Flink 容错 2024-06-05 flink, 大数据 96人 已看 Flink的容错机制是确保数据流应用程序在出现故障时能够恢复一致状态的关键组成部分。其核心是通过创建分布式数据流和操作符状态的一致快照来实现,这种快照被称为检查点(Checkpoint)。
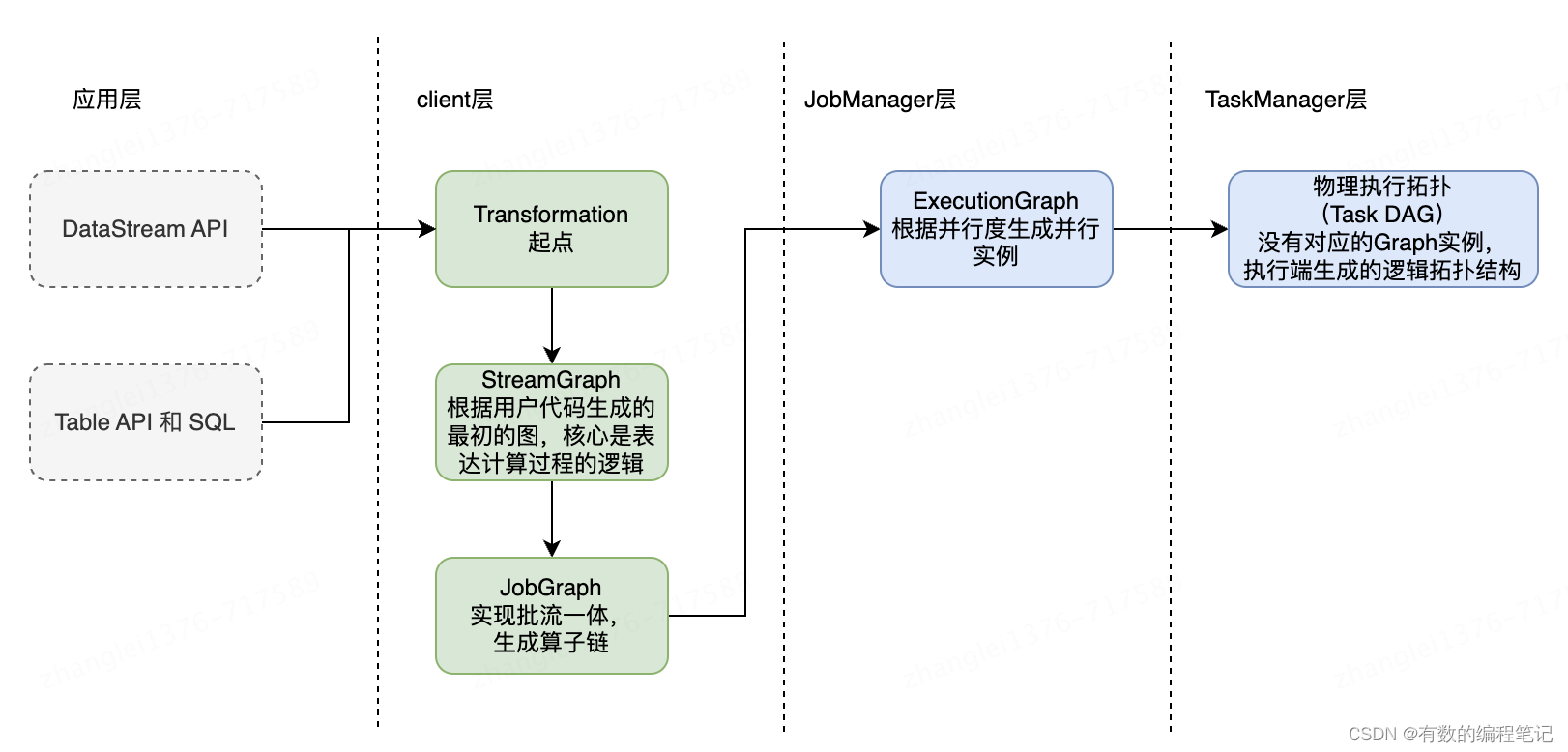
Flink任务如何跑起来之 1.DataStream和Transformation 2024-06-06 flink, 大数据 113人 已看 在使用Flink完成业务功能之余,有必要了解下我们的任务是如何跑起来的。知其然,知其所以然。既然重点是学习应用程序如何跑起来,那么应用程序的内容不重要,越简单越好。WordCount示例作为学习数据引擎时hello word程序,再合适不过。接下来便以任务执行顺序为线索开启对源码逐步学习。为了使示例代码足够纯粹(直接复制粘贴后即可跑起来的那种),因此在示例中直接使用List数据作为Source。最后,计划将自己学习的过程以系列文档的形式作为记录。
flink 状态 2024-06-04 flink, java, 大数据, 开发语言 96人 已看 使用Flink的Stateful Functions API(如KeyedProcessFunction、ProcessFunction等)来定义和访问状态。通过getRuntimeContext().getState(…)或特定的状态描述符(如ValueStateDescriptor)来获取状态。Broadcast State用于保持所有子任务状态相同,确保当数据被广播到所有下游并行任务时,这些任务可以访问相同的状态数据。在这些任务中广播状态用于保持所有子任务状态相同。
活动预告|6月13日Apache Flink Meetup·香港站 2024-05-31 flink, apache, 大数据 89人 已看 Apache Flink Meetup 的风吹到了香江之畔,Apache Flink 香港 Meetup 来啦!本次活动,我们邀请了来自阿里云的顶尖专家,帮助开发者全面了解 Apache Flink 的流批一体的数据处理能力,流式数据湖的关键特性,全方位解析 Apache Flink 流数据处理和基于 Apache Paimon 的流式湖仓技术架构,让您更好的利用阿里云为业务创造更大价值!
Flink 通过 paimon 关联维表,内存降为原来的1/4 2024-05-28 flink, 运维, linux, 服务器, 大数据 88人 已看 本文介绍了如何通过替换维表实现FlinkSQL任务内存占用的优化。作者通过分析Iceberg lookup部分源码,发现其cache的数据会存在内存中,导致内存占用过大。作者将维表替换为paimon,通过分析paimon维表的原理,发现其cache的数据存储在rocksdb中,从而实现了内存占用的降低。
整库同步 Catalog 和 Flink CDC 2024-05-28 flink, 数据库, 大数据 82人 已看 Flink CDC连接器的主要目的是从关系型数据库中的binlog(二进制日志)中捕获变更事件,并将这些事件作为数据流传递给Flink应用程序进行处理。Catalog是数据库管理系统(DBMS)中用于存储元数据信息的组件,它包含了数据库对象(如表、视图、函数等)的定义和描述。通常情况下,Flink CDC连接器并不直接操作Catalog数据,而是通过解析binlog来捕获对数据库对象的变更。然而,一些特定的CDC实现或特殊的配置可能会考虑到对Catalog数据的变更进行捕获和处理。
Kafka篇:Kafka搭建、使用、及Flink整合Kafka文档 2024-06-01 flink, linq, kafka, 分布式, 大数据 136人 已看 Kafka搭建、使用、及Flink整合Kafka
Flink 通过 paimon 关联维表,内存降为原来的1/4 2024-05-28 flink, 运维, linux, 服务器, 大数据 86人 已看 本文介绍了如何通过替换维表实现FlinkSQL任务内存占用的优化。作者通过分析Iceberg lookup部分源码,发现其cache的数据会存在内存中,导致内存占用过大。作者将维表替换为paimon,通过分析paimon维表的原理,发现其cache的数据存储在rocksdb中,从而实现了内存占用的降低。
Hudi Flink MOR 学习总结 2024-05-28 flink, 学习, 数据库, 大数据 69人 已看 之前很少用MOR表,现在来学习总结一下。首先总结一下 compaction 遇到的问题。
整库同步 Catalog 和 Flink CDC 2024-05-28 flink, 数据库, 大数据 66人 已看 Flink CDC连接器的主要目的是从关系型数据库中的binlog(二进制日志)中捕获变更事件,并将这些事件作为数据流传递给Flink应用程序进行处理。Catalog是数据库管理系统(DBMS)中用于存储元数据信息的组件,它包含了数据库对象(如表、视图、函数等)的定义和描述。通常情况下,Flink CDC连接器并不直接操作Catalog数据,而是通过解析binlog来捕获对数据库对象的变更。然而,一些特定的CDC实现或特殊的配置可能会考虑到对Catalog数据的变更进行捕获和处理。
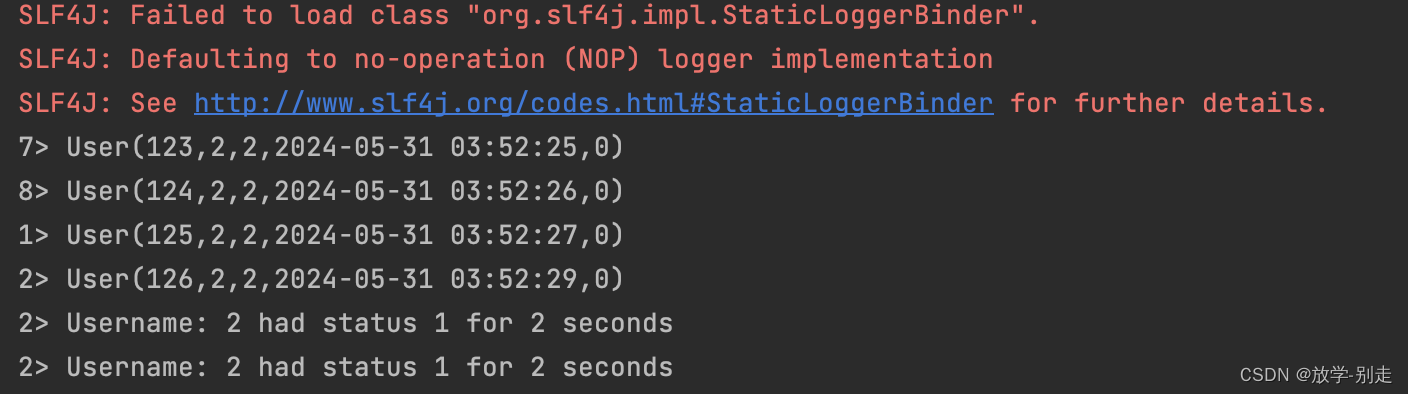
Flink实现实时异常登陆监控(两秒内多次登陆失败进行异常行为标记) 2024-05-31 flink, 大数据 61人 已看 从 MySQL 数据库读取用户登录数据。过滤出特定状态的登录记录。对这些记录进行时间窗口处理。将异常登陆结果写回 MySQL 数据库。
Flink实现实时异常登陆监控(两秒内多次登陆失败进行异常行为标记) 2024-05-31 flink, 大数据 69人 已看 从 MySQL 数据库读取用户登录数据。过滤出特定状态的登录记录。对这些记录进行时间窗口处理。将异常登陆结果写回 MySQL 数据库。
Flink系列一:flink光速入门 (^_^) 2024-05-28 flink, 大数据 61人 已看 引入(spark和flink的区别),离线和实时的区别,主流实时计算框架对比,Spark Streaming微批处理 与Flink流式处理对比,Apache Flink简介(概述、特性、组件栈),入门案例
flink 操作mongodb的例子 2024-05-30 flink, 数据库, mongodb, 大数据 85人 已看 flink mongo从一个Collection获取数据然后插入到另外一个Collection中。