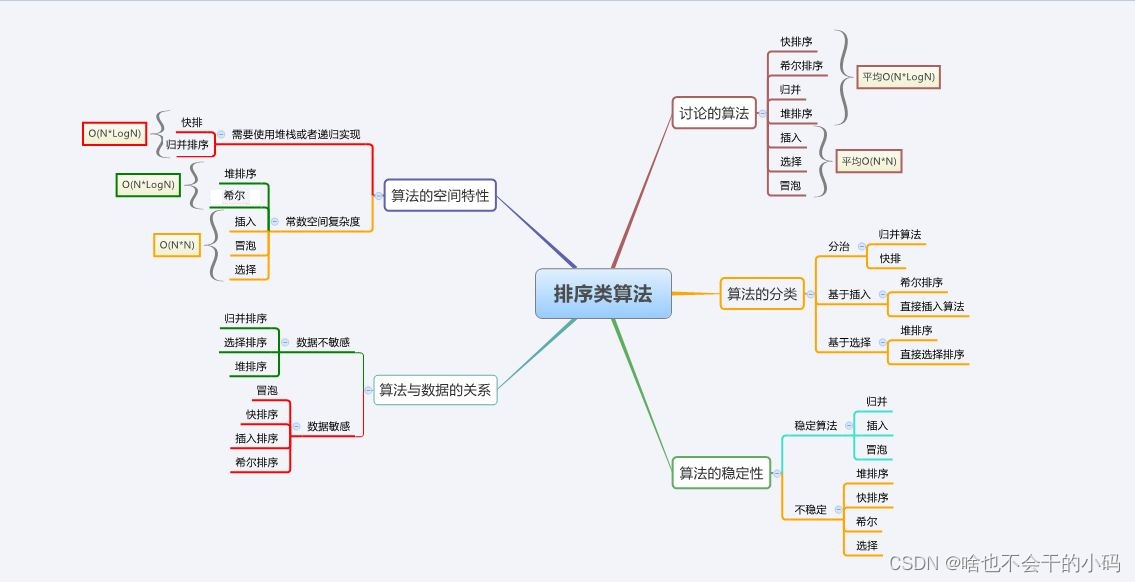
快速排序(Quick_Sort) 2024-06-09 算法, java, 排序算法, 数据结构, 开发语言 122人 已看 先用一个变量t存储元素,从左右两端循环,因为排序的元素是最左端元素,所以应该先从右侧开始,如果遇到了小于t的元素,就将左侧覆盖为他,接着从左端开始,如果遇到比t大的元素就将他覆盖到右边,直到low == hight;这个时候的位置就是左侧数都小于t,右侧数都大于t,将t插入后返回即可。每次排序一个元素,每次使他的左边都比他小,右边都比他大;先排序low位置的元素。然后返回他排序后的位置。接着排序他左边和右边。递归直到只剩一个元素。
C语言数据结构(排序算法总结) 2024-06-07 算法, java, 数据结构, 排序算法, 开发语言 132人 已看 先比较插入,选择,冒泡排序,放置1w个随机数比较剩下几个排序,每个放入1000w个数由于伪随机数非常均衡,因此相对来说计数排序效率相对来说非常高。
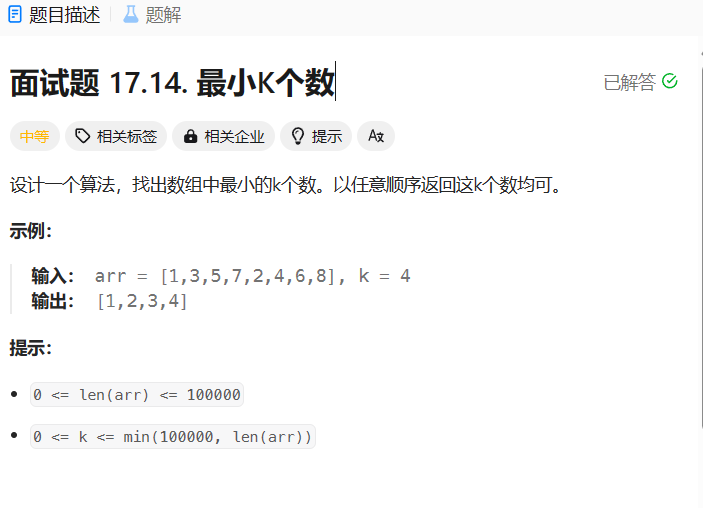
【数据结构】使用堆实现 求最小K个数 2024-06-04 算法, java, 排序算法, 数据结构, 开发语言 113人 已看 因此,总的时间复杂度为 O(n * log(n) + k * log(n))。如果 k 远小于 n,那么算法的时间复杂度可以近似为 O(n * log(n))。因此,整个算法的时间复杂度为 O((N - K) * log(k) + k * log(k)),其中 N 为数组的长度 arr.length,k 为要求的最小元素个数。如果 k 远小于 n,那么算法的时间复杂度可以近似为 O((N-K) * log(K))。此时将堆顶元素出堆,遍历到的数组元素入堆,最终堆中就是要求的前K个最小元素;
软设之排序算法对比 2024-06-03 算法, 排序算法 70人 已看 时间复杂度:平均情况O(nlog(2)n),基本有序最差是O(n^2)如果数据数目很大,应采用时间复杂度为O(nlog(2)n)的排序方法。时间复杂度:平均情况为O(n^2)。时间复杂度:平均情况O(n^1.3)时间复杂度:O(nlog(2)n)时间复杂度 O(nlog(2)n)时间复杂度:平均情况O(n^2)时间复杂度:O(d(n+rd))时间复杂度:O(n^2)空间复杂度:O(rd)空间复杂度:O(1)空间复杂度:O(1)空间复杂度:O(1)空间复杂度:O(1)空间复杂度:O(1)
各种内部排序算法的比较及应用(插入排序、交换排序、选择排序、归并排序、基数排序) 2024-06-06 算法, 排序算法 73人 已看 这篇文章总结了所有内部排序的适用场景,性质特点,以及空间和时间复杂度的考量;前半部分是对内部排序的总结,后半部分是对所有内部排序的具体性能分析;
折半查找&二分查找 2024-06-03 算法, java, 排序算法, 数据结构, 开发语言 102人 已看 本文介绍了折半查找算法的基本原理,并进行了代码的编写,最后又根据标准库中折半查找代码进行了实现,在现有代码的基础上进行优化,使得更加适用一般的情况。
软设之排序算法对比 2024-06-03 算法, 排序算法 77人 已看 时间复杂度:平均情况O(nlog(2)n),基本有序最差是O(n^2)如果数据数目很大,应采用时间复杂度为O(nlog(2)n)的排序方法。时间复杂度:平均情况为O(n^2)。时间复杂度:平均情况O(n^1.3)时间复杂度:O(nlog(2)n)时间复杂度 O(nlog(2)n)时间复杂度:平均情况O(n^2)时间复杂度:O(d(n+rd))时间复杂度:O(n^2)空间复杂度:O(rd)空间复杂度:O(1)空间复杂度:O(1)空间复杂度:O(1)空间复杂度:O(1)空间复杂度:O(1)
探索数据结构:堆,计数,桶,基数排序的分析与模拟实现 2024-06-06 算法, java, 排序算法, 数据结构, 开发语言 119人 已看 在计算机科学中,排序算法是一门经典而重要的领域。堆排序、桶排序、计数排序和基数排序是其中几种性能优异的算法。堆排序利用堆这种数据结构,实现高效的排序;桶排序将数据分布到不同的桶中,通过各自的排序算法完成排序;计数排序和基数排序则通过统计元素出现次数或位数来完成排序。探索这些算法背后的原理和实现,让我们一窥排序算法的精彩世界。
探索数据结构:快速排序与归并排序的实现与优化 2024-06-04 算法, 数据结构, 排序算法 96人 已看 快速排序和归并排序是两种常见的排序算法。快速排序是一种分治策略的排序算法,通过不断地将待排序数组分成更小的子数组,并对这些子数组进行排序,最终完成整个数组的排序。归并排序也是一种分治策略的排序算法,它将待排序数组分成两个子数组,然后递归地将每个子数组排序,最后将两个有序子数组合并为一个有序数组。相比之下,快速排序更加高效,但归并排序是一种稳定的排序算法。想要了解更多关于这两种排序算法的内容,赶快来看看本篇博客吧!
排序算法——上 2024-05-28 算法, java, 数据结构, 排序算法, 开发语言 96人 已看 我们从左边开始把相邻的两个数两两做比较,当一个元素大于右侧与它相邻的元素时,交换它们之间位置;反之,它们之间的位置不发生变化。冒泡排序是一种稳定的排序算法。
如何理解:选择排序中交换可能改变相同元素的相对顺序? 2024-06-03 算法, java, leetcode, 排序算法, 数据结构 102人 已看 算法复杂度:两者在最坏和平均情况下的时间复杂度相同,都是 (O(n^2))。但是选择排序在交换次数上通常比冒泡排序少。实现方式:选择排序每次找到最小(或最大)元素放到已排序部分,冒泡排序则是通过多次相邻元素的比较和交换来排序。稳定性:冒泡排序是稳定排序,选择排序是不稳定排序(因为选择排序中交换可能改变相同元素的相对顺序)。适用场景:在实际应用中,两者的使用较少,通常使用更高效的排序算法如快速排序或归并排序。但在数据量小且对交换次数要求高的情况下,可以考虑选择排序。
冒泡排序(经典) 2024-05-30 算法, java, 数据结构, 排序算法, 开发语言 99人 已看 2.i 的初始化为 0,是j的初始化也为 0,注意 j 的终止条件为:j < arr.length - i - 1,是为了防止越界。1.优化的 flag 是为了减少排序次数,如果在一次比较中都没有交换数据,那么这个数组就是有序的。总共由两次循环,外层循环为总共需要比较多少次,一般全部无序的数组,需要比较该数组的长度的值。内层循环,每一次比较需要比较多少次,每一次都比上一次减少一次的次数。我是小辉,24 届毕业生。当下是找工作ing,欢迎关注,持续分享。相邻的两个元素的比较,每次选出一个最大值。