【C++】、【Redis】、【人工智能】与【大数据】的深度整合 2024-06-08 c++, 人工智能, 缓存, 数据库, redis, 大数据 226人 已看 总之,C++和人工智能的深度整合在游戏开发、机器人技术、自然语言处理、深度学习框架、实时系统应用、嵌入式系统和科学计算等多个领域都有广泛的应用场景。这些应用场景体现了C++在高性能计算、底层控制、实时性和稳定性等方面的优势,使其成为人工智能领域不可或缺的技术之一。C++、Redis、人工智能和大数据的深度整合涉及多个方面,包括数据存储、处理、优化以及在不同技术栈之间的交互。一、C++与Redis的整合。二、C++与人工智能的整合。三、C++与大数据的整合。
软考-架构设计师-综合知识总结(试卷:2009~2022)(下篇) 2024-06-11 数据库 67人 已看 本文档对2009到2022年试卷的综合知识进行了归纳总结,同时对叶宏主编的《系统架构设计师教程》划分重点。
【rust 第三方库】serde 序列化反序列化框架 2024-06-11 rust, 后端, 数据库, 开发语言 199人 已看 Serde是主流的rust序列化、反序列化框架。设计上,基于rust的静态类型系统和元编程(宏)的能力,使Serde序列化的执行速度与手写序列化器的速度相同。使用上及其简单用户为自己的类型实现Serialize和特质即可(大多数使用derive宏实现)序列化提供商,提供Serializer和特征的实现即可。若要数据类型支持序列化和反序列化,则该类型需要实现Serialize和trait。Serde提供了rust基础类型和标准库类型的Serialize和实现。对于自定义类型,可以自行实现。
【rust 第三方库】serde 序列化反序列化框架 2024-06-11 rust, 后端, 数据库, 开发语言 186人 已看 Serde是主流的rust序列化、反序列化框架。设计上,基于rust的静态类型系统和元编程(宏)的能力,使Serde序列化的执行速度与手写序列化器的速度相同。使用上及其简单用户为自己的类型实现Serialize和特质即可(大多数使用derive宏实现)序列化提供商,提供Serializer和特征的实现即可。若要数据类型支持序列化和反序列化,则该类型需要实现Serialize和trait。Serde提供了rust基础类型和标准库类型的Serialize和实现。对于自定义类型,可以自行实现。
SQL 数据库学习 Part 1 2024-06-11 oracle, 数据库, sql 112人 已看 数据库是长期存储在计算机内、有组织的可共享的数据集合用户与操作系统之间的一层数据管理软件,科学地组织和存储数据、高效地获取和维护数据计算机系统中引入数据库后地系统构成数据的逻辑结构(数据项的名字、类型、取值范围等)数据之间的联系数据有关的安全性、完整性要求数据库用户(包括用户程序员和最终用户)使用的局部数据的逻辑结构和特征的描述数据库用户的数据视图,是与某一应用有关的数据的逻辑表示数据物理结构和存储方式的描述数据在数据库内部的表示方式。
构建高效的数据存储系统:Python dbm 模块的应用与实践 2024-06-10 python, oracle, 数据库, 开发语言 174人 已看 dbm(Database Manager)是Python中的一个模块
【MySQL】数据类型 2024-06-11 mysql, 数据库 125人 已看 本篇主要介绍了MySQL的数据类型,用以创建更加丰富的表结构,主要从理论和实践的角度出发,对数据类型进行了基本的说明,并选出加黑部分进行了实践演示,希望各位读者有所收获。
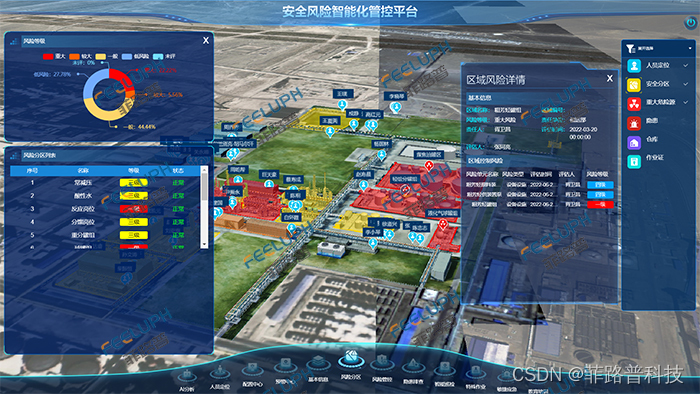
安全生产信息化平台:高效构建安全台账管理体系 2024-06-11 安全, 人工智能, 数据库, 大数据 155人 已看 安全生产信息化平台通过数据标准化、流程自动化、智能化分析、可视化展示和移动化应用,构建高效安全台账管理体系,提升管理效率和质量,降低安全事故风险,企业应积极推进应用。
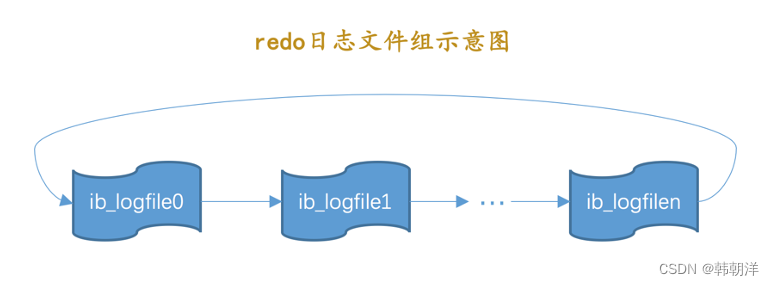
mysql中 redo日志(下) 2024-06-08 mysql, 数据库 116人 已看 大家好。上篇文章我们介绍了什么是redo日志以及redo日志的写入过程。建议没看过上篇文章的同学先看一下《mysql那些事儿》之 redo日志(上),今天我们继续来说一说redo日志。
Linux - 深入理解/proc虚拟文件系统:从基础到高级 2024-06-07 java, linux, 前端, 服务器, 数据库 131人 已看 通过读取/proc/stat和/proc/loadavg等文件,可以获取CPU使用情况和系统负载信息,这对于性能监控和容量规划非常有用。虚拟内存管理是系统性能优化的重要方面,通过监控/proc/vmstat文件,可以了解系统的虚拟内存使用情况,并进行相应的调优。监控系统的CPU使用情况是系统管理员的常见任务,通过读取/proc/stat文件,可以获取每个CPU的使用情况。/proc/sys/fs/file-nr文件可以用于监控系统中文件句柄的使用情况,以防止文件句柄耗尽的问题。
Flink Watermark详解 2024-06-04 flink, java, 前端, 数据库, javascript 195人 已看 Watermark 是用于处理流数据中事件时间(event time)乱序情况的重要机制。在流处理中,数据往往不是按照它们实际发生的时间顺序到达的,这可能是由于网络延迟、系统处理延迟或其他因素导致的。为了能够在这种乱序环境中正确地执行基于时间的操作(如时间窗口聚合),Flink 引入了 Watermark 的概念。Watermark 是一个特殊的标记,它表示“在此时间戳之前的数据应该都已经到达了”。
springAOP 使用aop代替SqlsessionUtil业务层操作 2024-06-04 spring, java, 后端, 数据库, sql 133人 已看 第一种方式是针对service包所有的方法,包括增删改和查询操作,但是查询操作使用线程提交回滚是非必要的,可以修改配置文件,只针对增删改操作进行线程提交和回滚操作。环绕通知实际上就是一个动态代理方法的重写,可以看到格式和jdk动态代理,cglib动态代理一样。在执行目标对象方法前使用前置通知拿到方法名,判断是否是查询操作在进行后置通知的提交回滚操作。添加之后可以使用aop的其他注解:@Pointcut;@Before...@Aspect表明这是一个切面,
flink实战--⼤状态作业调优实践指南-Flink SQL 作业篇 2024-06-04 flink, linq, 数据库, 大数据, sql 263人 已看 作为一种特定领域语言,SQL 的设计初衷是隐藏底层数据处理的复杂性,让用户通过声明式语言来进行数据操作。而Flink SQL 由于其架构的特殊性,在实现层面通常需引入状态后端 配合 checkpoint 来保证计算结果的最终一致性。目前 Flink SQL 生成状态算子的策略由优化器根据配置项 + SQL 语句来推导,想要在处理有状态的大规模数据和性能调优方面游刃有余的话,用户还是需要对 SQL 状态算子生成机制和管理策略有一定了解。