt | grep -v "^State" | tr -s " "| cut -d" " -f4 | cut -d":" -f1 | uniq -c
1 192.168.254.102.2 sed
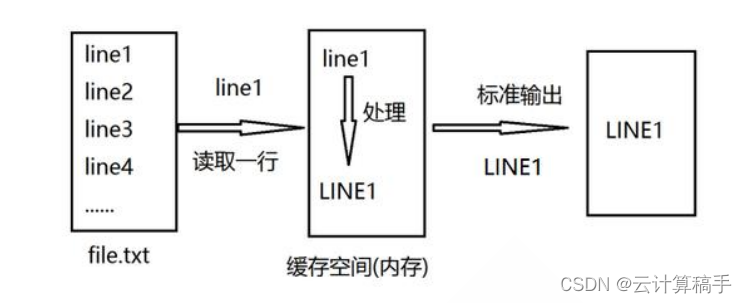
2.2.1 sed原理
2.2.2 sed基本用法
sed [option] ... 'script; script;...' [ input file...]常用选项:
-n 不输出模式空间内容到屏幕,即不自动打印
-e 多点编辑 sed -n -e '/^r/p' -e'/^b/p' /etc/passwd
-f FILE 从指定文件中读取编辑脚本
-r, -E 使用扩展正则表达式,r与E的区别在于不同版本之间的兼容性问题
-i.bak 备份文件并原处编辑
sed -r 使用拓展正则
sed ' ' /etc/fstab #类似于cat /etc/fstab
cat /etc/fstab | sed ' '2.2.3 sed脚本格式
'地址+命令'组成
1. 不给地址:对全文进行处理(比如行号)
2. 单地址:
#:指定的行,$:最后一行
/pattern/:被此处模式所能够匹配到的每一行,正则表达式
3. 地址范围:
#,# #从#行到第#行,3,6 从第3行到第6行
#,+# #从#行到+#行,3,+4 表示从3行到第7行
/pat1/,/pat2/ 第一个正则表达式 到 第二个正则表达式之间的行
#,/pat/ 从#号行为开始找到 pat为止 3 , /^r/
/pat/,# 找到#号个pat为止
4. 步进:~
1~2 奇数行
2~2 偶数行
sed -n 'n;p' testfile1 #打印偶数行
sed -n '2,${n;p}' testfile1
命令
p 打印当前模式空间内容,追加到默认输出之后
Ip 忽略大小写输出
d 删除模式空间匹配的行,并立即启用下一轮循环
a [\]text 在指定行后面追加文本,支持使用\n实现多行追加
i [\]text 在行前面插入文本
c [\]text 替换行为单行或多行文本n 读取匹配到的行的下一行覆盖至模式空间
w file 保存模式匹配的行至指定文件 seq 10 |sed -n '2wa.txt'
r file 读取指定文件的文本至模式空间中匹配到的行后 seq 10|sed '2r /etc/issue'
= 为模式空间中的行打印行号 sed '2=' /etc/passwd sed -n -e '=;p' /etc/passwd
! 模式空间中匹配行取反处理seq 10 |sed -n '1~2!p'
q 结束或退出sed seq 10 | sed '3q'
2.2.4 sed搜索替代
s/pattern/string/修饰符
查找替换,支持使用其它分隔符,可以是其它形式:s@@@,s###修饰符:
g 行内全局替换
p 显示替换成功的行
w /PATH/FILE 将替换成功的行保存至文件中
I,i 忽略大小写
echo 123abcxzy | sed -r 's/(123)(abc)(xzy)/\1/'
#s///代表查找替换,()表示分组,\1留下第一组,即结果为1232.2.5 sed高级用法
sed 中除了模式空间,还另外还支持保持空间(Hold Space),利用此空间,可以将模式空间中的数据,临时保存至保持空间,从而后续接着处理,实现更为强大的功能。
常见的高级命令:
P 打印模式空间开端至\n内容,并追加到默认输出之前
h 把模式空间中的内容覆盖至保持空间中
H 把模式空间中的内容追加至保持空间中
g 从保持空间取出数据覆盖至模式空间
G 从保持空间取出内容追加至模式空间
x 把模式空间中的内容与保持空间中的内容进行互换
n 读取匹配到的行的下一行覆盖至模式空间
N 读取匹配到的行的下一行追加至模式空间
d 删除模式空间中的行
D 如果模式空间包含换行符,则删除直到第一个换行符的模式空间中的文本,并不会读取新的输入行,而使
用合成的模式空间重新启动循环。如果模式空间不包含换行符,则会像发出d命令那样启动正常的新循环
2.3 awk
2.3.1 awk命令格式
awk [options] 'program' var=value file…
常见选项:
-F “分隔符” 指明输入时用到的字段分隔符,默认的分隔符是若干个连续空白符
-v var=value 变量赋值
Program格式:
pattern{action statements;..}
- pattern:决定动作语句何时触发及触发事件,比如:BEGIN,END,正则表达式等
- action statements:对数据进行处理,放在{}内指明,常见:print, printf
- output statements:print,printf
- Expressions:算术,比较表达式等
- Compound statements:组合语句
- Control statements:if, while等
- input statements2.3.2 awk基本用法
awk 选项 '模式{print }'
FS :指定每行文本的字段分隔符,缺省默认为空格或制表符(tab)。与 “-F”作用相同 -v "FS=:"
OFS:输出时的分隔符
NF:当前处理的行的字段个数
NR:当前处理的行的行号(序数)
$0:当前处理的行的整行内容
$n:当前处理行的第n个字段(第n列)
FILENAME:被处理的文件名
RS:行分隔符。awk从文件上读取资料时,将根据RS的定义就把资料切割成许多条记录,而awk一次仅读入一条记录进行处理。预设值是\nawk -v FS=':' '{print $1FS$3}' /etc/passwd
#此处FS 相当于于变量 -v 变量赋值 相当于 指定“:”为分隔符fs=":";awk -v FS=$fs -v OFS="+" '{print $1,$3}' /etc/passwd
#输出分隔符-F -FS一起使用 -F 的优先级高
################## NF ###################awk -F: '{print NF}' /etc/passwd
#打印出字段总数
awk -F: '{print $NF}' /etc/passwd
#$NF最后一个字段df|awk -F: '{print $(NF-1)}'
#倒数第二行
################ NR ######################awk '{print $1,NR}' /etc/passwd
#打印出第一列和行号awk 'NR==2{print $1}' /etc/passwd
#只取第二行的第一个字段awk 'NR==1,NR==3{print}' passwd
#打印出1到3 行awk 'NR==1||NR==3{print}' passwd
#打印出1和3行awk '(NR%2)==0{print NR}' passwd
#打印出函数取余数为0行,即偶数行awk '(NR%2)==1{print NR}' passwd
#打印出函数取余数为1的行,即奇数行
2.3.3 awk行范围
awk不支持使用行号,但是可以使用变量NR 间接指定行号加上比较操作符 或者逻辑关系
算术操作符
x+y, x-y, x*y, x/y, x^y, x%y
-x:转换为负数
+x:将字符串转换为数值
比较操作符:
==, !=, >, >=, <, <=逻辑
与:&&,并且关系
或:||,或者关系
非:!,取反
模式匹配符:
~ 左边是否和右边匹配,包含关系
!~ 是否不匹配
例子:
awk 'BEGIN{i=0;print i++,i}'
awk 'BEGIN{i=0;print ++i,i}
awk -F: '$0 ~ /root/{print $1}' /etc/passwd
awk -F: '$0 ~ "^root"{print $1}' /etc/passwd
awk '$0 !~ /root/' /etc/passwd
awk -F: '$1 ~ /root/{print $0}' /etc/passwd
root:x:0:0:root:/root:/bin/bash2.3.4 awk扩展用法
关系表达式结果为“真”才会被处理
真:结果为非0值,非空字符串
假:结果为空字符串或0
seq 10 |awk 'n++' 打印除了第一行
seq 10 |awk '!n++' 只打第一行
seq 10 |awk '!0'
seq 10 |awk 'i=!i' 奇数行
seq 10 |awk -v i=1 'i=!i' 偶数行
seq 10 |awk '!(i=!i)' 偶数行条件判断
awk 选项 '模式 {actions}'
条件判断写在 actions里
if语句:awk的if语句也分为单分支、双分支和多分支
单分支为if(判断条件){执行语句}
双分支为if(判断条件){执行语句}else{执行语句}
多分支为if(判断条件){执行语句}else if(判断条件){执行语句}else if(判断条件){执行语句}else if(判断条件){执行语句
举例:
awk -F: '{if($3>1000)print $1,$3}' /etc/passwd
nfsnobody 65534
mysql 1001
lisi 1002
liwu 1003
awk -F: '{if($3>1000){print $1,$3}else{print $3}}' /etc/passwd
for循环
awk '{a[$0]++}END{for (i in a){print i,a[i]}}' test.txt
awk 'BEGIN{sum=0;for(i=1;i<=100;i++){sum+=i};print sum}'
5050
awk 'BEGIN{i=0;print i++,i}'
0 1awk 'BEGIN{i=0;print ++i,i}'
1 1awk 'BEGIN{print x+1}' //不指定初始值,初始值就为0,如果是字符串,则默认为空
1