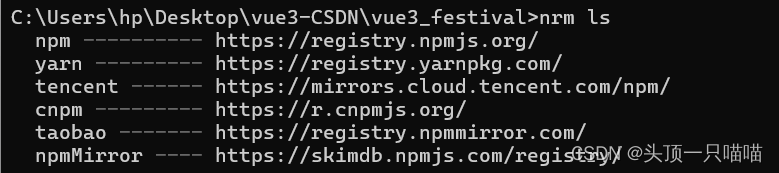
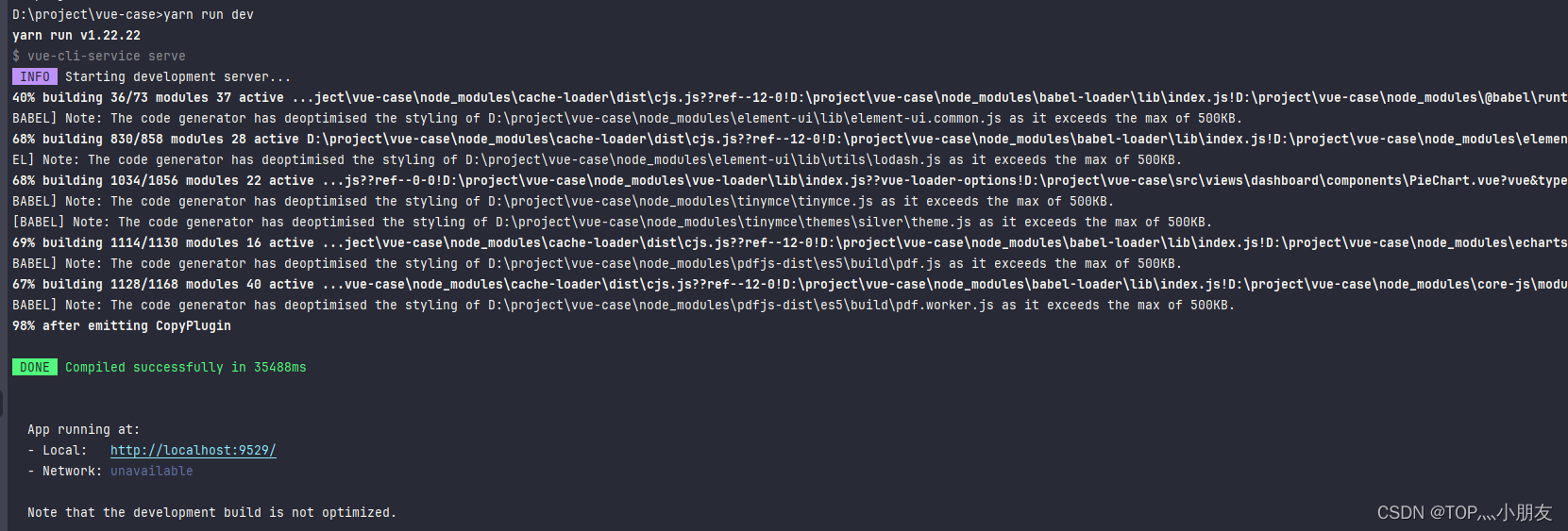
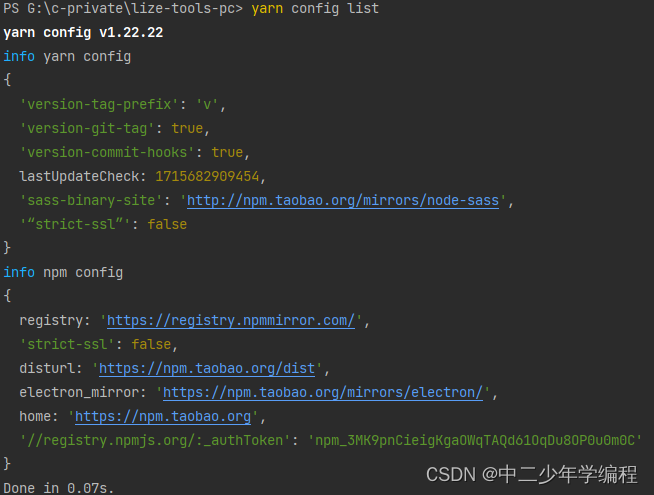
export/data/spark_project/spark_base/05_词频统计案例_spark_on_yarn运行.py。/export/data/spark_project/spark_base/05_词频统计案例_spark_on_yarn运行.py。/export/data/spark_project/spark_base/05_词频统计案例_spark_on_yarn运行.py。相比原理hadoop集群,需要多启动一个spark的自己的历史服务,它是依赖hadoop的历史服务的!