Flink状态数据结构升级 2024-05-22 flink, 大数据, 数据结构 110人 已看 目前,仅支持 POJO 和 Avro 类型的 schema 升级 因此,如果你比较关注于状态数据结构的升级,那么目前来看强烈推荐使用 Pojo 或者 Avro 状态数据类型。一个例外是如果新的 Avro 数据 schema 生成的类无法被重定位或者使用了不同的命名空间,在作业恢复时状态数据会被认为是不兼容的。Flink 完全支持 Avro 状态类型的升级,只要数据结构的修改是被 Avro 的数据结构解析规则认为兼容的即可。
Flink集群搭建简介 2024-05-17 flink, 大数据 68人 已看 在搭建过程中,如果遇到任何问题,你可以参考Flink的官方文档或者寻求社区的帮助。你可以通过访问Flink的Web UI(默认端口是8081)来查看集群的状态。在Web UI上,你可以看到正在运行的作业、TaskManager的状态等信息。如果你有多个节点(即除了主节点外还有从节点),你需要将Flink的安装目录和配置文件复制到这些从节点上。在提交作业时,你需要指定作业的JAR包路径、入口类名以及其他的运行参数。一旦集群搭建完成并启动,你就可以提交Flink作业到集群上运行了。例如,如果你下载的是。
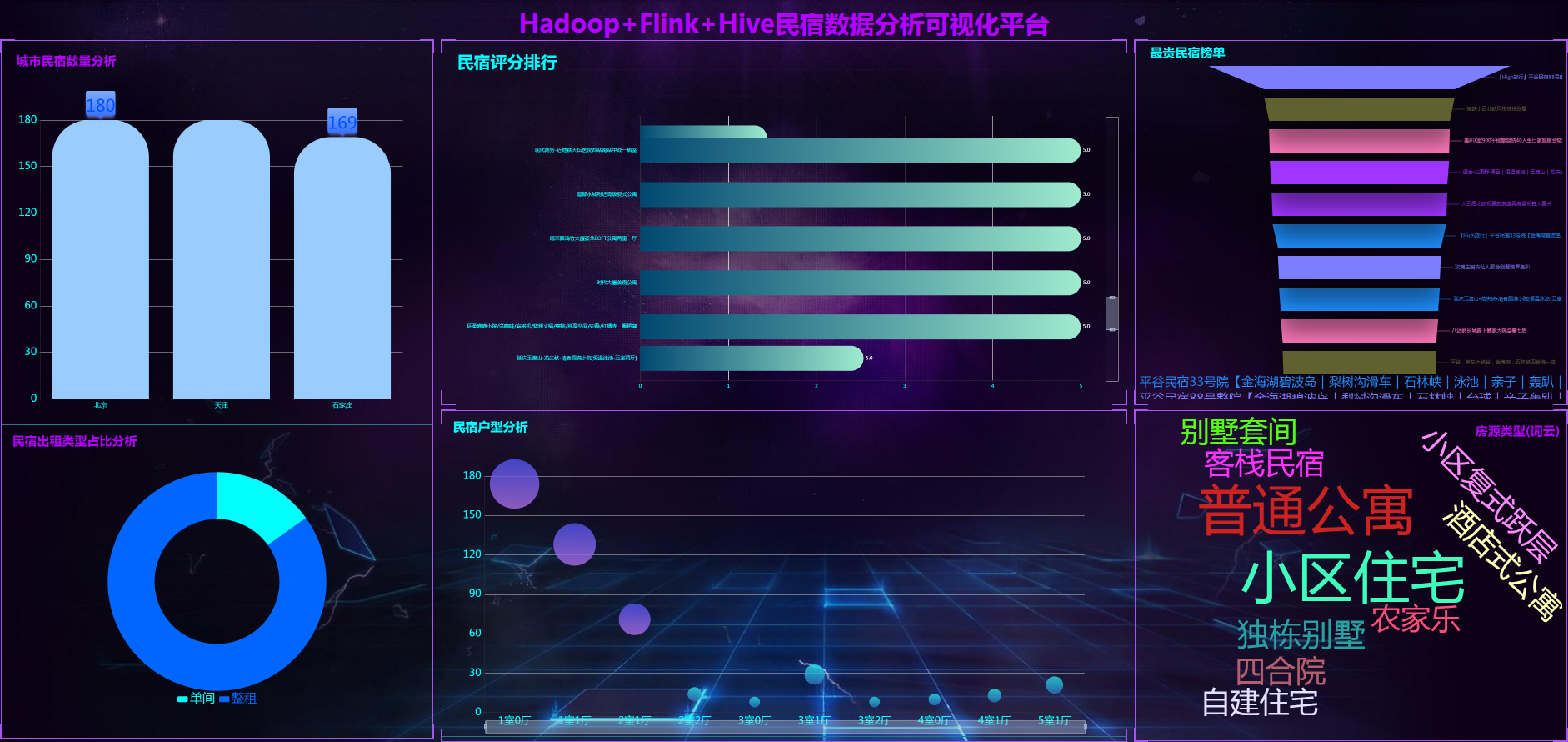
计算机毕业设计PyFlink+Spark+Hive民宿推荐系统 酒店推荐系统 民宿酒店数据分析可视化大屏 民宿爬虫 民宿大数据 知识图谱 机器学习 2024-05-19 hive, flink, 爬虫, 数据分析, 机器学习, spark, 知识图谱, 大数据 303人 已看 计算机毕业设计PyFlink+Spark+Hive民宿推荐系统 酒店推荐系统 民宿酒店数据分析可视化大屏 民宿爬虫 民宿大数据 知识图谱 机器学习
Flink 生态对 Confluent / Kafka Schema Registry 支持情况的研究报告 2024-05-17 flink, linq, kafka, 分布式, 大数据 120人 已看 这几年,在流式链路上引入一个 Schema Registry 变得越来越流行,也越来越有必要, Schema Registry 能有效控制 Schema 的变更,合理推进 Schema Evolution,同时,引入它以后还能有效精简消息内容(特别是针对 Avro 格式),提升消息的传输效率,所以引入 Schema Registry 是有很多正向收益的。在 Flink 生态中,对 Confluent Schema Registry 的支持度如何呢?本文,我们来详细地梳理和总结一下。有关的组件主要是 Flin
本地虚拟机启用Flink CDC连接 Oracle 同步数据到StarRocks问题记录 2024-05-17 flink, oracle, r语言, 数据库, 大数据 131人 已看 4、复制 flink-sql-connector-postgres-cdc-xxx.jar, flink-connector-starrocks-xxx.jar 到 flink-xxx/lib/。2、下载 Flink CDC connector,请注意下载对应 Flink 版本的 flink-sql-connector-postgres-cdc-xxx.jar。我本地访问不了虚拟机的地址,实际上是虚拟机的防火墙是开启的,需要把虚拟机防火墙关闭。1、下载 Flink,我的版本是1.18;
ES 数据写入方式:直连 VS Flink 集成系统 2024-05-15 flink, elasticsearch, 全文检索, 搜索引擎, 大数据 152人 已看 ES 作为一个分布式搜索引擎,从扩展能力和搜索特性上而言无出其右,然而它有自身的弱势存在,其作为近实时存储系统,由于其分片和复制的设计原理,也使其在数据延迟和一致性方面都是无法和 OLTP(Online Transaction Processing)系统相媲美的。也正因如此,通常它的数据都来源于其他存储系统同步而来,做二次过滤和分析的。这就引入了一个关键节点,即 ES 数据的同步写入方式,本文介绍的则是 MySQL 同步 ES 方式。将 MySQL 数据写入 ES,首先想到的一定是消费 Binlog 直连
深入解析Apache Flink核心概念:事件流、状态、事件时间和快照 2024-05-13 flink, apache, 大数据 81人 已看 Apache Flink树立了流处理领域的标杆,其核心支柱——事件流、状态管理、事件时间处理,以及快照机制,共同构成了一个强大而灵活的框架,专为应对大数据的实时和历史分析挑战而设计。
Flink分布式计算架构设计及核心原理实现 2024-05-06 flink, 大数据 66人 已看 胡弦,视频号2023年度优秀创作者,互联网大厂P8技术专家,Spring Cloud Alibaba微服务架构实战派(上下册)和RocketMQ消息中间件实战派(上下册)的作者,资深架构师,技术负责人,极客时间训练营讲师,四维口袋KVP最具价值技术专家,技术领域专家团成员,2021电子工业出版社年度优秀作者,获得2023电子工业出版技术成长领路人称号,荣获2024年电子工业出版社博文视点20周年荣誉专家称号。
Spark面试整理-Spark和Flink的区别 2024-05-06 flink, 面试, spark, 分布式, 大数据 162人 已看 如果应用需要复杂的流处理、低延迟和高吞吐量,Flink可能是更好的选择。而对于批处理或对延迟要求不高的流处理任务,以及需要丰富生态系统和成熟稳定性的场景,Spark可能更加适合。Apache Spark和Apache Flink都是流行的大数据处理框架,但它们在设计理念、性能特性以及适用的使用场景上有所不同。也提供了丰富的API,包括DataStream API和Table API,同时有一定的机器学习和图处理的支持。适合于需要低延迟和高吞吐量的实时流处理应用,以及复杂的事件驱动应用。