数据仓库介绍 2024-06-05 数据仓库 64人 已看 数据仓库(Data Warehouse, DW)是一种用于存储和管理大量业务数据的系统,旨在支持决策支持系统(DSS)和商业智能(BI)应用。它将来自不同来源的数据整合到一个统一的数据库中,以便于分析和报告。
Hive on Spark版本兼容性 2024-06-08 hive, 数据仓库, spark, hadoop, 大数据 527人 已看 Hive on Spark仅在特定版本的Spark上进行测试,因此给定版本的Hive只能保证与特定版本的Spark一起工作。其他版本的Spark可能与给定版本的Hive一起工作,但不能保证。
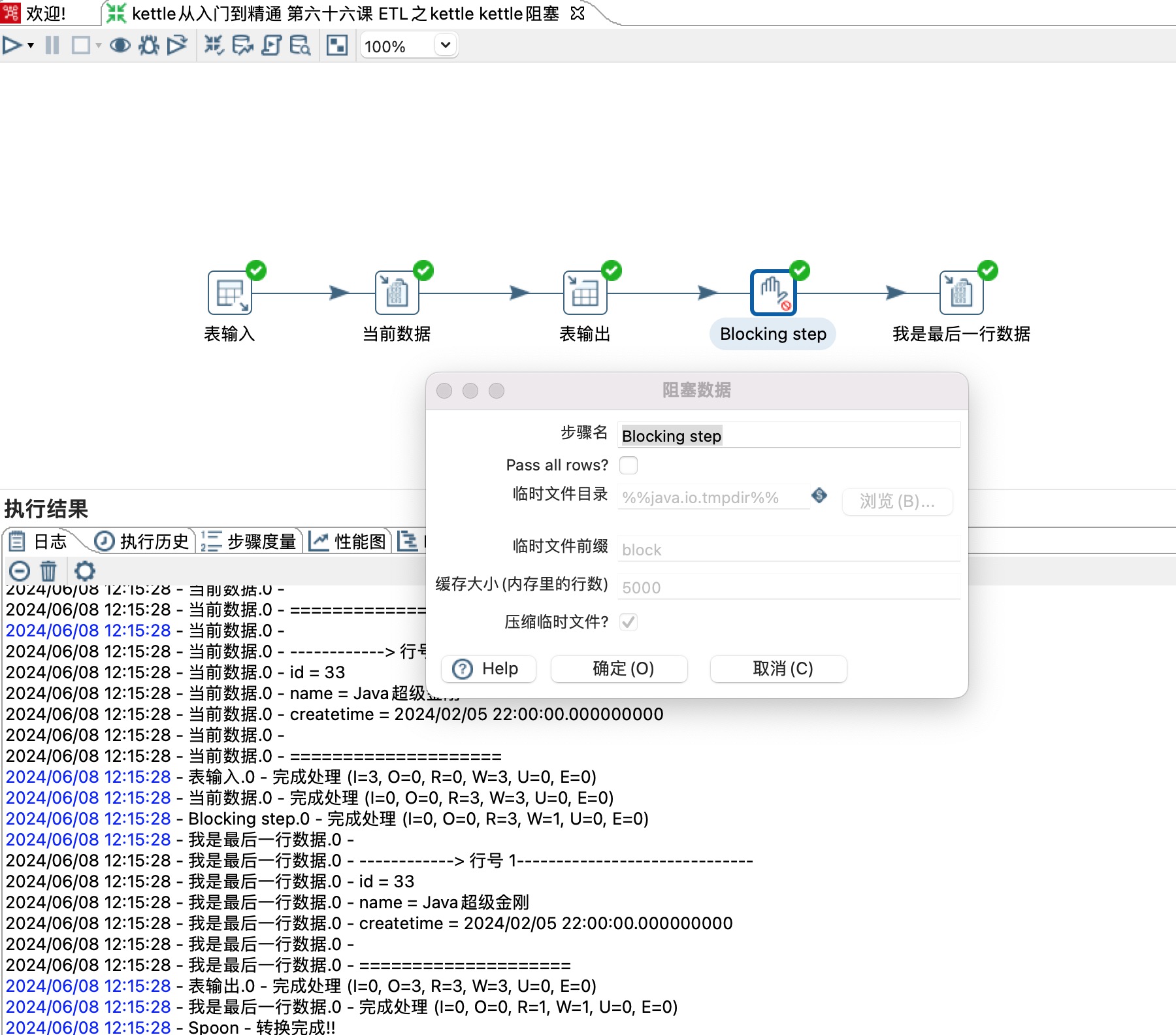
kettle从入门到精通 第六十六课 ETL之kettle kettle阻塞教程,轻松获取最后一行数据,so easy 2024-06-08 数据仓库, etl 149人 已看 若不勾选,表输出步骤成功写入3条数据之后只有最后一条数据才会通过Blocking step步骤传递给之后的步骤。:若勾选,表输出步骤成功写入3条数据之后所有数据都会通过Blocking step步骤传递给之后的步骤。2)从图片日志可以很清晰的看到,虽然Blocking step 写了三条数据,但是执行顺序依然是在Blocking step的前置步骤表输出完毕之后。1)从图片日志可以很清晰的看到,Blocking step 读取了三条数据,写了三条数据。
数据挖掘--数据仓库与联机分析处理 2024-06-07 数据仓库, 人工智能, 数据挖掘 95人 已看 (面集时非)面向主题的:围绕某一主题来构建集成的:图片文字杂糅在一起时变的:随时间变化的数据非易失的:硬盘存放,不易丢失。
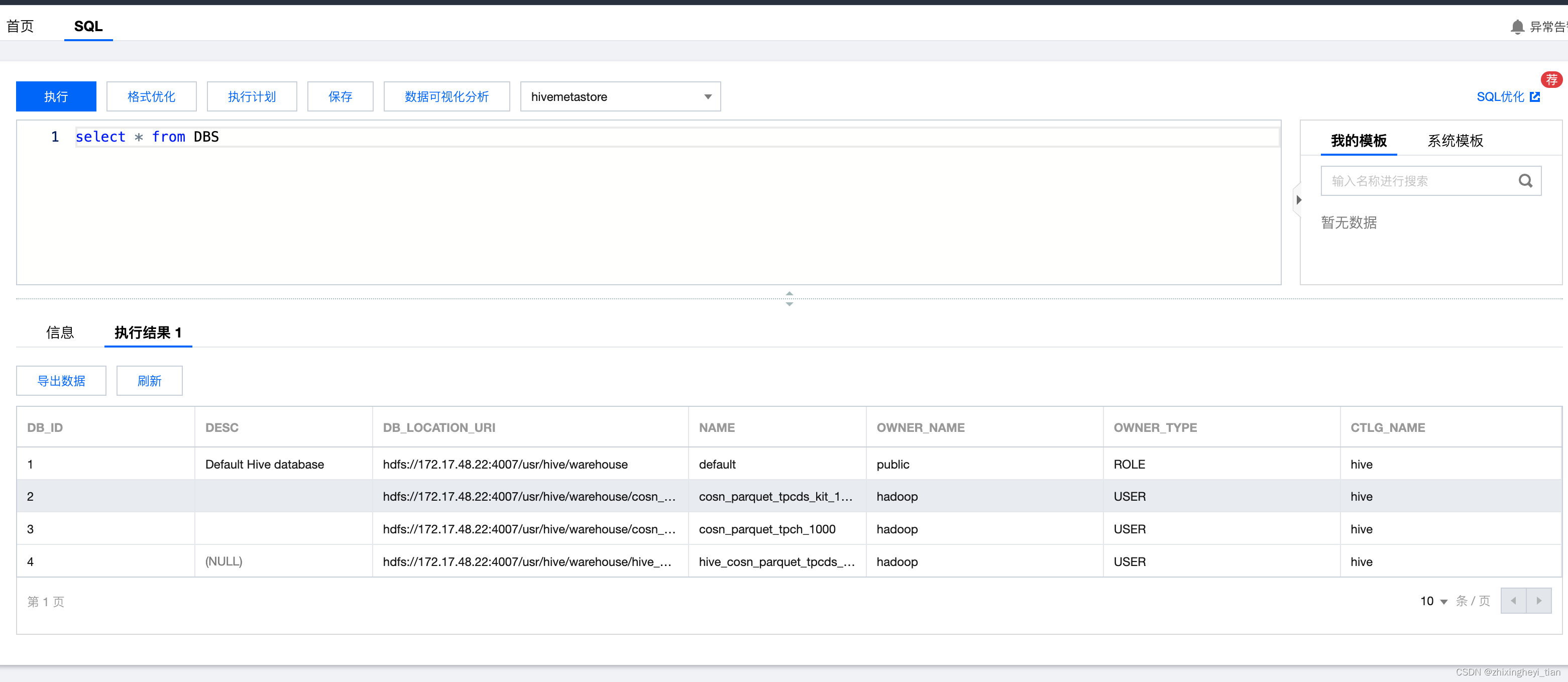
查看Hive表的描述信息,包括在HDFS上的Location信息 2024-06-01 hive, 深度优先, 数据仓库, hadoop, 大数据 173人 已看 DESCRIBE FORMATTED 表名;
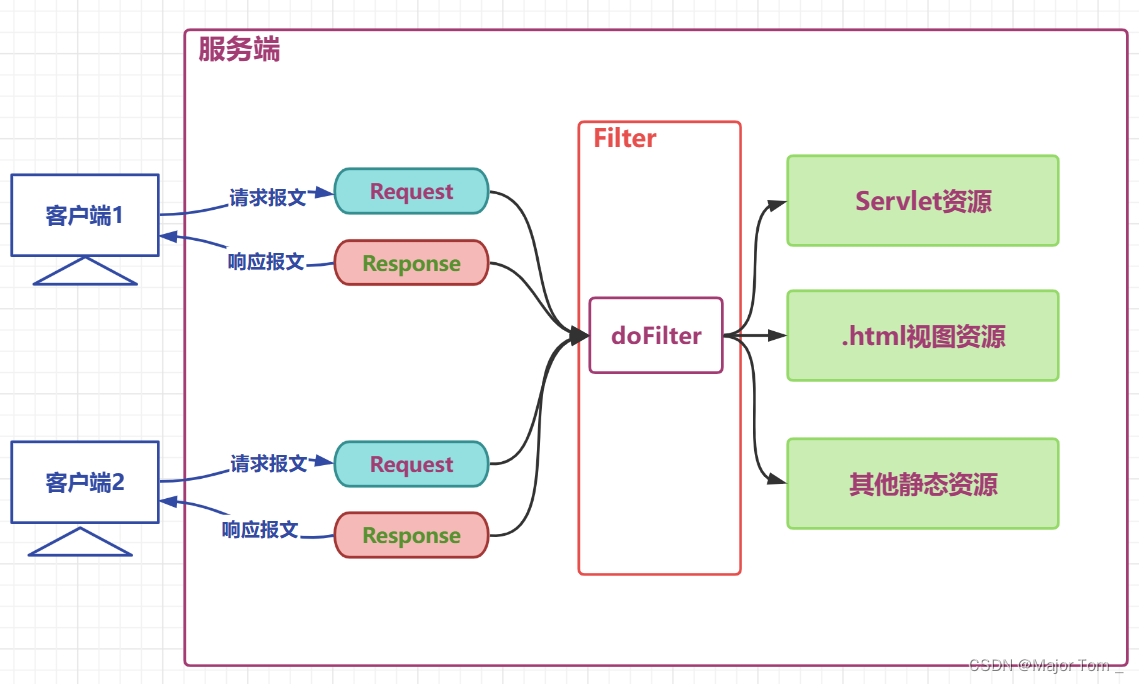
Servlet 2024-05-31 hive, 数据仓库, servlet, hadoop, 大数据 168人 已看 在刚才的入门案例中,我们定义了自己的Servlet,实现的方式都是选择实现Servlet,在Servlet的API介绍中,它提出了我们除了实现Servlet还可以继承GenericServlet和继承HttpServlet,通过查阅servlet的类视图,我们看到Servlet下有一个抽象类GenericServlet,抽象类GenericServlet还有一个子类HttpServlet。我们通过浏览器发送请求,请求首先到达Tomcat服务器,由服务器解析请求URL,然后在部署的应用列表中找到我们的应用。
【Hive SQL 每日一题】统计各个商品今年销售额与去年销售额的增长率及排名变化 2024-05-31 hive, 数据仓库, hadoop, 大数据, sql 169人 已看 惯性思维导致,在排序中,并不是排名越高值越大,相反,因为我们的排名越靠前(越高),其排名值越小,想到这里,就应该明白了。(2)根据(1)中的结果,通过窗口函数排序,获取分别获取两个年度的销售额排名。(3)根据(2)中的结果,判断并计算两个年度的增长率以及排名变化,最终通过。统计各个商品今年销售额与去年销售额的增长率及销售额的排名变化。(1)获取去年与今年两个年度的数据,并进行聚合统计。可能对于排名那里存在疑惑,为什么是。连接商品表,获取商品名称。
数据仓库与数据挖掘总复习练习2-3(实验六 2024.6.5) 2024-06-05 spark, 数据仓库, 人工智能, 分布式, 大数据, 数据挖掘 160人 已看 cities中index:数值,data:地名。(index中值最好不要重复,避免计算错误)一列作为index,一列作为数据。
10_JavaWeb过滤器 2024-06-05 hive, 数据仓库, hadoop, 大数据 140人 已看 关于路径的配置过滤器可以url-pattern或者直接写url-name都可。下面写法是通过url-pattern配置 批Servlet匹配;3.过滤 doFilter (多次)生活举例: 公司前台,停车场安保,地铁验票闸机。1.构造 constorct 默认重写。java中过滤仅仅是对请求做出过滤。4.销毁 destory。过滤器开发中应用的场景。2.初始化 init。
数据仓库与数据挖掘总复习练习2-3(实验六 2024.6.5) 2024-06-05 spark, 数据仓库, 人工智能, 分布式, 大数据, 数据挖掘 166人 已看 cities中index:数值,data:地名。(index中值最好不要重复,避免计算错误)一列作为index,一列作为数据。
大数据基础问题:在Hive中如何实现全增量统一的UDTF、内置函数、聚合、Join等计算引擎常见算子? 2024-06-04 hive, 数据仓库, hadoop, 大数据 123人 已看 大数据行业的Hive可谓是精兵强将。HiveQL支持丰富的SQL功能,包括但不限于数据定义语言(DDL)、数据操作语言(DML)、聚合函数、窗口函数、子查询等
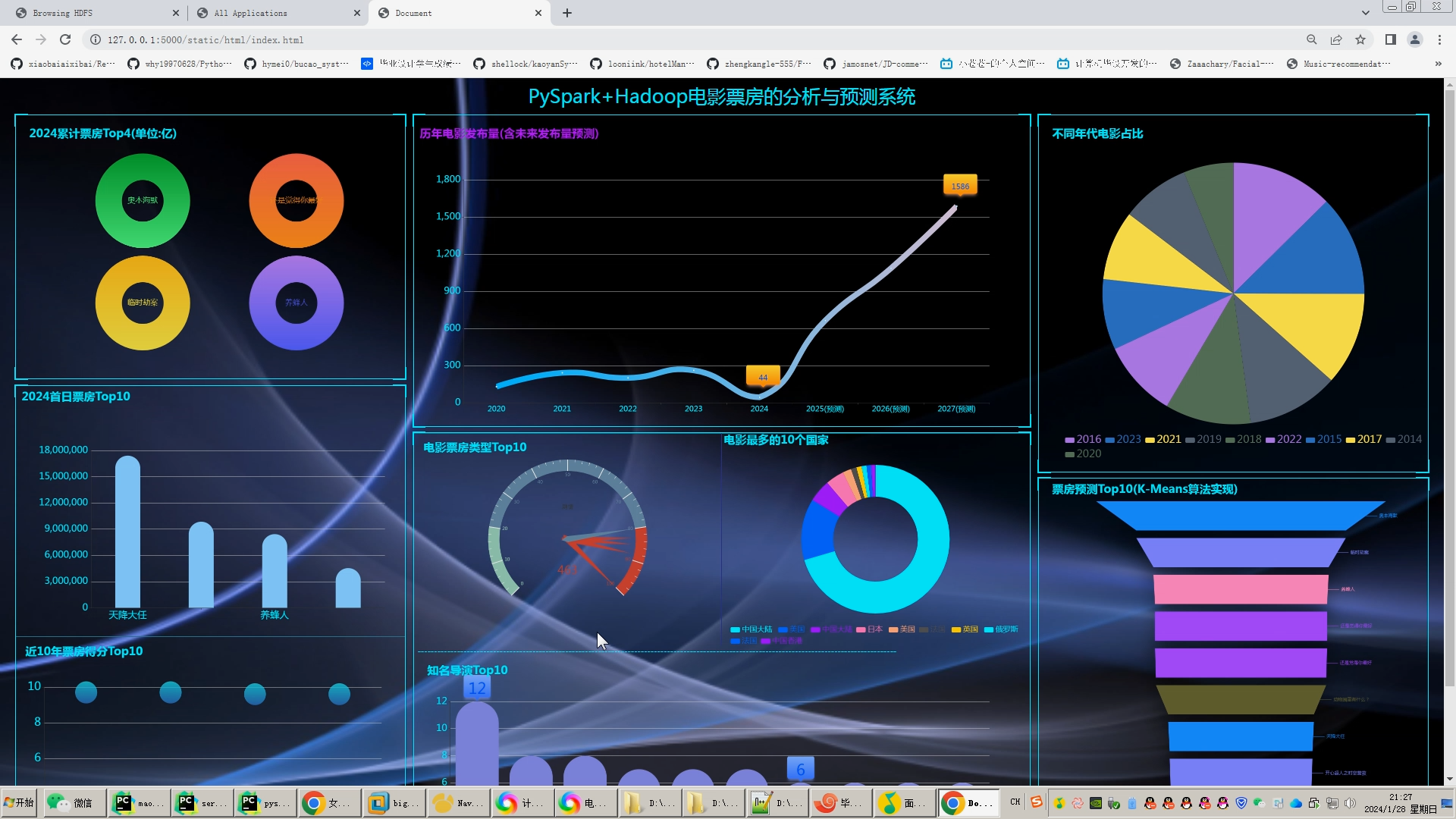
计算机毕业设计python+hadoop+spark猫眼电影票房预测 电影推荐系统 猫眼电影爬虫 电影数据可视化 电影用户画像系统 协同过滤算法 数据仓库 2024-06-04 爬虫, python, 信息可视化, 数据仓库, spark, hadoop, 开发语言 272人 已看 计算机毕业设计python+hadoop+spark猫眼电影票房预测 电影推荐系统 猫眼电影爬虫 电影数据可视化 电影用户画像系统 协同过滤算法 数据仓库
ServletContext 2024-06-02 hive, 数据仓库, servlet, hadoop, 大数据 178人 已看 ServletContext 是应用上下文对象。每一个应用中只有一个 ServletContext 对象, 这个ServletContext 对象被所有Servlet所共享.在 Servlet 规范中,一共有 4 个域对象。ServletContext 就是其中的一个。它也是 web 应用中最大的作用域,也叫 application 域。它可以实现整个应用之间的数据共享!生命周期:应用一加载则创建,应用被停止则销毁。
大数据面试题 —— Hive 2024-05-19 hive, 数据仓库, hadoop, 大数据 126人 已看 (1)承UDF或者UDAF或者UDTF,实现特定的方法;(2)打成jar包,上传到服务器(3)执行命令add jar路径,目的是将 jar 包添加到 hive 中create temporary function 函数名 as "自定义函数全类名"(5)在select中使用 UDF 函数。