Spark面试整理-Spark和Flink的区别 2024-05-06 flink, 面试, spark, 分布式, 大数据 166人 已看 如果应用需要复杂的流处理、低延迟和高吞吐量,Flink可能是更好的选择。而对于批处理或对延迟要求不高的流处理任务,以及需要丰富生态系统和成熟稳定性的场景,Spark可能更加适合。Apache Spark和Apache Flink都是流行的大数据处理框架,但它们在设计理念、性能特性以及适用的使用场景上有所不同。也提供了丰富的API,包括DataStream API和Table API,同时有一定的机器学习和图处理的支持。适合于需要低延迟和高吞吐量的实时流处理应用,以及复杂的事件驱动应用。
【spark RDD】spark 之 Kryo高性能序列化框架 2024-05-07 spark, 前端, 分布式, ajax, 大数据 201人 已看 【spark RDD】spark 之 Kryo序列化框架
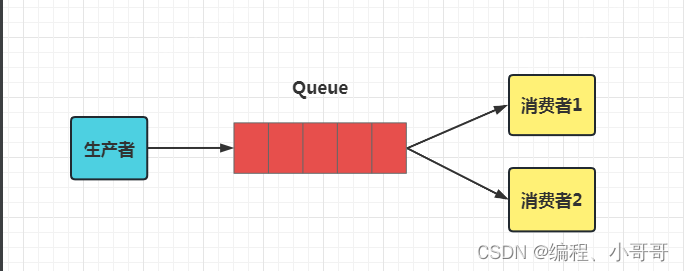
RabbitMQ之基础入门 2024-04-30 后端, rabbitmq, 分布式, ruby, 开发语言 149人 已看 在 AMQP 中,Producer 将消息发送到 Exchange ,再由 Exchange 将消息路由到一个或多个 Queue 中(或者丢弃)。Exchange 根据 Routing Key 和 Binding Key 将消息路由到 Queue ,目前提供了四种类型。A. QueueQueue: Queue(队列)是RabbitMQ的内部对象,用于存储消息,RabbitMQ 中的消息都只能存储在 Queue 中,生产消息并最终投递到Queue中, 消费者可以从Queue中获取消息并消费。