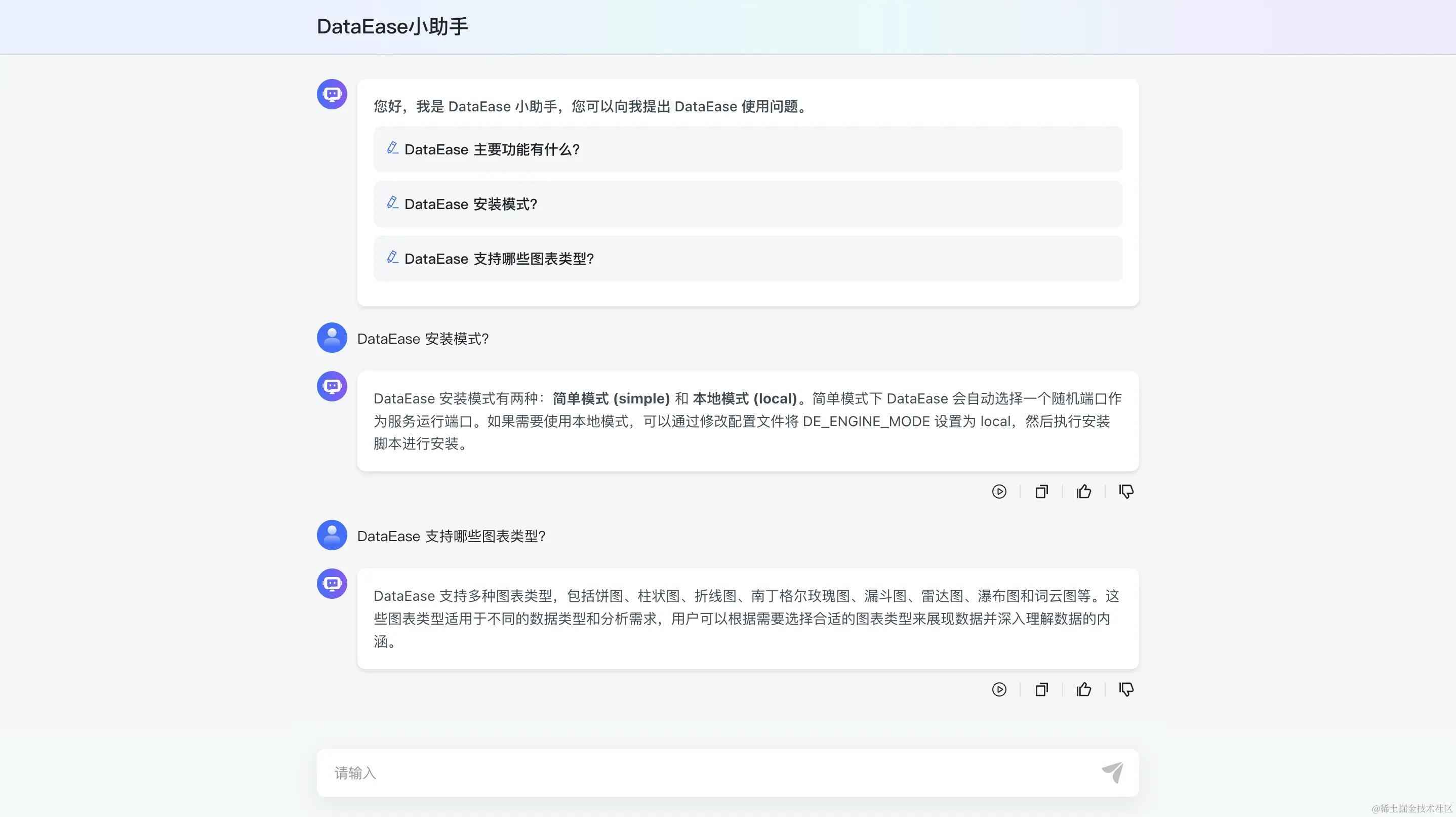
大语言模型RAG-将本地大模型封装为langchain的chat model(三) 2024-06-05 语言模型, 人工智能, 自然语言处理 172人 已看 这个类就是本地llm的langchain封装,需要定义以下方法或属性。这是后面构建RAG应用的基础。模型为例,演示最基础使用方法。还在0.1时代,这期使用的。已经与之前不兼容了。
构建大型语言模型(LLM)产品的实战指南 2024-06-04 语言模型, 人工智能, 自然语言处理 145人 已看 每周跟踪AI热点新闻动向和震撼发展 想要探索生成式人工智能的前沿进展吗?订阅我们的简报,深入解析最新的技术突破、实际应用案例和未来的趋势。与全球数同行一同,从行业内部的深度分析和实用指南中受益。不要错过这个机会,成为AI领域的领跑者。点击订阅,与未来同行!订阅:https://rengongzhineng.io/使用大型语言模型(LLM)进行开发的时代令人兴奋。过去的一年中,LLM在实际应用中的表现已经达到“足够好”的水平,并且每年都在变得更好且更便宜。
Monaco Editor系列(六)Range详解、Uri 自动匹配语言模型、缩略图 miniMap 配置 2024-06-04 c#, 语言模型, 人工智能, 自然语言处理, 开发语言 158人 已看 前情回顾:一鼓作气,再鼓,再鼓!!哈哈哈。争取早日占领 Monaco 领地。上一篇文章讲到的三个功能分别是 Position 类型、设置 markers、指定位置插入或替换内容涉及到的知识点:⛈️ 获取光标位置:⛈️ 获取某个位置处的单词:这一篇文章继续来探索更多的功能吧!遨游在 monaco editor 的世界里是不是很快乐啊哈哈哈哈(bushi,大佬写的非常好,是少有的成系列的学习 Monaco Editor 的学习资料,并且有很多总结性的东西都给总结好了。
语言模型解构——手搓BPE算法 2024-06-04 算法, 语言模型, 人工智能, 自然语言处理 129人 已看 BPE 的全称是 Byte Pair Encoding,以语料库作为输入,通过学习训练得到一个词库;基于训练出来的词库,对文本进行tokenize;让数据告诉我们如何去tokenize,而不是人工标注;subword tokenizer不是以单词为单位,而是以子词为单位,英语上可以理解成词根词缀;
从零开始:腾讯云轻量应用服务器上部署MaxKB项目(基于LLM大语言模型的知识库问答系统) 2024-06-03 语言模型, 人工智能, 自然语言处理 96人 已看 MaxKB是基于LLM大语言模型的知识库问答系统,旨在成为企业的最强大脑。它支持开箱即用,无缝嵌入到第三方业务系统,并提供多模型支持,包括主流大模型和本地私有大模型,为用户提供智能问答交互体验和灵活性。
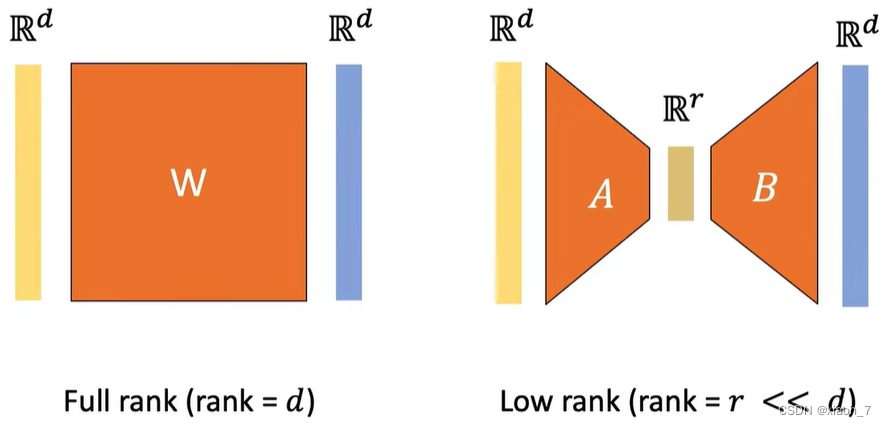
探索Lora:微调大型语言模型和扩散模型的低秩适配方法【原理解析,清晰简洁易懂!附代码】 2024-05-29 语言模型, 人工智能, 自然语言处理 198人 已看 Lora是一种创新且高效的微调大型模型的方法。通过低秩矩阵分解,Lora能够在保持模型性能的同时,显著减少计算资源和存储需求。本文介绍了Lora的背景、原理、公式、代码实现及其效果,希望能帮助你更好地理解和掌握这一方法。随着大型模型在各个领域的广泛应用,Lora的出现为我们提供了一种高效、实用的微调解决方案。
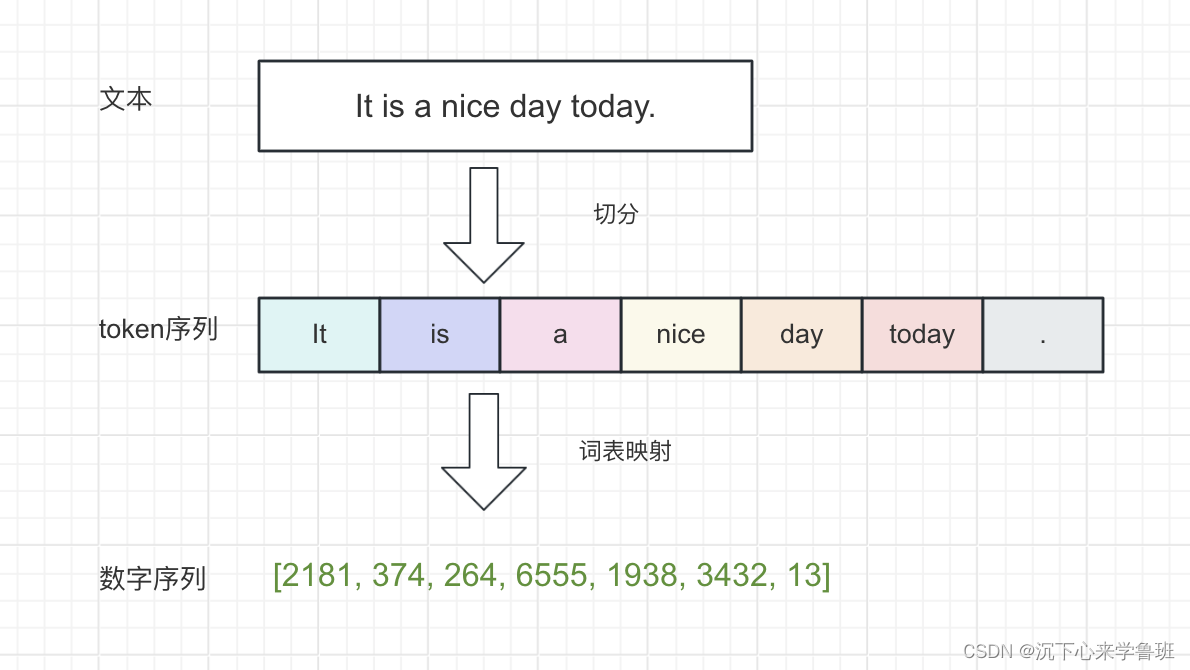
语言模型解构——Tokenizer 2024-05-31 c#, 语言模型, 人工智能, 自然语言处理, 开发语言 93人 已看 Tokenizer是一个词元生成器,它首先通过分词算法将文本切分成独立的token列表,再通过词表映射将每个token转换成语言模型可以处理的数字。
讲解如何使用RAG(检索增强生成)和LLM(大语言模型)来构建一个法律咨询网站。 2024-06-02 语言模型, 人工智能, 自然语言处理 108人 已看 文档预处理:将法律文档转化为向量,存储在Faiss向量数据库中。文档检索:根据用户问题检索相关文档。提取重要段落:从相关文档中提取与用户问题相关的重要段落。生成答案:使用OpenAI的GPT-4生成详细回答。前后端构建:使用Flask构建后端API,用HTML和JavaScript构建简单的前端页面。通过这些步骤,即使是初学者也能逐步理解和实现一个利用RAG+LLM技术的法律咨询网站。
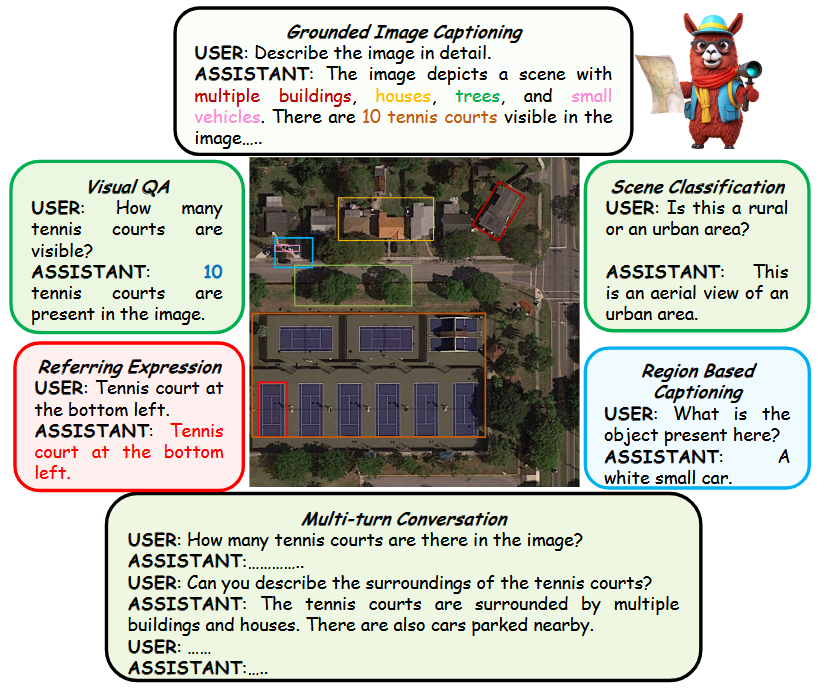
【论文阅读】遥感大模型GeoChat : Grounded Large Vision-Language Model for Remote Sensing 2024-06-02 论文阅读, 语言模型, 人工智能, 自然语言处理 493人 已看 本文是遥感领域的大模型相关的一篇工作,发表在CVPR2024。
大语言模型技术系列讲解:大模型应用了哪些技术 2024-05-31 语言模型, 人工智能, 自然语言处理 81人 已看 为了弄懂大语言模型原理和技术细节,笔者计划展开系列学习,并将所学内容从简单到复杂的过程给大家做分享,希望能够体系化的认识大模型技术的内涵。本篇文章作为第一讲,先列出大模型使用到了哪些技术,目的在于对大模型使用的技术有个整体认知。后续我们讲一一详细讲解这些技术概念并解剖其背后原理。大语言模型(LLMs)在人工智能领域通常指的是参数量巨大、能够处理复杂任务的深度学习模型。大模型通常是深度神经网络的一种,具有多层结构,能够学习数据的复杂表示。
AI推介-大语言模型LLMs论文速览(arXiv方向):2024.04.20-2024.04.25 2024-05-30 语言模型, 人工智能, 自然语言处理 122人 已看 使用检索增强生成(RAG)从外部知识源检索相关信息,可以让大型语言模型(LLM)回答私人和/或以前未见过的文档集合中的问题。但是,RAG 无法回答针对整个文本语料库的全局性问题,例如 “数据集中的主要主题是什么?”,因为这本质上是一个以查询为重点的总结(QFS)任务,而不是一个明确的检索任务。同时,先前的 QFS 方法无法扩展到典型 RAG 系统索引的文本数量。
AI推介-多模态视觉语言模型VLMs论文速览(arXiv方向):2024.05.01-2024.05.10 2024-05-28 语言模型, 计算机视觉, 深度学习, 人工智能, 自然语言处理 135人 已看 医学图像识别任务因存在多种不同的病理指征而明显复杂化,这给未见标签的多标签分类带来了独特的挑战。这种复杂性凸显了对采用多标签零点学习的计算机辅助诊断方法的需求。预训练视觉语言模型(VLMs)的最新进展展示了医疗图像零镜头分类的显著能力。然而,这些方法在利用来自更广泛图像数据集的大量预训练知识方面存在局限性,而且通常依赖于放射科专家的手动提示构建。通过自动调整提示过程,提示学习技术已成为使 VLM 适应下游任务的有效方法。
AI推介-多模态视觉语言模型VLMs论文速览(arXiv方向):2024.05.10-2024.05.20 2024-05-28 语言模型, 人工智能, 自然语言处理 75人 已看 编辑视频时,一段动听的背景音乐必不可少。然而,视频背景音乐生成任务面临着一些挑战,例如缺乏合适的训练数据集,难以灵活控制音乐生成过程并按顺序对齐视频和音乐。在这项工作中,我们首先提出了一个高质量的音乐视频数据集 BGM909,该数据集具有详细的注释和镜头检测功能,可提供视频和音乐的多模态信息。然后,我们提出了评估音乐质量的评价指标,包括音乐多样性和音乐与视频之间的匹配度以及检索精度指标。
LLM大语言模型学习资料网站(git、gitee、等) 2024-05-30 学习, git, 语言模型, 人工智能, 自然语言处理 154人 已看 LLM的火爆程度不用多说,如果想深入理解大语言模型(LLM),一些必要的论文还是要读的。以下是汇总的LLM大语言模型学习资料网站(Git、Gitee、模型社区等)
AI推介-大语言模型LLMs论文速览(arXiv方向):2024.05.01-2024.05.05 2024-05-30 语言模型, 人工智能, 自然语言处理 92人 已看 虽然大型语言模型(LLMs)作为交互任务中的代理已显示出巨大的前景,但其巨大的计算需求和有限的调用次数限制了其实际效用,特别是在决策等长时交互任务或涉及持续不断任务的场景中。为了解决这些制约因素,我们提出了一种方法,将拥有数十亿参数的 LLM 的性能转移到更小的语言模型(7.7 亿参数)中。我们的方法包括构建一个由规划模块和执行模块组成的分层代理,规划模块通过从 LLM 中进行知识提炼来生成子目标,而执行模块则通过学习使用基本动作来完成这些子目标。
AI推介-大语言模型LLMs论文速览(arXiv方向):2024.05.10-2024.05.20 2024-05-29 语言模型, 人工智能, 自然语言处理 83人 已看 预训练+微调范式是在各种下游应用中部署大型语言模型(LLM)的基础。其中,Low-Rank Adaptation(LoRA)因其参数高效微调(PEFT)而脱颖而出,产生了大量现成的针对特定任务的 LoRA 适配程序。然而,这种方法需要明确的任务意图选择,这给推理过程中的自动任务感知和切换带来了挑战,因为现有的多个 LoRA 适配程序都嵌入了单个 LLM 中。在这项工作中,我们介绍了 MeteoRA(多任务嵌入式 LoRA),这是一个专为 LLM 设计的可扩展多知识 LoRA 融合框架。
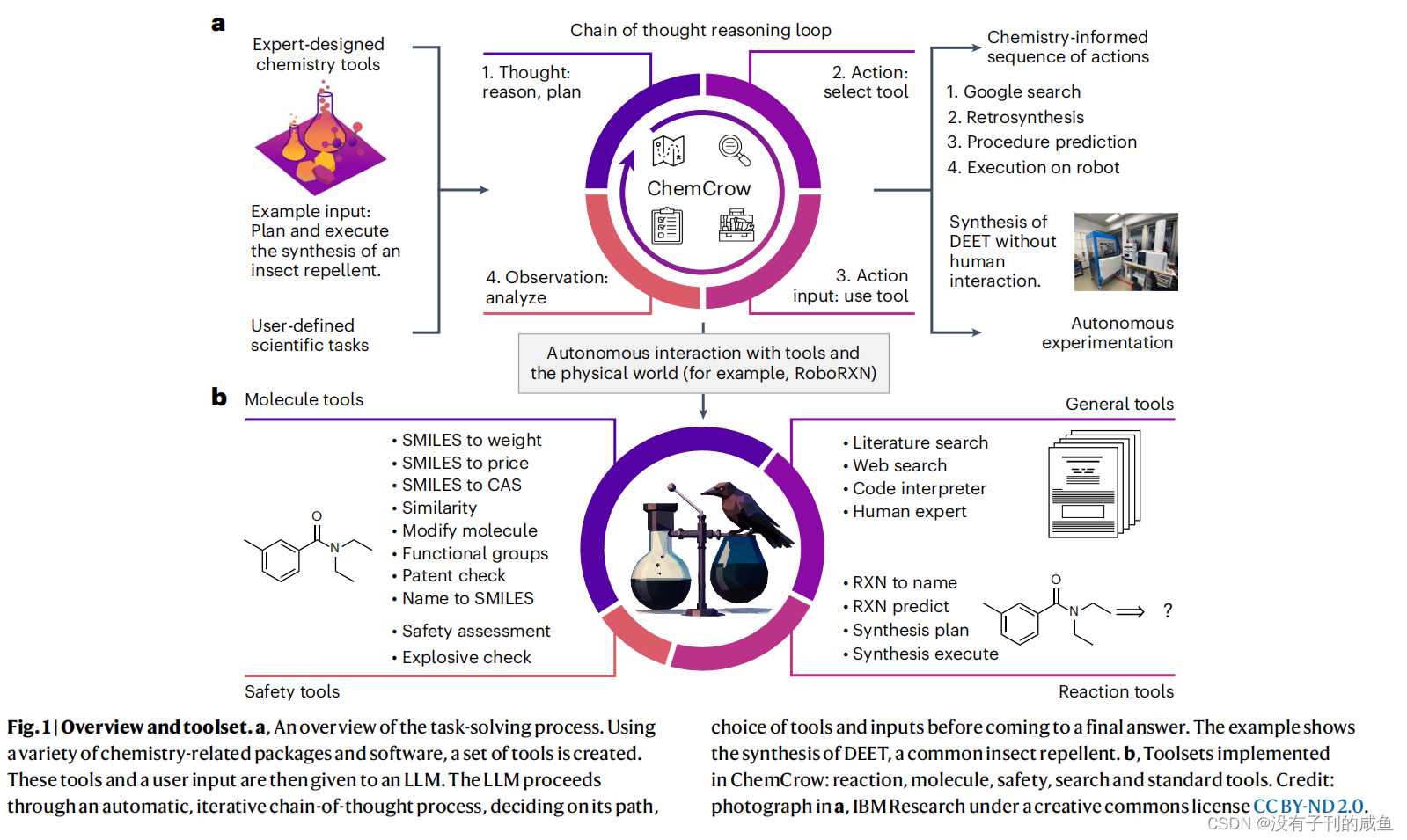
论文阅读笔记(十二)——Augmenting large language models with chemistry tools 2024-05-30 论文阅读, 笔记, 语言模型, 人工智能, 自然语言处理 186人 已看 大型语言模型(LLMs)在跨领域任务中表现出色,但在化学相关问题上却表现不佳。这些模型也缺乏外部知识源的访问权限,限制了它们在科学应用中的有用性。我们介绍了ChemCrow,这是一种设计用于完成有机合成、药物发现和材料设计任务的LLM化学代理。通过集成18个专家设计的工具,并使用GPT-4作为LLM,ChemCrow增强了LLM在化学领域的性能,并展现了新的能力。我们的代理自主规划和执行了昆虫驱避剂和三种有机催化剂的合成,并指导发现了一种新的发色团。
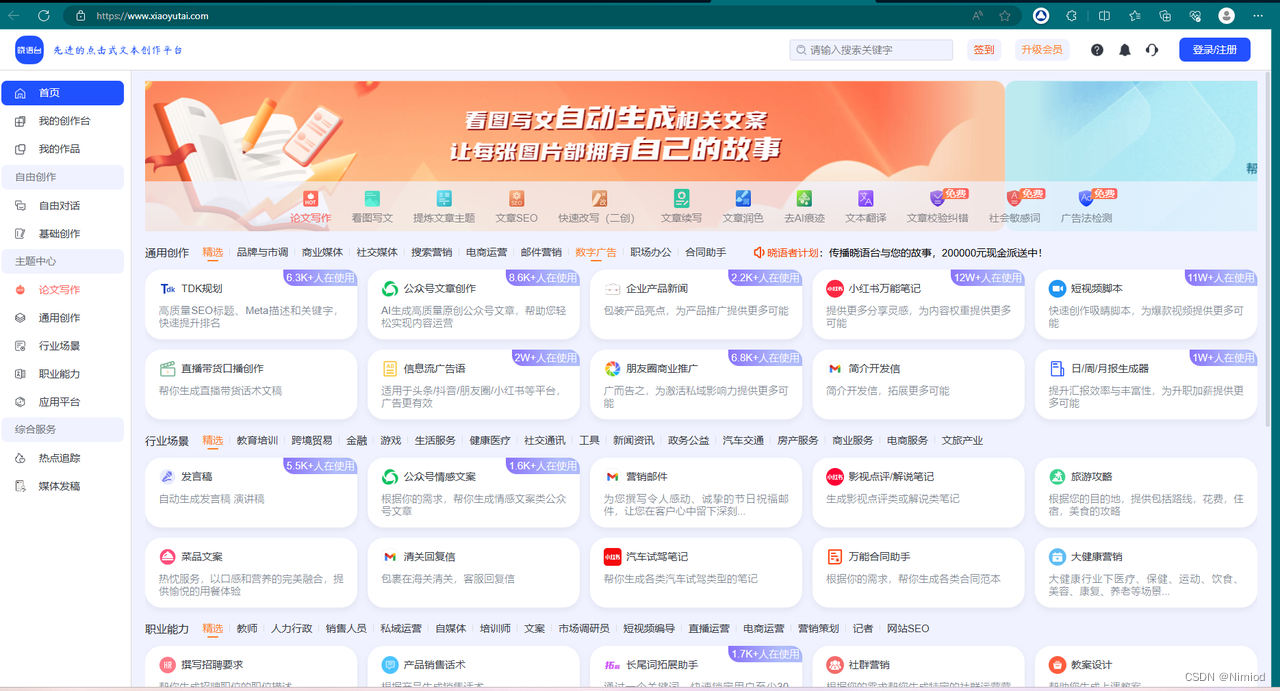
晓语台:基于大语言模型和深度学习技术的智能创作平台,高效、个性化地创作高质量内容。 2024-05-28 语言模型, 深度学习, 人工智能, 自然语言处理, 大数据 109人 已看 除了基本的文本内容生成功能,晓语台还提供了对话创作、自由扩写、文本润色、续写改写、内容翻译、文章校验、广告法检测等辅助创作功能,满足用户在创作过程中的各种需求。多样化的创作场景:晓语台覆盖了品牌与市场调研、商业媒体、社交媒体、搜索营销、数字广告和职场办公等六类全营销文本的高维创作场景,满足用户在各种行业、平台和职业中的文案创作需求。多种辅助创作功能:除了文本内容生成外,晓语台还提供了对话创作、自由扩写、文本润色、续写改写、内容翻译、文章校验、广告法检测等辅助创作功能,满足用户的不同需求。