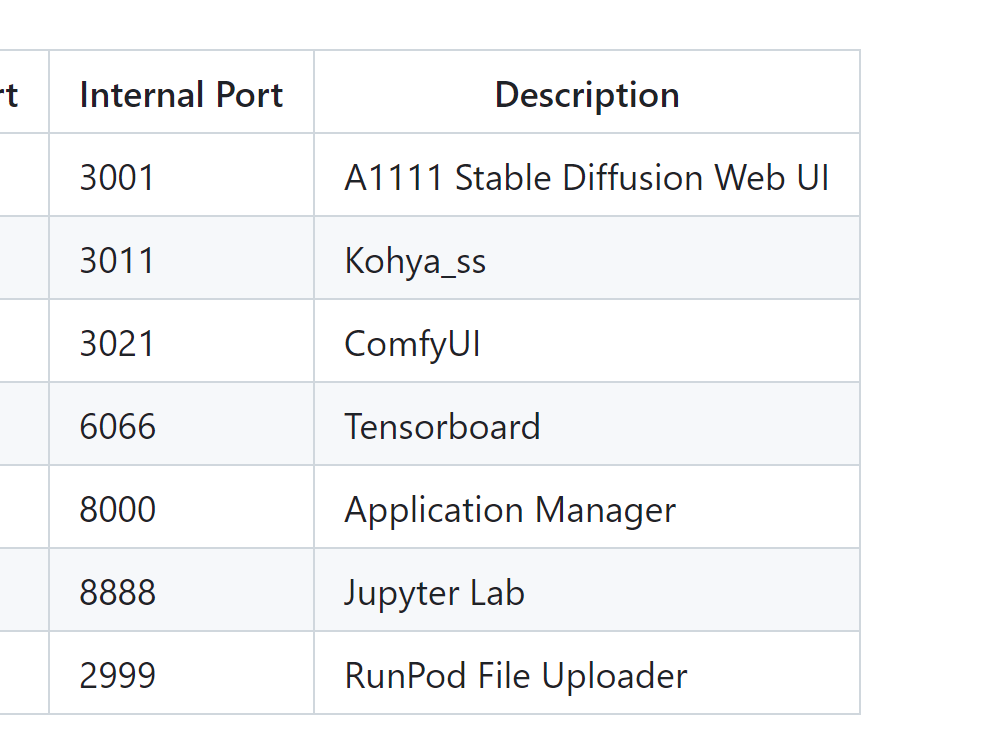
【深度学习】【Lora训练0】StabelDiffusion,Lora训练,kohya_ss训练 2024-05-09 深度学习, 人工智能 110人 已看 资源:(1)训练ui kohya_ss:(2)kohya_ss 的docker+ 其他docker。
豆芽机置入语音芯片WTN6040-8S:开启智能生活新篇章,让豆芽制作更便捷有趣 2024-05-09 生活, 人工智能, 语音识别 115人 已看 豆芽作为一种营养丰富、味道鲜美的食品,深受广大消费者的喜爱。然而,传统的豆芽生产过程繁琐,需要耗费大量的时间和人力,且存在生产效率低、质量不稳定等问题。随着人们生活节奏的加快和对健康饮食的追求,对便捷、高效的豆芽生产方式的需求日益增长。这为豆芽机的开发提供了广阔的市场空间。
【基于 PyTorch 的 Python 深度学习】5 机器学习基础(3) 2024-05-09 python, 机器学习, 深度学习, pytorch, 人工智能 131人 已看 根据吴茂贵《 Python 深度学习基于 PyTorch ( 第 2 版 ) 》撰写的学习笔记,该篇主要介绍了单 GPU 加速和多 GPU 加速,以及使用 GPU 的注意事项。
富格林:营造安全环境稳健出金 2024-05-06 区块链, 安全, 人工智能, 大数据 135人 已看 富格林指出,作为黄金投资中的一种线上投资方式,现货黄金的买卖优势提供了更多的盈利机会。事实上,成功盈利出金的交易需要具备一定的交易技巧,并且营造安全的交易环境。投资者可以通过查询相关监管机构的网站,了解平台是否获得了相应的牌照和资质,以及是否有过违规行为的记录。此外,平台的交易软件也应该易于使用,功能齐全,能够满足投资者的交易需求。投资者在选择平台时,可以了解平台的服务质量和响应速度,以及是否有专业的分析师提供市场分析和建议。投资者需要仔细比较不同平台的交易成本和费用,选择最符合自己交易策略和预算的平台。
pytorch中的数据集处理部分data_transforms = { ‘train‘: transforms.Compose([...])... 2024-05-06 python, 机器学习, 深度学习, pytorch, 人工智能 134人 已看 在PyTorch的深度学习框架中,是一个非常常用的工具,它用于将多个数据转换(或称为“变换”)组合成一个单一的转换流程。这通常用于预处理输入数据,比如图像,以符合模型的训练要求。当你看到这样的代码时,这通常是在一个字典中定义数据预处理流程,其中'train'是键,表示这是用于训练数据的预处理流程。例如,以下是一个常见的图像预处理流程,它使用了在这个例子中,ToTensor()当你使用这样的预处理流程时,你可以确保你的模型在训练时接收到经过适当预处理的数据。
Unity与C++网络游戏开发实战:基于VR、AI与分布式架构 【3.8】 2024-05-06 unity, c++, 游戏引擎, 人工智能, vr 143人 已看 如何管理UI资源的引用?(3)本章开发了仿真系统的各个UI面板,为大家介绍了登录UI、大厅人物系统UI和战场场景交互UI三个面板的开发。·人物和UI面板的互动操作,是基于UI中使用了Game.Instance.GetHostPlayer()来获取HostPlayer这个仿真人物类(见第7章中的相关介绍),通过它相关的函数和属性来操作人员。VRGUI的方式就是把NGUI制作成为3D资源,然后通过3D世界的Camera来渲染,提供一个3D世界的射线检测器,检测UI的操作状况,并且提供事件返回给各个UI组件。
可视化3个10分类 2024-05-09 算法, 机器学习, 人工智能, 数据挖掘, 分类 137人 已看 keras.callbacks.EarlyStopping(monitor="val_loss", patience=5),#超过四次验证损失不减少就停止。x = layers.Rescaling(scale=1.0 / 255)(inputs)#0-1归一化。
谷歌继续将生成式人工智能融入网络安全 2024-05-10 安全, web安全, 人工智能 131人 已看 Google 威胁情报服务旨在帮助安全团队快速准确地整理大量数据,以便更好地保护组织免受网络攻击。
卷积通用模型的剪枝、蒸馏---蒸馏篇--RKD关系蒸馏(以deeplabv3+为例) 2024-05-09 python, 机器学习, 深度学习, 人工智能, 剪枝 324人 已看 本文以deeplabv3+为例,采用RKD蒸馏方法,实现了剪枝前模型对剪之后模型的蒸馏训练。
分享几个.NET开源的AI和LLM相关项目框架 2024-05-06 人工智能, .net, 开源 125人 已看 现如今人工智能(AI)技术的发展可谓是如火如荼,它们在各个领域都展现出了巨大的潜力和影响力。今天大姚给大家分享4个.NET开源的AI和LLM相关的项目框架,希望能为大家提供一些参考。如果你有更好的推荐,欢迎RP投稿或文末留言。
人工智能定向推广:数据驱动的精准营销策略 2024-05-09 人工智能, 搜索引擎 113人 已看 通过对用户行为、兴趣、偏好等海量数据的深入挖掘和分析,人工智能能够洞察用户的真实需求和心理,从而为用户呈现更加符合其个性化需求的广告内容。系统会对广告效果进行持续跟踪和分析,一旦发现广告效果不佳,系统会立即进行调整和优化,以确保广告投放的效果最大化。这种实时监测和优化能力使得人工智能定向推广具有更高的灵活性和适应性,能够更好地应对市场变化和用户需求的变化。这种精准投放方式能够大大提高广告的转化率和ROI(投资回报率),因为用户所看到的广告内容更加符合其个性化需求,更容易引起用户的兴趣和共鸣。
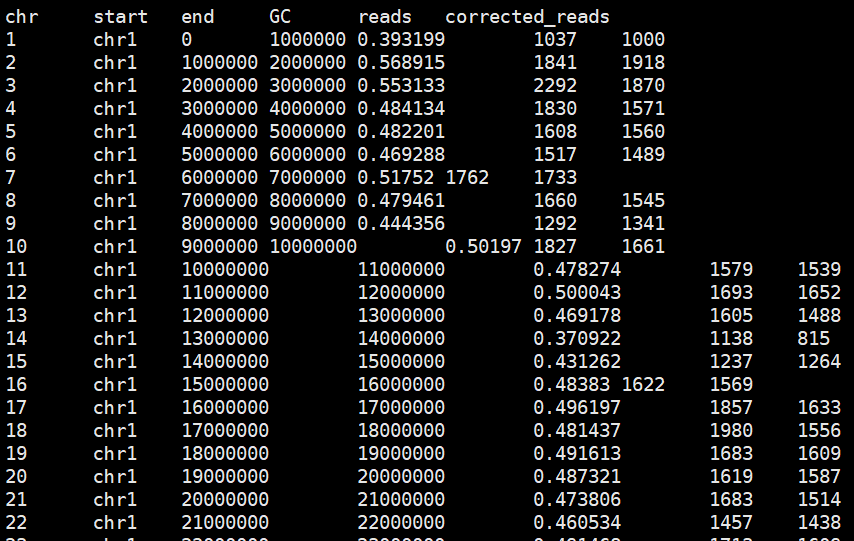
生信分析进阶2 - 利用GC含量的Loess回归矫正reads数量 2024-05-09 算法, 机器学习, 人工智能, 回归, 数据挖掘 370人 已看 在NGS数据比对后,需要矫正GC偏好引起的reads数量误差可用loess回归算法,使用R语言对封装的loess算法实现。
如何用opencv去掉单元格的边框线,以提高Tesseract识别率? 2024-05-09 计算机视觉, 人工智能, opencv 110人 已看 这可能包括灰度化、二值化、去噪等操作。在OpenCV中处理从表格切割下来的图片,并去掉单元格的边框线,以提升Tesseract的识别准确率,确实是一个具有挑战性的任务。4. **填充轮廓**:对于筛选后保留的轮廓(即认为是数字部分的轮廓),可以使用`cv2.drawContours`函数和`cv2.fillPoly`函数来填充这些轮廓,从而去除边框线的影响。5. **后处理**:在填充轮廓后,可能还需要进行一些后处理操作,如形态学操作(腐蚀、膨胀)、连通域分析等,以进一步改进数字与背景之间的对比度。
ChatPPT开启高效办公新时代,AI赋能PPT创作 2024-05-08 人工智能, powerpoint 95人 已看 想想以前啊,为了做个PPT,我得去网上找各种模板,有时候还得在某宝上花钱买。结果一做PPT,经常就得熬个通宵,真心累人。但现在不一样了,咱们活在了一个超级棒的时代——AI时代!现在做PPT,你点点鼠标,大纲、PPT就自动生成了,最慢也就一个小时,以前得熬通宵的活儿,现在轻松搞定了今天就给大家介绍个神器——ChatPPT。它是个超级智能的PPT制作小助手,用AI技术帮你一键生成PPT。
与Apollo共创生态:助力自动驾驶迈向新台阶 2024-05-06 自动驾驶, 机器学习, 人工智能 135人 已看 Apollo计划展现了技术的坚韧与毅力。自2013年百度开始自动驾驶技术的探索以来,Apollo团队一直坚持不懈,经历了无数挑战和困难。然而,他们始终保持着对技术的执着追求,不断突破自我,推动自动驾驶技术的发展。**Apollo 的每一步都走得坚定而有力。**让我们从中学到了不少技术知识,也让我们成为了Apollo时代发展的见证者。我深刻地意识到自动驾驶技术的巨大潜力和广阔前景。而Apollo作为自动驾驶领域的领军企业,将继续引领行业创新,推动自动驾驶技术的普及和应用。自动驾驶技术将会越来越普及。
下一代自动化,国外厂商如何通过生成性AI重塑RPA? 2024-05-06 运维, r语言, 人工智能, 自动化 123人 已看 企业自动化的未来趋势是什么?科技巨头们普遍认为,由生成性AI驱动的AI Agent将成为下一个重大发展方向。尽管“AI Agent”这一术语尚无统一定义,但它通常指的是那些能够根据指令通过模拟人类互动,在软件和网络平台上执行复杂任务的生成性AI工具。例如,AI Agent能在航空公司和酒店连锁的网站上填写客户信息,并制定行程;或者,它可以自动在各个软件中比较价格,帮助用户预订到目的地的最经济的打车服务。供应商们已经意识到这一机会。
实现光储充一体化服务平台需要怎么做 ? 2024-05-09 人工智能, 大数据 76人 已看 首先,通过利用光伏发电和储能系统,客户可以享受到绿色、清洁的能源,降低对传统能源的依赖,从而减少对环境的污染和破坏。其次,由于项目实现了能量的高效转换和存储,客户可以在需要时随时获得稳定、可靠的能源供应,无论是为电动汽车充电还是满足家庭或企业的能源需求。此外,考虑到未来技术的发展和升级,项目的设计应具有一定的前瞻性,以适应未来可能出现的新技术和标准。通过合理规划和设计,将充电桩和光伏系统有效结合在一个大平台中,可以为客户提供绿色、清洁、高效且可靠的能源服务,带来多方面的好处。**充电桩与光伏的结合**
英伟达推出视觉语言模型:VILA 2024-05-06 算法, 语言模型, 计算机视觉, 深度学习, 人工智能 125人 已看 1.情境学习与泛化能力:VILA通过预训练不仅提升了情境学习能力,即模型对新情境的适应性和学习能力,而且还优化了其泛化能力,使模型能在不同的视觉语言任务上展现出色的性能。这个框架旨在通过有效的嵌入对齐和动态神经网络架构,改进语言模型的视觉和文本的学习能力。3.融合层:融合层是VILA模型的核心,它负责整合来自视觉处理单元和语言处理单元的信息,生成统一的、多模态的表示,这对于执行跨模态任务至关重要4.优化策略:包括技术如弹性权重共享和梯度截断,这些策略帮助模型在训练过程中保持稳定,并优化跨模态信息的流动。