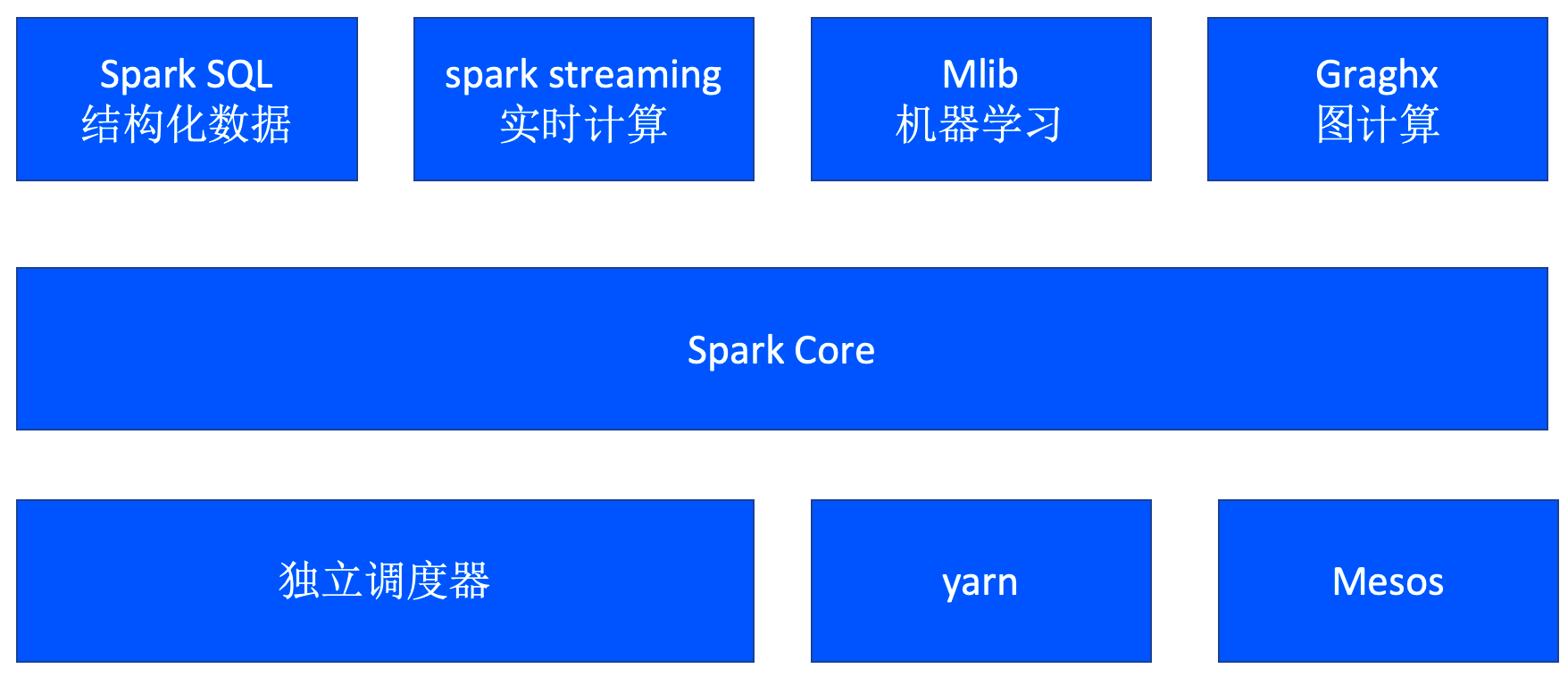
而对数据计算复杂(有推荐、分类、聚类算法场景)且时延要求高的场景,如迭代计算, 交互式计算, 流计算、有机器学习算法需求,图计算需求,且成本投入可以接受的情况下使用Spark SQL,Spark SQL读取的数据都是存入到内存中,因此对机器的内存有要求,且要求内存较大, 相对较贵.总结一下,hiveSQL 应用于大规模的离线跑批,但是对时间要求不高,而Spark SQL 应用于迭代式计算和交互式数据挖掘、Spark Streaming 支持流式数据计算、Spark MLlibk提供的机器学习功能的程序库。