Hadoop 面试题(九) 2024-06-25 java, hadoop, 分布式, 大数据, eclipse 359人 已看 1. 简述下面关于Hadoop系统中使用CombineFileInputFormat解决小文件问题的描述错误的是() ?2. 简述有关Hadoop生态中各个角色对在高可用上的作用下列描述错误的是() ?3. 简述关于Hadoop系统中添加节点的描述错误的是 ?4. 简述不参与Hadoop系统读过程的组件是 ?5. 简述关于 HDFS 安全模式说法正确的是() ?6. 简述Hadoop生态圈中ZooKeeper的作用描述错误的选项是() ?
hadoop常见简单基础面试题 2024-06-18 hadoop, 分布式, 大数据 328人 已看 inputFile 通过 split 被切割为多个 split 文件,通过 Record 按行读取内容给map(自己写的处理逻辑的方法) ,数据被 map 处理完之后交给 OutputCollect收集器,对其结果key进行分区(默认使用的hashPartitioner),然后写入buffer,
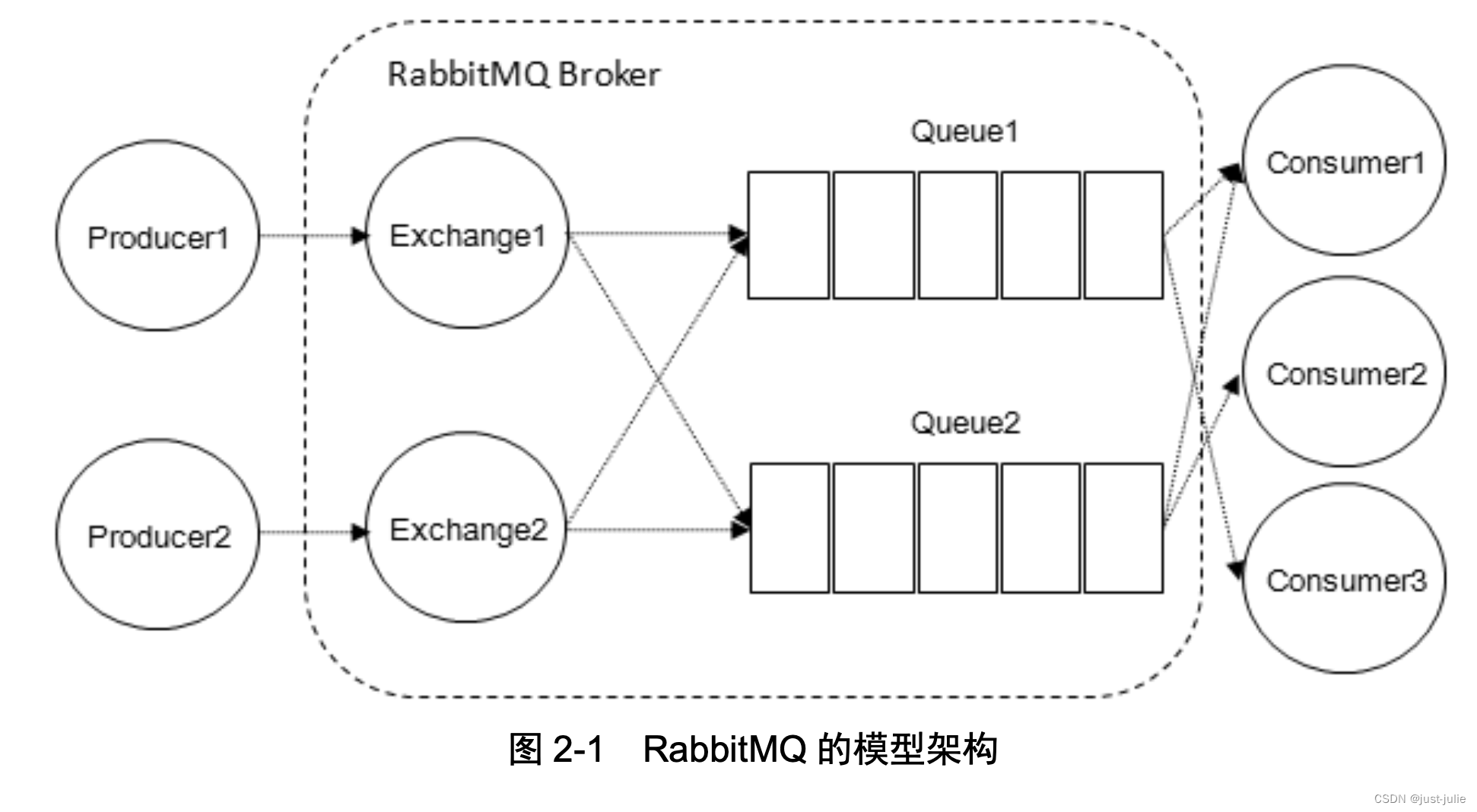
RabbitMQ 相关概念 2024-06-18 rabbitmq, 分布式 283人 已看 消息是指在应用间传送的数据,包含文本字符串、JSON等。消息队列中间件(MQ)指利用高效可靠的消息传递机制进行平台无关的数据交流,并基于数据通信来进行分布式系统的集成。通过提供消息传递和消息排队模型,他可以在分布式环境下扩展进程间的通信。消息队列中间件,也称为消息队列或者消息中间件,一般有两种传递模式:点对点(P2P)以及发布/订阅(Pub/Sub)模式.点对点模式是基于队列的,消息生产者发送消息到队列,消息消费者从队列中接收消息,队列的存在使得消息的异步传输成为可能。
在PHP项目中使用阿里云消息队列MQ集成RabbitMQ的完整指南与问题解决 2024-06-18 阿里云, rabbitmq, 分布式, 云计算 443人 已看 阿里云消息队列MQ作为一种高可用、可伸缩的消息队列服务,为开发者提供了可靠的消息投递和处理能力。通过本文的介绍,你应该能够在PHP项目中集成阿里云消息队列MQ,并使用RabbitMQ进行消息的发布和订阅。3. **获取AccessKey和SecretKey**:在阿里云控制台,找到并记录你的AccessKey和SecretKey。首先,需要在你的PHP项目中安装RabbitMQ的PHP客户端。2. **创建消息队列实例**:登录阿里云控制台,创建一个新的消息队列实例。#### 五、消费者接收并处理消息。
Hbase存储倒排索引 2024-06-20 数据库, 分布式, 大数据, hbase 267人 已看 定义:倒排索引是搜索引擎用于快速全文搜索的数据结构,它将文档中出现的每个词与包含该词的文档列表相关联。组成:倒排索引由两部分组成:词典和倒排文件。词典包含所有唯一词项,倒排文件包含每个词项对应的倒排列表(即文档ID列表)。
RabbitMQ实践——最大长度队列 2024-06-19 网络, rabbitmq, 分布式 318人 已看 在一些业务场景中,我们只需要保存最近的若干条消息,这个时候我们就可以使用“最大长度队列”来满足这个需求。该队列在收到消息后,如果达到长度上限,会将队列头部(最早的)的信息从队列中移除。在进行实验之前,我们先创建一个交换器direct.max.length,用于接收消息。
springCloudAlibaba之分布式网关组件---gateway 2024-06-16 spring, java, 后端, 分布式, gateway 275人 已看 在微服务架构中一个系统会被拆分成多个微服务。那么作为客户端(前端)要如何去调用这么多的微服务?如果没有网关的存在,我们只能在客户端记录每个微服务的地址,然后分别去用。
Mac M3 Pro 安装 Zookeeper-3.4.6 2024-06-15 云原生, zookeeper, 分布式, macos 287人 已看 Mac M3 Pro 安装 Zookeeper-3.4.6
【大数据】gRPC、Flink、Kafka 分别是什么? 2024-06-18 flink, kafka, 分布式, 大数据 340人 已看 Apache Flink 是一个开源的流处理框架,用于处理无界和有界数据流。它是一个分布式处理引擎,支持实时数据流处理和批处理任务。Flink 被广泛应用于大数据分析、机器学习、实时监控和复杂事件处理等领域。
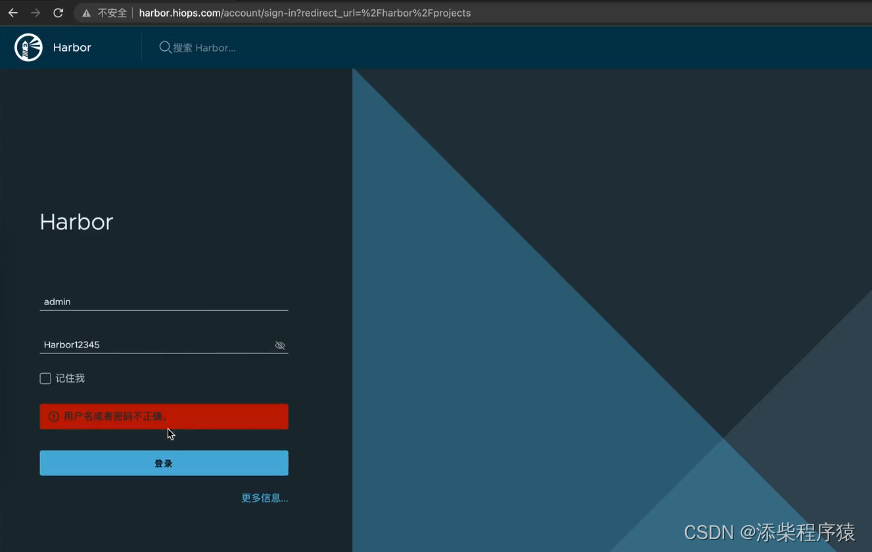
Harbor本地仓库搭建003_Harbor常见错误解决_以及各功能使用介绍_镜像推送和拉取---分布式云原生部署架构搭建003 2024-06-18 云原生, 架构, 分布式 249人 已看 然后点开这个镜像,可以看到对应的artifacts还有,他的tags,我们设站点1.15.12对吧。可以看到添加上,忽略的域名就可以了,让docker,对我们的地址,忽略https检测。首先我们去登录一下harbor,但是可以看到,用户名密码没有错,但是登录不上去。是因为,我们用了负债均衡,nginx会把,负载均衡进行,随机分配,访问的。的business这个项目,可以看到在镜像仓库中,就有了。登录以后,可以看到项目中,我们可以创建一个项目,比如。可以看到我们给,负载均衡,分发的时候,添加上。
大数据学习-Hadoop 2024-06-21 hadoop, 分布式, 大数据 341人 已看 分布式大数据存储——HDFS 组件分布式大数据计算——MapReduce 组件分布式资源调度——YARN 组件可以通过它来构建集群,完成大数据的存储和计算学习起来相对简单,市场占有率高,为后续的其他大数据软件学习打下基础这里学习的是 Hadoop 开源版它是 Hadoop 的一个组件,用来进行分布式计算的一个框架;计算的模式:分散-汇总模式提供了两个接口Map,提供“分散”功能,由多个服务器分布式地对数据进行处理Reduce,提供“汇总”功能,将分布式计算的结果进行汇总。
Zookeeper 集群节点选举原理实现(二) 2024-06-19 云原生, zookeeper, 数据库, 分布式 367人 已看 通过以上解释,我们可以了解 Zookeeper 如何初始化和实现 ZXID 以及领导节点选举过程中的核心逻辑。ZXID 确保了事务的全局顺序一致性,而isMajority方法确保了选举结果的合法性。理解这些原理和实现逻辑对于掌握 Zookeeper 的工作机制至关重要。
Redis 的分布式 Session 与本地 Session 的区别 2024-06-17 缓存, 数据库, 分布式, redis 331人 已看 在现代分布式系统中,选择合适的 Session 管理机制至关重要。相比本地 Session,分布式 Session 具有更高的扩展性和可用性,适用于多节点分布式环境。
微服务SpringCloud ES分布式全文搜索引擎简介 下载安装及简单操作入门 2024-06-15 spring, 微服务, elasticsearch, 搜索引擎, 分布式 280人 已看 分布式全文搜索引擎我们天天在用ES搜索的时候要与多个信息进行匹配查找然后返回给用户首先ES会将数据库中的信息先进行一个拆分这个叫做分词是按照词语关键词拆的然后就能进行搜索的时候匹配对应的id每一个关键字对应若干id每一个id对应数据然后搜索的时候展示简化版数据点击简化版数据反映全部信息属于的是全文搜索在数据库中有索引在ES中也有索引但是根据关键字查ID 再由ID查数据这个在全文搜索里叫倒排索引倒排索引是怎么出现的呢是根据创建文档 出现一个一个的库。
【Kafka】Kafka生产者数据重复、数据有序、数据乱序-07 2024-06-16 linq, kafka, 数据库, 分布式, sql 335人 已看 虽然同一个消息不会被写入多个分区,但Kafka有一个副本机制(Replication),用于提高数据的可靠性和容错性。每个分区有一个主副本(Leader)和多个从副本(Follower),这些副本会在不同的Broker上保存相同的数据。相同键的消息会被写入同一个分区,从而保证了消息的顺序性。每个Kafka主题(Topic)可以有多个分区(Partitions),消息在这些分区之间分布。当Producer发送消息到一个分区的主副本时,主副本会将消息复制到从副本中,以保证数据的高可用性。
RabbitMQ消息的可靠传输和防止消息丢失 2024-06-16 后端, rabbitmq, 分布式, 开发语言, ruby 328人 已看 import org} }} }} }@Bean@Bean@Bean通过以上步骤,你可以在Spring Cloud项目中使用RabbitMQ并确保消息不会丢失。消息和队列的持久化:确保消息和队列都是持久化的。发布确认。