Flink 生态对 Confluent / Kafka Schema Registry 支持情况的研究报告 2024-05-17 flink, linq, kafka, 分布式, 大数据 100人 已看 这几年,在流式链路上引入一个 Schema Registry 变得越来越流行,也越来越有必要, Schema Registry 能有效控制 Schema 的变更,合理推进 Schema Evolution,同时,引入它以后还能有效精简消息内容(特别是针对 Avro 格式),提升消息的传输效率,所以引入 Schema Registry 是有很多正向收益的。在 Flink 生态中,对 Confluent Schema Registry 的支持度如何呢?本文,我们来详细地梳理和总结一下。有关的组件主要是 Flin
2.3 Spark运行架构与原理 2024-05-14 架构, spark, 分布式, 大数据 89人 已看 Spark运行架构由SparkContext、Cluster Manager和Worker构成。在集群模式下,Driver进程初始化SparkContext并向Cluster Manager申请资源,后者根据算法在Worker节点上启动Executor。Executor负责任务执行,反馈状态给Cluster Manager。任务由Task Scheduler发送给Executor执行,完成后Driver注销资源。 Spark的基本流程确保资源管理和任务执行的高效协作,支持并行计算作业的顺利完成。
使用java远程提交spark任务到yarn集群 2024-05-17 java, spark, yarn, 分布式, 大数据, 开发语言 175人 已看 公司需求中,需要用到java远程提交spark任务,方式还是用yarn提供的方法提交任务。如果你也想远程提交flink任务,请看这篇文章。
RabbitMQ中间件安装 2024-05-13 中间件, rabbitmq, 分布式 79人 已看 根据官网的的表格判断自己用哪个版本的 RabbitMQ:https://www.rabbitmq.com/docs/which-erlang#r16b03 根据表格可知,我需要下载 3.6.14 版本。
spark编程基础 2024-05-13 spark, 分布式, 大数据 91人 已看 subtract()方法用于将前一个RDD中在后一个RDD出现的元素删除,可以认为是求补集的操作,返回值为前一个RDD去除与后一个RDD相同元素后的剩余值所组成的新的RDD。使用flatMap()方法时先进行map(映射)再进行flat(扁平化)操作,数据会先经过跟map一样的操作,为每一条输入返回一个迭代器(可迭代的数据类型),然后将所得到的不同级别的迭代器中的元素全部当成同级别的元素,返回一个元素级别全部相同的RDD。转换操作是创建RDD的第二种方法,通过转换已有RDD生成新的RDD。
Hbase2.1.5集群环境搭建 2024-05-15 数据库, 分布式, 大数据, hbase 129人 已看 请注意,以上步骤仅提供了一个大致的框架,具体的步骤可能会因你的环境和需求而有所不同。在实际操作中,请根据你的具体情况进行相应的调整。同时,也建议参考HBase和Hadoop的官方文档,以及相关的教程和社区资源,以获取更详细和准确的指导。使用HBase的shell或Java API测试HBase的基本功能。(由于Hadoop的安装步骤相对复杂,这里仅提供大致步骤,具体步骤请参考Hadoop的官方文档或相关教程)中设置HBase的根目录、Zookeeper的地址等。下载HBase 2.1.5的安装包。
Kafka 环境配置与使用总结 2024-05-12 c#, linq, kafka, 分布式 65人 已看 部署教程参考 # 官方教程: https://kafka.apache.org/quickstart。6-【不同服务器间的消费配置】2-主题topic操作。4-Console操作。5-Configs操作。
零基础掌握Kafka 2024-05-11 kafka, 分布式 62人 已看 Kafka是一个分布式的、可分区的、可复制的消息系统,它主要用于处理大规模实时消息。Kafka的设计目标是高吞吐量、持久存储和低延迟处理。
第十一章数据仓库和商务智能 2024-05-09 spark, 数据仓库, 分布式, 大数据 81人 已看 A:运营报表指的是业务用户直接从交易系统、应用程序或数据仓库生成报表。B:绩效管理是一套集成的组织流程和应用程序,旨在优化业务战略的执行。C:在线分析处理(OLAP)是一种为多维分析查询提供快速性能的方法。D:在线分析处理(OLAP)比在线事务处理(OLTP)对数据的实时性有更高的要求。正确答案:D 你的答案:D解析:309页~310页 1运营报表第一行,2业务绩效管理第一行,310页运营分析应用第二段第一行,D选项说反了。
CAP与BASE分布式理论 2024-05-10 分布式 29人 已看 CAP理论是说对于分布式数据存储,最多只能同时满足一致性(C,Consistency)、可用性(A, Availability)、分区容忍性(P,Partition Tolerance)中的两者。
SparkStructuredStreaming状态编程 2024-05-06 spark, 分布式, 大数据 73人 已看 spark官网关于spark有状态编程介绍比较少,本文是一篇个人理解关于spark状态编程。一般的流计算使用窗口函数可以解决大部分问题,但是一些比较复杂的业务,窗口函数无法解决,比如需要的数据范围大于你设定的时间窗口,那么就需要状态编程处理中间状态。
RabbitMQ高级(MQ的问题,消息可靠性,死信交换机,惰性队列,MQ集群)【详解】 2024-05-08 rabbitmq, 分布式 58人 已看 当我们的生产者发送一条消息后,这条消息最终会到达消费者。那么在这整个过程中任何一个环境出错,都可能会导致消息的丢失,而导致不够可靠。可能出问题的环节有:生产者发送消息到Broker时 丢失:消息未送达Exchange消息到达了Exchange,但未到达QueueBroker收到消息后丢失:MQ宕机,导致未持久化保存消息消费者从Broker接收消息丢失:消费者接收消息后,尚未消费就宕机针对这些问题,RabbitMQ给出了对应的解决方案生产者发送消息丢失:使用生产者确认机制。
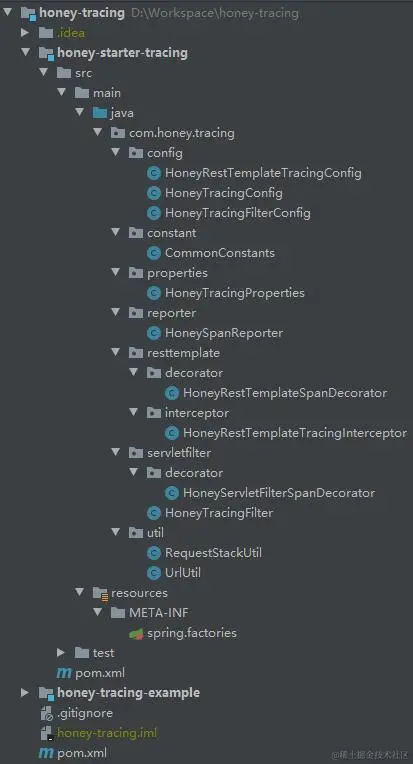
6. 分布式链路追踪RestTemplate拦截器实现设计 2024-05-10 分布式 55人 已看 本文将对4. 分布式链路追踪客户端工具包Starter设计一文中的的拦截器进行一个增强设计,以使得使用调用下游时,可以得到3. 分布式链路追踪的链路日志设计一文中所定义的链路日志的字段内容。相关版本依赖如下。0.33.04.1.01.8.1Springboot2.7.6github本文对的分布式链路追踪拦截器的实现进行了说明,并分析了如何提供装饰器进行功能扩展与增强。
HADOOP之YARN详解 2024-05-07 hadoop, yarn, 分布式, 大数据 218人 已看 第一代Hadoop,由分布式存储系统HDFS和分布式计算框架MapReduce组成。其中,HDFS由一个NameNode和多个DataNode组成,MapReduce由一个JobTracker和多个TaskTracker组成。对应Hadoop版本为Hadoop 1.x, 和0.21.x, 0.22.x。为克服Hadoop 1.0中的HDFS和MapReduce存在的各种问题而提出的,针对Hadoop 1.0中的MapReduce在扩展性和多框架支持方面的不足,提出了全新的资源管理框架YARM。
Apache Spark 的基本概念和在大数据分析中的应用 2024-05-11 apache, spark, 分布式, 大数据 93人 已看 弹性分布式数据集(Resilient Distributed Dataset,简称RDD):RDD 是 Spark 中的基本数据结构,它是一个分布式的不可变数据集合,可以在并行计算中进行操作和处理。总的来说,Apache Spark 是一个功能强大的大数据分析引擎,可以处理大规模数据集,支持多种数据处理和分析场景,是大数据分析中的重要工具之一。数据清洗和预处理:Spark 提供了丰富的数据处理和转换操作,可以对大规模数据进行清洗和预处理,如数据过滤、聚合、整理等。
DI/DO/AI/AO混合分布式BACnet IO控制器助力智慧城市 2024-05-09 人工智能, 智慧城市, 分布式 109人 已看 以智能交通为例,BL207通过其灵活的I/O扩展能力,可以轻松集成于交通信号控制系统中。系统通过BL207的DI模块监控车位占用情况,结合AI模块的车牌识别技术,实现了车位的智能分配与导航,同时通过BACnet/IP网络将数据同步至云端,为车主提供实时空闲车位信息,极大地提高了停车场的运营效率与用户体验。BL207的边缘计算能力使其能够直接在现场处理部分数据,例如,在公共安全监控中,它能即时分析视频流数据,识别异常行为,迅速触发警报或控制继电器启动应急措施,大大缩短响应时间,提升城市的安全防护等级。