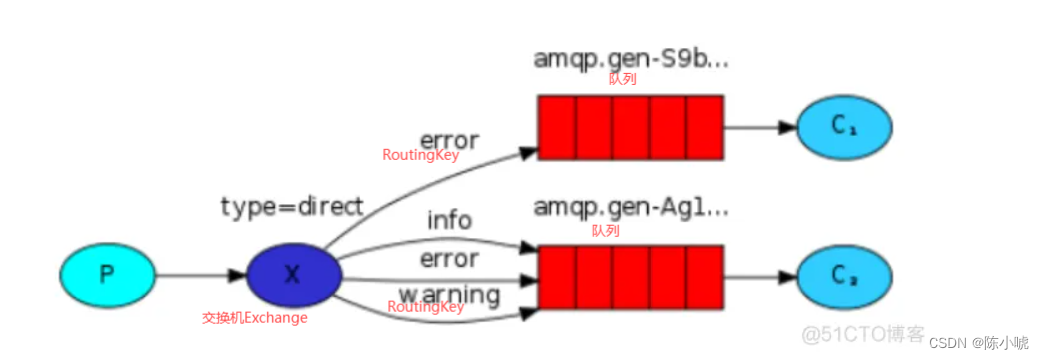
RabbitMQ(Direct 订阅模型-路由模式)的使用 2024-05-31 后端, rabbitmq, 分布式, ruby, 开发语言 283人 已看 订阅模型-路由模式,此时生产者发送消息时需要指定 RoutingKey,即路由 Key,Exchange 接收到消息时转发到与 RoutingKey 相匹配的队列中。 direct的意思是直接的,direct类型的Exchange会将消息转发到指定Routing key的Queue上,Routing key的解析规则为精确匹配。也就是只有当producer发送的消息的Routing key与某个Binding key相等时,消息才会被分发到对应的Queue上。
WPF入门--多种方式设置样式(Style) 2024-05-31 hadoop, wpf, 分布式, 大数据 160人 已看 本篇文章通过多种方式设置WPF样式(Style)以控制UI元素的外观和行为
Sleuth(Micrometer)+ZipKin分布式链路追踪(上) 2024-06-03 分布式 98人 已看 问题:在微服务框架中,一个由客户端发起的请求在后端系统中会经过多个不同的的服务节点调用来协同产生最后的请求结果,每一个前段请求都会形成一条复杂的分布式服务调用链路,链路中的任何一环出现高延时或错误都会引起整个请求最后的失败。在分布式与微服务场景下,我们需要解决如下问题:在大规模分布式与微服务集群下,如何实时观测系统的整体调用链路情况。在大规模分布式与微服务集群下,如何快速发现并定位到问题。在大规模分布式与微服务集群下,如何尽可能精确的判断故障对系统的影响范围与影响程度。
spark3.0.1版本查询Hbase数据库例子 2024-05-31 spark, 数据库, 分布式, 大数据, hbase 210人 已看 需要采用spark查询hbase数据库的数据同步到中间分析库,记录spark集成hbase的简单例子代码
数据仓库与数据挖掘总复习练习2-3(实验六 2024.6.5) 2024-06-05 spark, 数据仓库, 人工智能, 分布式, 大数据, 数据挖掘 184人 已看 cities中index:数值,data:地名。(index中值最好不要重复,避免计算错误)一列作为index,一列作为数据。
MQ基础(RabbitMQ) 2024-06-03 microsoft, rabbitmq, 分布式 154人 已看 同步通信:就相当于打电话,双方交互是实时的。同一时刻,只能与一人交互。异步通信:就相当于发短信,双方交互不是实时的。不需要立刻回应对方,可以多线程操作,跟不同人同时聊天。
8、架构-分布式的共识 2024-06-02 架构, 分布式 127人 已看 在正式探讨分布式环境中面临的各种技术问题和解决方案前,我 们先把目光从工业界转到学术界,学习几种具有代表性的分布式共识 算法,为后续在分布式环境中操作共享数据准备好理论基础。下面笔 者从一个最浅显的场景开始,引出本章的主题:如果你有一份很重要的数据,要确保它长期存储在电脑上不会丢 失,你会怎么做?这不是什么脑筋急转弯的古怪问题,答案就是去买几块硬盘,在 不同硬盘上多备份几个副本。
数据仓库与数据挖掘总复习练习2-3(实验六 2024.6.5) 2024-06-05 spark, 数据仓库, 人工智能, 分布式, 大数据, 数据挖掘 201人 已看 cities中index:数值,data:地名。(index中值最好不要重复,避免计算错误)一列作为index,一列作为数据。
kafka-生产者拦截器(SpringBoot整合Kafka) 2024-06-04 c#, linq, kafka, 分布式 161人 已看 kafka-生产者拦截器(SpringBoot整合Kafka)
RabbitMQ延时队列 2024-06-01 rabbitmq, 分布式 155人 已看 rabbitmq延时队列的实现,使用docker部署的rabbitmq上下载并使用rabbitmq延时插件,以及延时队列的示范代码实现,和确保消息可靠性的生产者的处理方法
kafka-生产者拦截器(SpringBoot整合Kafka) 2024-06-04 c#, linq, kafka, 分布式 155人 已看 kafka-生产者拦截器(SpringBoot整合Kafka)
Spark基础:Scala内建控制结构 2024-05-29 scala, spark, 分布式, 大数据, 开发语言 261人 已看 在Scala中,控制结构是编程的基础,它们允许你根据条件执行不同的代码块,或者重复执行某些代码块。Scala的for循环非常强大,可以遍历集合、数组、列表等,并支持多种模式,包括传统的C-style for循环和更强大的for推导式(for comprehension)。Scala的模式匹配功能强大且灵活,它允许你根据输入的值匹配不同的模式,并执行相应的代码块。这在处理复杂的数据结构时特别有用。等操作中,你可能需要根据数据的某些属性来执行不同的操作,这时就需要使用到条件语句和循环结构。
使用 Django 和 RabbitMQ 构建高效的消息队列系统 2024-05-28 python, django, 后端, rabbitmq, 分布式 163人 已看 RabbitMQ是一个流行的开源消息队列系统,它支持多种消息协议,包括 AMQP、STOMP 和 MQTT。RabbitMQ 提供了高度可靠的消息传递机制,并且具有良好的性能和可扩展性,因此成为了许多开发人员首选的消息队列系统。通过本文,我们了解了如何在 Django 项目中集成 RabbitMQ 来构建一个高效的消息队列系统。结合 Celery 这样的任务队列库,我们可以实现异步任务的处理,提高系统的性能和可扩展性。
Spark的性能调优——RDD 2024-06-03 c#, spark, 分布式, ajax, 大数据 246人 已看 参数是函数、或者返回值是函数的函数,我们把这类函数统称为“高阶函数”(Higher-order Functions)。换句话说,这 4 个算子,都是高阶函数。// 读取文件内容// 以行为单位做分词// 把RDD元素转换为(Key,Value)的形式// 按照单词做分组计数// 打印词频最高的5个词汇在 RDD 的编程模型中,一共有两种算子,Transformations 类算子和 Actions 类算子。
Spark Streaming概述 2024-05-29 spark, 分布式, 大数据 122人 已看 Spark Streaming的工作原理是将输入数据以某一时间间隔(如几秒)批量地处理。Spark Streaming通过定期地(如每几秒)从数据源拉取数据,并创建新的RDD来表示这些数据。总之,Spark Streaming是一个强大的实时计算框架,具有实时数据处理、微批次处理、容错性、灵活性等特点。它可以与Spark的其他组件集成,实现数据的批处理和实时处理的无缝衔接。Spark Streaming是构建在Spark上的实时计算框架,它扩展了Spark处理大规模流式数据的能力。
修改hostname导致RabbitMQ数据丢失 2024-05-31 rabbitmq, 分布式 121人 已看 公司的很多关键服务都使用了RabbitMQ来作为消息队列服务, 可以说是非常地关键的一个环节, 最近由于业务量的上升, 导致RabbitMQ的CPU持续走高, 所以抽空研究了一下RabbitMQ的扩容, 利用我们自己运维平台使用的一个单节点的RabbitMQ来作为测试吧.看到这个单节点的RabbitMQ的服务器主机名不是很规范, 所以就顺手改了主机名。
dolphinScheduler(海豚调度器)分布式机群安装 2024-05-31 分布式 117人 已看 bigdata1:2181,bigdata2:2181,bigdata3:2181 为大数据zookeeper集群。下载好安装包 apache-dolphinscheduler-3.0.0-bin.tar.gz,上传至 /opt。bigdata1和bigdata2为安装了resource manager的主机名。找到on-profile: mysql。找到type: zookeeper。{ip}为mysql8数据库ip。ns为HDFS的命名空间。
hadoop其中一个节点坏了,用其他节点克隆的教程+datanode正常显示,但master只有1个livenodes 2024-05-28 hadoop, 分布式, 大数据 134人 已看 3.去克隆出来的slave的hdfs的存放datanode的文件夹(你自己已经配置了相应的名称)把current文件夹删掉。1.克隆后只需要:sudo gedit /etc/network/interfaces,把ip地址改好。master只有1个livenodes主要是因为logs的问题。把你识别成原来的另一台机器了。如果一个slave出了非常棘手的问题,还是用其他slave克隆吧,很快的。6.去克隆出来的slave上,tmp里面的东西也全删掉。4.去克隆出来的slave上,把logs文件夹删掉。
Go 雪花算法生成唯一ID(Snowflake)&分布式 2024-05-30 golang, 后端, 分布式, 开发语言 152人 已看 实例时,你需要为每个节点配置一个不同的工作节点ID。这个ID通常在节点启动时配置,并在节点的整个生命周期内保持不变。:尽管雪花算法是线程安全的,可以在同一节点内被多个 Goroutine 安全地调用,但不同节点之间不应该共享同一个。:每个节点(或服务实例)都应该有一个唯一的工作节点ID(worker ID)。在使用 Go 语言实现的雪花算法(Snowflake)时,每个分布式系统中的节点通常都会有一个独立的。实例,并为其分配一个唯一的工作节点ID。实例会根据节点的配置生成唯一的ID。